Learning with Less: Knowledge Distillation from Large Language Models via Unlabeled Data
发表:NNACL-Findings 2025
机构:密歇根州立大学
Abstract
在实际的自然语言处理(NLP)应用中,大型语言模型(LLMs)由于在海量数据上进行过广泛训练,展现出极具前景的解决方案。然而,LLMs庞大的模型规模和高计算需求限制了它们在许多实际应用中的可行性,尤其是在需要进一步微调的场景下。为了解决这些限制,实际部署时通常更倾向于使用较小的模型。但这些小模型的训练常受到标注数据稀缺的制约。相比之下,无标签数据通常较为丰富,可以通过利用LLMs生成伪标签(pseudo-labels),用于训练小模型,从而使得这些小模型(学生模型)能够从LLMs(教师模型)中学习知识,同时降低计算成本。
这一过程也带来了一些挑战,例如伪标签可能存在噪声。因此,选择高质量且信息丰富的数据对于提升模型性能和提高数据利用效率至关重要。为了解决这一问题,我们提出了 LLKD(Learning with Less for Knowledge Distillation),一种能够以更少计算资源和更少数据完成从LLMs进行知识蒸馏的方法。
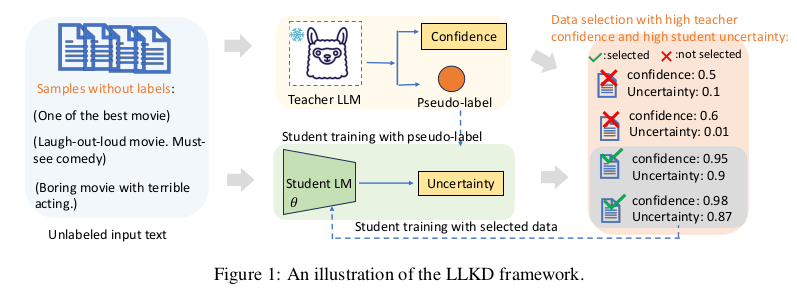
LLKD 是一种自适应样本选择方法,融合了来自教师模型和学生模型的信号。具体来说,它优先选择那些教师模型在标注上表现出高度置信度的样本(意味着标签更可靠),以及学生模型在这些样本上表现出高信息需求的样本(表明这些样本具有挑战性,需要进一步学习)。
我们的大量实验证明,LLKD 在多个数据集上都实现了更高的数据效率和更优的性能表现。
1 Introduction
大型语言模型(LLMs),如 LLaMA(Touvron 等,2023)和 GPT-4(Achiam 等,2023),由于在大规模语料上进行了预训练,获得了广泛的知识,因此在许多实际的自然语言处理(NLP)应用中展现出卓越的语言理解能力(Schopf 等,2022;Thirunavukarasu 等,2023;Zhao 等,2023)。然而,LLMs 的部署需要大量资源,包括高内存需求、较高的计算成本以及推理时更高的延迟,尤其是在需要为特定任务进一步微调时(Shoeybi 等,2019)。为了应对这些限制,研究者和开发者往往更倾向于使用资源需求更低的小型模型(Liu,2019;Devlin,2018;Wang 等,2024)。然而,小模型在能力上不如LLMs(Kaplan 等,2020),通常需要使用带标签的数据进行进一步训练,因为它们通常缺乏捕捉广泛知识的能力。
在缺乏标注数据的指导下,对小模型进行自监督训练可能导致性能欠佳,因为这类模型在泛化到多样化任务方面存在困难,且常常无法有效地学习特定任务所需的特征(Goyal 等,2019)。这一挑战因获取任务相关的标注数据代价高昂而进一步加剧。尽管无标签数据通常更加丰富,但若缺乏适当的标注,便无法直接用于训练模型,从而成为模型训练中的一大挑战。
