目录
一、正则表达简介
二、REGEXP_LIKE(x,'匹配项')
三、REGEXP_INSTR
四、REGEXP_SUBSTR
五、REGEXP_REPLACE
一、正则表达简介
相关网址:
https://cloud.tencent.com/developer/article/1456428
https://www.cnblogs.com/lxl57610/p/8227599.html
https://blog.csdn.net/qiuzhi__ke/article/details/78849570
正则表达式有四个关键字:
REGEXP_LIKE : 正则模糊匹配——%
REGEXP_INSTR : 正则查找索引位置——数字
REGEXP_SUBSTR : 正则截取——字符串
REGEXP_REPLACE : 正则替换——替换完成后的结果
一些常用的正则表达:
^--匹配一个字符串的开始
[^] -- ^非
$--匹配字符串的结尾
[]--用于指定一个匹配列表
+ --匹配一次或多次出现
?--匹配0次或1次
{M} --匹配m次。
{M,} --至少匹配m次。
{M,N} --至少匹配m次,但不多于n次
[0-9]:匹配任意单个数字,从0到9
[a-zA-Z]:匹配任意单个字母,包括小写字母(a到z)和大写字母(A到Z)
CREATE TABLE T_STR (CONTENT VARCHAR2(1000));INSERT INTO T_STR VALUES ('ADJKSAV,AFDSA13214');
INSERT INTO T_STR VALUES ('ADJKSAV,AFDSA13214');
INSERT INTO T_STR VALUES ('SADA324,AFDS213@32A13214');
INSERT INTO T_STR VALUES ('ADJKSAV,AFDSA.,Z.,SKDF13214');
INSERT INTO T_STR VALUES ('ADJKSAV,AFDSA');
INSERT INTO T_STR VALUES ('1232143225435');
INSERT INTO T_STR VALUES ('张三,李四,王五');
INSERT INTO t_str VALUES('17823459999');
COMMIT;SELECT * FROM T_STR;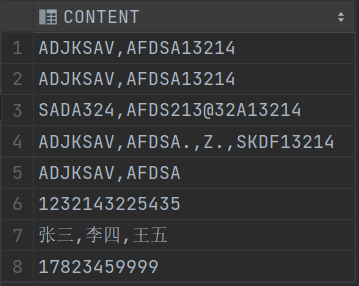
二、REGEXP_LIKE(x,'匹配项')
WHERE 字段 LIKE 'A_'
示例:找出 CONTENT 中包含数字的行有哪些?
select CONTENT
from T_STR
where regexp_like(CONTENT,'[0-9]+');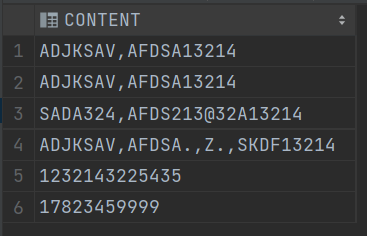
示例:找出 CONTENT 由纯数字组成
select *
from T_STR
where regexp_like(CONTENT,'^[0-9]+$')
-- where regexp_like(CONTENT,'^\d+$')
-- where regexp_like(CONTENT,'^[[:digit:]]+$');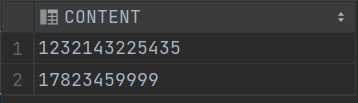
示例:找出 CONTENT 由13位数字组成的有哪些?
select *
from T_STR
where regexp_like(CONTENT,'^[0-9]{13}$');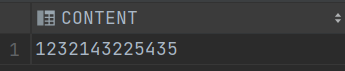
示例:校验输入手机号合法(11位纯数字,1开头,第二位是3/5/7/8/9)
-- REGEXP_LIKE 校验 11位纯数字
-- REGEXP_LIKE(str,'^[0-9]{11}$')select *
