文章目录
- 预处理语言模型的发展
- 预训练
- 语言模型
- 统计语言模型
- 神经网络语言模型
- 词向量
- onehot编码
- 词嵌入word embedding
- Word2Vec模型
- RNN和LSTM
- RNN
- LSTM
- ELMo模型
- 预训练
- 下游任务
- Attention
- 自注意力
- Masked Self Attention
- Multi-head Self Attention
- 位置编码
- Transformer概念
- GPT概念
- BERT概念
- 参考链接
预处理语言模型的发展
| 年份 | 技术 | 说明 |
|---|---|---|
| 2013 | word2vec | 静态编码,无法一词多义 |
| 2014 | GloVe | |
| 2015 | LSTM/Attention | 可以处理长距离文本,但存在长距离依赖问题(如梯度消失/爆炸),难以并行化训练 |
| 2016 | Self-Attention | |
| 2017 | Transformer | Transformer是一个模型结构,用自注意力机制self-attention替代循环结构,可实现并行化计算 |
| 2018 | GPT/ELMo/BERT/GNN | ELMo使用双向LSTM训练语言模型,然后将其中间层输出作为动态词向量,用于下游任务。BERT结合了ELMo的上下文思想和Transformer的结构 |
| 2019 | XLNet/BoBERTa/GPT-2/ERNIE/T5 | |
| 2020 | GPT-3/ELECTRA/ALBERT |
预训练
以图像领域的预训练为例,CNN一般用于图片分类任务,越浅的层学到的特征越通用(横竖撇捺),越深的层学到的特征和具体任务的关联性越强。
预训练的思想具体做法就是,对于一个具有少量数据的任务,首先通过一个现有的大量数据搭建一个CNN模型A,对模型A做出一部分改进(冻结或微调)得到模型B。
(1)冻结:浅层参数使用模型A的参数,高层参数随机初始化,浅层参数一直不变,然后利用现有小规模图片训练参数
(2)微调:浅层参数使用模型A的参数,高层参数随机初始化,然后利用现有小规模图片训练参数,但是在这里浅层参数会随着任务的训练不断发生变化
然后利用模型B的参数对模型A进行初始化,再通过任务中的少量数据对模型A进行训练。其中模型B的参数是随机初始化的。
语言模型
语言模型通俗点讲就是计算一个句子的概率
给定一句由n个词组成的句子W=w1,w2,⋯,wn,计算这个句子的概率P(w1,w2,⋯,wn),或者计算根据上文计算下一个词的概率P(wn|w1,w2,⋯,wn−1)。
语言模型有两个分支,统计语言模型和神经网络语言模型
统计语言模型
统计语言模型的基本思想就是计算条件概率
P ( w 1 , w 2 , ⋯ , w n ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) ⋯ p ( w n ∣ w 1 , w 2 , ⋯ , w n − 1 ) = ∏ i P ( w i ∣ w 1 , w 2 , ⋯ , w i − 1 ) \begin{align*} P(w_1,w_2,\cdots,w_n) & = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)\cdots p(w_n|w_1,w_2,\cdots,w_{n-1}) \\ & = \prod_i P(w_i|w1,w_2,\cdots,w_{i-1}) \end{align*} P(w1,w2,⋯,wn)=P(w1)P(w2∣w1)P(w3∣w1,w2)⋯p(wn∣w1,w2,⋯,wn−1)=i∏P(wi∣w1,w2,⋯,wi−1)
因为Wn词只和它前面的k的词有相关性,用马尔科夫链化简为二元语言模型公式如下
P ( w i ∣ w i − 1 ) = c o u n t ( w i − 1 , w i ) c o u n t ( w i − 1 ) P(w_i|w_{i-1})=\frac{count(w_{i-1},w_i)}{count(w_{i-1})} P(wi∣wi−1)=count(wi−1)count(wi−1,wi)
统计语言模型会出现数据稀疏的情况,即训练时未出现,测试时出现了的未登录单词,为了避免0值的出现,使用一种平滑的策略
P ( w i ∣ w i − 1 ) = c o u n t ( w i − 1 , w i ) + 1 c o u n t ( w i − 1 ) + ∣ V ∣ P(w_i|w_{i-1}) = \frac{count(w_{i-1},w_i)+1}{count(w_{i-1})+|V|} P(wi∣wi−1)=count(wi−1)+∣V∣count(wi−1,wi)+1
神经网络语言模型
神经网络语言模型(NNLM)引入神经网络架构来估计单词的分布,通过词向量的距离衡量单词之间的相似度。因此对于未登录单词,也可以通过相似词进行估计,进而避免出现数据稀疏问题。
NNLM学习任务是输入某个句中单词wt=bert前的t−1个单词,要求调整网络中的参数,正确预测单词bert,即最大化下面公式结果。
P ( w t = b e r t ∣ w 1 , w 2 , ⋯ , w t − 1 ; θ ) P(w_t=bert|w_1,w_2,\cdots,w_{t-1};\theta) P(wt=bert∣w1,w2,⋯,wt−1;θ)