一种有前景的解决方案是利用LLMs为无标签数据生成伪标签(pseudo-labels),进而用于训练小模型。这种策略使得小模型能够从LLMs中蕴含的广泛知识中获益,同时降低了计算成本。该过程可以被视为一种知识蒸馏方法(Mishra 与 Sundaram,2021;Zhou 等,2023;Kontonis 等,2024;Iliopoulos 等,2022)。然而,这一方法也存在挑战——由LLMs生成的伪标签可能存在噪声或不可靠性,从而可能削弱学生模型的性能。
因此,提高数据效率至关重要——这不仅有助于减轻噪声伪标签的影响,还能确保选取具有代表性的数据样本以实现最优训练效果。一种潜在的解决思路是选择那些不仅伪标签质量高,而且对学生模型而言具有信息价值的数据样本。然而,由于学生模型在训练过程中会不断更新,持续识别对其具有学习价值的知识仍然是一项挑战。
已有一些研究提出了在知识蒸馏过程中进行数据选择的方法(Mishra 与 Sundaram,2021;Zhou 等,2023;Li 等,2021)。但多数方法(如 Zhou 等,2023;Li 等,2021)依赖于真实标签的数据集,并未考虑伪标签样本可能存在噪声的问题,从而导致训练效果不佳。而部分方法虽然针对无标签数据(如 Kontonis 等,2024;Iliopoulos 等,2022),却往往忽视了学生模型的学习进度,或者未能兼顾数据利用效率。
因此,我们提出一种方法,旨在让学生模型从最有价值的数据中学习,并通过减少所需训练数据量来提升数据效率。为了解决上述挑战,我们提出了 LLKD,即“以更少计算资源和更少数据从LLMs进行知识蒸馏的学习方法”(Learning with Less for Knowledge Distillation)。这是一种在每个训练步骤中根据学生模型动态学习状态进行自适应样本选择的方法。
具体而言,我们优先选择以下两类样本:(1)教师模型在标注时表现出高度置信度的样本,代表伪标签具有较高可靠性(Mishra 与 Sundaram,2021);(2)学生模型在这些样本上表现出高度不确定性的样本,表明这些是其仍需进一步学习的难点样本(Zhou 等,2023)。我们在每个训练步骤中基于教师模型置信度和学生模型不确定性设计了两种阈值,并从两种视角出发选取符合标准的重叠样本。该样本选择策略促进了从LLM向小模型的高效知识转移,确保用于训练的都是最具信息量的样本,同时减少所需数据量,从而提升数据利用效率。
我们将 LLKD 应用于一个基础的NLP任务——文本分类,并在多个数据集上进行了全面评估。实验结果表明,LLKD 显著提升了模型性能,在数据利用效率方面也取得了更优表现。
我们的贡献总结如下:
1)我们提出了一种基于无标签数据的知识蒸馏方法,该方法所需计算资源更少;
2)我们提出了一个动态的数据选择方法 LLKD,能够识别高质量样本,从而提高数据利用效率;
3)大量实验证明,LLKD 在文本分类任务中能实现更优性能和更高数据效率。
2 Related Work
Knowledge Distillation(知识蒸馏)
