一、chunked prefills
1.1 chunked prefills核心思想
ORCA虽然很优秀,但是依然存在两个问题:GPU利用率不高,流水线依然可能导致气泡问题。
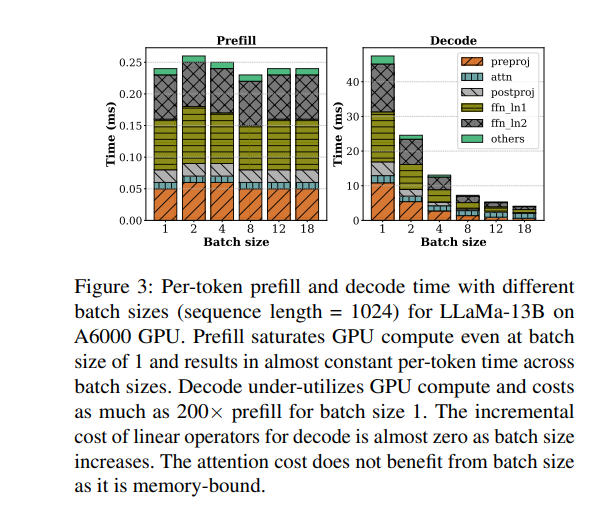
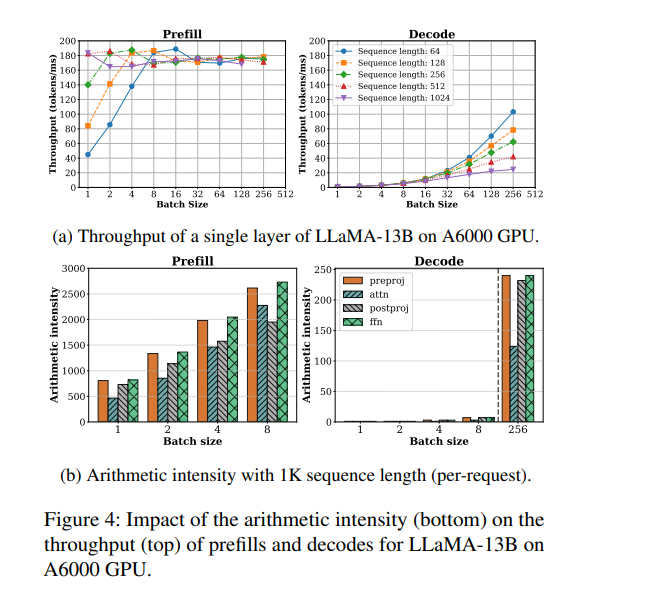
我们来看sarathi-serve做的一个实验。左右两图分别刻画了在不同的batch size下,prefill和decode阶段的处理时间和计算强度。可以观察到如下:
-
prefill 阶段是计算密集型(compute-bound),主要时间花在大规模的线性变换和矩阵运算上,算力利用率高,但内存带宽利用率不高。即使 batch size 很小,prefill 吞吐量也很快趋于饱和,增大 batch size 对提升吞吐帮助有限(比如 batch size 从 4 增加到 8),甚至可能因算力饱和而下降。
-
decode 阶段是内存密集型(memory-bound),大部分时间消耗在读取 KV cache 和模型权重上,算力利用率很低。此时增大 batch size 可以显著提升吞吐,因为可以合并多次权重和 KV cache 的读取,减少 IO 次数,让空闲的算力得到利用。
混合批处理的优势在于:
-
prefill 阶段可以搭载(piggyback)在 decode 阶段未被充分利用的算力上,提升整体算力利用率。
-
decode 阶段可以和 prefill 阶段共享一次权重读取,减少内存带宽压力,提高带宽利用率。
-
这样,GPU 的计算单元和内存带宽都能被更充分利用,整体吞吐和 QPS 明显提升。
-
回顾 ORCA 的 Selective Batching 的策略就会发现,其行为具有一定的随机性:一个 batch 中包含多少条 prefill 请求、多少条 decode 请求,并没有明确控制,仅仅是按照“先到先服务”的策略动态拼装而成。这就带来一些问题:
-
若某个 batch 中包含大量 prefill 请求,或某些 prefill 请求本身 token 很长,就会导致 prefill tokens 占据大量计算资源,使整个 batch 变得 compute-bound;
-
相反,若 batch 中以 decode 请求为主,例如所有请求都处于推理阶段,或没有新的输入序列可调度,则该 batch 很可能是 memory-bound 的,导致算力无法充分利用。
-
在流水线并行中同样可能产生气泡。
虽然流水线并行(Pipeline Parallelism)可以扩展大模型的并行能力,但也引入了一个典型问题:流水线气泡(pipeline bubbles)。所谓“气泡”,是指由于不同阶段间计算不均衡或等待导致的 GPU 空闲时间,从而造成资源浪费和吞吐下降。
Orca 流水綫氣泡
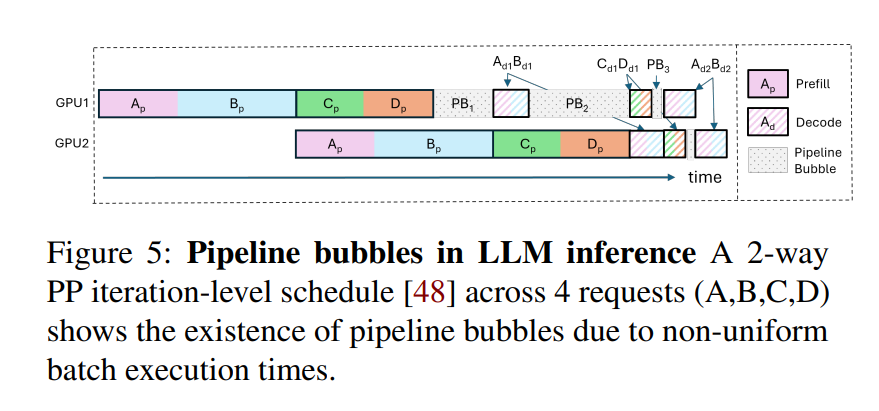
Orca 系统尝试通过 迭代级调度(iteration-level scheduling) 来缓解这一问题,但在实际推理中仍然可能出现气泡,主要原因包括:
-
PB1:连续 micro-batch 的 prefill token 数量差异大。例如,若 AB 和 CD 分别是两个 micro-batch,且 AB 的 token 总数显著多于 CD。当 GPU1 完成 Cp 和 Dp 的 prefill 后,必须等待 GPU2 完成 AB 的 prefill,才能继续执行 Ad1 和 Bd1 的 decode。GPU1 在此期间处于空转状态,形成 PB1 类型气泡。
