论文标题:
Noise Modeling in One Hour: Minimizing Preparation Efforts for Self-supervised Low-Light RAW Image Denoising发表日期:
2025年5月作者:
Feiran Li, Haiyang Jiang*, Daisuke Iso发表单位:
Sony Research, Tokyo University原文链接:
https://arxiv.org/pdf/2505.00045开源代码链接:
https://github.com/SonyResearch/raw_image_denoising
引言
在低光环境下拍摄RAW图像时,噪声问题总是令人头疼。传统降噪方法需要大量成对的干净-噪声图像进行训练,而索尼研究院的这项研究提出了一种自监督学习方法,仅需1小时的准备时间就能完成噪声建模,性能还比现有方法提升了0.54dB。这项技术将大大降低低光摄影的门槛,让更多人能拍出清晰的照片。
论文中的方法架构图展示了这个创新的降噪流程:

实验结果对比图显示,该方法在保持图像细节的同时有效去除了噪声:

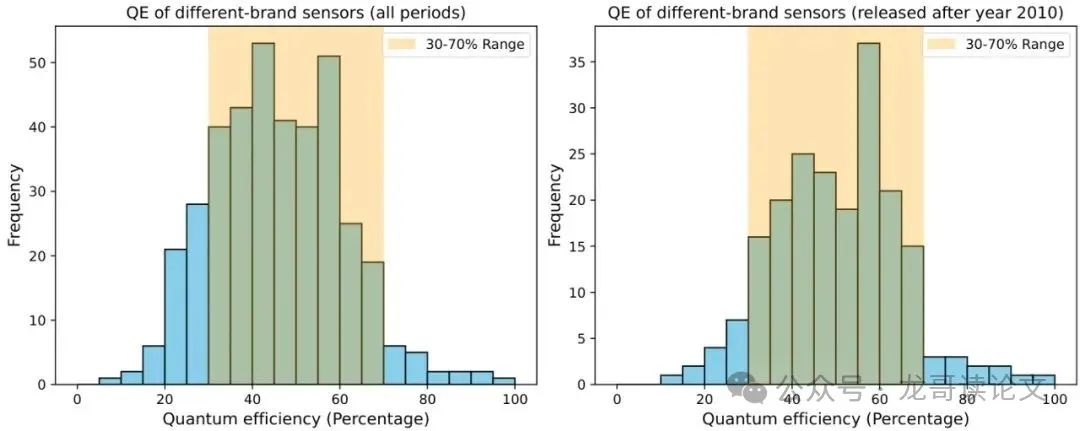
量子效率统计图展示了该方法在传感器特性分析方面的创新:
问题背景及相关工作
在低光环境下拍摄RAW图像时,噪声问题尤为突出。相比标准RGB图像,RAW图像保留了原始噪声特性,具有更高的位深度,因此在降噪方面展现出巨大潜力。然而,基于学习的方法需要大量成对的干净-噪声图像进行训练,这在实践中往往难以实现。
传统噪声合成方法通常需要传感器特定的建模,包括信号依赖和信号无关的噪声合成两个步骤。这些步骤往往需要大量人工干预和复杂流程,如系统增益校准和噪声分析,耗时可达数天。
现有的噪声合成方法主要分为两类:基于统计模型的方法和基于神经网络的方法。前者如ELD方法识别了RAW传感器数据中的四种关键噪声元素;后者如NoiseFlow使用流模型进行噪声建模。但这些方法都存在实现复杂或部署困难的问题。
方法概述
本论文提出了一种简单实用的噪声合成流程,通过详细分析噪声特性和广泛验证现有技术,大大减少了准备时间。该方法的核心在于:
假设量子效率:通过假设量子效率值来合成光子散粒噪声,避免了繁琐的系统增益校准过程
直接采样信号无关噪声:直接从传感器采集暗帧作为信号无关噪声的样本,省去了复杂的噪声分析步骤
暗影校正:通过暗影校正消除时间一致性噪声的影响,提高训练效果
术语解读
RAW图像:直接从相机传感器输出的未经处理的图像数据,保留了更多的原始信息
系统增益K:由量子效率(QE)和模拟增益(AG)组成,K=QE×AG,是噪声建模中的关键参数
暗帧:在完全黑暗条件下拍摄的图像,仅包含传感器自身产生的噪声
光子散粒噪声:由光的量子特性引起,服从泊松分布,是信号依赖噪声的主要成分
核心设计
本方法的整体流程如图2所示:

