1. capitalize:
是第一个字符大写,其余小写
2. encode:
将字符串转换为字节串(bytes),默认使用 UTF-8 编码。
3. format:
format是 Python 中字符串对象的内置方法,语法为S.format(*args, **kwargs)
*args:代表可变数量的位置参数,按顺序对应格式化字符串中用大括号{}标识的替换位置。**kwargs:代表可变数量的关键字参数,通过键值对形式,依据关键字来对应格式化字符串中用{关键字}标识的替换位置 。
s = "我叫{},今年{}岁".format("小明", 18)
print(s)
# 输出:我叫小明,今年18岁
4. isalpha:
isalpha()返回False的常见原因:
- 包含非字母字符(如数字、空格、标点符号、符号、表情符号等)

isalnum():检查是否全是字母或数字(如"abc123"返回True)。isdigit():检查是否全是数字(如"123"返回True)。isspace():检查是否全是空格(如" "返回True)
5. isidentifier:
判断是否是标识符

6. isspace:
判断是否是空白字符串

7. ljust
快速实现文本对齐需求,用于将字符串左对齐,并使用指定的填充字符(默认为空格)填充至指定长度。
语法:
string.ljust(width,fillchar=' ')
width:目标字符串长度。如果原字符串长度小于width,则在右侧填充字符;否则返回原字符串(不截断)。fillchar(可选):填充字符,必须为单字符。默认为空格' '。
In [15]: a.ljust(15,'*')
Out[15]: 'hello world!***'In [16]: print (a)
hello world!

8. partition:
把字符串依据指定的分隔符拆分成三个部分
- 仅分割一次:此方法只会对字符串进行一次分割,不管分隔符出现的次数有多少。
- 分隔符必须存在:若字符串中不存在指定的分隔符,元组的结果会有所不同(见下文示例)。
- 保留分隔符:返回的元组里会包含分隔符本身。
- 返回值:返回一个包含三个元素的元组,分别是:
- 分隔符前面的子字符串。
- 分隔符本身。
- 分隔符后面的子字符串。

9. rfind
用于从右向左查找子字符串第一次出现的位置。如果找到,则返回该位置的索引;如果未找到,则返回
-1。这与find()方法类似,但搜索方向相反(从右到左)语法:
string.rfind(sub[, start[, end]])
sub:要查找的子字符串。start(可选):开始搜索的索引位置(默认为 0,即从字符串开头开始)。end(可选):结束搜索的索引位置(默认为字符串长度,即搜索到字符串末尾)
a='hello world!'
In [27]: a.rfind("d!")
Out[27]: 10text = "Hello, world! Hello, Python!"# 从索引 0 到 10 之间查找 "Hello"
print(text.rfind("Hello", 0, 10)) # 输出:0(第一个 "Hello" 的起始位置)# 从索引 5 到末尾查找 "world"
print(text.rfind("world", 5)) # 输出:710. casefold
返回一个不区分大小写的字符串版本
11. center
用于将字符串居中对齐,并使用指定字符(默认为空格)填充至指定长度。
text = "Hello"# 居中对齐,总宽度10,默认用空格填充
print(text.center(10)) # 输出:" Hello "# 使用指定字符填充
print(text.center(10, '*')) # 输出:"**Hello***"# 原字符串长度超过width时,返回原字符串
print(text.center(3)) # 输出:"Hello"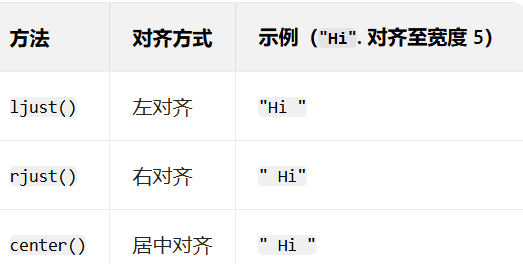
12.count
用于统计特定元素、事件或数据出现的次数。
字符串计数
text = "hello world"
print(text.count('l')) # 输出: 3列表 / 元组计数
nums = [1, 2, 2, 3, 3, 3]
print(nums.count(2)) # 输出: 213. endswith
用于检查字符串是否以指定的后缀结束。如果是,则返回 True,否则返回 False。该方法非常适合用于文件类型判断、路径验证或文本模式匹配等场景。
语法:
string.endswith(suffix[, start[, end]]
suffix:要检查的后缀,可以是单个字符串或元组(多个候选后缀)。start(可选):开始检查的索引位置(默认为 0,即从字符串开头开始)。end(可选):结束检查的索引位置(默认为字符串长度,即检查到字符串末尾)
:LeetCode 234. 回文链表(Palindrome Linked List)详解)







)





)




