一、《基于区域提议网络的实时目标检测方法》
1.1、基本信息
-
标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
-
作者:任少卿(中国科学技术大学、微软研究院)、何凯明(微软研究院)、Ross Girshick(Facebook AI Research)、孙剑(微软研究院)
-
发表时间:2015年(会议版本为NIPS 2015)
-
代码开源:提供MATLAB和Python实现
MATLAB开源地址:
ShaoqingRen/faster_rcnn: Faster R-CNN
Python开源地址
rbgirshick/py-faster-rcnn: Faster R-CNN (Python implementation) -- see https://github.com/ShaoqingRen/faster_rcnn for the official MATLAB version

1.2、主要内容
核心创新:
区域建议网络(RPN, Region Proposal Network):
一种全卷积网络(FCN),直接在卷积特征图上生成高质量的区域建议,与检测网络共享计算,显著降低时间开销。
引入锚点(anchors)机制:通过预定义的多个尺度和宽高比的参考框(如3种尺度×3种宽高比,共9种锚点),覆盖不同物体大小和形状,避免传统图像金字塔或滤波器金字塔的计算冗余。
网络架构:
端到端训练:RPN与Fast R-CNN共享卷积层,通过交替训练策略(4步训练)联合优化:
训练RPN生成建议;
用RPN建议训练Fast R-CNN;
固定共享层,微调RPN;
固定共享层,微调Fast R-CNN。
多任务损失函数:结合分类损失(物体/非物体)和回归损失(边界框修正)。
性能优势:
速度:VGG-16模型在GPU上达到5帧/秒(包括所有步骤),ZF模型达17帧/秒。
精度:在PASCAL VOC 2007/2012、MS COCO等数据集上取得当时最优结果(如VOC 2007测试集mAP 73.2%)。
1.3、作用影响
技术突破:
首次实现端到端的实时级物体检测框架,解决了区域建议的计算瓶颈问题。
提出锚点机制和共享卷积特征设计,成为后续检测模型(如Mask R-CNN、YOLO系列)的重要参考。
竞赛与应用:
ILSVRC & COCO 2015:作为基础模型助力多项竞赛夺冠(检测、定位、分割等)。
工业应用:被Pinterest等公司用于推荐系统,提升用户交互效率。
学术影响:
推动了基于深度学习的物体检测研究,启发了3D检测、实例分割、图像描述等方向的工作。结合更深的网络(如ResNet-101)后,性能进一步提升(COCO数据集mAP达59.0%)。
开源贡献:
公开的代码和预训练模型成为学术界和工业界的基准工具,加速了后续研究的迭代与优化。
