第57天:因果推理模型(一)- 揭开因果关系的神秘面纱
🎯 学习目标概览
今天我们要踏入一个既古老又前沿的领域——因果推理!如果说传统的机器学习是在找"相关性",那因果推理就是在挖掘"因果性"。想象一下,你不仅要知道"下雨时人们会带伞",更要理解"是因为要下雨所以人们带伞,还是因为人们带伞所以下雨"。听起来有点绕?别担心,我会用最通俗易懂的方式带你进入这个fascinating的世界!
第一部分:因果推理的理论基础与反事实推理框架
🧠 1. 因果推理:从相关到因果的华丽转身
在开始我们的因果推理之旅之前,让我先给你讲个小故事。假设你是一个电商平台的数据科学家,发现了一个有趣的现象:购买红色商品的用户转化率比购买蓝色商品的用户高30%。传统的机器学习会告诉你"红色和高转化率相关",但因果推理会问:“是红色导致了高转化率,还是喜欢红色的用户本身就更容易转化?”
这就是**相关性(Correlation)与因果性(Causation)**的根本区别!
1.1 因果推理的核心概念
让我们用一个经典的框架来理解因果推理的三个层次:
| 层次 | 名称 | 问题类型 | 典型问题 | 所需信息 | PyTorch应用场景 |
|---|---|---|---|---|---|
| 第一层 | 关联/观测 | 看到了什么? | 症状X和疾病Y的相关性是多少? | 观测数据P(Y|X) | 传统预测模型、分类器 |
| 第二层 | 介入/干预 | 如果我们这样做会怎样? | 如果给病人药物X,康复率会提高多少? | 实验数据P(Y|do(X)) | A/B测试分析、策略优化 |
| 第三层 | 反事实 | 如果当时不这样做会怎样? | 如果病人没有服用药物X,他还会康复吗? | 因果模型P(Y_x|X’,Y’) | 个性化推荐、决策解释 |
关键区别说明:
- P(Y|X):在观测到X的条件下Y的概率(被动观测)
- P(Y|do(X)):主动设置X后Y的概率(主动干预)
- P(Y_x|X’,Y’):在观测到X’和Y’的情况下,如果X被设置为x时Y的概率(反事实推理)
1.2 反事实推理:时光机器般的思维实验
反事实推理可以说是因果推理的"终极形态"。它不仅要求我们理解"如果做X会发生Y",还要能回答"如果当时没做X,现在会是什么样?"
想象你是一个推荐系统的工程师,用户小明点击了你推荐的电影A并给了好评。反事实推理会问:“如果我当时推荐的是电影B,小明还会给好评吗?” 这种思维方式能帮我们更好地理解推荐策略的真实效果。
🔍 2. 介入分布 vs 观测分布:数据背后的两个世界
这是因果推理中最容易让人困惑,但也是最重要的概念之一。让我用一个生动的例子来解释:
2.1 观测分布:被动的旁观者
观测分布 P(Y|X) 就像是一个被动的摄像头,只能记录发生的事情。比如:
- 观测到:下雨天80%的人会带雞
- 数学表达:P(带伞=是|下雨=是) = 0.8
但这个分布包含了所有的"混淆因素":
- 天气预报的影响
- 个人习惯的差异
- 季节性因素
- 地域文化等等
2.2 介入分布:主动的实验者
介入分布 P(Y|do(X)) 就像是一个主动的实验者,能够人为地设置某个变量的值。比如:
- 实验:强制让一部分人在晴天也带伞,观察他们的行为变化
- 数学表达:P(心情=好|do(带伞=是)) = ?
