多场景游戏AI新突破!Divide-Fuse-Conquer如何激发大模型"顿悟时刻"?
大语言模型在强化学习中偶现的"顿悟时刻"引人关注,但多场景游戏中训练不稳定、泛化能力差等问题亟待解决。Divide-Fuse-Conquer方法,通过分组训练、参数融合等策略,在18款TextArena游戏中实现与Claude3.5相当的性能,为多场景强化学习提供新思路。
论文标题
Divide-Fuse-Conquer: Eliciting “Aha Moments” in Multi-Scenario Games
来源
arXiv:2505.16401v1 [cs.LG] + https://arxiv.org/abs/2505.16401
文章核心
研究背景
近年来,大语言模型(LLMs)在强化学习(RL)中展现出令人瞩目的推理能力,在数学、编程、视觉等领域通过简单的基于结果的奖励,就能触发类似人类“顿悟时刻”的能力突破。
尽管RL在单场景任务中成效显著,但在多场景游戏领域却面临严峻挑战。游戏场景中,规则、交互模式和环境复杂度的多样性,导致策略常出现“此长彼消”的泛化困境——在某一场景表现优异,却难以迁移至其他场景。而简单合并多场景进行训练,还会引发训练不稳定、性能不佳等问题,这使得多场景游戏成为检验RL与LLMs结合成效的关键领域,也亟需新的方法来突破现有瓶颈。
研究问题
1. 训练不稳定性:多场景游戏中任务分布异质性强,直接应用强化学习易导致训练崩溃,如DeepSeek-R1在场景增多时性能显著下降。
2. 泛化能力不足:简单合并多场景训练时,模型在某一场景表现良好,却难以迁移到其他场景,出现"顾此失彼"的情况。
3. 效率与性能矛盾:统一训练所有场景时,模型可能优先学习简单任务,忽视复杂任务,导致整体优化效率低下且最终性能不佳。
主要贡献