from T_STR
where regexp_like(CONTENT,'^[1][35789][0-9]{9}$');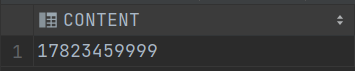
--^:表示字符串的开头。
--[1]:匹配数字1。
--[35789]:匹配数字3、5、7、8或9中的任意一个。
--[0-9]{9}:匹配任意数字0到9,重复9次。
--$:表示字符串的结尾
示例:找出 CONTENT 中 包含 字母的 有哪些
select *
from T_STR
where regexp_like(CONTENT,'[a-zA-Z]+');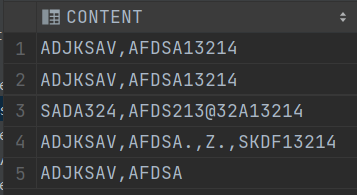
三、REGEXP_INSTR
regexp_instr(在哪个字符串中,正则表达式,从哪个位置开始匹配,第几次匹配)
示例:查找ENAME中 从第一位开始 第二次出现'T'的位置
示例:查找ENAME中 从第一位开始 第二次出现 英文字母 的位置
select ENAME, regexp_instr(ENAME, '[a-zA-Z]', 1, 2) rg
from EMP;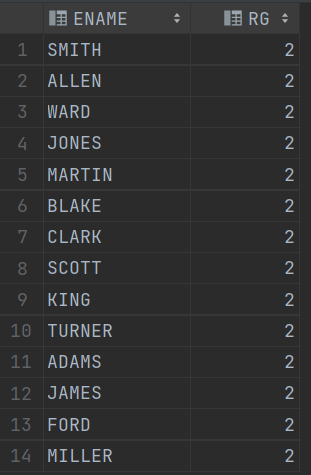
练习:
-- 1.输出所有员工姓名是 5个 英文字母组成的,员工信息,用正则LIKE
select *
from EMP
where REGEXP_LIKE(ENAME, '^[a-zA-Z]{5}$');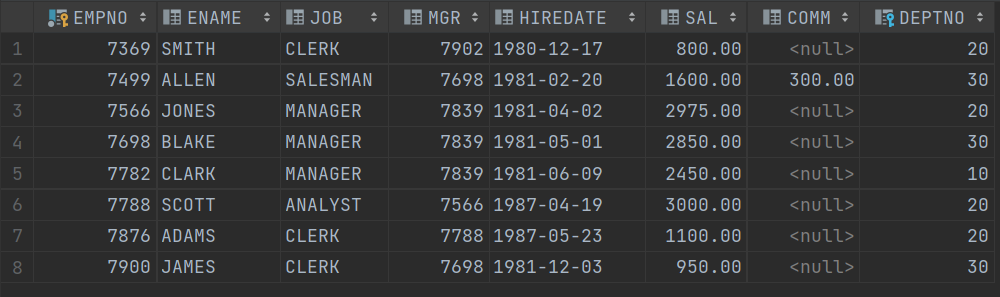
2.查找所有员工 姓名 是 从第二位开始 第三次出现 英文字母的 位置。
-- 输出 姓名 + 位置
select ENAME, regexp_instr(ENAME, '[a-zA-Z]', 2, 3) loc
from EMP;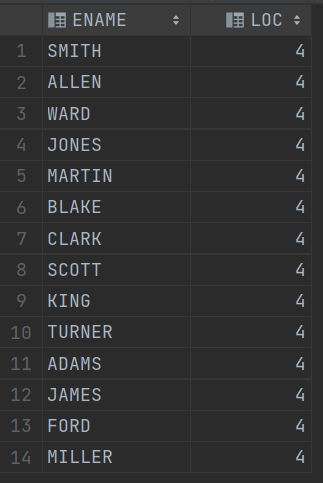
四、REGEXP_SUBSTR
语法同substr
regexp_substr(字段,正则表达式,第几个字符开始匹配正则表达式,取第几个匹配组)
REGEXP_SUBSTR(source_string, -- 源文本pattern, -- 正则表达式模式[position], -- 起始位置(可选,默认1)[occurrence], -- 匹配第几次出现的结果(可选,默认1)[match_parameter] -- 匹配参数(可选))
- 第一个参数是源字符串,
- 第二个参数是正则表达式截取规则,
- 第三个表示从第几个字符开始匹配正则表达式,
- 第四个参数表示取第几个匹配组
示例:将 CONTENT 中'张三,李四,王五'内容 按照逗号进行分割
--从字符串中提取匹配模式的子串
select regexp_substr(CONTENT, '[^,]+', 1, 1) a,regexp_substr(CONTENT, '[^,]+', 1, 2) b,regexp_substr(CONTENT, '[^,]+', 1, 3) c
from T_STR
where CONTENT = '张三,李四,王五';
[^,]表示匹配除逗号以外的任意字符
+表示前面的字符(即除逗号以外的字符)出现一次或多次参数
1(第一个1):表示从目标字符串的第 1 个字符开始进行匹配。参数
1(第二个1):表示返回匹配到的第 1 个子串。如果这个参数改为2,就会返回按逗号分割后的第二个子串(前提是存在第二个子串),以此类推。
--[^-]+:匹配除了连字符以外的任意单个字符,至少出现一次或多次。
CREATE TABLE TT(CON VARCHAR2(100));
INSERT INTO TT VALUES ('广东省-深圳市-龙岗区');
INSERT INTO TT VALUES ('广东省-广州市-天河区');
