在浩瀚的文本海洋中航行,人类大脑天然具备发现主题的能力——翻阅几份报纸,我们迅速辨别出"政治"、"体育"、"科技"等板块;浏览社交媒体,我们下意识区分出美食分享、旅行见闻或科技测评。但机器如何理解文本背后隐藏的主题结构? 这正是主题模型要解决的核心问题。在深度学习浪潮席卷NLP之前,潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)作为主题模型的代表,为我们打开了无监督探索文本语义结构的窗口。
想象《红楼梦》中黛玉的一句"早知他来,我就不来了"。在"情感分析"主题下,这句话透露出幽怨;在"社交礼仪"主题下,它可能只是客套;而在"家族关系"主题下,又隐含贾府复杂的人际网络。LDA的核心能力,正是揭示这种一词多义背后的主题分布。
一、主题模型:文本挖掘的基石
1.1 从词袋到主题
传统文本表示如词袋模型(Bag-of-Words, BoW)和TF-IDF虽能转换文本为向量,却面临两大困境:
-
高维稀疏性:万级词汇表导致特征空间巨大,单个文档仅激活少量维度
-
语义鸿沟:无法捕捉"手机"与"智能手机"的关联,或"苹果"的水果与品牌歧义
主题模型应运而生,其核心思想是:文档是主题的混合,而主题是词语的概率分布。LDA作为生成式概率图模型,通过引入隐变量(主题),在文档-词语矩阵之上构建了一层抽象表示。
1.2 LDA之前的探索
-
LSI/LSA:利用SVD分解词-文档矩阵,但缺乏概率解释
-
pLSI:提出文档-主题分布概念,但无法泛化到新文档
-
LDA突破:引入狄利克雷先验,实现完全生成式建模,支持新文档推理
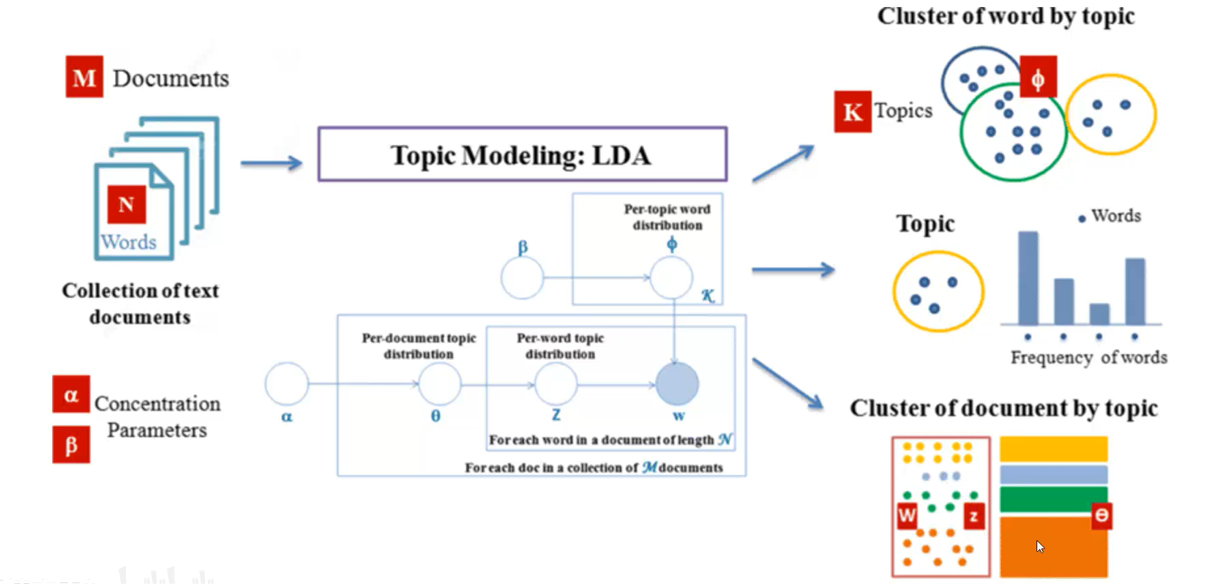
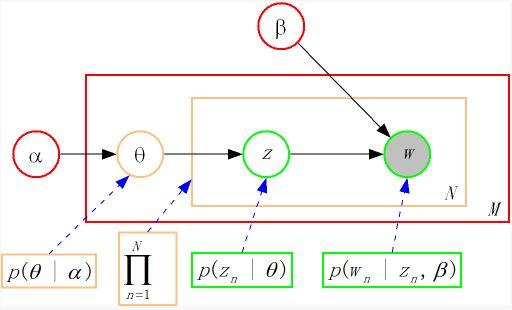
二、LDA原理解析:三层贝叶斯网络的魅力
2.1 生成过程:文本如何"诞生"
LDA的核心是一个优雅的文本生成模拟:
For each document d in corpus D:1. 从狄利克雷分布中采样文档主题分布 θ_d ~ Dir(α)2. For each word w_{d,n} in document d:a. 从主题分布采样一个主题 z_{d,n} ~ Multinomial(θ_d)b. 从该主题的词语分布采样词语 w_{d,n} ~ Multinomial(φ_z)示例:生成一篇"人工智能"相关的文档:
-
步骤1:确定主题混合比,如[科技:0.6, 伦理:0.3, 教育:0.1]
-
步骤2a:对第一个词,按比例随机选中"科技"主题
-
步骤2b:从科技主题的词语分布中采样出"算法"
-
重复直至生成所有词语
2.2 概率图模型表示
LDA的贝叶斯网络结构清晰表达了变量依赖关系:
α β│ │▼ ▼θ_d ──► z_{d,n} ──► w_{d,n}▲ ▲ ▲│ │ │
Dirichlet Multinomial Multinomial-
α, β:超参数,控制主题分布的稀疏性
-
θ_d:文档d的主题分布(文档级变量)
-
φ_k:主题k的词语分布(语料级变量)
-
z_{d,n}:词语w_{d,n]的隐主题(词语级变量)
2.3 Dirichlet分布:关键的先验选择
狄利克雷分布作为多项式分布的共轭先验,其概率密度函数为:
Dir(p|α) = (1/B(α)) * ∏_{i=1}^K p_i^{α_i-1}-
α<1:偏好稀疏分布(少数主题主导)
-
α>1:偏好均匀分布(主题混合均匀)
-