1. 提出Divide-Fuse-Conquer框架:通过启发式分组、参数融合和渐进式训练,系统性解决多场景强化学习中的训练不稳定和泛化问题,这与传统单一训练或简单合并训练的方式有本质区别。
2. 创新技术组合提升训练质量:集成格式奖励塑造、半负采样、混合优先级采样等技术,从稳定性、效率和性能三方面优化训练过程,如半负采样通过过滤一半负样本防止梯度主导,就像在嘈杂环境中过滤掉部分干扰信号。
3. 多场景游戏验证与性能突破:在18款TextArena游戏中,使用Qwen2.5-32B-Align模型训练后,与Claude3.5对战取得7胜4平7负的成绩,证明该框架能有效激发大模型在多场景游戏中的"顿悟时刻"。
方法论精要
框架设计:Divide-Fuse-Conquer的三级递进策略
分组(Divide):根据游戏规则(如固定/随机初始状态)和难度(基础模型胜率是否为零),将18款TextArena游戏划分为4个组。例如,ConnectFour-v0等固定初始状态且基础模型可获胜的游戏归为一组,而LiarsDice-v0等随机初始状态且初始胜率为零的游戏归为另一组,如同将复杂任务按类型和难度分类拆解。
融合(Fuse):采用参数平均策略融合各组最优策略。具体而言,第 k k k组策略参数 θ ( π k ) \theta^{(\pi_k)} θ(πk)与前 k − 1 k-1 k−1组合并后的参数 θ ( π ( k − 1 ) ) ) \theta^{(\pi{(k-1)})}) θ(π(k−1)))按 θ ( π ( k ) ) = 1 2 ( θ π ( k − 1 ) + θ π k ) \theta^{(\pi{(k)})} = \frac{1}{2}(\theta^{\pi{(k-1)}} + \theta^{\pi_k}) θ(π(k))=21(θπ(k−1)+θπk)融合,使新模型继承跨组知识,类似将不同领域的专家经验整合为“全能选手”。