INSERT INTO TT VALUES ('内蒙古-呼和浩特-蕲春县');
COMMIT;示例:取 TT 表中所有的市名
select regexp_substr(CON, '[^-]+', 1, 2) city_name
from TT;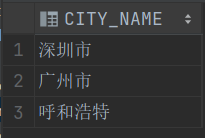
示例:将姓名分列,并为每个人均摊金额
select ENAME,AMOUNT,regexp_substr(ENAME, '[^,]+', 1, 1) a,regexp_substr(ENAME, '[^,]+', 1, 2) b,regexp_substr(ENAME, '[^,]+', 1, 3) c,-- 人数相当于逗号的数量+1=总长度-去掉逗号的长度+1length(ENAME) - length(replace(ENAME, ',')) + 1 num,AMOUNT / length(ENAME) - length(replace(ENAME, ',')) + 1 amt
from T_WRITEOFF;五、REGEXP_REPLACE
regexp_replace(字符串,正则表达式,替换之后的值)
select ENAME,regexp_replace(ENAME,'[^,]','Q') Q
from T_WRITEOFF;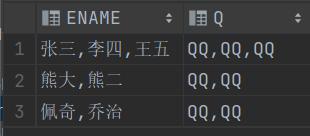
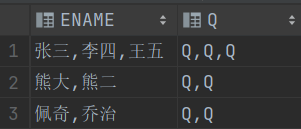
regexp_replace(ENAME,'[^,]','Q')中,如果换成[^,]+,意思是:匹配除逗号 (,) 以外的任意字符的连续序列(即一个或多个非逗号字符)
结果就会变成:
因此,要注意+号的使用
示例:查找字符串 'KJSADKABxkabdksa1432mn2k3n4k2,.1#@$mnad' 中,英文字母的个数
'[^a-zA-Z]+' 将非英文的替换为空,剩下的就是英文字母
select regexp_replace('KJSADKABxkabdksa1432mn2k3n4k2,.1#@$mnad', '[^a-zA-Z]+') a,length(regexp_replace('KJSADKABxkabdksa1432mn2k3n4k2,.1#@$mnad', '[^a-zA-Z]+')) b
from DUAL;
示例:查找字符串 ' 01010101011100110 '中 1 的个数
-- 总长度-非1的个数
select regexp_replace(' 01010101011100110 ', '[^1]+') a,length(regexp_replace(' 01010101011100110 ', '[^1]+')) b
from DUAL;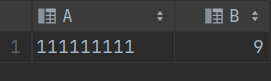
练习:
1. 截取 字符串 'CEO-总监-经理-主管-小组长-基层员工'中的'小组长'
select regexp_substr('CEO-总监-经理-主管-小组长-基层员工', '[^-]+', 1, 5) a
from DUAL;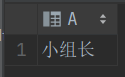
2.提取字符串 'KJASDAKzjxzzkjz212321,,.,1DA' 中,所有的小写英文字母
select regexp_replace('KJASDAKzjxzzkjz212321,,.,1DA', '[^a-z]+') a
from DUAL;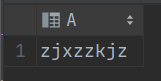
,简单尝试一下。)



)

)


)

)

![[Protobuf]常见数据类型以及使用注意事项](http://pic.xiahunao.cn/[Protobuf]常见数据类型以及使用注意事项)





