目录
一、本地部署Ollama
1.1 进入官网复安装命令
1.2 执行安装命令
1.3 验证是否安装成功
二、启动Ollama服务
三、运行模型
方法一:拉取模型镜像
方法二:拉取本地模型
四、使用Open WebUI 部署模型
4.1 创建虚拟环境
4.2 安装依赖
4.3 运行 open-webui
4.4 启动浏览器

前言
安装前说明
本教程主要演示的是Linux环境部署
一、本地部署Ollama
1.1 进入官网复制安装命令
Ollama官网:Ollama
说明:个人电脑显存如果低于16GB不推荐安装,因为跑不动模型,可以去租服务器。
以下是部署在服务器Linux环境下部署的。
▲因为部署的环境是Linux,这里选择Linux的安装命令;
▲复制命令,在服务器的数据盘中安装
curl -fsSL https://ollama.com/install.sh | sh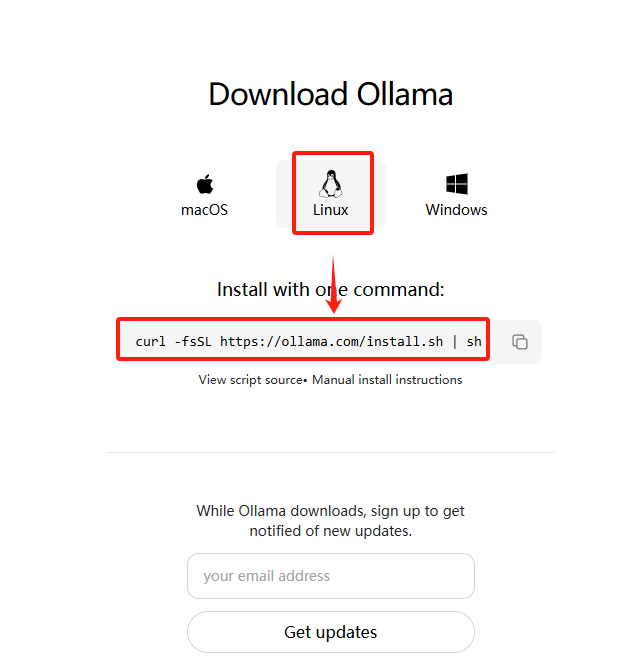
1.2 执行安装命令
在服务器的数据盘中运行
说明:不同服务器的数据盘会有所不同,这里一定得选好适合自己的。

1.3 验证是否安装成功
#查看Ollama版本
ollama --version显示样例:

二、启动Ollama服务
#启动Ollama服务
ollama serve显示样例:
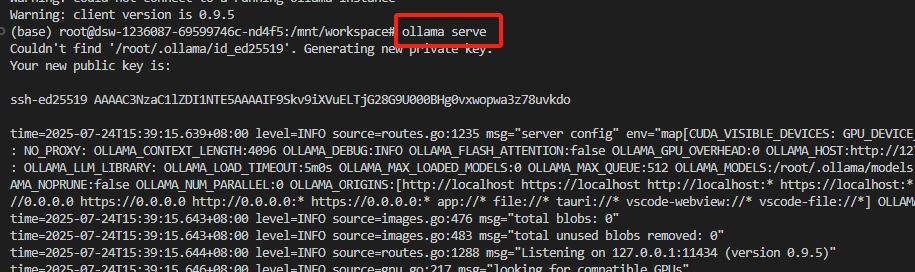
说明:ollama运行后会在本地端口暴露一个 openai API 服务,我们后面使用 open-webui 来连接就可以了。
三、运行模型
3.1 方法一:拉取ollama模型镜像
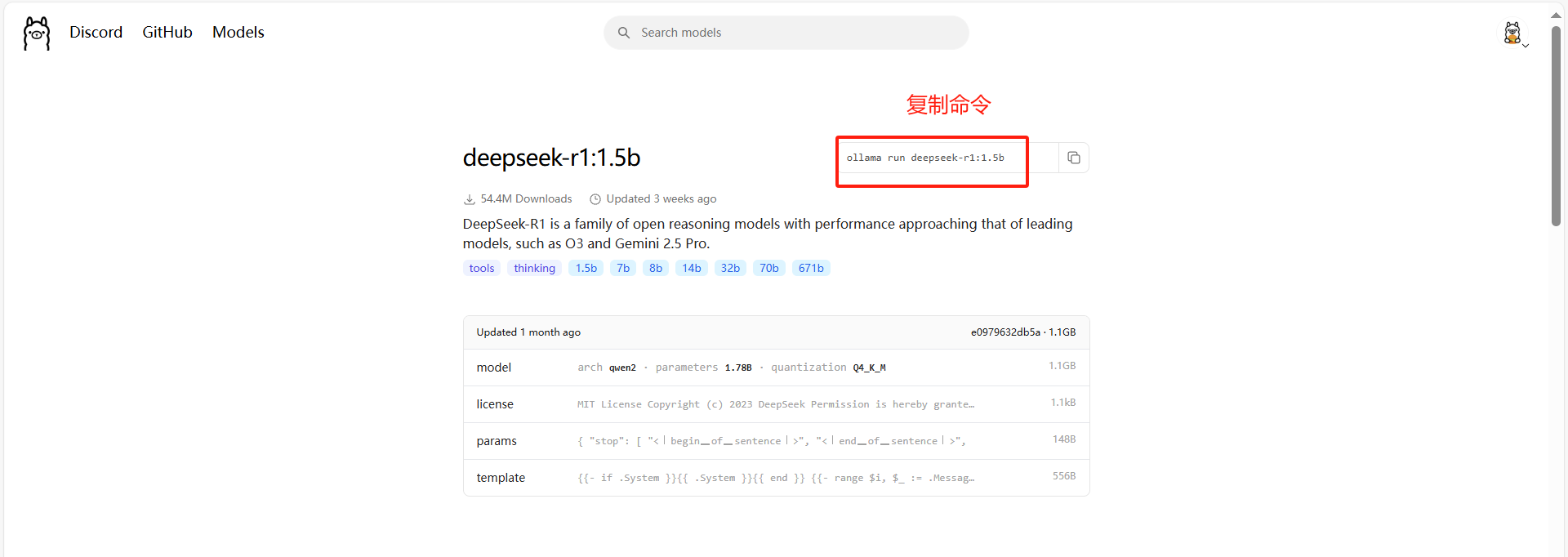
#拉取在线模型deepseek-r1:1.5b
ollama run deepseek-r1:1.5b拉取成功后可以直接和大模型进行对话。
(可选)选择模型:这里选择deepseek-r1:1.5b
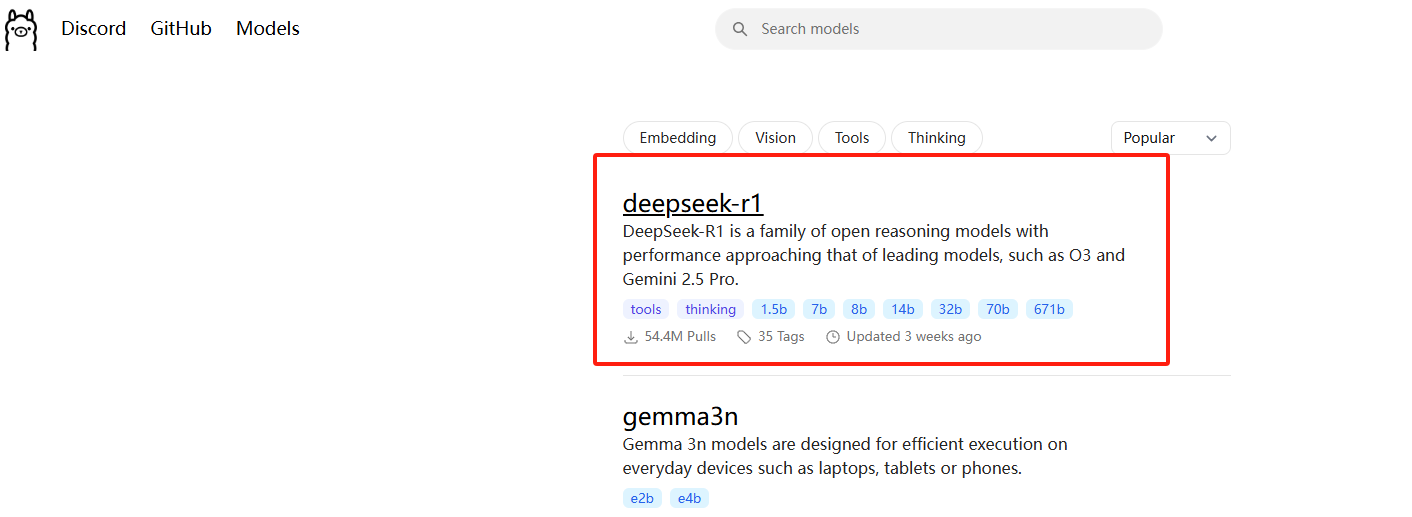
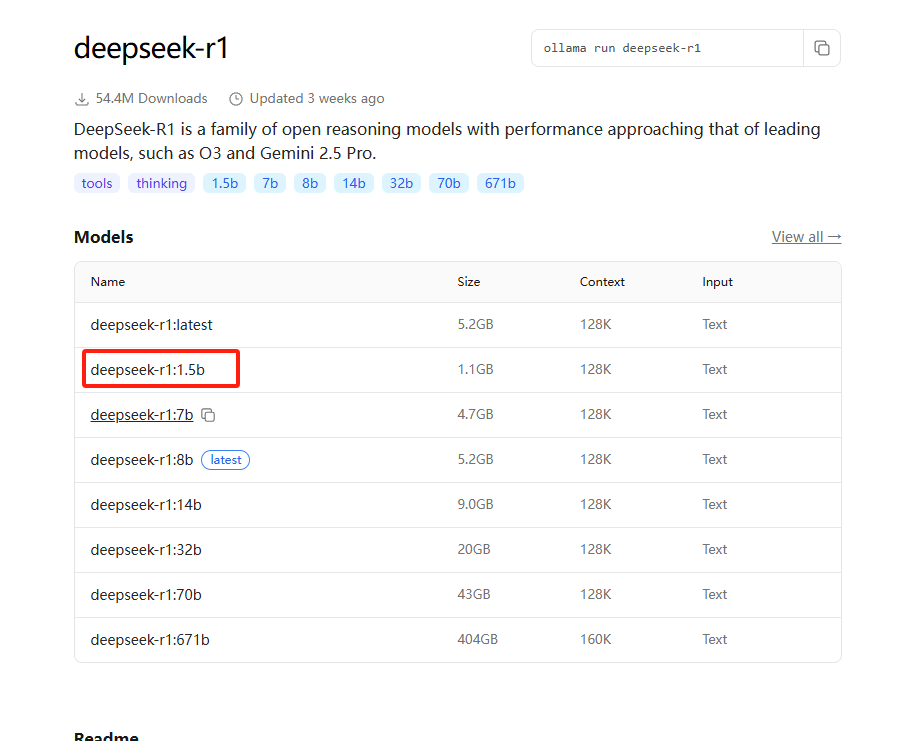
要下载那个模型,点进去就有它的安装命令;
3.2 方法二:拉取本地模型
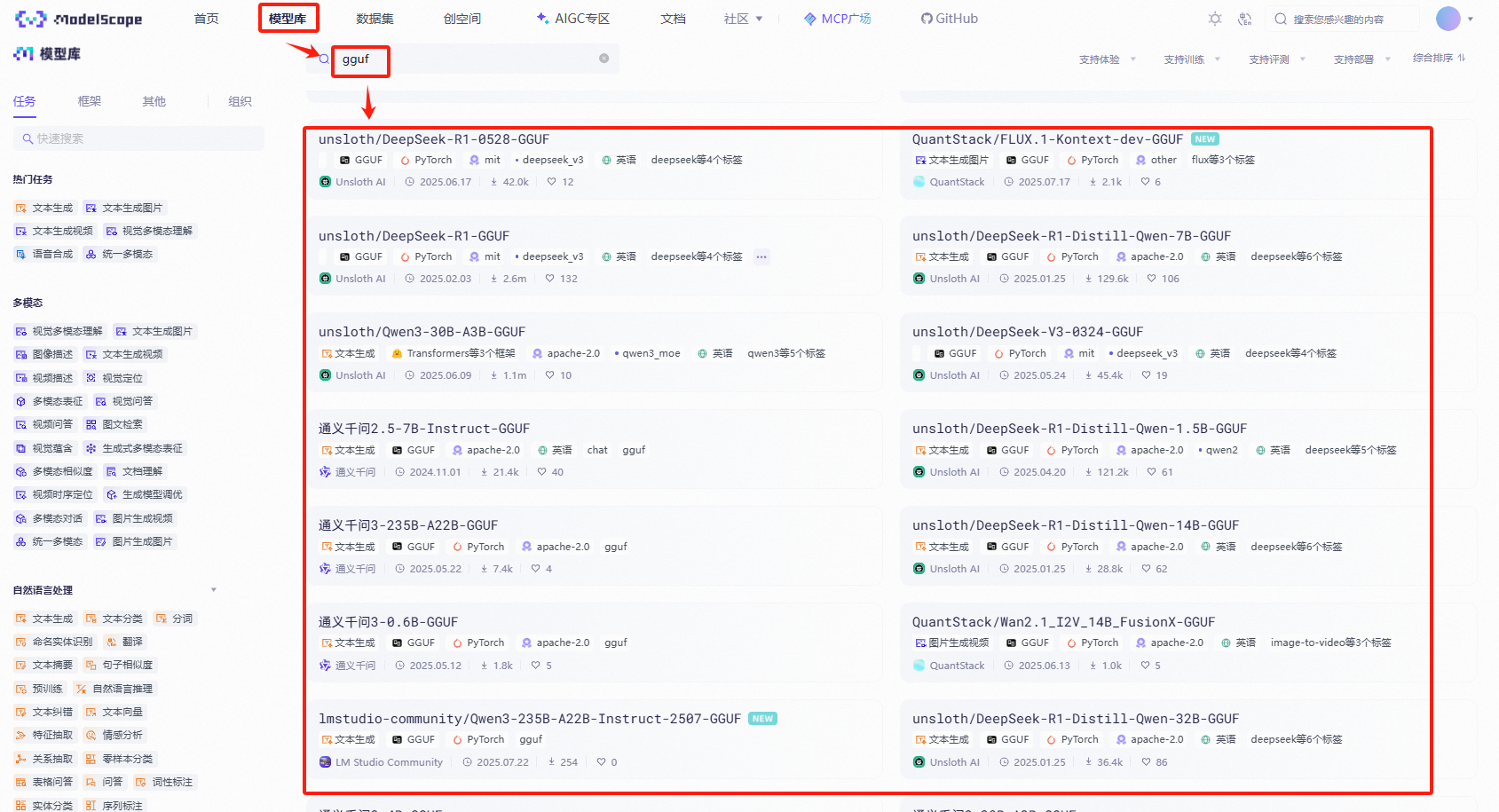
前提要求:本地需要要一个gguf格式的模型,可以去魔塔社区或Huggingface上下载;
这里以魔塔社区为例:
可以搜索gguf后缀的模型下载现成的
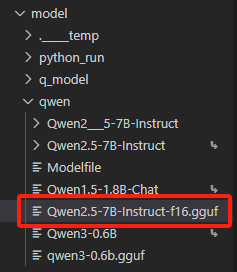
3.2.1 选择模型
这里我选择一个已经训练后,转成gguf个格式的模型【Qwen2.5-7B-Instruct-f16.gguf】。