-
PB2:prefill 阶段和 decode 阶段计算负载差异大。PB2 类型气泡出现在 prefill 和 decode 阶段相继执行时。以 Ad1 和 Bd1 为例,它们的 decode 阶段每次仅处理一个 token,计算时间极短;而此时 GPU2 正在处理 Cp 和 Dp 的 prefill,涉及多个 token,耗时较长,导致 GPU1 无法及时执行后续任务,资源被浪费,形成 PB2 气泡。
-
PB3:decode 阶段上下文长度差异导致计算时间不均。decode 阶段的计算开销受上下文长度(即 KV cache 长度)影响较大。不同 micro-batch 中请求的上下文长度不一,导致 decode 阶段耗时不同,从而在流水线上产生等待,形成 PB3 类型气泡。
为了进一步解决上述问题,Sarathi-Serve 提出了一种兼顾吞吐量与延迟的调度机制,其中包括两个核心设计思想:chunked-prefills(分块预填充) 和 stall-free scheduling(无阻塞调度)。
-
chunked-prefills 将一个 prefill 请求拆分为计算量基本相等的多个块(chunk),并在多轮调度迭代中逐步完成整个 prompt 的 prefill 过程(每次处理一部分 token)。
-
stall-free scheduling 则允许新请求在不阻塞 decode 的前提下,动态加入正在运行的 batch,通过将所有 decode 请求与新请求的一个或多个 prefill chunk 合并,构造出满足预设大小(chunk size)的混合批次。
Sarathi-Serve 建立在 iteration-level batching 的基础上,但有一个重要区别:它在接纳新请求的同时,限制每轮迭代中 prefill token 的数量。这样不仅限制了每轮迭代的延迟,还使其几乎不受输入 prompt 总长度的影响。通过这种方式,Sarathi-Serve 将新 prefill 的计算对正在进行的 decode 阶段的 TBT 影响降到最低,从而同时实现了高吞吐量和较低的 TBT 延迟。
此外,Sarathi-Serve 构建的混合批次(包含 prefill 和 decode token)具有近似均衡的计算需求。结合流水线并行(pipeline-parallelism),这使我们能够创建基于微批处理(micro-batching)的均衡调度,从而显著减少流水线气泡(pipeline bubbles),提升 GPU 利用率,实现高效且可扩展的部署。
chunked-prefills 流水綫氣泡示意圖:
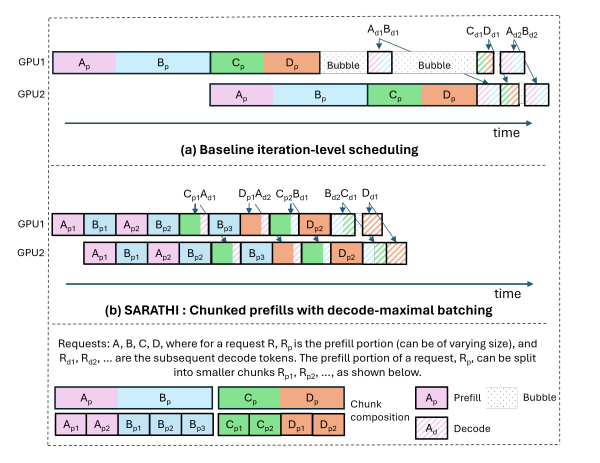
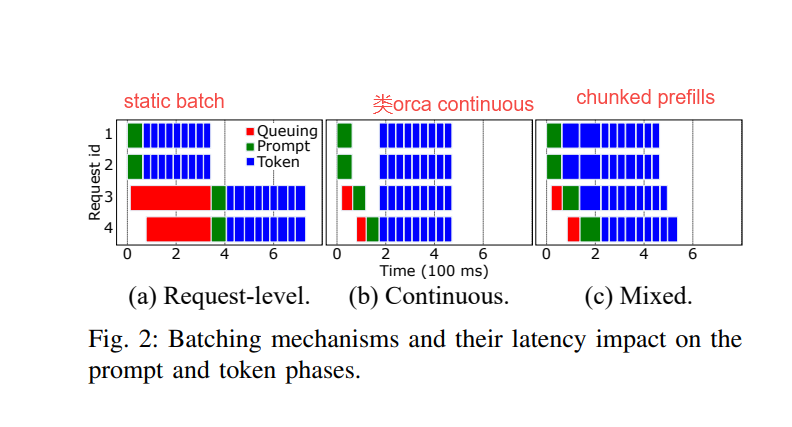 图片来源:Splitwise: Efficient generative LLM inference using phase splitting
图片来源:Splitwise: Efficient generative LLM inference using phase splitting
1.2 实现
要使用预填充来附带解码,我们需要实现两件事。
-
我们需要确定可以携带的解码的最大可能批量大小,并确定构成预填充块的预填充token的数量。