原论文地址:
[1506.01497] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
二、Faster R-CNN
与Fast R-CNN的区别
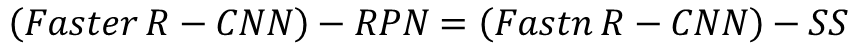
由Shaoqing Ren, Kaiming He, Ross B. Girshick和Jian Sun在2015年提出 的,它是Fast R-CNN的改进版本。 其主要创新在于引入了区域建议网络 (Region Proposal Network, RPN),使得整个目标检测过程能够在一个 神经网络中完成,从而大幅提高了检测效率和准确性。
backbone同样使用VGGNet-16。

最先进的目标检测网络依赖于区域建议算法来假设目标位置。SPPnet [1] 和 Fast R-CNN [2] 等进展减少了这些检测网络的运行时间,但区域建议计算却成为瓶颈。本文提出一种区域建议网络(Region Proposal Network, RPN),该网络与检测网络共享全图像卷积特征,从而实现近乎零成本生成区域建议。RPN 是一种全卷积网络,可在每个位置同时预测目标边界和目标性分数(objectness score)。通过端到端训练,RPN 能够生成高质量区域建议,供 Fast R-CNN 进行检测。我们进一步将 RPN 和 Fast R-CNN 合并为一个网络(共享卷积特征),即用神经网络的“注意力”机制术语来说,RPN 模块告诉统一网络需要关注的位置。对于极深的 VGG-16 模型 [3],我们的检测系统在 GPU 上以 5 帧/秒的帧率运行(包含所有步骤),同时在 PASCAL VOC 2007、2012 和 MS COCO 数据集上仅需每图 300 个建议即可达到最优检测精度。在 ILSVRC 和 COCO 2015 竞赛中,Faster R-CNN 和 RPN 是多个赛道第一名方案的基础。代码已开源。
关键词:目标检测,区域建议,卷积神经网络。
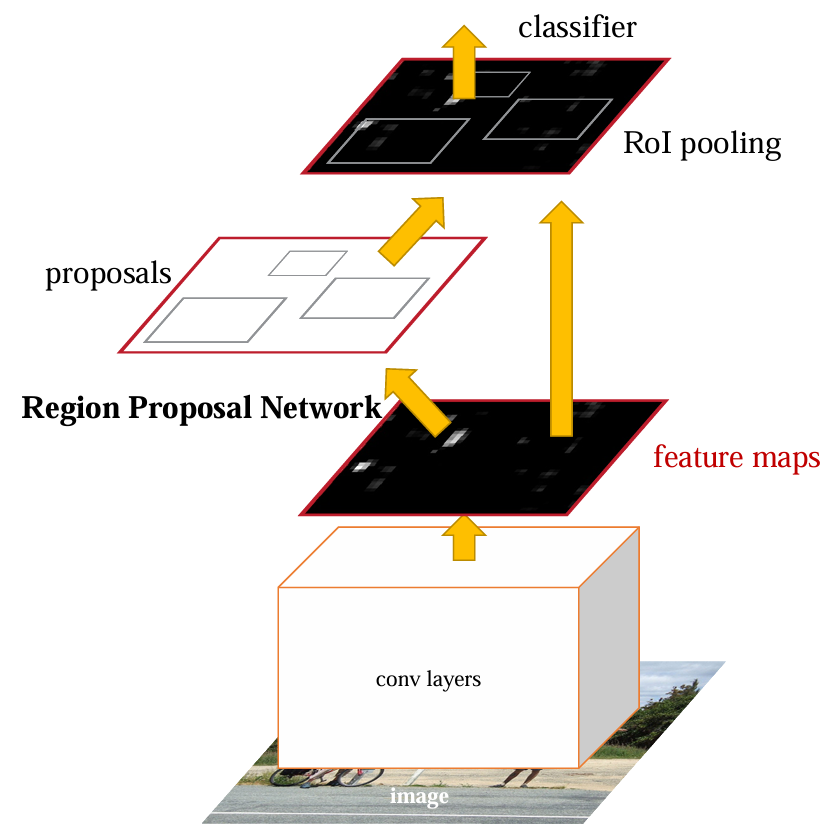
2.1、Faster R-CNN的架构
Faster R-CNN的整体架构包括以下几个主要部分:
1. 卷积神经网络(CNN):将图片输入CNN得到输入图像的特征图。
2. 区域建议网络(RPN):生成候选区域(Region Proposals)。
3. RoI Pooling层:将RPN生成的候选区域映射到特征图上,并通过池化 操作得到固定尺寸的特征。
4. 分类和回归网络:对RoI Pooling层输出的特征进行分类和边界框回归。
2.2、实现流程
特征提取
区域建议网络(RPN)
候选区域的筛选
RoI Pooling
分类和回归
特征提取