征服(Conquer):通过GRPO算法对融合模型持续训练,结合多维度优化技术,逐步提升跨场景泛化能力。


核心技术:多维度训练优化组合
奖励机制重构:
格式奖励 ( R format ) (R_{\text{format}}) (Rformat):对无效动作(如格式错误)施加-2惩罚,确保模型输出合规,如同考试中规范答题格式。
环境奖励 ( R env ) (R_{\text{env}}) (Renv):按游戏结果赋予1(胜)、0(平)、-1(负),直接反馈游戏胜负。
仓促动作惩罚 ( R step ) (R_{\text{step}}) (Rstep):在获胜场景中,根据轨迹步数 n T n_T nT缩放奖励(如TowerOfHanoi中高效解法获更高分),引导模型避免短视决策。

样本与探索优化:
半负采样(Half-Negative Sampling):随机丢弃50%负样本,防止负梯度主导训练,类似在嘈杂数据中过滤干扰。
混合优先级采样(MPS):动态分配采样权重,优先训练中低胜率游戏,如学生重点攻克薄弱科目。
ϵ \epsilon ϵ-greedy扰动与随机种子:以概率 ϵ \epsilon ϵ随机选择动作,并随机初始化环境种子,增强探索多样性,避免陷入局部最优。
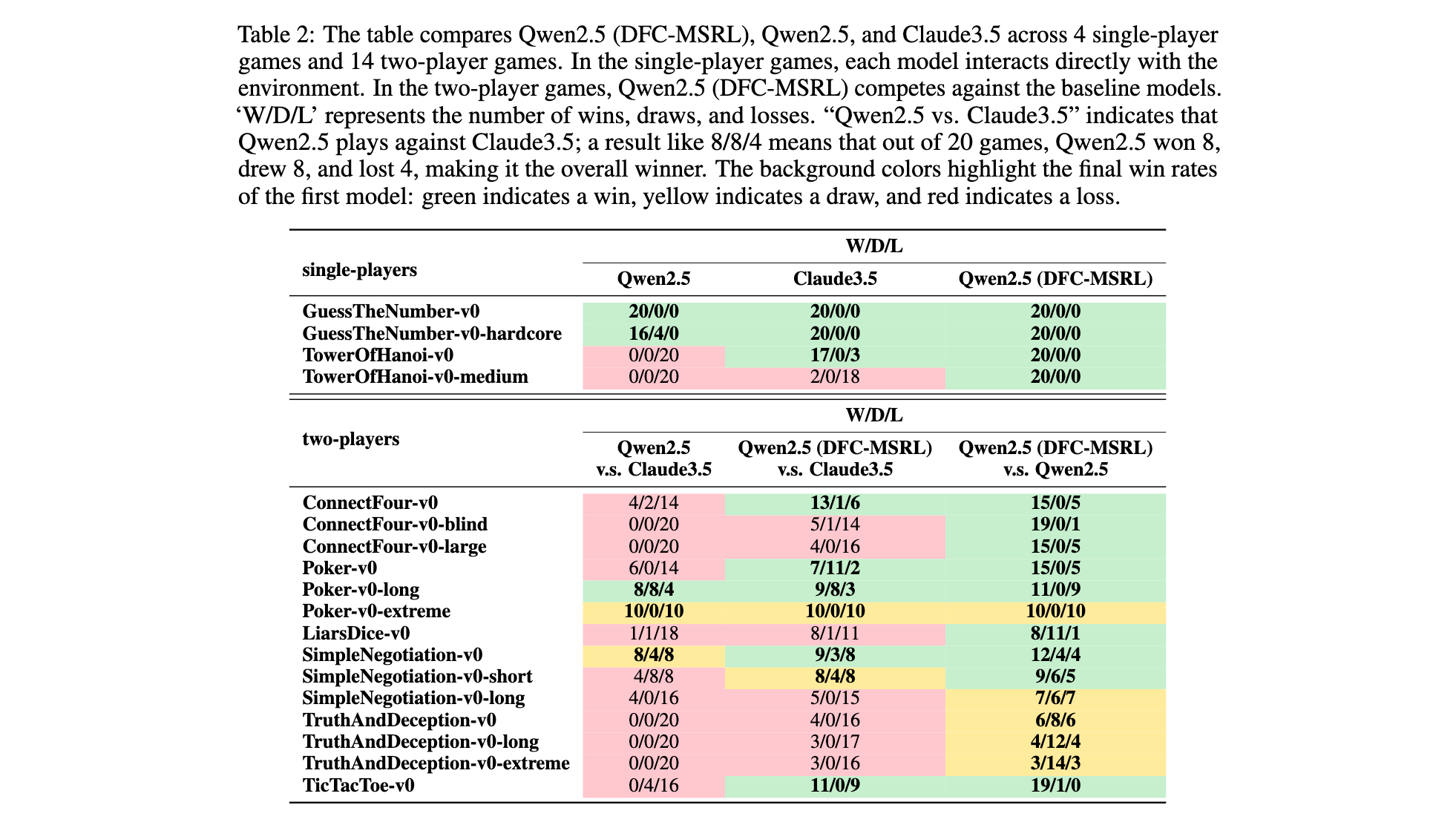
实验验证:多场景与基线对比设计
数据集:TextArena平台18款游戏,包括4款单玩家(如TowerOfHanoi-v0)和14款双玩家(如Poker-v0、ConnectFour-v0),覆盖规则简单到复杂的场景。
基线方法:
- Naive-MSRL:直接多场景RL训练;
- Naive-SSRL:单场景RL训练;