-
为了真正利用混合批的GPU饱和预填充计算来提高解码效率,我们需要将预填充块和批解码的线性运算计算融合到一个操作中。动态分割的关键是将较长的预填充分成更小的块(chunk),从而通过将预填充块与多个解码任务组合形成批处理,并充分调动 GPU,这个过程称为捎带确认(piggybacking)。
chunk的大小
该实现中很重要的一点就是如何确定chunk的大小,Sarathi提供了“固定”和“动态”两种chunk size策略。
-
固定策略:该策略会依据硬件和profilling实验计算出来一个可以最大限度把GPU利用起来的单batch中的tokens数量。这个是batch的token总配额(默认512),其在运行过程中会尽量保持不变,而prefill tokens数量会随着decode tokens的增减而变化,但是因为decode tokens数量一般也不多,所以prefill tokens数量和整体batch tokens配额也不会相差很多。
-
动态策略:该策略希望对于一个请求,其prefill tokens的数量能随着迭代次数的增加而减少。这是因为如果一个prompt特别长,它在每次迭代中都会占据很多计算资源,从而历史累积的decode序列和新来的请求受到影响。因此对于这种新进入batch的长序列请求,Sarathi会在开始多配置一些prefill tokens额度,后续随着迭代次数的增加,递减这个配额,降低它对其它迭代的影响。
-
较小的 chunk size 有助于减少 TBT 延迟,因为每轮 iteration 涉及的 prefill token 更少,执行速度更快。
但如果 chunk size 过小,也会带来一系列问题:
-
每个 chunk 的 Attention 操作都需重复读取此前的 KV cache,增加内存访问负担;
-
算术强度下降,GPU 利用率降低;
-
kernel 启动的固定开销更频繁,影响整体效率。
因此,在确定 chunk size 时,需要在 prefill 的计算开销与 decode 的延迟之间做出合理权衡。可以通过一次性对不同 token 数量的 batch 进行 profiling,找出在不违反 TBT SLO 的前提下,单个 batch 可容纳的最大 token 数,从而设定合适的 chunk size。论文中借助工具 Vidur 自动化完成这一过程,确保最终配置既能最大化吞吐量,又能有效控制延迟。
固定 chunk size 是包含 prefill + decode token 的总数。例如,512 token 的 batch 可能包含:2 个 decode 请求(各 1 token)+ prefill 请求 1(400 个 token)+ prefill 请求 2(110 个 token)= 512 个 token。
而动态 chunk size 对于不同阶段的 prefill 请求是不一样的,比如 chunk_sizes 列表是 [1024, 512, 256],一个 batch 可能包含 2 个 decode 请求(各 1 个 token)+ prefill 请求 1(250 个 token,阶段 3)+ prefill 请求 2(772 个 token,阶段 1,1024-2-250=772)= 1024 个 token。
-