输入图像首先通过一个预训练的卷积神经网络(如VGG-16)来提取特征 图。这部分和Fast R-CNN相同,通常称为backbone。
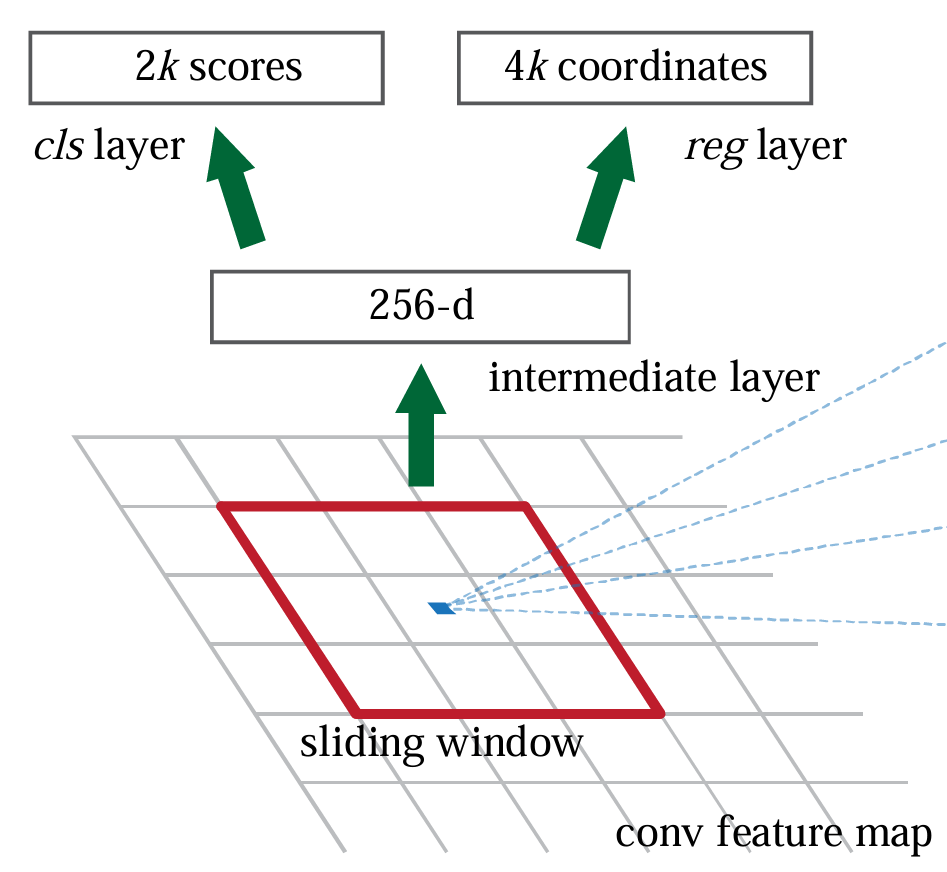
区域建议网络(RPN)
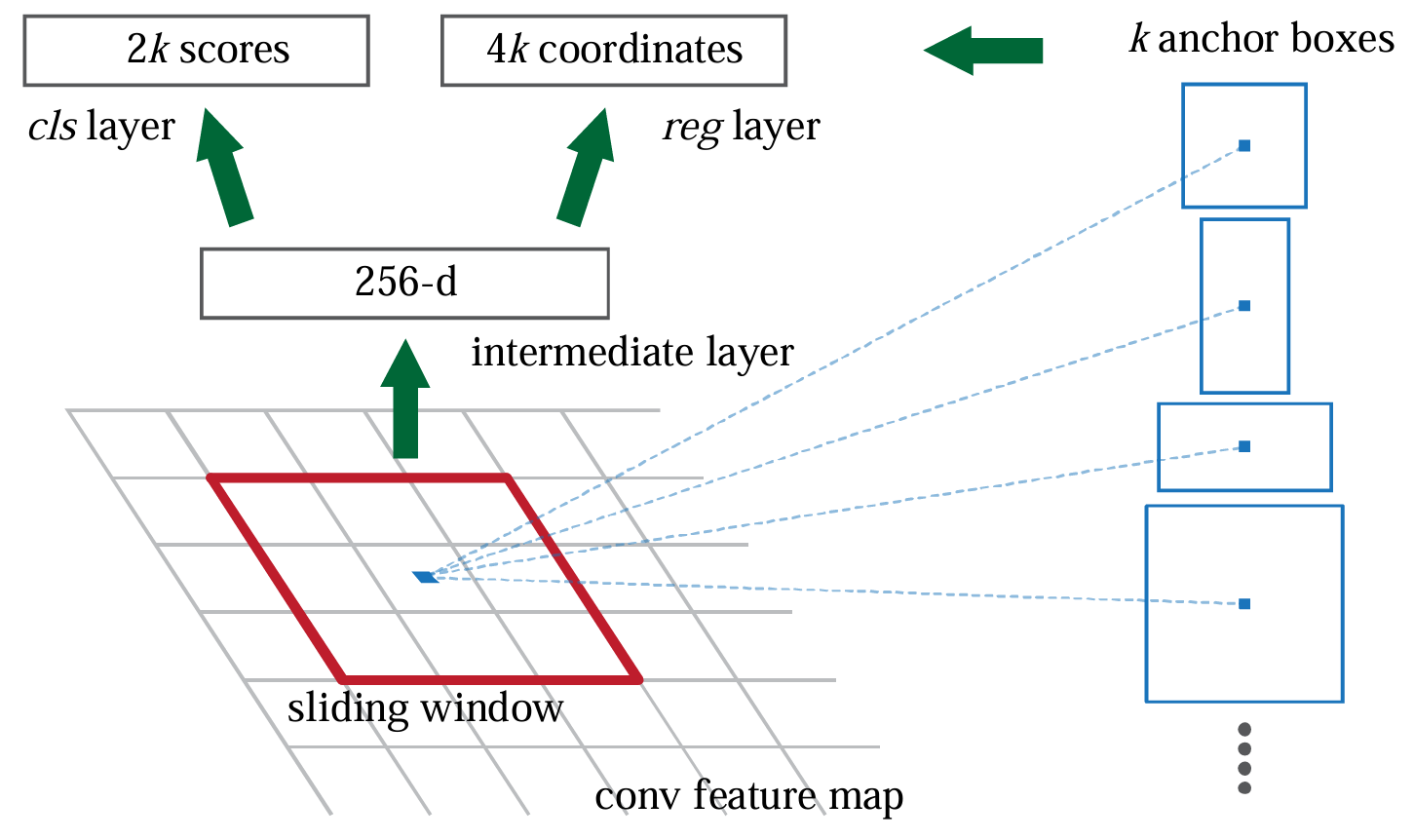
上图中:k是anchor boxes个数,2k是分类算法的两个概率分数(前景和 背景),4k是每个anchor的边界框回归参数,256-d是256 Dimension, 即2013年AlexNet优化ZF的最后一层卷积的通道数,2014年的VGGNet是 512-d。
RPN是Faster R-CNN的核心创新部分。它在特征图上滑动一个小的网络窗 口,以生成候选区域。具体步骤如下:
滑动窗口:在特征图上使用一个3x3的滑动窗口,生成一个256-d的特 征图。
锚框(Anchor Boxes):每个滑动窗口中心点生成一组锚框(anchor boxes),这些锚框具有不同的尺度和纵横比。
回归和分类:对于每个锚框,RPN输出两个预测:
一个是该锚框是目标的概率(背景/前景)。
另一个是锚框的调整参数(回归偏移量)。
滑动窗口
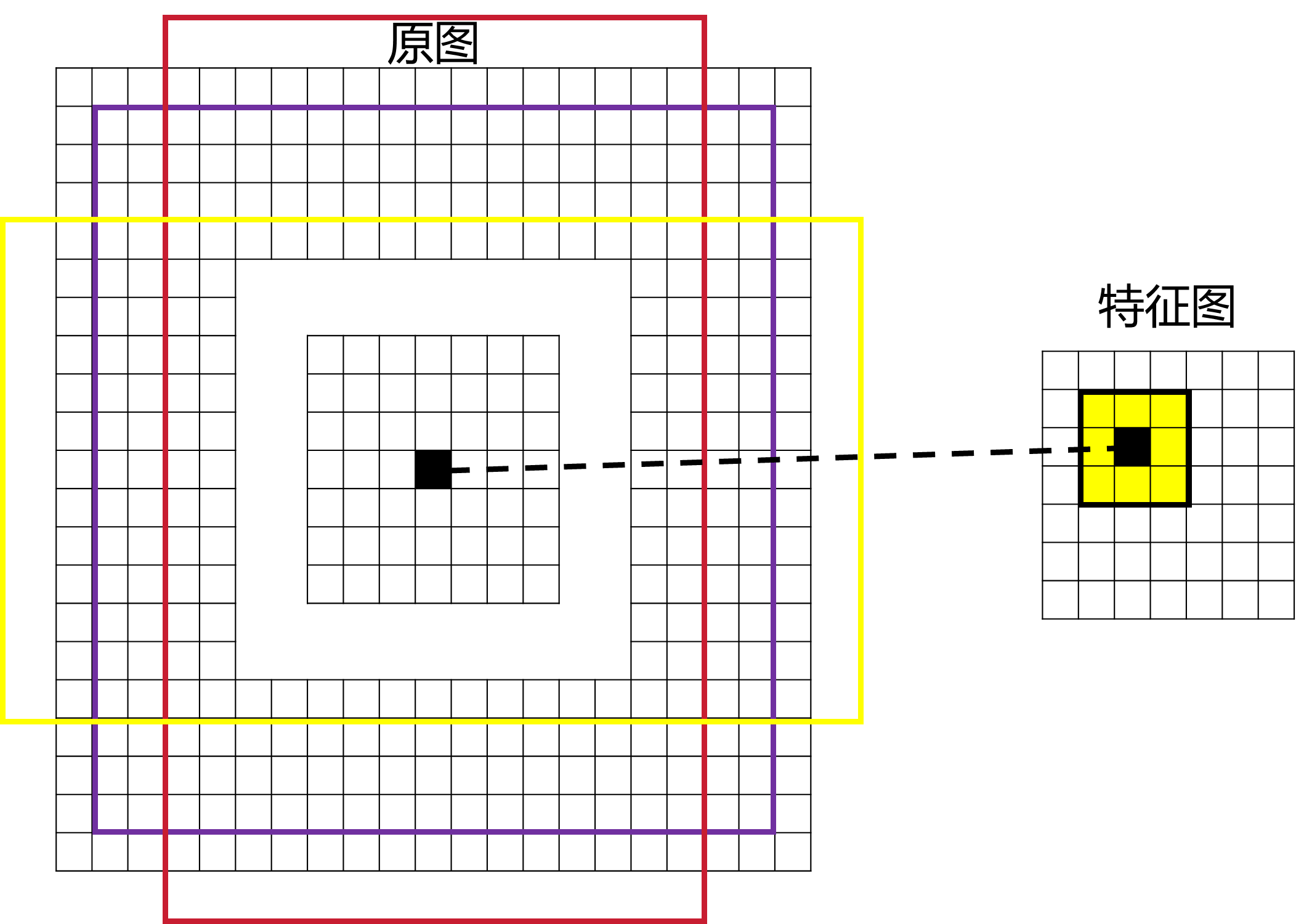
在特征图上用3x3的滑动窗口进行滑动,每滑动到一个地方,就对应原图的 一个中心点的位置。
如何将特征图对应中心点的位置呢?