知识蒸馏(Mishra 和 Sundaram, 2021;Zhou 等, 2023;Xu 等, 2023;Li 等, 2021;Kontonis 等, 2024)被广泛用于将知识从一个庞大的教师模型传递给一个轻量级的学生模型。大多数传统方法集中于带有真实标签的数据集,并且一些方法在此过程中探索了数据选择策略。例如,Mishra 和 Sundaram(2021)提出了一种基于训练轮次的阈值方法,用于为学生模型选择困难样本。类似地,Li 等(2021)和 Xu 等(2023)通过设置固定的采样比例,选择那些学生模型不确定性较高的样本。Zhou 等(2023)引入了一种基于强化学习的选择器,以不同方式衡量学生模型的不确定性。然而,这些方法大多依赖真实标签,且未能解决教师模型所生成的伪标签可能存在噪声的问题。虽然部分方法关注于无标签数据(Lang 等, 2022;Dehghani 等, 2018),但它们通常忽视了数据效率,或未考虑学生模型的动态变化以识别对学生有价值的样本。例如,Kontonis 等(2024)通过将学生模型的软标签与去噪后的教师标签结合来生成新的软标签;而 Iliopoulos 等(2022)则通过对学生模型的损失函数重新加权来模拟无噪声伪标签下的训练损失。
Thresholding Methods(阈值方法)
在面对大量无标签和噪声数据的分类任务中,已有多种基于置信度的阈值方法被提出(Zhang 等, 2021;Sohn 等, 2020;Wang 等, 2023;Chen 等, 2023),以优先选择置信度高的样本。例如,FlexMatch(Zhang 等, 2021)采用课程学习策略,依据已学习样本的数量为每个类别灵活调整阈值;FreeMatch(Wang 等, 2023)和 SoftMatch(Chen 等, 2023)使用基于置信度的阈值,其中 FreeMatch 同时考虑全局和类别层面的学习状态,而 SoftMatch 则使用高斯函数对损失函数进行加权。然而,这些方法通常依赖于有限的有标签数据,因此在自训练场景下可能表现不佳。
Unsupervised Text Classification(无监督文本分类)
无监督文本分类的目标是在没有标签数据的情况下对文本进行分类。一种常见的方法是基于相似度的技术(Abdullahi 等, 2024;Schopf 等, 2022;Yin 等, 2019),这些方法为输入文本和标签生成嵌入向量,然后基于相似度将文本与标签进行匹配。这类方法无需训练数据或训练过程。例如,Abdullahi 等(2024)建议用 Wikipedia 数据增强输入文本;而 Schopf 等(2022)使用 lbl2TransformerVec 来生成嵌入表示。然而,如果缺乏特定任务的领域知识,这些方法通常表现较差。虽然一些方法(如 Gretz 等, 2023)提出先在其他领域的数据集上进行预训练,再将模型应用于当前任务进行预测,但这些预训练模型通常因法律或隐私问题而无法公开获取。
3 Method
3.1 Notations

3.2 Teacher Model

3.3 Student Model

3.4 Data Selection


4 Experiment
在本节中,我们将进行全面的实验以验证 LLKD 的性能。我们首先介绍实验设置,随后呈现结果及其分析。
4.1 experimental settings
数据集。我们使用了来自不同领域的五个数据集:
-
PubMed-RCT-20k(Dernoncourt 和 Lee,2017),提取自医学论文;