- Claude3.5:先进大模型基线。
实施细节:使用64张A100 GPU,batch size=1,学习率2e-6,训练100轮,每轮通过自玩收集轨迹数据,结合GRPO算法更新策略,最终以胜率(W/D/L)评估跨场景性能。
实验洞察
跨场景性能突破:Qwen2.5与Claude3.5的对战表现
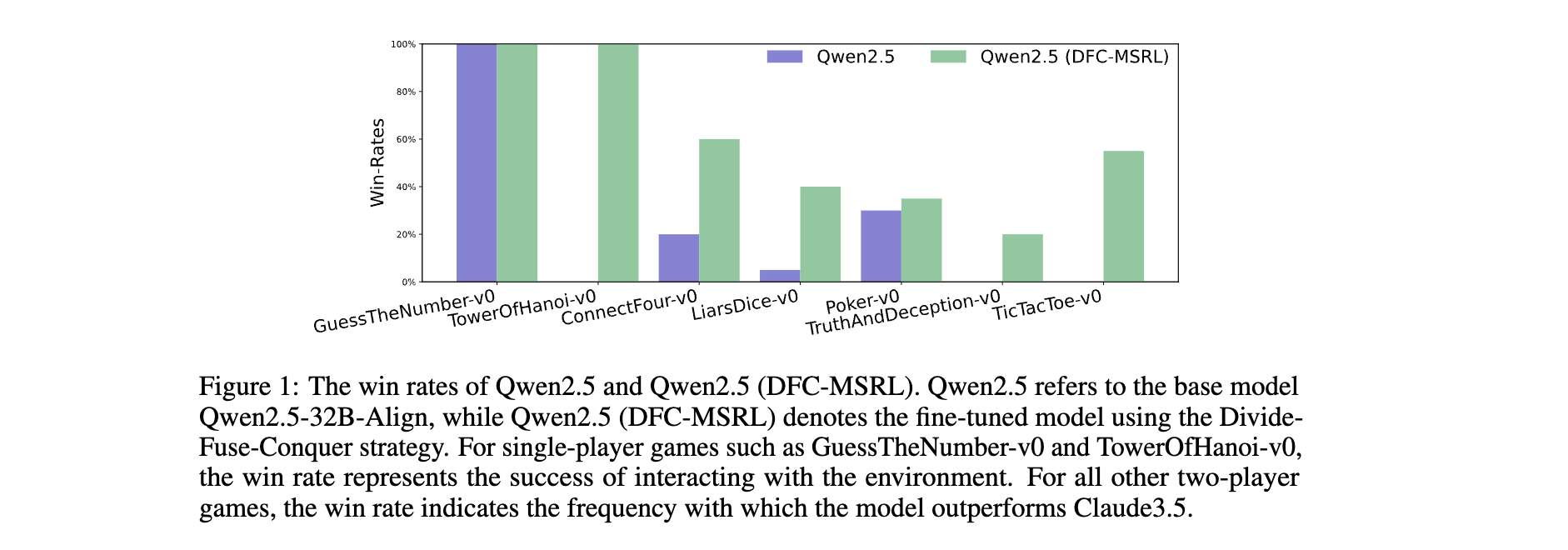
在18款TextArena游戏中,采用Divide-Fuse-Conquer(DFC-MSRL)训练的Qwen2.5-32B-Align模型展现出显著提升:
- 单玩家游戏全胜突破:在TowerOfHanoi-v0-medium等场景中,模型从基础版本的0胜率提升至100%胜率,如3层汉诺塔问题中,通过策略优化实现7步内完成移动(传统解法最优步数)。
- 双玩家游戏竞争力:与Claude3.5对战时,取得7胜4平7负的战绩。其中在ConnectFour-v0中以13胜1平6负显著超越基础模型(4胜2平14负);在Poker-v0中以7胜11平2负实现平局率提升,证明在策略博弈中具备动态决策能力。
效率验证:训练收敛速度与资源优化
- 对比单/多场景训练:DFC-MSRL在ConnectFour-v0中仅用10轮迭代就达到65%胜率,而Naive-MSRL需30轮才收敛至40%,训练效率提升约3倍。这得益于分组训练减少了跨场景干扰,类似分阶段攻克知识点的学习模式。
- 采样策略的效率优势:混合优先级采样(MPS)使TowerOfHanoi-v0-medium的有效训练样本增加40%,模型在20轮内即稳定至100%胜率,而均匀采样基线需40轮,验证了“优先攻克薄弱场景”策略的高效性。
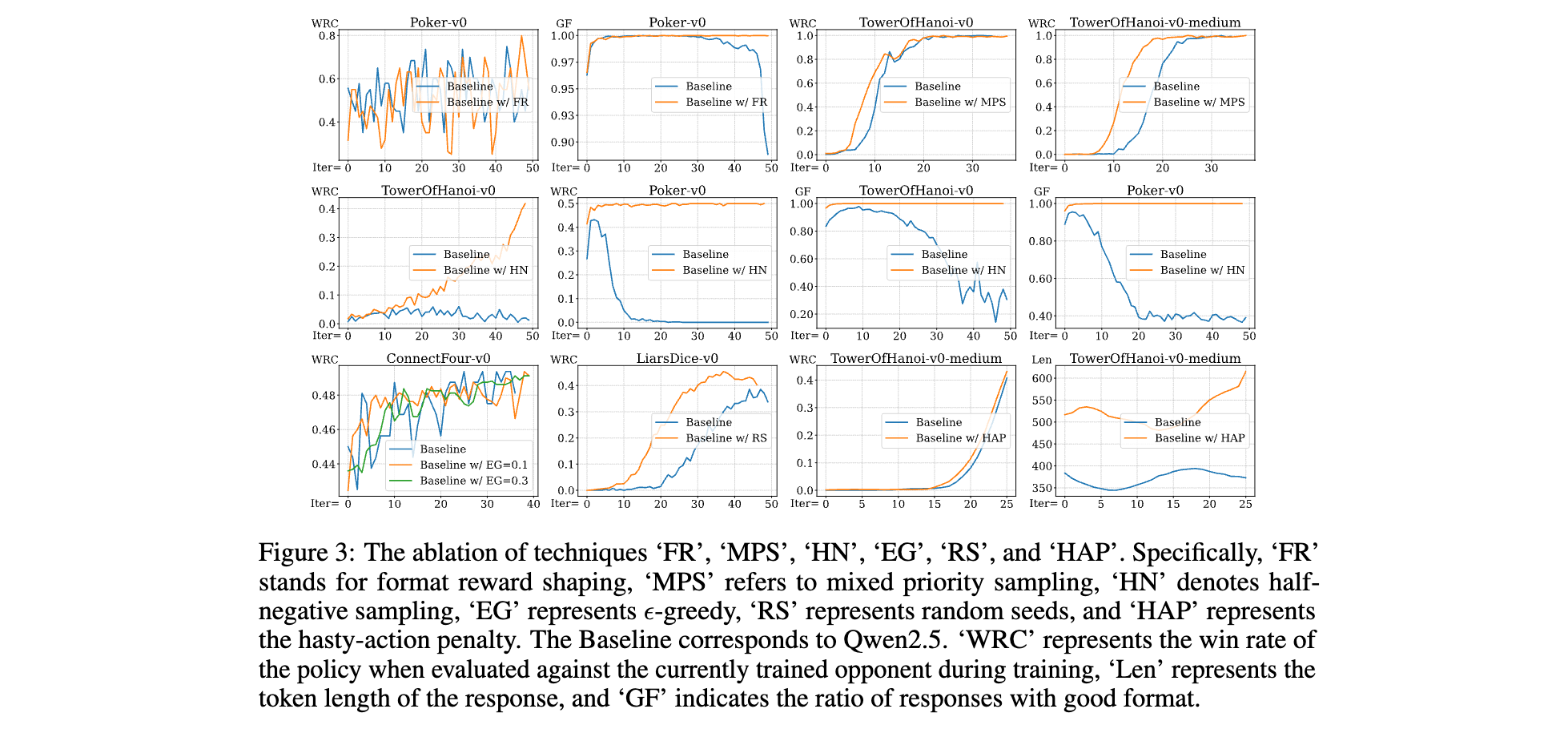