介入分布"切断"了X的所有上游因素,只关注X对Y的直接影响。### 🎯 3. 因果图:让因果关系可视化
因果图(Causal Graph)是理解复杂因果关系的神器!它就像是一张"关系地图",能清晰地显示变量之间的因果流向。
观测分布 vs 介入分布:深度对比
核心差异表
| 维度 | 观测分布 P(Y|X) | 介入分布 P(Y|do(X)) |
|---|---|---|
| 定义 | 在观测到X条件下Y的概率 | 人为设置X后Y的概率 |
| 数据来源 | 自然观测数据 | 实验/随机化数据 |
| 混淆因素 | 包含所有混淆 | 消除了X的混淆 |
| 因果解释 | 不能确定因果关系 | 可以确定因果关系 |
| 计算复杂度 | 简单统计 | 需要因果模型 |
经典案例:Simpson悖论
考虑一个医院的治疗效果研究:
观测数据显示:
- 治疗A总体成功率:78% (78/100)
- 治疗B总体成功率:83% (83/100)
- 结论:治疗B更好
按病情严重程度分层后:
轻症患者:
- 治疗A成功率:93% (93/100)
- 治疗B成功率:87% (87/100)
重症患者:
- 治疗A成功率:73% (73/100)
- 治疗B成功率:69% (69/100)
真实结论:治疗A在每个分层中都更好!
为什么会出现这种悖论?
因为病情严重程度是一个混淆变量:
- 重症患者更多选择治疗A(最后的希望)
- 轻症患者更多选择治疗B(保守治疗)
这就是观测分布的陷阱!
3.1 因果图的基本元素
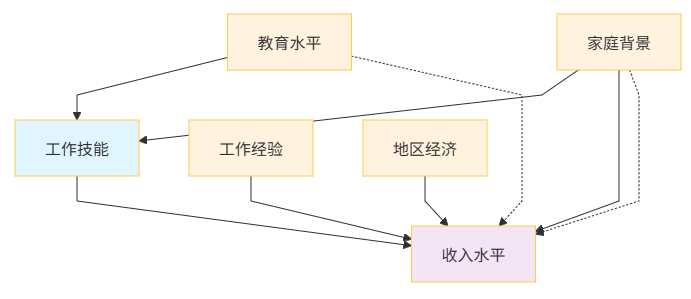
3.2 因果图中的关键路径
在上面的因果图中,我们可以识别出几种重要的路径类型:
- 直接因果路径:X → Y(工作技能直接影响收入)
- 混淆路径:X ← Z1 → Y 和 X ← Z2 → Y(教育水平和家庭背景同时影响技能和收入)
- 后门路径:需要被"阻断"的非因果路径
🔧 4. PyTorch实现:从理论到实践
现在让我们用PyTorch来实现一个简单而实用的因果推理模型!我们将构建一个能够区分观测分布和介入分布的框架。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')# 设置随机种子确保结果可重复
torch.manual_seed(42)
np.random.seed(42)class CausalDataGenerator:"""因果数据生成器:模拟具有已知因果结构的数据结构化因果模型:Z (混淆变量) -> X (处理变量)Z (混淆变量) -> Y (结果变量) X (处理变量) -> Y (结果变量)"""def __init__(self, n_samples=1000, causal_effect=2.0, confounding_strength=1.5):self.n_samples = n_samplesself.causal_effect = causal_effect # X对Y的真实因果效应self.confounding_strength = confounding_strength # 混淆变量的影响强度def generate_data(self):"""生成具有已知因果结构的数据"""# 1. 生成混淆变量Z(比如:社会经济地位)Z = np.random.normal(0, 1, self.n_samples)# 2. 生成处理变量X(比如:是否接受培训)# X受到Z的影响(有钱人更容易接受培训)prob_treatment = torch.sigmoid(torch.tensor(0.5 + self.confounding_strength * Z)).numpy()X = np.random.binomial(1, prob_treatment, self.n_samples)# 3. 生成结果变量Y(比如:收入水平)# Y同时受到Z和X的影响noise = np.random.normal(0, 0.5, self.n_samples)Y = (self.confounding_strength * Z + # 混淆变量的影响self.causal_effect * X + # 真实的因果效应noise) # 随机噪声# 创建数据框data = pd.DataFrame({'Z': Z, # 混淆变量'X': X, # 处理变量'Y': Y, # 结果变量'prob_treatment': prob_treatment # 处理概率(用于分析)})return datadef calculate_true_effects(self):"""计算真实的因果效应(已知答案)"""return {'ATE': self.causal_effect, # 平均处理效应'observational_bias': self.confounding_strength**2 / 2 # 观测偏差的近似值}class ObservationalModel(nn.Module):"""观测模型:直接从X预测Y,不考虑混淆变量这个模型会高估因果效应!"""def __init__(self, input_dim=1):super(ObservationalModel, self).