-
Yahoo! Answers(Zhang 等,2015),来自 Yahoo! Answers 平台的问题与回答对集合;
-
Emotions(Saravia 等,2018),包含被分类为六种基本情感的推特消息;
-
Arxiv-10(Farhangi 等,2022),由 ArXiv 论文构建;
-
BiosBias(De-Arteaga 等,2019),一个文本传记数据集,旨在预测职业身份。
更多细节见附录 A.3 节。
基线方法。我们将方法与四组基线方法进行比较:
-
阈值方法,如 FreeMatch(Wang 等,2023),使用自适应阈值选择学生模型高置信度样本;SoftMatch(Chen 等,2023),对学生置信度更高的样本赋予更大权重。
-
知识蒸馏方法,重点在于基于教师模型过滤噪声伪标签,或基于学生模型选择信息量大的样本。第一类中,我们评估 CCKD_L(Mishra 和 Sundaram,2021),根据教师概率加权样本;Entropy Score(Lang 等,2022),选择教师熵最低(即教师置信度最高)的样本。第二类中,包含 CCKD_T+Reg(Mishra 和 Sundaram,2021),使用阈值选择对学生具有挑战性的样本;UNIXKD(Xu 等,2023),选择学生不确定性最高的样本。
-
无监督文本分类方法:Lbl2TransformerVec(Schopf 等,2022),基于输入文本与标签词的嵌入相似度进行标签预测。
-
基础基线方法:Random,从每个批次随机选择样本子集;Teacher,使用教师模型结合少量示例直接生成预测;Teacher-ZS,使用教师模型不带示例(零样本)生成预测;No_DS,学生模型在无数据选择的情况下训练。
实现细节。教师模型采用 LLaMA(Touvron 等,2023),一款在多种应用中表现出色的开源大语言模型。学生模型采用 RoBERTa(Liu,2019)。为确保公平比较,所有基线模型均使用与我们模型相同的伪标签,且除 Lbl2TransformerVec 外,基线模型均以 RoBERTa 作为骨干模型。文本分类任务的模型性能使用准确率(ACC)和宏观 F1 分数进行评估,数据效率则根据总训练样本数进行衡量。参数分析见第 4.7 节。更多细节请参见附录 A.1 和 A.4 节。
4.2 Classification Performance Comparison
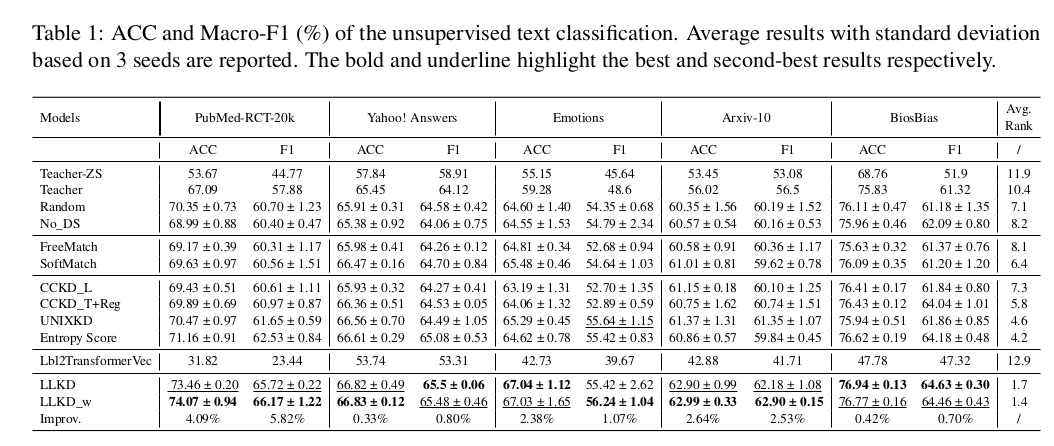
我们在表1中展示了分类性能对比结果,其中"LLKD_w"表示采用公式(9)加权损失函数的版本。同时,我们计算了各方法在所有数据集和评估指标上的平均排名,并以"Improv."标注最优方法相对于最佳基线的相对提升幅度。由于Lbl2TransformerVec是基于相似度的无训练方法,其性能无标准差。
主要发现如下:
-
如表1所示,我们的模型在所有基线方法中表现最优,在PubMed-RCT-20k数据集上的F1分数相对提升达5.82%。加权版本普遍表现更优,说明通过教师置信度和学生不确定性对选定样本进行加权能进一步提升模型性能。
-