答:原图的宽度/特征图的宽度取整,得到x轴缩放比例,那么特征图 上x轴第三个位置的黑色中心点对应原图上x轴的3*缩放比例。高度(y 轴)同理。
以原图为中心点计算k个anchor Boxes。
锚框(Anchor Boxes)
每个滑动窗口中心点生成一组锚框(anchor boxes),这些锚框具有不同 的长宽尺度(128像素,256像素,512像素)和纵横比(1:1,2:1,1:2) 共九个,如上图与下图显示了其中三个。
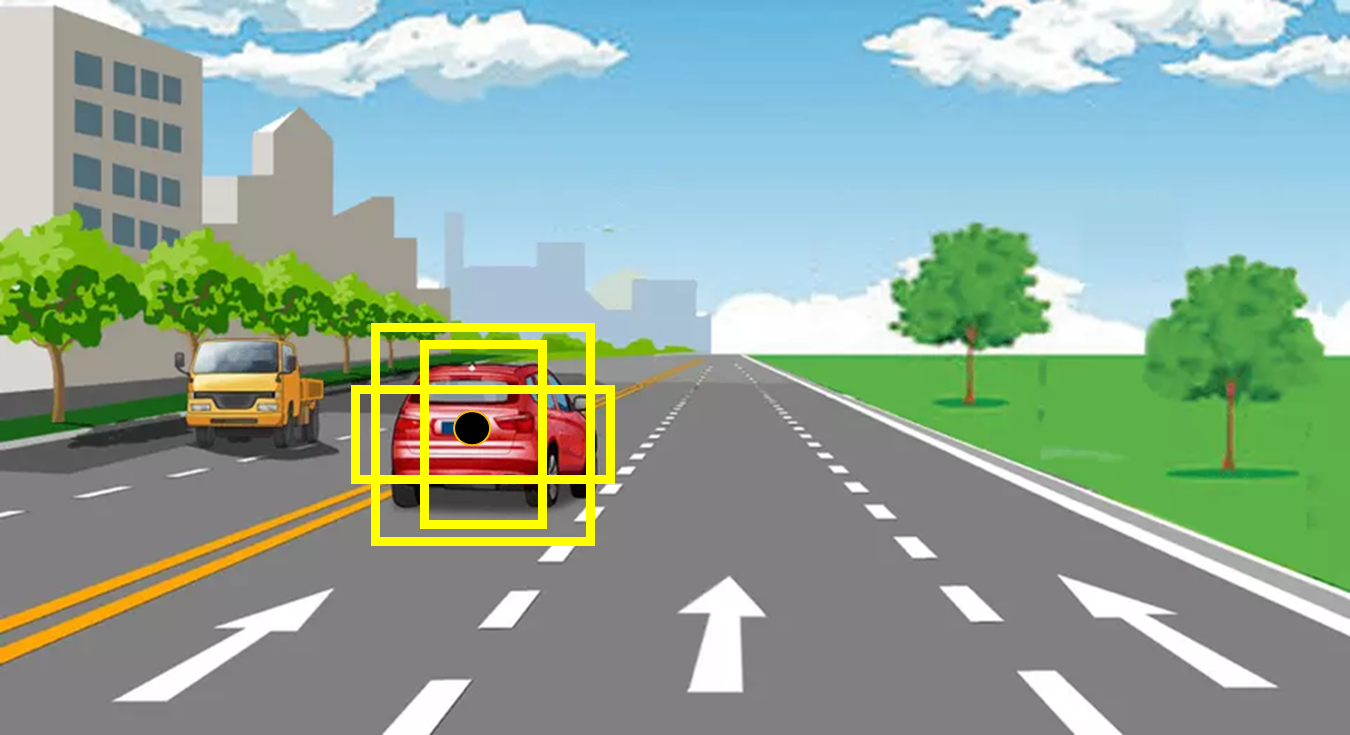
回归和分类
--------------------------------------------------------------------------------------------------------------------------------
感受野
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神 经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域 即该元素的感受野。
卷积神经网络中,越深层的神经元看到的输入区域越大,如下图所示,卷积核kernel size 均为3×3,stride均为1,绿色标记的是Layer2每个神经元看到的区域,黄色标记 的是Layer3 看到的区域,具体地,Layer2每个神经元可看到Layer1上3×3 大小的区 域,Layer3 每个神经元看到Layer2 上3×3 大小的区域,该区域可以又看到Layer1上 5×5 大小的区域。