词向量
将单词转成向量形式,叫词向量,有如下两种
onehot编码
对于onehot编码,如果采用余弦相似度计算向量间的相似度,任意两者向量的相似度结果都为0,即任意二者都不相关,也就是说onehot表示无法解决词之间的相似性问题。
词嵌入word embedding
对于神经网络语言模型的矩阵Q(这个矩阵Q和注意力机制中的Q不是一回事),是一个V x m,V代表词典大小,每一行的内容代表对应的单词的Word Embedding值。
矩阵Q通过训练学习正确的参数,将单词的onehot编码点乘矩阵Q,得到这个词的Word Embeddind向量Ci。
Word2Vec模型
2013年最火的用语言模型做Word Embedding的工具是Word2Vec
Word2Vec有两种训练方法
-
CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词
-
Skip-gram,和CBOW正好反过来,输入某个单词,要求网络预测它的上下文单词
神经网络语言模型NNLM主要任务是看到上文去预测下文,其中的Word Embedding只是其中的一个挂件
Word2Vec主要任务就是做Word Embedding
训练好的Word Embedding矩阵Q,就可以当作其他任务的预训练模型的参数,进行冻结或微调,应用于其他任务模型。
但是Word2Vec的词嵌入模型生成的词向量,无法做到一词多义
RNN和LSTM
RNN
传统的神经网络无法获取时序信息,然而时序信息在自然语言处理任务中非常重要。

每一个模块A都会把当前信息传递给下一个模块。
RNN的出现,让处理时序信息变为可能。但这里的时序一般指的是短距离的。
RNN存在梯度消失和梯度爆炸问题,即被近距离梯度主导,而远距离的梯度影响特别小。
LSTM
LSTM是为了解决RNN缺乏序列长距离依赖问题,LSTM的一个RNN门控结构(LSTM的timestap)
但是LSTM无法做到并行计算

ELMo模型
Word2Vec的词嵌入模型生成的词向量,无法做到一词多义
ELMo可以做到一词多义
ELMo采用了典型的两阶段过程:
- 第一个阶段是利用语言模型进行预训练;网络结构采用了双层双向LSTM
- 第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
预训练
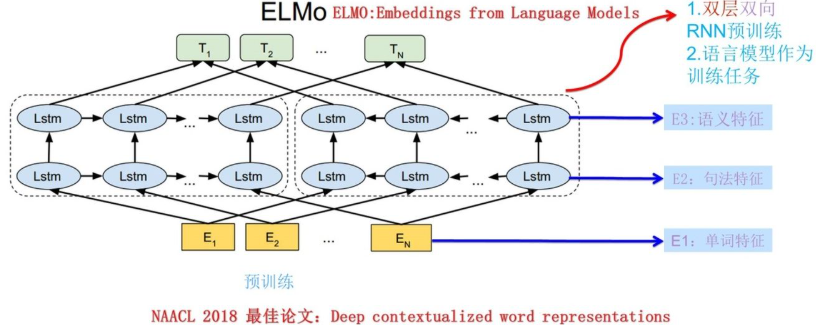
使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子,句子中每个单词都能得到对应的三个Embedding:
- 最底层是单词的Word Embedding;
- 往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;
- 再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。
下游任务