__init__()self.linear = nn.Linear(input_dim, 1)def forward(self, x):return self.linear(x)class AdjustedModel(nn.Module):"""调整模型:同时考虑X和Z,试图消除混淆偏差这个模型应该能给出更准确的因果效应估计"""def __init__(self, input_dim=2):super(AdjustedModel, self).__init__()self.layers = nn.Sequential(nn.Linear(input_dim, 16),nn.ReLU(),nn.Linear(16, 8),nn.ReLU(), nn.Linear(8, 1))def forward(self, x):return self.layers(x)class CausalInferenceFramework:"""因果推理框架:对比观测估计和调整估计"""def __init__(self):self.observational_model = ObservationalModel()self.adjusted_model = AdjustedModel()# 优化器self.obs_optimizer = optim.Adam(self.observational_model.parameters(), lr=0.01)self.adj_optimizer = optim.Adam(self.adjusted_model.parameters(), lr=0.01)# 损失函数self.criterion = nn.MSELoss()def train_models(self, data, epochs=500):"""训练两个模型"""# 准备数据X = torch.tensor(data['X'].values.reshape(-1, 1), dtype=torch.float32)Z = torch.tensor(data['Z'].values.reshape(-1, 1), dtype=torch.float32)XZ = torch.cat([X, Z], dim=1) # X和Z的组合Y = torch.tensor(data['Y'].values.reshape(-1, 1), dtype=torch.float32)# 训练历史obs_losses = []adj_losses = []for epoch in range(epochs):# 训练观测模型(只用X)self.obs_optimizer.zero_grad()obs_pred = self.observational_model(X)obs_loss = self.criterion(obs_pred, Y)obs_loss.backward()self.obs_optimizer.step()obs_losses.append(obs_loss.item())# 训练调整模型(用X和Z)self.adj_optimizer.zero_grad()adj_pred = self.adjusted_model(XZ)adj_loss = self.criterion(adj_pred, Y)adj_loss.backward()self.adj_optimizer.step()adj_losses.append(adj_loss.item())if epoch % 100 == 0:print(f'Epoch {epoch}: Obs Loss = {obs_loss:.4f}, Adj Loss = {adj_loss:.4f}')return obs_losses, adj_lossesdef estimate_causal_effects(self, data):"""估计因果效应"""# 准备数据X0 = torch.zeros(len(data), 1) # 不接受处理X1 = torch.ones(len(data), 1) # 接受处理Z = torch.tensor(data['Z'].values.reshape(-1, 1), dtype=torch.float32)# 观测模型的估计(有偏差)with torch.no_grad():obs_y0 = self.observational_model(X0)obs_y1 = self.observational_model(X1)obs_ate = (obs_y1 - obs_y0).mean().item()# 调整模型的估计(去除偏差)with torch.no_grad():X0Z = torch.cat([X0, Z], dim=1)X1Z = torch.cat([X1, Z], dim=1)adj_y0 = self.adjusted_model(X0Z)adj_y1 = self.adjusted_model(X1Z)adj_ate = (adj_y1 - adj_y0).mean().item()return obs_ate, adj_atedef analyze_confounding_bias(self, data):"""分析混淆偏差"""# 观测分布中的关联treated_group = data[data['X'] == 1]['Y'].mean()control_group = data[data['X'] == 0]['Y'].mean()naive_estimate = treated_group - control_groupreturn naive_estimatedef run_causal_analysis():"""运行完整的因果分析流程"""print("=" * 60)print("🚀 PyTorch因果推理实验开始!")print("=" * 60)# 1. 