图2:降噪流程概览。在准备阶段,本文为每个模拟增益收集多个暗帧并计算相应的暗影。为了合成一对训练图像,本文假设一个系统增益K来生成泊松散粒噪声图,并将其与采样得到的暗影校正暗帧一起添加到干净图像中。在推理阶段,给定一个噪声图像,本文从中减去暗影后输入网络。
该方法的核心创新点在于:
基于假设的散粒噪声合成:通过假设量子效率值来估计系统增益K,避免了复杂的校准过程
直接采样信号无关噪声:使用直接从传感器采集的暗帧作为信号无关噪声的样本
暗影校正:通过暗影校正消除时间一致性噪声的影响
论文主体思路
本论文的主要研究思路可以总结如下:
应用场景:低光环境下RAW图像去噪
问题建模:通过噪声合成实现自监督学习,解决成对数据不足的问题
模型Backbone:采用U-Net作为去噪网络,与现有工作保持一致
损失函数:使用L1损失函数
训练数据集:使用合成的噪声-干净图像对
测试数据集:SID、ELD和LRID数据集
训练方法:使用Adam优化器训练1000个epoch,其中400个epoch用于微调
方法优势:准备时间从数天缩短至1小时,性能提升0.54dB
方法缺点:需要已知模拟增益(AG),对普通消费者相机用户可能不友好
主要创新点
基于假设的散粒噪声合成:通过假设量子效率值来估计系统增益K,避免了复杂的校准过程
直接采样信号无关噪声:使用直接从传感器采集的暗帧作为信号无关噪声的样本
暗影校正:通过暗影校正消除时间一致性噪声的影响
简化流程:将准备时间从数天缩短至1小时,同时保持甚至提升去噪性能
核心原理推导
本方法基于以下图像形成模型:
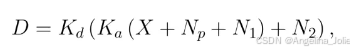
其中Kd是用于亮度调整的数字增益,Ka是应用于模拟信号的系统增益,X是与场景辐照度成正比的实际光子数,Np是信号依赖噪声,N1和N2是两种信号无关噪声。
信号依赖噪声主要来自光子散粒噪声,服从泊松分布:
![]()
系统增益K由量子效率(QE)和模拟增益(AG)组成:
![]()
基于量子效率的物理约束(通常在30%-70%之间),可以安全地假设K值而不需要精确校准。
数据准备及实验设计
实验使用了三个流行的低光RAW图像去噪数据集:
SID:使用Sony-A7S2全画幅单反相机拍摄
ELD:使用另一台Sony-A7S2相机拍摄
LRID:使用Redmi K30智能手机的IMX686传感器拍摄
实验对比了多种方法,包括:
监督方法:使用真实噪声-干净图像对训练
自监督方法:基于干净图像合成噪声
混合方法:使用合成数据进行预训练,真实图像对进行微调
实验结果
在SID和ELD数据集上,本文方法以46.43dB的平均PSNR刷新了自监督降噪记录,甚至超过部分监督学习方法。来看关键数据对比:

图3:不同噪声合成方法的定性对比。所有图像都经过简单的图像信号处理流程转换为sRGB格式以便更好可视化。ELD和SFRN在图像边界处表现出明显的颜色偏差,而本文方法则没有。
在智能手机传感器测试集LRID上,本文方法展现出45.08dB的惊人表现,比现有最佳方法提升0.54dB。更令人惊喜的是,使用仅10个暗帧进行在线校准时的性能损失不超过0.1dB!

图4:不同模型拟合信号无关噪声的分位数-分位数图。左:重采样数据与用于模型拟合数据的对比(即建模精度)。右:重采样数据与未见暗帧数据的对比(即泛化精度)



)

医学图像的配准全过程文档及程序)
基础使用)

中播放)
)








的路径规划(附ROS C++/Python仿真))