消融研究:核心技术的有效性拆解
稳定性优化技术
- 格式奖励塑造(FR):在Poker-v0中,FR使模型输出有效动作比例(GF)始终维持1.0,而无FR的基线模型在10轮后GF骤降至0.6,出现大量格式错误(如未按“[Action]”格式输出),证明格式约束是训练基石。
- 半负采样(HN):在TowerOfHanoi-v0中,HN将训练初期的胜率波动从±30%降至±5%,避免负样本主导导致的策略崩溃,如同在学习中过滤掉过多错误示例的干扰。
探索与采样技术
- ε-greedy扰动(EG):在ConnectFour-v0中,EG=0.3时模型从持续输给Claude3.5(0胜20负)转变为可获胜(5胜1平14负),证明随机探索能帮助模型发现“四子连线”的关键策略,而纯贪心策略易陷入固定思维。
- 随机种子初始化(RS):在LiarsDice-v0中,RS使模型面对不同初始骰子分布时胜率提升25%,从基线的40%升至65%,验证了多样化初始状态对策略泛化的重要性。
奖励机制优化
- 仓促动作惩罚(HAP):在TowerOfHanoi-v0-medium中,HAP使模型平均决策步数从12步降至8步(接近最优解),轨迹长度减少33%,表明惩罚机制有效抑制了“盲目试错”行为,引导模型追求高效策略。
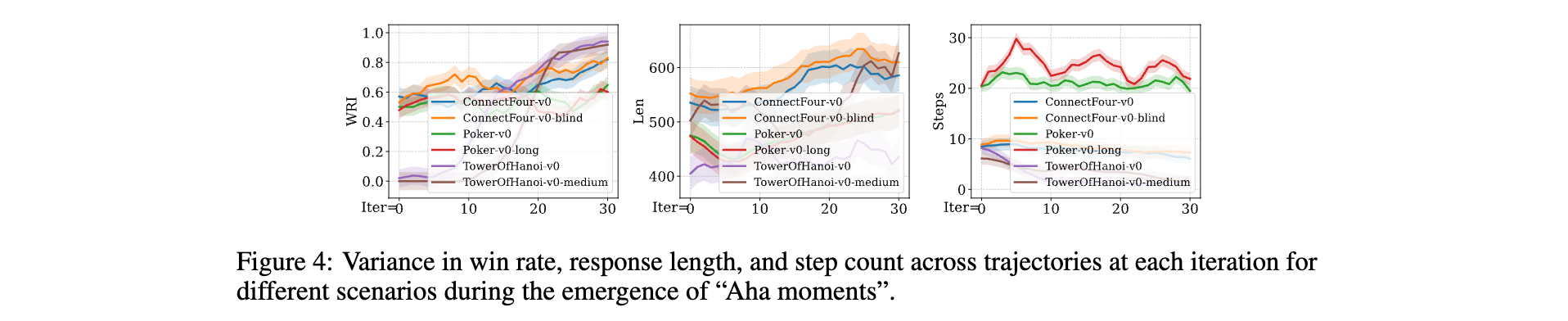
Aha Moment
在TextArena游戏中应用GRPO训练时,模型偶现“Aha moments”。表现为胜率显著提升,如ConnectFour-v0从4胜到13胜;响应更深入,token长度增30%;结合惩罚后执行步数减25%,如TowerOfHanoi-v0-medium达最优解,体现从试错到策略推理的突破。









)

)



坐标系!)




)