直接使用教师模型(Teacher)的表现通常逊于我们的方法及其他基于伪标签微调学生模型的基线(Lbl2TransformerVec除外)。这表明学生模型不仅能有效从教师处学习,还能取得更优结果。这些发现证明:经过适当调整,学生模型可以在保持更低计算成本的同时实现更优性能。
-
采用少样本示例的教师模型(Teacher)普遍优于零样本版本(Teacher-ZS),验证了融入少样本示例的有效性。
-
基于相似度的方法Lbl2TransformerVec表现最弱,说明仅依赖文本-标签相似度难以实现有效的分类。
4.3 Ablation Study
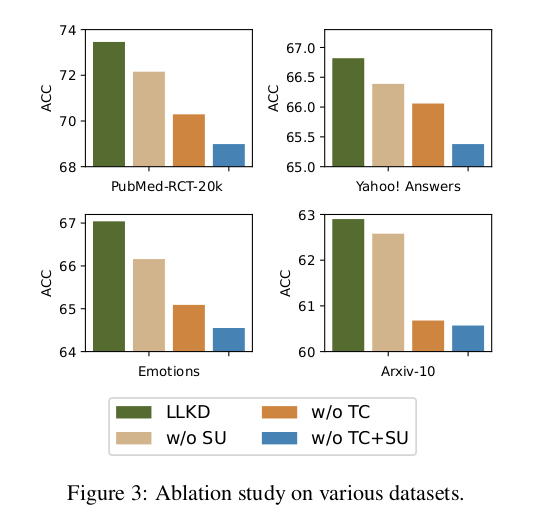
在本小节中,我们进行了消融实验,以评估我们方法中各个组件的有效性,包括数据选择、教师置信度和学生不确定性。结果如图 3 所示。我们使用 “w/o TC” 表示未使用教师置信度进行样本选择的模型,此时仅依赖学生不确定性阈值进行筛选;类似地,“w/o SU” 表示未使用学生不确定性阈值的模型;“w/o TC+SU” 表示完全不进行数据选择的模型。需要注意的是,“w/o TC+SU” 与表 1 中的 No_DS 模型是相同的。图中清晰地表明,我们的模型在所有数据集上均明显优于各个去除组件的版本,突显了各个组件的重要性。尤其值得注意的是,在完全不进行数据选择的情况下,模型表现最差,进一步验证了我们数据选择策略在提升模型性能方面的关键作用。
此外,为评估在标注数据有限的情况下使用未标注数据的必要性,我们进行了进一步分析,详见附录 A.5。表 6 的结果表明,仅使用少量真实标签训练的模型,其性能远不如使用未标注数据训练的 LLKD 模型。这一发现强调了在标注数据有限时,利用未标注数据的重要性。
4.4 Data Efficiency
在本小节中,我们通过展示每轮训练中模型所看到的样本总数及其占原始总样本数的百分比,来评估数据效率。例如,Arxiv-10 的原始训练集大小为 79,790,我们将训练轮数设置为 6,因此在不进行任何数据选择的情况下,学生模型总共会看到 79,790 × 6 = 479,820 个样本。所有方法在原始样本总数上是一致的。
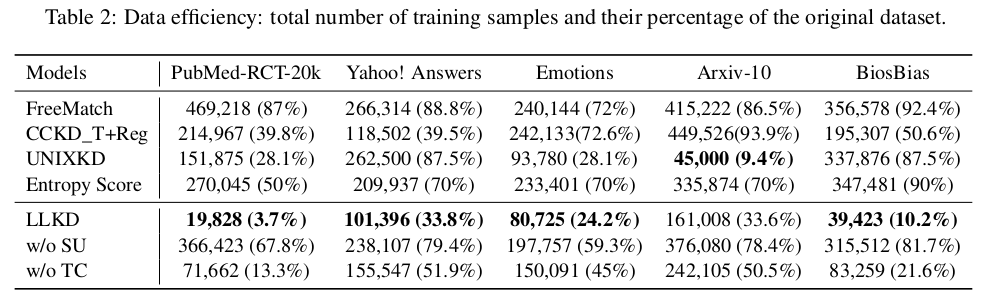
各种数据选择方法的结果如表 2 所示。我们还包含了各个消融版本的结果,以更深入地分析我们的方法。对于采用固定选择比例的 UNIXKD 和 Entropy Score,我们在比例 {10%, 30%, 50%, 70%, 90%} 上进行了实验,并选择验证集性能最好的比例。由于 SoftMatch 和 CCKD_L 是对样本进行加权而非筛选,它们使用了全部的原始样本集合。
总体而言,结果表明我们的方法在效果和数据效率上始终优于其他方法。在大多数情况下,我们的方法只需要选择不到 25% 的训练样本。值得注意的是,在 PubMed-RCT-20k 数据集上,我们仅使用了 3.7% 的训练样本,便实现了相对提升 5.82% 的显著性能改进,如表 1 所示。尽管在 Arxiv-10 数据集上,UNIXKD 使用了更少的数据进行训练,但我们的方法在性能上仍有较大提升,说明 UNIXKD 未能选择到足够有信息量的样本。


)







)