在实际调度过程中,Sarathi-Serve 会优先调度正在进行的 decode 请求,因为每个 decode 仅消耗一个 token,且对延迟最为敏感,调度器会根据 KV cache 的容量判断是否仍可继续添加 decode 请求。随后,系统会在剩余的 token 预算范围内处理尚未完成的 prefill 请求,优先填满一个 prefill 请求中的 token,再继续处理下一个,在预算允许的情况下可连续处理多个 prefill 请求。若仍有剩余 token 预算,则进一步接纳新的 prefill 请求加入当前批次。系统会确保当前调度轮次中 decode 和 prefill 的 token 总数不超过预设的 chunk size。
stall-free scheduling(无阻塞调度)
-
prefill 优先的调度策略(prefill-prioritized schedules):
-
vLLM 会优先调度尽可能多的 prefill 请求,只有在完成这些 prefill 后才恢复 decode,从而造成 decode 阶段的阻塞,导致 TBT 延迟上升。
-
Orca 和 vLLM 都采用 FCFS(先来先服务)的 iteration-level batching 策略,并同样优先处理 prefill 请求。但在 batch 组成策略上有所不同:vLLM 仅支持纯 prefill 或纯 decode 的 batch,而 Orca 支持 prefill 和 decode 的混合 batch。尽管如此,Orca 的混合 batch 在包含长 prompt 时执行时间依然较长,decode 阶段依旧受到影响,无法避免 decode 阻塞。
-
decode 优先的调度策略(decode-prioritized schedules):
-
FasterTransformer 采用 request-level batching 策略,在当前请求的 decode 阶段全部完成之前,不会调度任何新的请求。例如在下图中,请求 C 和 D 的 prefill 将被阻塞,直到请求 A 和 B 完全退出系统。该策略虽然可以显著降低 TBT 延迟,但也牺牲了系统整体吞吐量。
-
无阻塞(stall-free)的调度策略:
-
Sarathi-Serve 同样支持 prefill 和 decode 的并行执行,但相比 Orca,它通过精细控制每个 batch 中 prefill token 的数量,确保 decode 几乎不受影响。与 FasterTransformer 相比,Sarathi 的 decode 时间只略有延长(把 Sarathi-Serve 的绿色块和 FasterTransformer 的红色块相比,可以发现绿色块只长了一点),却显著提升了吞吐量,实现了低延迟与高吞吐的兼得。sarathi-serve允许decode和prefill一起做,但是它通过合理控制每个batch中prefill tokens的数量,使得decode阶段几乎没有延迟。这样即保了延迟,又保了吞吐。
-
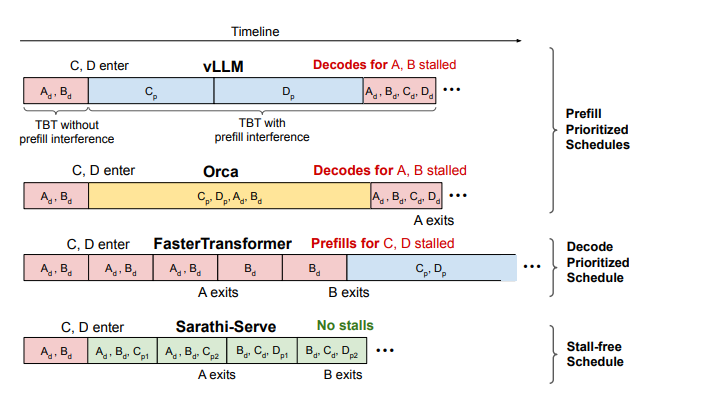
圖片來源:Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
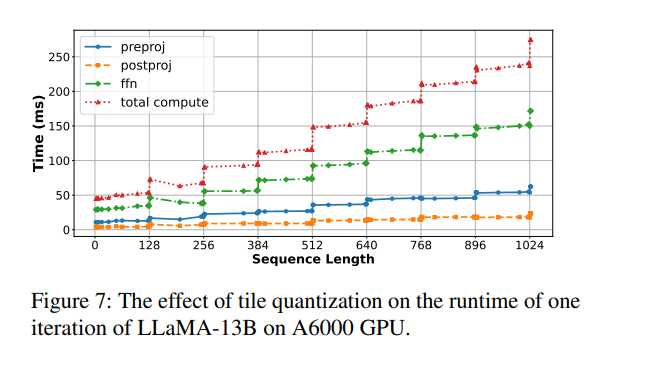
避免 tile quantization 效应
GPU 执行矩阵乘法时通常采用 tile 分块机制(例如 tile size = 128),只有当矩阵维度是 tile 的整数倍时,资源利用率才最高。
