YOLOv2讲解
一、YOLOv2 整体架构与核心特性
YOLOv2(You Only Look Once v2)于2016年发布,全称为 YOLO9000(因支持9000类目标检测),在YOLOv1基础上进行了多项关键改进,显著提升了检测精度和速度,同时首次实现了目标检测与分类的联合训练。
二、YOLOv2 网络结构详解
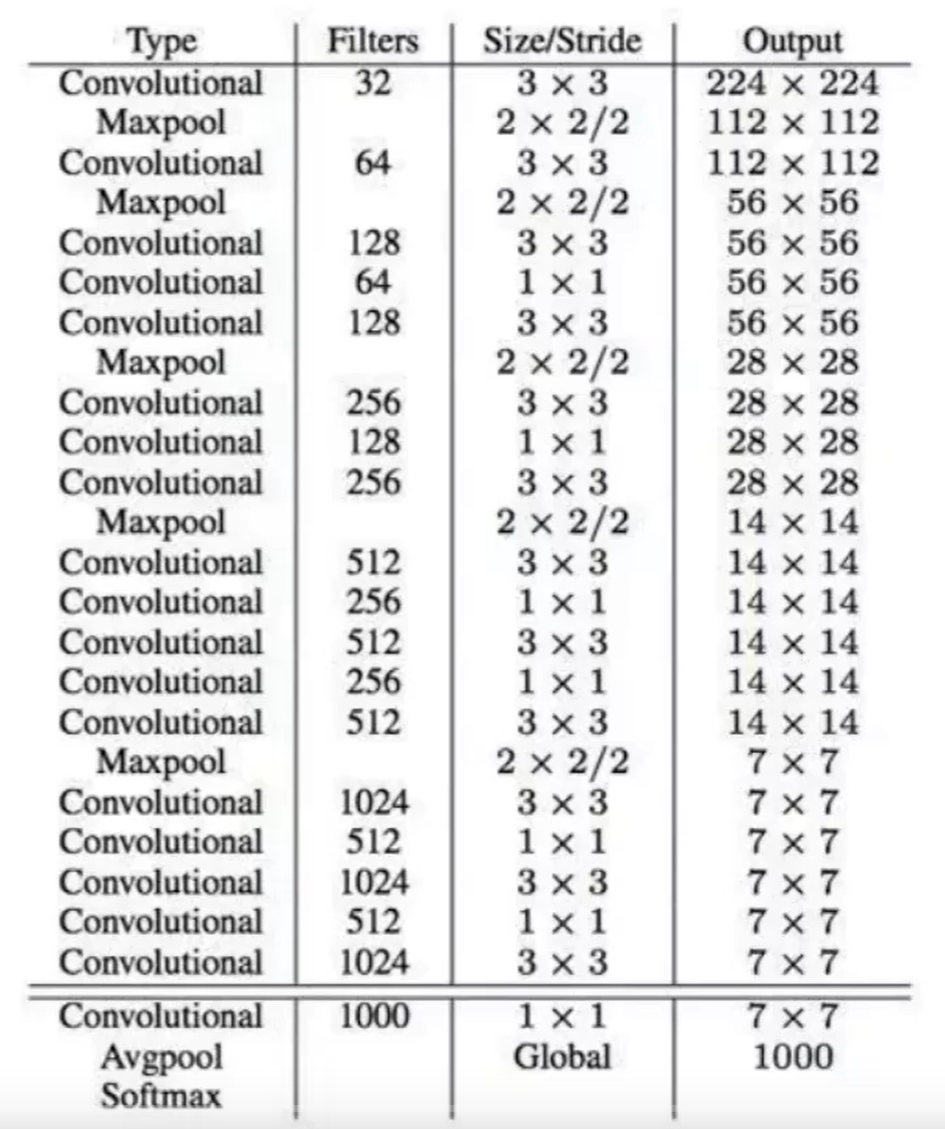
1. 主干网络:Darknet-19
- 设计目标:相比YOLOv1的Darknet-20,减少计算量并保持精度。
- 结构特点:
- 由19个卷积层和5个最大池化层组成,最终通过全局平均池化输出特征。
- 卷积层采用 1×1 和 3×3 交替堆叠,降低参数量(YOLOv1为24个卷积层)。
- 引入 批量归一化(Batch Normalization, BN):所有卷积层后均添加BN,提升收敛速度,减少过拟合。
- 输出特征:输入图像经Darknet-19后,生成 13×13×1024 的特征图(输入尺寸为416×416时)。
2. 检测头与锚框机制(锚框常也被称作先验框)
-
锚框(Anchor Boxes)的引入:
-
YOLOv1问题:直接预测边界框坐标,缺乏先验信息,定位精度低。
-
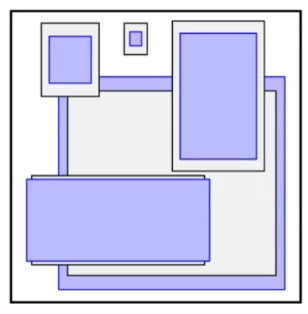
YOLOv2改进:借鉴Faster R-CNN的锚框机制,通过 K-Means聚类 从训练数据中自动学习锚框尺寸,共生成 5种锚框(YOLOv1无锚框)。
-
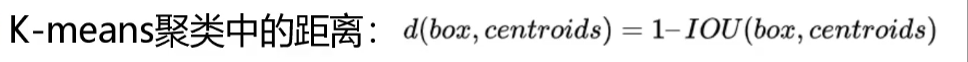
-
优势:
- 召回率从YOLOv1的81%提升至88%,允许模型预测更多边界框。
- 简化网络学习任务(仅需预测锚框的偏移量和尺度,而非绝对坐标)。
-
-
边界框预测:
-
放弃YOLOv1的直接坐标预测,采用 逻辑斯蒂回归 预测锚框的中心坐标偏移量 ( t x , t y ) (t_x, t_y) (tx,ty)、尺度 ( t w , t h ) (t_w, t_h) (tw,th) 和置信度 t o t_o to。
-
坐标公式:

-
优势:通过 σ \sigma σ 函数将中心坐标约束在网格内,避免YOLOv1的坐标预测发散问题。
-
3. 多尺度训练(Multi-Scale Training)
- YOLOv1问题:固定输入尺寸为448×448,部署时缺乏灵活性。
- YOLOv2策略:
- 训练过程中每10 batches随机选择输入尺寸(320×320, 352×352, …, 608×608),步长为32(因下采样5次,32=2^5)。