实践意义:通过调整α控制文档主题集中度,调整β控制主题内词语集中度
可视化实验:当α=0.1时,采样点靠近单纯形顶点;当α=2.0时,采样点向中心聚集。
三、LDA求解:从吉布斯采样到变分推断
3.1 吉布斯采样(Gibbs Sampling)
通过迭代更新每个词语的主题分配进行近似推断:
P(z_i=k | z_{-i}, w) ∝ (n_{d,k}^{-i} + α_k) * (n_{k,w_i}^{-i} + β_{w_i}) / (n_k^{-i} + β_sum)-
n_{d,k}:文档d中主题k出现的次数
-
n_{k,w}:主题k下词语w出现的次数
-
^{-i}:排除当前词语的计数
Python伪代码实现:
# 初始化:随机分配每个词的主题
for iter in range(num_iterations):for d in documents:for i in word_position:# 排除当前词统计decrement_counts(z[d][i], w[d][i], d)# 按概率采样新主题p_z = compute_topic_prob(d, w[d][i])new_z = sample_from(p_z)# 更新统计z[d][i] = new_zincrement_counts(new_z, w[d][i], d)3.2 变分推断(Variational Inference)
通过优化变分分布q(θ,z|γ,φ)逼近真实后验:
最大化 ELBO(γ,φ; α,β) = E_q[log p(θ,z,w|α,β)] - E_q[log q(θ,z|γ,φ)]-
γ_d:文档d的主题分布的变分参数
-
λ_k:主题k的词语分布的变分参数
对比:
-
吉布斯采样:结果更精确,但内存消耗大,适合小型语料
-
变分推断:速度更快,适合大规模数据,但可能低估方差
四、LDA实战:从数据到洞察
4.1 预处理流程

4.2 模型训练(Python示例)
from gensim.models import LdaModel
from gensim.corpora import Dictionary# 构建词典和语料
dictionary = Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]# 训练LDA模型
model = LdaModel(corpus=corpus,id2word=dictionary,num_topics=10,alpha='auto',eta='auto',iterations=50
)# 可视化主题
import pyLDAvis.gensim_models
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(model, corpus, dictionary)
pyLDAvis.display(vis)4.3 结果解释与优化
-
主题一致性评估:
from gensim.models import CoherenceModel coherence = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v') coherence_score = coherence.get_coherence() -
参数调优技巧:
-
使用
alpha='auto'自动学习非对称α -
通过网格搜索选择最佳主题数k
-
结合UMAP降维可视化主题分布
-
4.4 主题演化分析(动态LDA)