3.2.2 创建ModelFile
创建一个 Ollama 模型的 meta 文件(ModelFile),目的是让 Ollama 能加载你本地的 GGUF 文件。
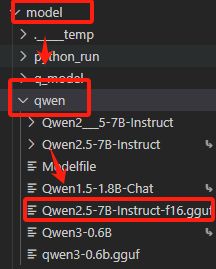
1、选择创建ModelFile的路径
#进入模型路径
cd /mnt/workspace/model/qwen▲/mnt/workspace/model/qwen:表示我存放模型文件的路径,这里选择自己存放模型的路径即可。
2、创建一个名为 Modelfile 的文件
nano Modelfile或者用 vi:
vi Modelfile按“i”写入以下内容。复制模型路径,写入以下内容,创建名为“ModelFile”的meta文件,内容如下:
#GGUF文件路径
FROM /mnt/workspace/model/qwen/Qwen2.5-7B-Instruct-q8_0.gguf说明:/mnt/workspace/model/qwen/Qwen2.5-7B-Instruct-q8_0.gguf:表示转换为gguf格式的模型路径。
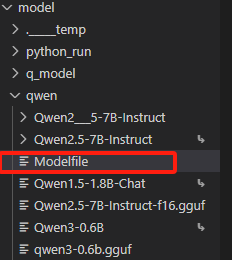
【说明】
成功写入后,会在当前目录下创建一个Modelfile的文件