- 网络自动适应不同尺寸,小尺寸下速度更快(如320×320时帧率更高),大尺寸下精度更高。
- 优势:提升模型泛化能力,无需重新训练即可适应不同硬件环境。
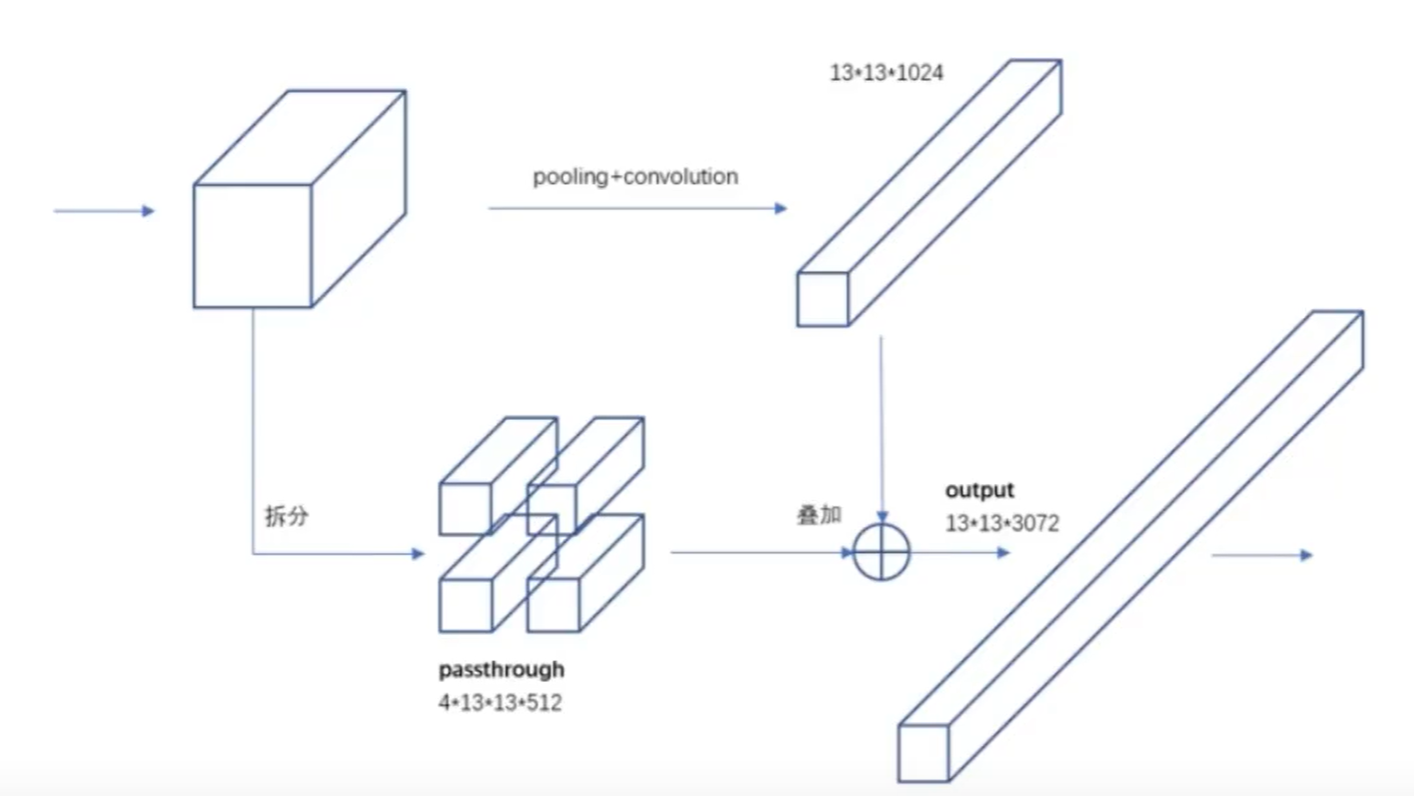
4. 细粒度特征(Fine-Grained Features)与Passthrough层
- YOLOv1问题:仅使用最后一层特征图(13×13),缺乏细粒度信息,小目标检测能力弱。
- YOLOv2改进:
- 在Darknet-19后添加 Passthrough层(类似特征金字塔网络FPN),将前一层26×26×512的特征图通过 通道叠加(Channel Concatenation)与13×13×1024的特征图融合。
- 具体操作:将26×26×512的特征图进行 像素重排列(Pixel Shuffle),转化为13×13×2048的特征图,与深层特征结合,增强小目标检测能力。
5. 更高分辨率的预训练
- YOLOv1预训练:在ImageNet上使用224×224分辨率预训练,检测时提升至448×448,分辨率跳跃大,导致训练初期不稳定。
- YOLOv2预训练:
- 先在ImageNet上用448×448分辨率预训练10 epochs,再微调检测任务。
- 优势:缩小预训练与检测阶段的分辨率差距,提升特征提取能力。
6. 联合训练(Joint Training)与YOLO9000
- 目标:同时训练检测数据(如VOC)和分类数据(如ImageNet),扩展检测类别至9000类。
- 技术实现:
- 分类数据仅含标签无边界框,需设计统一输出格式。
- WordTree结构:将分类标签构建为树状结构(如“狗”包含多个品种),检测时通过树结构合并概率分布。
- 损失函数中,检测样本计算全部损失,分类样本仅计算分类损失。
- 效果:成功检测ImageNet中未标注边界框的类别(如“蝴蝶”),验证了联合训练的有效性。
三、YOLOv2 对比 YOLOv1 的核心改进
| 改进点 | YOLOv1 | YOLOv2 | 效果/原因 |
|---|---|---|---|
| 主干网络 | Darknet-20(24卷积层) | Darknet-19(19卷积层+BN) | 减少计算量,BN提升收敛速度,降低过拟合。 |
| 锚框机制 | 无 | 引入5种K-Means聚类锚框 | 召回率从81%→88%,定位精度提升,模型更易优化。 |
| 边界框预测 | 直接预测绝对坐标 | 预测锚框偏移量+逻辑斯蒂回归 | 坐标约束在网格内,避免发散,提升稳定性。 |