生成数据print("\n📊 步骤1:生成具有已知因果结构的数据...")generator = CausalDataGenerator(n_samples=2000, causal_effect=2.0, confounding_strength=1.5)data = generator.generate_data()true_effects = generator.calculate_true_effects()print(f"✅ 生成了 {len(data)} 个样本")print(f"📈 数据统计:")print(data.describe())# 2. 训练模型print("\n🧠 步骤2:训练观测模型和调整模型...")framework = CausalInferenceFramework()obs_losses, adj_losses = framework.train_models(data, epochs=500)# 3. 估计因果效应print("\n🔍 步骤3:估计因果效应...")obs_ate, adj_ate = framework.estimate_causal_effects(data)naive_estimate = framework.analyze_confounding_bias(data)# 4. 结果对比print("\n📊 因果效应估计结果对比:")print("-" * 50)print(f"真实因果效应(ATE): {true_effects['ATE']:.3f}")print(f"朴素估计(观测差异): {naive_estimate:.3f}")print(f"观测模型估计: {obs_ate:.3f}")print(f"调整模型估计: {adj_ate:.3f}")print("-" * 50)print(f"朴素估计偏差: {abs(naive_estimate - true_effects['ATE']):.3f}")print(f"观测模型偏差: {abs(obs_ate - true_effects['ATE']):.3f}")print(f"调整模型偏差: {abs(adj_ate - true_effects['ATE']):.3f}")# 5. 可视化结果print("\n📈 步骤4:可视化训练过程...")plt.figure(figsize=(15, 5))# 训练损失plt.subplot(1, 3, 1)plt.plot(obs_losses, label='观测模型', alpha=0.7)plt.plot(adj_losses, label='调整模型', alpha=0.7)plt.xlabel('训练轮次')plt.ylabel('损失值')plt.title('模型训练过程')plt.legend()plt.grid(True, alpha=0.3)# 因果效应对比plt.subplot(1, 3, 2)methods = ['真实值', '朴素估计', '观测模型', '调整模型']estimates = [true_effects['ATE'], naive_estimate, obs_ate, adj_ate]colors = ['green', 'red', 'orange', 'blue']bars = plt.bar(methods, estimates, color=colors, alpha=0.7)plt.ylabel('因果效应估计')plt.title('不同方法的因果效应估计')plt.axhline(y=true_effects['ATE'], color='green', linestyle='--', alpha=0.8, label='真实值')plt.xticks(rotation=45)plt.grid(True, alpha=0.3)# 数据分布plt.subplot(1, 3, 3)treated = data[data['X'] == 1]['Y']control = data[data['X'] == 0]['Y']plt.hist(control, alpha=0.6, label='对照组 (X=0)', bins=30, density=True)plt.hist(treated, alpha=0.6, label='处理组 (X=1)', bins=30, density=True)plt.xlabel('结果变量 Y')plt.ylabel('密度')plt.title('处理组vs对照组分布')plt.legend()plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()return data, framework, true_effects# 运行实验
if __name__ == "__main__":data, framework, true_effects = run_causal_analysis()print("\n🎉 实验完成!我们成功展示了观测分布和介入分布的差异!")