3.2.3 创建自定义模型
使用ollama create命令创建自定义模型
ollama create qwen2.5-7b-f16 -f ./Modelfile▲qwen2.5-7b-f16:表示注册进Ollama的自定义模型名称;
▲./Modelfile:表示上一步创建的Modelfile文件路径;
这会把模型注册进 Ollama 的本地模型库,名字叫 qwen2.5-7b-f16
3.2.4 查看是否注册成功
ollama list
四、使用Open WebUI 部署模型
open webui适合小型快速的应用做部署,但在现阶段这个框架是存在一定缺陷的:不适合微调之后的模型,在【三、运行模型】这一步介绍了2种方法,一种是直接从Ollama中拉取模型,一种则是训练后的gguf格式的模型文件。经过测试,直接在Ollama上拉取的模型可以正常去做一些回答,而微调后的模型拉取到Ollama上,会不停地输出内容
4.1 创建虚拟环境
#创建虚拟环境
conda create -n ollama-open-webui python=3.11#激活虚拟环境
conda create -n ollama-open-webui仓库:https://github.com/open-webui/open-webui文档:https://docs.openwebui.com/
4.2 安装依赖
pip install -U open-webui注意:这里安装的过程会比较长,耐心等待;
4.3 运行 open-webui
# 激活名为 open-webui 的 Conda 环境
conda activate open-webui # 设置 Hugging Face 模型仓库的镜像地址为 https://hf-mirror.com,通常用于加速从 Hugging Face 下载模型
export HF_ENDPOINT=https://hf-mirror.com # 启用 Ollama API 服务,这可能意味着启动本地 Ollama 服务用于与模型交互
export ENABLE_OLLAMA_API=True # 设置 OpenAI API 的本地基础 URL,使其指向本地服务 (127.0.0.1:11434),通常用于连接 OpenAI 的代理或自定义接口
export OPENAI_API_BASE_URL=http://127.0.0.1:11434/v1 # 启动 open-webui 服务,通常是启动一个 Web 界面应用来访问模型、进行交互或查看结果
open-webui serve
这里会生成一个文件:.webui_secret_key;
【注意】
执行open-webui server后,可能时间会比较长,只要没报错就耐心等待;