| 多尺度训练 | 固定448×448 | 动态调整输入尺寸(320×320~608×608) | 提升泛化能力,适应不同硬件,兼顾速度与精度。 |
| 细粒度特征融合 | 无 | Passthrough层融合26×26与13×13特征图 | 增强小目标检测能力(小目标在浅层特征中更清晰)。 |
| 预训练分辨率 | 224×224→448×448(跳跃大) | 448×448预训练+微调 | 减少分辨率差距,特征更贴近检测任务。 |
| 批量归一化 | 仅部分层使用 | 所有卷积层后添加BN | 消除Internal Covariate Shift,提升训练稳定性。 |
| 损失函数 | 定位损失权重固定(λ_coord=5) | 可能调整权重或引入锚框置信度损失 | 未明确文档,但锚框机制间接优化了损失函数设计。 |
| 数据增强与正则化 | 随机裁剪、翻转等 | 增强数据增强(如HSV颜色扰动) | 提升模型对颜色、光照变化的鲁棒性。 |
| 检测类别与训练策略 | 仅支持VOC等小数据集 | 联合训练检测与分类数据(YOLO9000) | 扩展至9000类,利用海量分类数据提升泛化能力。 |
| 速度与精度平衡 | mAP@VOC2007约63.4%,FPS≈45(GPU) | mAP@VOC2007提升至78.6%,FPS≈67(GPU) | 精度显著提升,速度因优化结构未下降反升,实现更好的trade-off。 |
四、YOLOv2 性能总结
- 精度:在VOC2007数据集上,mAP从YOLOv1的63.4%提升至78.6%,接近当时领先的Faster R-CNN(78.8%)和SSD(77.2%),但速度更快。
- 速度:在Titan X上,输入416×416时FPS约67,输入608×608时FPS约40,兼顾实时性与高精度。
- 创新意义:
- 首次将锚框机制与YOLO结合,奠定后续YOLO系列基础。
- 多尺度训练、特征融合等策略成为目标检测的通用技术。
- YOLO9000开创“弱监督检测”思路,为大数据场景提供新方向。
五、YOLOv2 的局限性
- 小目标检测:虽引入Passthrough层,但仅融合一层浅层特征,效果有限(后续YOLOv3通过多尺度特征金字塔进一步优化)。
- 锚框数量:仅使用5种锚框,对复杂场景覆盖不足(YOLOv3增加至9种)。
- 正负样本分配:沿用YOLOv1的启发式分配策略,可能导致训练低效(后续版本通过IOU阈值或标签分配算法改进)。
总结