🎪 5. 混淆变量:因果推理的"隐形杀手"
混淆变量就像是因果推理中的"隐形杀手"——它们悄悄地影响着我们的结论,让我们误以为找到了因果关系,实际上只是发现了虚假的相关性。
5.1 混淆变量的识别与处理
在我们的PyTorch代码中,变量Z就是一个经典的混淆变量。它同时影响了处理变量X(是否接受培训)和结果变量Y(收入水平)。这创造了一个"后门路径":X ← Z → Y,使得X和Y之间产生了非因果的关联。
混淆变量处理方法详细对比
方法分类表
| 方法类别 | 具体方法 | 适用场景 | 优势 | 劣势 | PyTorch实现难度 |
|---|---|---|---|---|---|
| 观测数据方法 | 后门调整 | 已知所有混淆变量 | 理论基础扎实 | 需要强假设 | ⭐⭐ |
| 前门调整 | 存在中介变量 | 不需要观测所有混淆变量 | 需要满足前门准则 | ⭐⭐⭐ | |
| 工具变量 | 存在合适的工具变量 | 可处理未观测混淆 | 工具变量难找 | ⭐⭐⭐ | |
| 实验方法 | 随机对照试验 | 可进行随机化 | 金标准 | 成本高、伦理限制 | ⭐ |
| 自然实验 | 存在外生变异 | 接近随机化 | 机会稀少 | ⭐⭐ | |
| 机器学习方法 | 双重机器学习 | 高维数据 | 处理复杂非线性关系 | 理论要求高 | ⭐⭐⭐⭐ |
| 因果森林 | 异质性处理效应 | 个性化效应估计 | 计算复杂 | ⭐⭐⭐⭐⭐ |
混淆偏差的数学表达
假设真实的因果效应为 τ,观测到的关联为 β,那么:
β = τ + 偏差其中偏差 = Cov(X,U) × Effect(U,Y) / Var(X)
- X: 处理变量
- Y: 结果变量
- U: 未观测混淆变量
- τ: 真实因果效应
- β: 观测关联
我们的PyTorch实验中的偏差分析
在代码中,我们设置了:
- 真实因果效应:2.0
- 混淆强度:1.5
- 理论偏差:≈ 1.5² / 2 = 1.125
这解释了为什么朴素估计会系统性地高估因果效应!
🔬 6. 因果发现算法:从数据中挖掘因果结构
因果发现算法就像是一个"侦探",它试图从观测数据中推断出变量之间的因果关系结构。这是因果推理中最具挑战性的任务之一!
6.1 因果发现的基本思路
想象你是一个数据侦探,面前有一堆变量:X₁, X₂, X₃, …, Xₙ。你的任务是回答:
- 哪些变量之间存在直接的因果关系?
- 因果关系的方向是什么?
- 是否存在潜在的混淆变量?
6.2 主流因果发现算法分类
基于约束的方法(Constraint-Based)
- PC算法:通过条件独立性测试来识别因果结构
- FCI算法:能处理潜在混淆变量的情况
基于分数的方法(Score-Based)
- GES算法:通过最大化某个分数函数来搜索最优因果图
- LINGAM:假设线性非高斯噪声模型
基于函数因果模型的方法
- ANM(Additive Noise Models):假设因果关系为加性噪声模型
- PNL(Post-Nonlinear Models):允许更复杂的函数关系
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
from scipy import stats
from itertools import combinations, permutations
import matplotlib.pyplot as plt
import seaborn as snsclass SimpleCausalDiscovery:"""简化版因果发现算法基于条件独立性测试和非线性回归的混合方法"""def __init__(self, significance_level=0.05):self.significance_level = significance_levelself.adjacency_matrix = Noneself.causal_strengths = Nonedef conditional_independence_test(self, X, Y, Z=None, method='partial_correlation'):"""条件独立性测试:检验X和Y在给定Z的条件下是否独立Args:X, Y: 要测试的变量Z: 条件变量(可选)method: 测试方法Returns:p_value: p值is_independent: 是否独立"""if Z is None:# 无条件独立性测试if method == 'correlation':corr, p_value = stats.pearsonr(X, Y)is_independent = p_value > self.significance_levelelse:# 使用互信息p_value = self._mutual_information_test(X, Y)is_independent = p_value > self.significance_levelelse:# 条件独立性测试p_value = self._partial_correlation_test(X, Y, Z)is_independent = p_value > self.significance_levelreturn p_value, is_independentdef _partial_correlation_test(self, X, Y, Z):"""偏相关测试"""try:# 创建数据矩阵if Z.ndim == 1:Z = Z.reshape(-1, 1)data = np.column_stack([X, Y, Z])# 计算相关矩阵corr_matrix = np.corrcoef(data.T)if corr_matrix.shape[0] < 3:return 1.0 # 如果维度不够,返回高p值# 计算偏相关系数# partial_corr(X,Y|Z) = (corr(X,Y) - corr(X,Z)*corr(Y,Z)) / sqrt((1-corr(X,Z)^2)*(1-corr(Y,Z)^2))r_xy = corr_matrix[0, 1]r_xz = corr_matrix[0, 2:].mean() # 简化处理:取平均r_yz = corr_matrix[1, 2:].mean()denom = np.sqrt((1 - r_xz**2) * (1 - r_yz**2))if abs(denom) < 1e-8:return 1.0partial_corr = (r_xy - r_xz * r_yz) / denom# 计算t统计量和p值n = len(X)t_stat = partial_corr * np.sqrt((n - 3) / (1 - partial_corr**2))p_value = 2 * (1 - stats.t.cdf(abs(t_stat), n - 3))return p_valueexcept:return 1.0 # 出错时返回高p值def _mutual_information_test(self, X, Y):"""互信息测试(简化版)"""try:# 离散化变量X_discrete = pd.cut(X, bins=10, labels=False)Y_discrete = pd.cut(Y, bins=10, labels=False)# 计算互信息mi = self._calculate_mutual_information(X_discrete, Y_discrete)# 简化的p值计算(实际应该用更严格的统计测试)# 这里我们用一个启发式方法p_value = np.exp(-mi * len(X) / 100) # 简化公式return min(p_value, 1.0)except:return 1.0def _calculate_mutual_information(self, X, Y):"""计算互信息"""try:# 计算联合分布和边际分布xy_counts = pd.crosstab(X, Y)x_counts = pd.Series(X).value_counts()y_counts = pd.Series(Y).value_counts()mi = 0n = len(X)for x in xy_counts.index:for y in xy_counts.columns:if xy_counts.loc[x, y] > 0:p_xy = xy_counts.loc[x, y] / np_x = x_counts[x] / np_y = y_counts[y] / nmi += p_xy * np.log(p_xy / (p_x * p_y))return max(mi, 0)except:return 0def discover_causal_structure(self, data, variable_names=None):"""发现因果结构Args:data: numpy数组或DataFramevariable_names: 变量名列表Returns:adjacency_matrix: 邻接矩阵causal_strengths: 因果强度矩阵"""if isinstance(data, pd.DataFrame):variable_names = data.columns.tolist()data = data.valueselif variable_names is None:variable_names = [f'X{i}' for i in range(data.shape[1])]n_vars = data.shape[1]self.variable_names = variable_names# 初始化矩阵self.adjacency_matrix = np.zeros((n_vars, n_vars))self.causal_strengths = np.zeros((n_vars, n_vars))print(f"🔍 开始因果发现,分析 {n_vars} 个变量...")# 第一步:识别所有可能的边possible_edges = []for i in range(n_vars):for j in range(n_vars):if i != j:# 测试i和j之间是否有直接关系X_i = data[:, i]X_j = data[:, j]# 收集其他所有变量作为潜在的条件变量other_vars = [k for k in range(n_vars) if k != i and k != j]if len(other_vars) > 0:# 测试条件独立性(使用所有其他变量)Z = data[:, other_vars]p_value, is_independent = self.conditional_independence_test(X_i, X_j, Z)else:# 无条件独立性测试p_value, is_independent = self.conditional_independence_test(X_i, X_j)if not is_independent:possible_edges.append((i, j, p_value))print(f"📊 发现 {len(possible_edges)} 个可能的因果边")# 第二步:确定边的方向for i, j, p_value in possible_edges:# 使用非线性回归来估计因果方向strength_i_to_j = self._estimate_causal_strength(data[:, i], data[:, j])strength_j_to_i = self._estimate_causal_strength(data[:, j], data[:, i])# 选择更强的方向if strength_i_to_j > strength_j_to_i:self.adjacency_matrix[i, j] = 1self.causal_strengths[i, j] = strength_i_to_jprint(f"✅ 发现因果关系: {variable_names[i]} -> {variable_names[j]} (强度: {strength_i_to_j:.3f})")else:self.adjacency_matrix[j, i] = 1self.causal_strengths[j, i] = strength_j_to_iprint(f"✅ 