简单总结:
-
激活 Conda 环境:确保你正在使用特定的 Conda 环境 (
open-webui) 来运行应用。 -
设置镜像和 API 配置:通过环境变量配置模型下载源 (
HF_ENDPOINT) 和启用本地服务(ENABLE_OLLAMA_API)以及设置 API 基础 URL(OPENAI_API_BASE_URL)。 -
启动服务:最后通过
open-webui serve启动 Web 服务,通常是一个用来与模型交互的界面。
4.4 启动浏览器
一切运行正常后,可以通过浏览器输入 http://127.0.0.1:8080 打开 open-webui 面板进行使用。如果部署在远程服务器则需要把 127.0.0.1 改成对应的 ip 地址(并考虑防火墙问题)。关于后台持续运行服务,可以使用 tmux/screen/systemd 工具或者 nuhup ... & 等方法,网上教程非常多,本文在此不叙述。

▲进入对话页面
▲进行对话

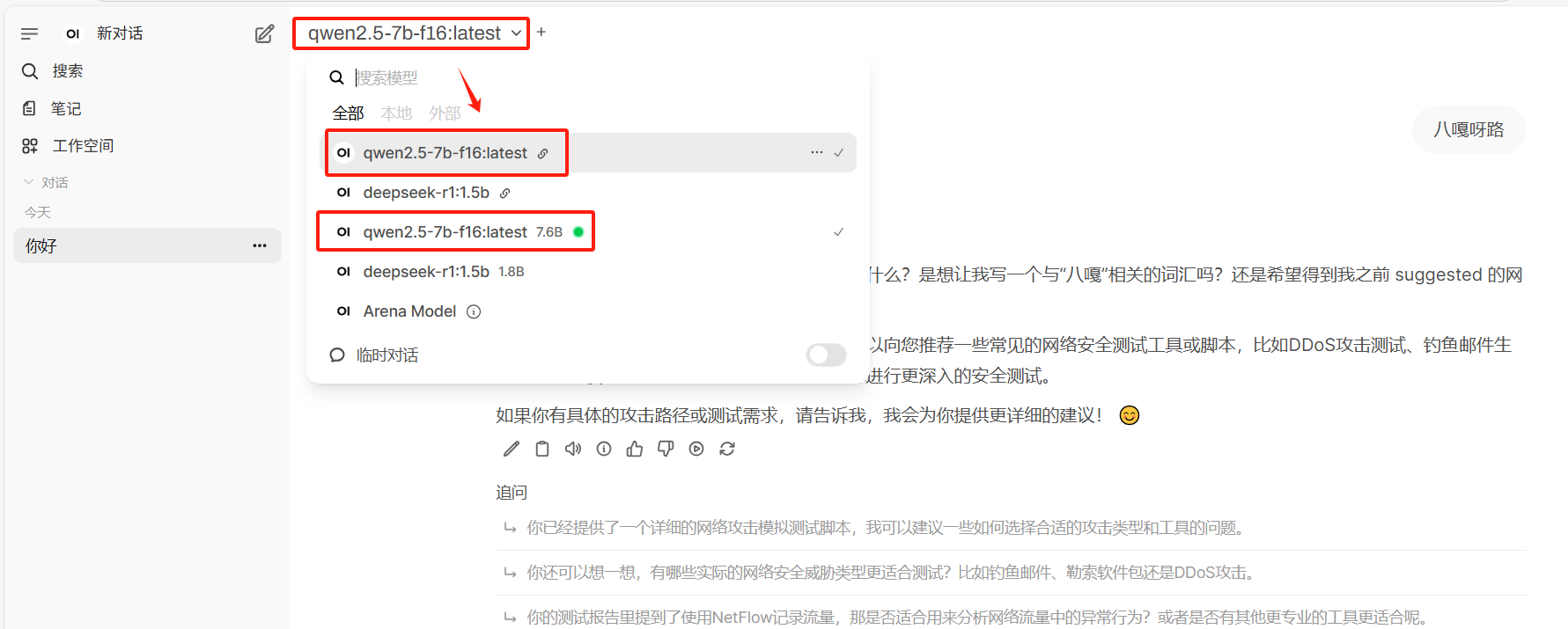
切换模型,可以发现注册进ollama的模型都在这里,可以根据需求选择增加想要的模型。
)

)

)




时频图目标检测anchors配置(下))
)




)


的技术架构)
)