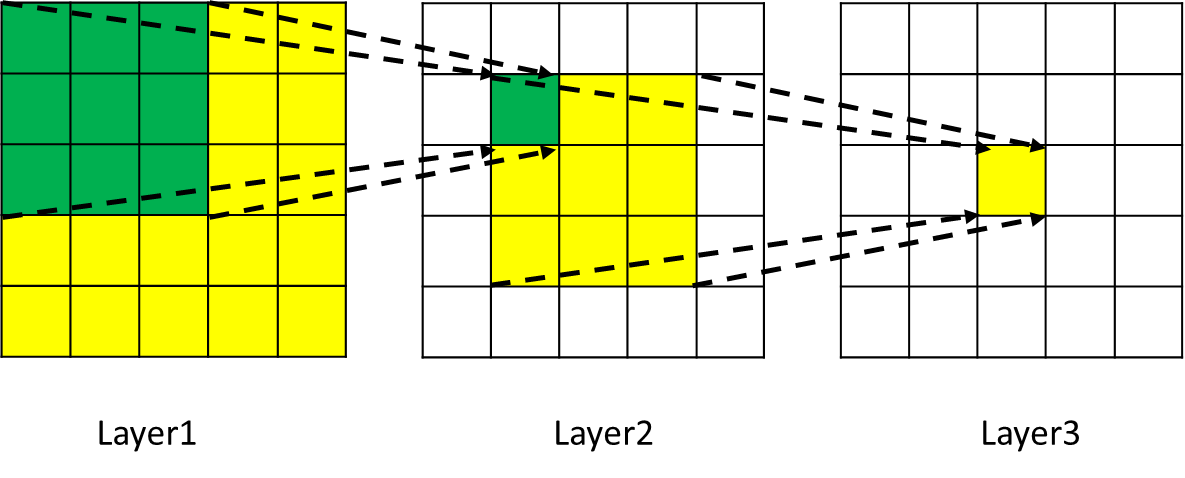
所以,感受野是个相对概念,某层feature map上的元素看到前面不同层上的区域范 围是不同的,通常在不特殊指定的情况下,感受野指的是看到输入图像上的区域。
--------------------------------------------------------------------------------------------------------------------------------
Anchor Box
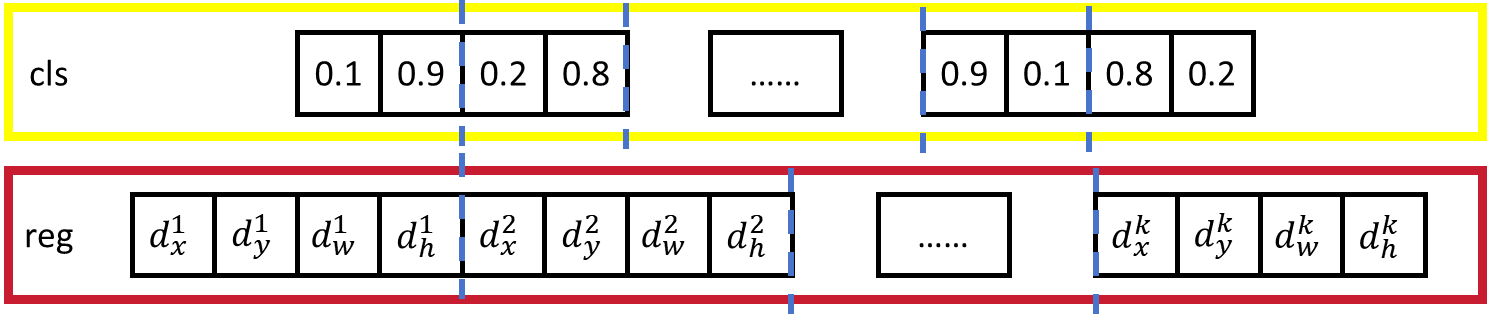
Anchor Box中可能包含前景,也可能不包含前景,所以2k scores意味着2 个分数概率,每2个为一组对应一个Anchor Box,前一个为背景的概率, 后一个为前景的概率,这里前景并不判断它是什么(例如:person、car 等),只看是否包含前景,每个滑动窗口有18个Anchor Boxes。
4k coordinates意味着4个边界框回归参数,每4个为一组对应一个Anchor Box,每个滑动窗口有36个Anchor Boxes。
感受野与Anchor Box的关系:
他们没有直接的关系,在AlexNet的改进版本ZF中,输出的3x3的 窗口对应的原图上的感受野为171;在VGGNet中,输出的3x3的窗口 对应的原图上的感受野为228。
为什么小的感受野可以预测更大的(256或者512)目标的边界框?