YOLOv2通过锚框机制、多尺度训练、特征融合、BN等一系列改进,在保持实时性的同时显著提升了检测精度,并首次实现了跨数据集的联合训练,为YOLO系列的后续发展(如YOLOv3、v4、v5)奠定了关键基础。其设计思路(如平衡速度与精度、数据增强、特征融合)至今仍被广泛借鉴。
YOLO中的锚框机制(Anchor Boxes)
一、锚框机制的起源与核心思想
锚框(Anchor Boxes) 最早由 Faster R-CNN 提出,用于解决目标检测中边界框预测的多样性问题。YOLO 在 v2版本 中引入锚框机制,显著提升了检测精度(尤其是定位精度)。其核心思想是:
- 在特征图的每个网格(Grid Cell)中预设多个具有不同尺度和比例的边界框(即锚框),作为目标检测的“先验框”。
- 模型通过学习对这些锚框的位置、尺寸进行调整,从而更灵活地预测不同形状的目标。
二、YOLOv2引入锚框的背景与动机
在 YOLOv1 中,每个网格直接预测边界框的绝对坐标(x, y, w, h),存在两大缺陷:
- 定位精度低:直接预测坐标难度大,尤其是对不同尺度的目标泛化能力不足。
- 边界框多样性不足:每个网格仅预测2个边界框,难以覆盖数据集中目标的多种形状(如高瘦、宽扁物体)。
YOLOv2引入锚框的目标:
- 通过预设锚框提供边界框的“先验信息”,降低模型学习难度。
- 增加边界框的多样性,提升召回率(Recall)和定位精度。
三、锚框的生成:K-Means聚类算法
YOLOv2采用 无监督聚类算法 自动确定锚框的尺寸和比例,而非手动设计(如Faster R-CNN),步骤如下:
- 数据准备:使用训练集中所有真实框(Ground Truth Boxes)的宽高作为输入。
- 距离度量:定义聚类的距离函数为 1 - IOU(box, centroid),即锚框与真实框的交并比(IOU)越大,距离越近(传统K-Means使用欧氏距离,不适合边界框尺寸聚类)。
- 聚类过程:
- 预设聚类中心数量
k(YOLOv2默认k=5,YOLOv3扩展为k=9)。 - 通过迭代更新聚类中心,使所有真实框与最近锚框的IOU均值最大化。
- 预设聚类中心数量
- 优势:生成的锚框更贴合数据集的目标分布,提升检测效率。
四、锚框在特征图上的应用
以 YOLOv2 为例(输入图像尺寸为 416×416,输出特征图尺寸为 13×13):
-
网格与锚框的对应关系:
- 每个网格负责预测
k个锚框(YOLOv2中k=5)。 - 每个锚框对应一组预测参数:
(t_x, t_y, t_w, t_h, t_o),分别表示:t_x, t_y:锚框中心坐标的偏移量(相对于网格左上角)。t_w, t_h:锚框宽高的缩放因子。t_o:置信度(Confidence),表示锚框内存在目标的概率。