对于QA(question-answer)任务,输入问句为X
-
先将句子X作为预训练好的ELMo网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding
-
之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个;
-
然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
-
对于上图所示下游任务QA中的回答句子Y来说也是如此处理。
因为ELMo给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。
Attention
注意力模型从大量信息Values中筛选出少量重要信息,这些重要信息一定是相对于另外一个信息Query而言是重要的
从编码器的每个输入向量创建三个向量因此,对于每个单词,我们创建一个 Query 向量、一个 Key 向量和一个 Value 向量。这些向量是通过将嵌入向量乘以我们在训练过程中训练的三个矩阵来创建的。
Q/K/V的定义和作用
- Query(Q):表示当前需要关注的词(或位置)的“提问”,用于与其他位置的键(Key)进行匹配。
- Key(K):表示序列中每个词的“索引”,用于与 Query 计算相关性。
- Value(V):表示序列中每个词的“实际内容”,最终根据注意力权重加权求和得到输出。
- Query 是你的搜索关键词。
- Key 是数据库中的文档标题或关键词。
- Value 是文档的实际内容。 搜索引擎会用 Query 和 Key 计算匹配度,然后返回对应的 Value
按照如下流程计算出每个单词经过注意力层的输出向量Z,这时Thinking这个词经过注意力机制得到的向量Z就包含了这个词在所在句子中的重要程度了。即Think相对于Thinking和Machines这句话的加权输出。

自注意力
自注意力强调QKV三个矩阵都源自于输入X本身
因为Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征
每个单词的计算是可以并行处理的
但是由于文本长度增加时,训练时间也将会呈指数增长
Masked Self Attention
这里的Masked就是要在做语言模型(或者像翻译)的时候,不给模型看到未来的信息
例如在补全或生成回答时,每次生成一个单词后,当前回答变成从头开始到当前单词的句子,后面的单词未知,需要下一步生成。
Multi-head Self Attention
允许模型在不同的语义或位置组合上分配注意力权重,避免单一注意力头只能捕捉一种固定模式
将 Q/K/V 矩阵分割为多个独立的子空间(头),每个头学习不同的注意力模式

位置编码
Attention解决了长距离依赖问题,并且可以支持并行化。但是也丢弃了输入序列X的中的各个单词在句子中的位置序列关系。
因此在对X进行Attention计算之前,在X词向量中加上位置信息
参考https://www.cnblogs.com/nickchen121/p/16470569.html#tid-YGp2KR
某个单词的位置信息是其他单词位置信息的线性组合,这种线性组合就意味着位置向量中蕴含了相对位置信息。
Transformer概念


GPT概念
NLP中两种预训练方法:Feature-based Pre-Training和基于Fine-tuning的模式
前者以ELMo为代表,后者以GPT为典型

GPT是Generative Pre-Training的简称,生成式的预训练。主要基于Transformer的Decoder堆叠结构,不包含Encoder部分
GPT也采用两阶段过程:
- 第一个阶段:利用语言模型进行预训练;
- 第二个阶段:通过 Fine-tuning 的模式解决下游任务。
BERT概念
Bidirectional Encoder Representations from Transformers
它的核心特点是
- 基于 Transformer Encoder 架构,
- 使用双向注意力机制(bidirectional attention)建模上下文,
- 通过 Masked Language Model 进行预训练,提升自然语言理解能力。
BERT参考了 ELMO 模型的双向编码思想、借鉴了 GPT 用 Transformer 作为特征提取器的思路、采用了 word2vec 所使用的 CBOW 方法

BERT和ELMo、GPT比较
- BERT和ELMo区别在与,ELMo使用LSTM作为特征提取器,有长距离问题和无法并行计算问题,而BERT用transformer块作为特征提取器,解决了上述问题。
- BERT和GPT的区别在于,BERT使用transformer encoder,将GPT的单向编码改成双向编码,虽然舍弃了文本生成能力,但是换来了更强的语义理解能力。
参考链接
https://www.cnblogs.com/nickchen121/p/16470569.html#tid-YGp2KR
https://blog.csdn.net/qq_62954485/article/details/146191691
![浏览器工作原理24 [#]分层和合成机制:为什么css动画比JavaScript高效](http://pic.xiahunao.cn/浏览器工作原理24 [#]分层和合成机制:为什么css动画比JavaScript高效)















】大模型为什么需要RAG)