from gensim.models import LdaSeqModel# 按时间切片语料
time_slice = [len(corpus_2019), len(corpus_2020), len(corpus_2021)]# 训练动态主题模型
dyn_model = LdaSeqModel(corpus=all_corpus,time_slice=time_slice,num_topics=10,chunksize=1000
)# 获取主题演化路径
dyn_model.print_topics(time=1) # 查看第二时间段的主题五、LDA应用场景:超越文本挖掘
5.1 推荐系统
-
用户画像构建:将用户历史行为文档化,提取兴趣主题
-
跨域推荐:通过共享主题空间连接不同内容类型
Netflix案例:将影片描述、用户评论转化为主题混合,计算主题相似度提升推荐多样性。
5.2 舆情监控
# 情感-主题联合分析
def sentiment_aware_lda(docs):# Step1: 情感词典标注doc_sentiments = [get_sentiment(doc) for doc in docs]# Step2: 扩展词典dictionary.add_documents([["POS_"+w, "NEG_"+w] for w in sentiment_words])# Step3: 训练联合模型model = LdaModel(corpus, num_topics=20, ...)# Step4: 分析主题-情感关联return model, doc_sentiments5.3 生物信息学
-
基因功能分析:将文献作为文档,基因为"词语",发现功能主题
-
药物重定位:通过疾病-药物主题关联寻找潜在治疗组合
六、LDA的局限与新时代发展
6.1 固有局限性
-
词序忽略:无法建模"算法优秀"与"优秀算法"的差异
-
短文本失效:推文等短文本因数据稀疏难以提取可靠主题
-
主题一致性:自动化评估指标与人工判断常存在差距
6.2 融合深度学习
-
Neural LDA:用神经网络参数化主题分布
class NeuralLDA(nn.Module):def __init__(self, num_topics, vocab_size):super().__init__()self.encoder = nn.Sequential(nn.Linear(vocab_size, 256),nn.ReLU(),nn.Linear(256, num_topics))self.topic_emb = nn.Embedding(num_topics, vocab_size)def forward(self, x):# 输出文档主题分布theta = F.softmax(self.encoder(x), dim=-1)# 重建词频分布word_dist = torch.matmul(theta, self.topic_emb.weight)return word_dist, theta -
结合词向量:用Word2Vec代替词袋提升语义敏感度
-
BERTopic:利用BERT嵌入聚类实现上下文感知的主题建模
结语:主题模型的时代价值
尽管深度学习模型在诸多NLP任务上超越了传统方法,LDA依然在特定场景闪耀独特价值:
-
可解释性:相比深度模型的"黑箱",LDA的主题词列表直观可理解
-
无监督优势:无需标注数据即可探索海量文本的隐藏结构
-
计算效率:在资源受限环境下仍具实用性








)










