YOLOv8-cls epochs与数据量的关系
(1)机器学习小白入门YOLOv :从概念到实践
(2)机器学习小白入门 YOLOv:从模块优化到工程部署
(3)机器学习小白入门 YOLOv: 解锁图片分类新技能
(4)机器学习小白入门YOLOv :图片标注实操手册
(5)机器学习小白入门 YOLOv:数据需求与图像不足应对策略
(6)机器学习小白入门 YOLOv:图片的数据预处理
(7)机器学习小白入门 YOLOv:模型训练详解
(8)机器学习小白入门 YOLO:无代码实现分类模型训练全流程
(9)机器学习小白入门 YOLOv:YOLOv8-cls 技术解析与代码实现
(10)机器学习小白入门 YOLOv:YOLOv8-cls 模型评估实操
(11)机器学习小白入门YOLOv:YOLOv8-cls epochs与数据量的关系
(12)机器学习小白入门YOLOv:YOLOv8-cls 模型微调实操
在 YOLOv8-cls 模型微调中,epochs(训练轮数)与数据量的关系是影响模型性能的核心因素,二者需动态匹配以避免过拟合或欠拟合。以下从具体场景、调整逻辑和实操建议三方面展开说明:
先说一下基础概念:
- 欠拟合:训练集和验证集的表现都很差(比如准确率低、误差大)
类比:代码在开发环境就跑不通,连基本功能都实现不了 - 过拟合:训练集表现极好(误差很小),但验证集表现突然变差(误差显著增大)
类比:代码在开发时的测试用例全通过,但换一组新测试用例就大量报错
一、数据量与 epochs 的基础匹配逻辑
1. 数据量少(如 100-1000 张样本)
-
特点:数据多样性有限,模型易记住训练样本细节(过拟合风险高)。
-
建议 epochs:10-20 轮。
-
原理:少量数据经过较少轮次即可让模型学习到核心特征,过多轮次会导致模型 “死记硬背” 噪声(如图片背景、无关细节),反而降低泛化能力。
2. 数据量中等(如 1000-10000 张样本)
-
特点:涵盖一定类别差异,但仍需控制训练强度。
-
建议 epochs:20-40 轮。
-
原理:中等数据量需要足够轮次让模型遍历不同样本组合,捕捉类别共性,但超过 40 轮后可能因重复学习导致过拟合。
3. 数据量庞大(如 10000 张以上)
-
特点:样本多样性丰富,模型有足够 “素材” 学习规律。
-
建议 epochs:40-50 轮(甚至更高,需结合验证指标判断)。
-
原理:大量数据需要更多轮次才能让模型充分学习各类别特征分布,且因样本多样,过拟合风险较低。
二、两者相互影响的核心表现
1. 数据量固定时,epochs 过高 / 过低的影响
-
过高:训练损失持续下降,但验证损失先降后升(过拟合),表现为模型在训练集准确率接近 100%,但在验证集准确率骤降。
-
过低:训练与验证损失均较高(欠拟合),模型未充分学习数据规律,对新样本的预测能力差。
2. epochs 固定时,数据量不足 / 过剩的影响
-
数据量不足:即使 epochs 适中,模型也易过拟合(如 100 张样本训练 30 轮,模型会记住每张图的细节)。
-
数据量过剩:若 epochs 不足,模型可能 “学不完” 数据中的特征(如 10 万张样本仅训练 10 轮,每轮仅见 10% 样本),导致欠拟合。
三、实操中如何动态调整?