作者的文章中提到:“We note that our algorithm allows predictions that are larger than the underlying receptive field. Such predictions are not impossible—one may still roughly infer the extent of an object if only the middle of the object is visible.”, 即:我们注意到,我们的算法允许比潜在感受野更大的预测。这样的 预测并非不可能——如果只有物体的中间可见,人们仍然可以大致推 断出物体的范围。也就是说:当我们看到物体的一部分时,就大致可 以判断物体的范围了,实际上表现出来的也是这个结论。
正负样本
一张图上有上万个Anchor Box,随机抽取256个Anchor Box去训练,这 256中正负样本比例是1:1,如果正样本不够128个,那么剩下的就是256 正样本=负样本,即如果只有100个正样本,那么就用156的负样本,保证 整体数量256。
正样本选择方式:
Anchor Box与GT BOX的IoU大于0.7即为正样本。
Anchor Box与GT BOX的IoU最大的那个即为正样本。
负样本选择方式:
Anchor Box与GT BOX的IoU小于0.3即为负样本。
不是正样本和负样本的其它Anchor Box,丢弃。
RPN的损失函数

2.3、分类损失

但是需要注意的是:二分类交叉熵损失只需要一个x就可以得到二分类的结 果,多分类的交叉熵损失需要两个x才可以得到二分类结果,从论文中看, scores是2k个,也就意味这论文使用的是多分类交叉熵,二分类交叉熵只 需要k个即可。但是这个不影响结果,该分还是能分开的。
2.4、回归损失


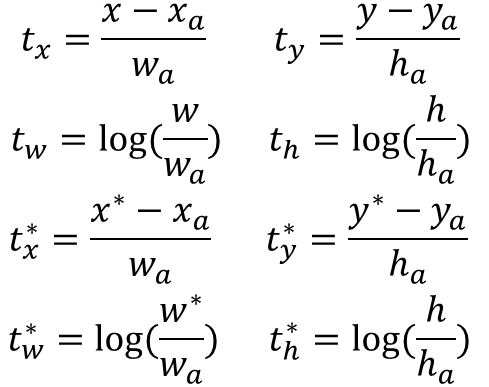
候选区域的筛选
RPN生成大量的候选区域,通过非极大值抑制(NMS)和去除低得分候选 区域的方法,筛选出一部分高质量的候选区域。
RoI Pooling
将筛选出的候选区域映射到特征图上,通过RoI Pooling层将不同大小的候 选区域变换为固定大小的特征向量 。
分类和回归
最后,经过RoI Pooling层的特征向量通过全连接层进行分类(确定目标类 别)和回归(调整候选框)。这里的分类和回归与Fast R-CNN中使用的相同。
三、训练
正常情况下,应该将RPN网络的损失和Fast R-CNN中的损失加起来,然后 一起进行反向传播。
原论文中采用分别训练RPN以及Fast R-CNN的方法
1. 利用lmageNet预训练分类模型初始化前置卷积网络层参数,并开始单 独训练RPN网络参数;
2. 固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训 练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议 框去训练FastRCNN网络参数。
3. 固定利用FastRCNN训练好的前置卷积网络层参数,去微调RPN网络独 有的卷积层以及全连接层参数。
4. 同样保持固定前置卷积网络层参数,去微调FastRCNN网络的全连接层 参数。最后RPN网络与FastRCNN网络共享前置卷积网络层参数,构成 一个统一网络。









)






-并建立socket连接发送和接收报文实例)