- 每个网格负责预测
-
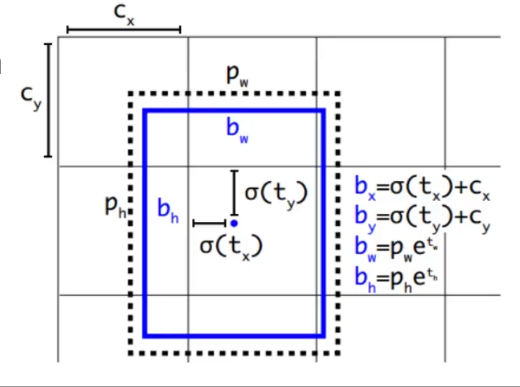
从预测值到真实坐标的转换:
设某网格的左上角坐标为(c_x, c_y),锚框的先验宽高为(p_w, p_h),则预测的边界框坐标计算如下:-
中心坐标:
b x = σ ( t x ) + c x , b y = σ ( t y ) + c y b_x = \sigma(t_x) + c_x, \quad b_y = \sigma(t_y) + c_y bx=σ(tx)+cx,by=σ(ty)+cy
其中,σ为Sigmoid函数,确保b_x, b_y位于当前网格内。 -
宽高:
b w = p w ⋅ e t w , b h = p h ⋅ e t h b_w = p_w \cdot e^{t_w}, \quad b_h = p_h \cdot e^{t_h} bw=pw⋅etw,bh=ph⋅eth通过指数函数允许宽高缩放至任意大小。
-
置信度:
C o n f i d e n c e = σ ( t o ) Confidence = \sigma(t_o) Confidence=σ(to)
表示预测框与真实框的IOU值(训练时)或目标存在的概率(推理时)。
-
五、YOLOv2对比YOLOv1:锚框带来的改进
| 改进点 | YOLOv1 | YOLOv2(引入锚框) |
|---|---|---|
| 边界框预测方式 | 直接预测绝对坐标 (x, y, w, h) | 基于锚框的偏移量预测 (t_x, t_y, t_w, t_h) |
| 每个网格的边界框数量 | 2个 | k=5个(通过聚类生成) |
| 召回率(Recall) | 较低(约81%) | 显著提升(约88%) |
| 定位精度(IOU) | 较低 | 更高(锚框先验提供更优初始值) |
| 全连接层 | 存在(用于预测坐标) | 移除(全卷积结构,支持任意输入尺寸) |
| 输入尺寸 | 固定 448×448 | 调整为 416×416(奇数倍32,确保特征图有单一中心网格,利于检测大目标) |
六、YOLOv3中的锚框机制:多尺度预测
YOLOv3进一步扩展锚框机制,引入 多尺度特征图预测,解决不同尺寸目标的检测问题:
-
三尺度特征图:
- 输入图像尺寸:
608×608,输出特征图尺寸分别为76×76(小目标)、38×38(中目标)、19×19(大目标)。 - 每个尺度对应 3个锚框,共9个锚框(通过聚类生成),分配方式:
- 小目标(
76×76):(10×13), (16×30), (33×23) - 中目标(