1. 通过验证损失曲线判断
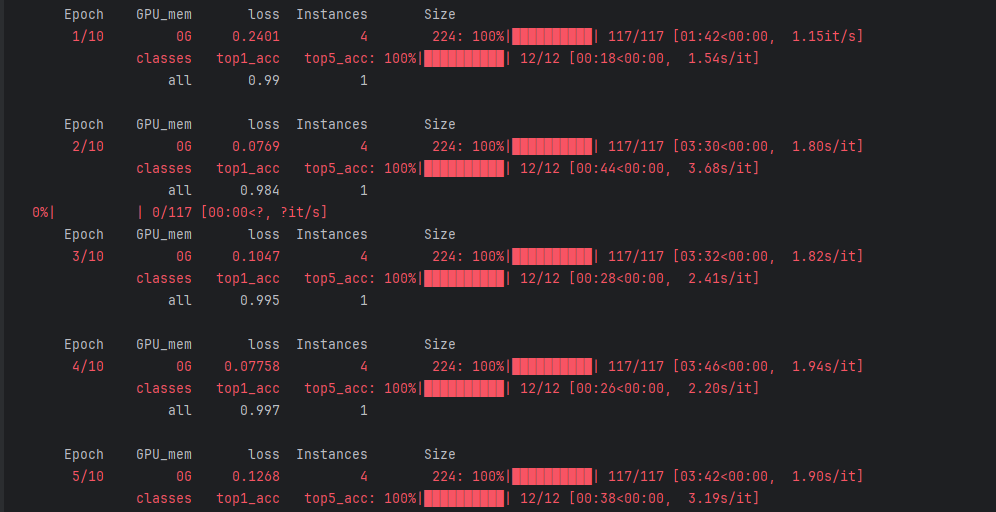
loss:损失值,衡量预测结果与真实标签的差距,数值越小模型表现越好(如从 0.2401 逐步降到 0.07758 后小幅波动)
-
训练过程中,若验证损失连续 5-10 轮不再下降(甚至上升),无论当前 epochs 是否达到预设值,都应停止训练(早停策略)。
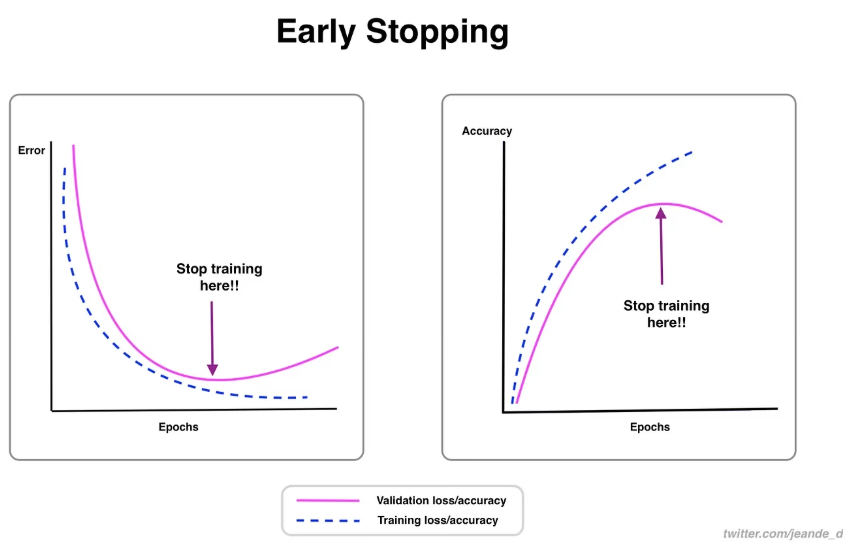
-
示例代码(启用早停):
model.train(data='dataset.yaml',epochs=50, # 最大轮数patience=10, # 验证损失10轮不下降则停止..
)
2. 数据量与 epochs 的经验公式
对于分类任务,可参考:
总训练样本数 × epochs ≈ 50000-200000(根据类别复杂度调整)
- 简单类别(如 3-5 类):取下限(5 万),例如 5000 张样本对应 10 轮(5000×10=5 万)。
- 复杂类别(如 50 类以上):取上限(20 万),例如 10000 张样本对应 20 轮(10000×20=20 万)。
3. 数据增强对两者关系的影响
当数据量较少时,启用数据增强(`augment=True`)可等效增加数据多样性,此时可适当提高 epochs(如原 10 轮可增至 15-20 轮),但需配合验证损失监控防止过拟合。
总结
epochs 与数据量的核心关系是 “让模型在有限数据中充分学习,同时避免过度记忆”。实际微调时,不应机械遵循 “10-50 轮” 的建议,而需根据数据量大小、类别复杂度及验证指标动态调整,通过早停策略和经验公式找到最佳平衡点。例如:
-
500 张样本 + 简单类别 → 15-20 轮
-
5000 张样本 + 中等复杂度 → 30-40 轮
-
10000 张样本 + 高复杂度 → 40-50 轮(或按早停策略终止)。










)




网络层 路由协议)
Pytorch中求逆torch.inverse和解线性方程组torch.linalg.solve有什么关系)