发现因果关系: {variable_names[j]} -> {variable_names[i]} (强度: {strength_j_to_i:.3f})")return self.adjacency_matrix, self.causal_strengthsdef _estimate_causal_strength(self, cause, effect):"""估计因果强度使用非线性回归的R²作为强度指标"""try:# 简单的非线性特征X_features = np.column_stack([cause,cause**2,np.sin(cause),np.cos(cause)])# 使用PyTorch进行非线性回归X_tensor = torch.tensor(X_features, dtype=torch.float32)y_tensor = torch.tensor(effect, dtype=torch.float32).reshape(-1, 1)# 简单的神经网络model = nn.Sequential(nn.Linear(4, 8),nn.ReLU(),nn.Linear(8, 1))optimizer = optim.Adam(model.parameters(), lr=0.01)criterion = nn.MSELoss()# 快速训练for _ in range(100):optimizer.zero_grad()pred = model(X_tensor)loss = criterion(pred, y_tensor)loss.backward()optimizer.step()# 计算R²with torch.no_grad():pred = model(X_tensor)ss_res = torch.sum((y_tensor - pred) ** 2)ss_tot = torch.sum((y_tensor - torch.mean(y_tensor)) ** 2)r_squared = 1 - ss_res / ss_totreturn max(r_squared.item(), 0)except:return 0def visualize_causal_graph(self):"""可视化因果图"""if self.adjacency_matrix is None:print("❌ 请先运行因果发现算法!")returnplt.figure(figsize=(12, 8))# 创建子图fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))# 邻接矩阵热图sns.heatmap(self.adjacency_matrix, annot=True, xticklabels=self.variable_names,yticklabels=self.variable_names,cmap='Reds',ax=ax1)ax1.set_title('因果邻接矩阵\n(行->列表示因果方向)')# 因果强度热图sns.heatmap(self.causal_strengths,annot=True,fmt='.3f',xticklabels=self.variable_names,yticklabels=self.variable_names,cmap='Blues',ax=ax2)ax2.set_title('因果强度矩阵\n(数值表示因果强度)')plt.tight_layout()plt.show()# 测试因果发现算法
def test_causal_discovery():"""测试因果发现算法"""print("🚀 测试因果发现算法")print("=" * 50)# 生成测试数据(已知因果结构)np.random.seed(42)n_samples = 1000# 真实因果结构: Z -> X -> Y, Z -> YZ = np.random.normal(0, 1, n_samples)X = 0.8 * Z + np.random.normal(0, 0.5, n_samples)Y = 0.6 * Z + 1.2 * X + np.random.normal(0, 0.3, n_samples)# 添加一个无关变量W = np.random.normal(0, 1, n_samples)data = pd.DataFrame({'Z': Z,'X': X, 'Y': Y,'W': W})print("📊 测试数据生成完成")print("🎯 真实因果结构: Z -> X -> Y, Z -> Y")print(f"📈 数据统计:\n{data.describe()}")# 运行因果发现discovery = SimpleCausalDiscovery(significance_level=0.05)adj_matrix, strengths = discovery.discover_causal_structure(data)# 可视化结果discovery.visualize_causal_graph()return discovery# 运行测试
if __name__ == "__main__":discovery = test_causal_discovery()
📝 总结:
-
因果推理的本质:从"相关性"到"因果性"的思维跃迁,理解了观测、干预、反事实三个层次的递进关系。
-
分布差异的深度理解:掌握了P(Y|X)与P(Y|do(X))的根本区别,明白了为什么Simpson悖论会发生,以及如何通过正确的因果框架来避免错误结论。
-
混淆变量的识别与处理:学会了如何识别"隐形杀手"般的混淆变量,并掌握了多种处理方法,从简单的分层调整到复杂的后门调整。
-
因果发现的算法思维:了解了如何从纯观测数据中推断因果结构,掌握了基于条件独立性测试和非线性回归的混合方法。
-
PyTorch实战能力:通过具体的代码实现,我们不仅理解了理论,更重要的是学会了如何用PyTorch将这些抽象概念转化为可执行的程序。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!



)


)










)
)