如果 chunk size 刚好超过 tile size 的倍数(例如 257),就会导致 thread blocks 内部部分线程空闲或执行无效计算,即“空转”,从而引发突发性的计算时间激增。下图展示了这一现象:当序列长度从 256 增加到 257,仅增加 1 个 token,延迟却从 69.8ms 飙升至 92.33ms,涨幅高达 32%。
当序列长度恰好是 tile size(128)的整数倍时,如 128、256、384 等,运行时间上升相对平稳;而一旦略微超过 tile 边界(例如从 256 到 257),计算时间则会急剧增加。
这是因为 GPU 的矩阵乘法是按 tile 并行执行的,如果维度不是 tile 的整数倍,部分 tile 无法充分利用,导致计算资源浪费,这就是所谓的 tile quantization overhead。
为避免这种问题,推荐的做法是:选择合适的 chunk size,并使其与搭载(piggyback) 的 decode token 数之和是 tile size 的整数倍,从而保持矩阵维度对齐,确保计算效率最优。
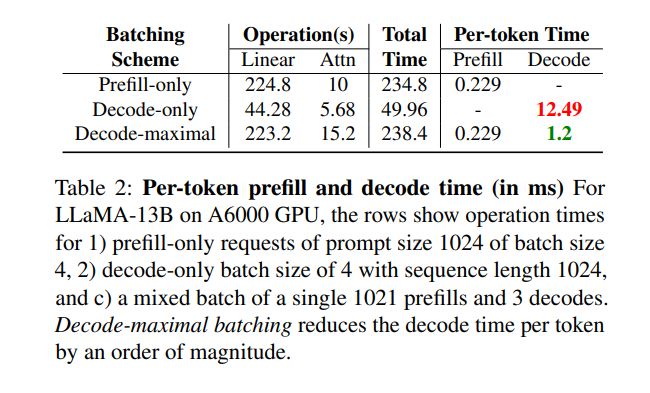
测试效果
-
仅包含 prompt 的请求(prompt 长度为 1024,batch 大小为 4);
-
仅包含 decode 的请求(batch 大小为 4,序列长度为 1024);
-
一个混合 batch,包括 1 个长度为 1021 的 prefill 请求和 3 个 decode 请求。
结果表明,混合 batch 能将每个 token 的解码时间显著降低一个数量级,大幅提升整体推理效率;同时,prefill 阶段的耗时几乎没有变化。
二、引用文献
[1] Orca: A distributed serving system for transformer-based generative models https://www.usenix.org/system/files/osdi22-yu.pdf
[2] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills https://arxiv.org/pdf/2308.16369
[3] DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference https://arxiv.org/pdf/2401.08671
[4] Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
https://arxiv.org/pdf/2403.02310
[5] Splitwise: Efficient generative LLM inference using phase splitting
https://arxiv.org/abs/2311.18677
[6] DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
https://arxiv.org/abs/2401.09670
[7] https://zhuanlan.zhihu.com/p/1928005367754884226
)




)

![[C++]string::substr](http://pic.xiahunao.cn/[C++]string::substr)










)