38×38):(30×61), (62×45), (59×119) - 大目标(
19×19):(116×90), (156×198), (373×326)
- 小目标(
- 输入图像尺寸:
-
多尺度的优势:
- 小尺度特征图(如
19×19)感受野大,适合检测大目标;大尺度特征图(如76×76)保留更多细节,适合检测小目标。 - 每个尺度的锚框尺寸与目标尺寸匹配,提升各尺度目标的检测精度。
- 小尺度特征图(如
七、锚框机制的训练与损失函数
-
正负样本分配:
- 正样本:与真实框IOU最大的锚框,或IOU超过阈值(如0.5)的锚框(不同实现可能不同)。
- 负样本:与真实框IOU低于阈值且未被选为正样本的锚框。
- 忽略样本:部分实现中,对IOU高但非匹配真实框的锚框不计算损失(如YOLOv3)。
-
损失函数设计:
YOLOv2/v3的损失函数分为三部分:- 坐标损失:预测框与真实框的坐标误差,通常对小目标赋予更高权重(如使用平方根或对数变换)。
- 置信度损失:正样本的置信度接近真实IOU,负样本的置信度接近0,采用二元交叉熵(BCE)损失。
- 类别损失:仅对正样本计算类别概率损失,同样使用BCE或交叉熵损失。
八、锚框机制的优缺点与争议
-
优点:
- 提供边界框先验,降低模型学习难度,提升定位精度。
- 通过聚类适应不同数据集,增强泛化能力。
- 多尺度锚框结合特征金字塔,提升对不同尺寸目标的检测能力。
-
缺点:
- 锚框数量和尺寸需手动或自动确定,对小目标检测仍需优化(如增加小锚框数量)。
- 计算量随锚框数量增加而上升(但YOLO通过轻量级主干网络缓解)。
-
争议与后续发展:
部分无锚框(Anchor-Free)检测器(如CenterNet、YOLOv8-NAS)尝试摒弃锚框,直接预测目标中心点和尺寸,避免锚框设计的复杂性,但锚框机制在YOLO系列中仍为核心技术之一。
九、总结:锚框机制的技术价值
锚框机制是YOLO从v1到v2/v3进化的关键创新,其核心贡献包括:
- 引入先验知识:通过聚类生成的锚框贴合数据分布,提升边界框初始化质量。
- 提升多样性与召回率:每个网格预测多个锚框,覆盖更多目标形状,避免YOLOv1的边界框匮乏问题。
- 多尺度扩展基础:为YOLOv3的多尺度检测提供了框架,结合特征金字塔网络(FPN),成为现代目标检测的标配技术。
通过锚框机制,YOLO在保持速度优势的同时,显著提升了检测精度,奠定了其在实时检测领域的地位。
我们大部分时间都在害怕失败与拒绝,但后悔或许才是最该害怕的事。 —特雷弗·诺亚




)



)










