文章目录
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 一、项目背景
- 二、研究目标与意义
- 三、数据获取与处理
- 四、文本分析与主题建模方法
- 1. 传统方法探索
- 2. 主题模型比较与优化
- 3. 深度语义建模与聚类
- 五、研究成果与应用价值
- 六、总结与展望
- 总结
- 每文一语
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
一、项目背景
随着互联网技术和移动终端的广泛普及,在线旅游平台成为游客获取信息和表达意见的主要渠道。游客在旅行过程中积累了丰富的个体体验,并通过在线评论的方式在平台上进行分享。这些评论不仅真实反映了游客对景区服务、设施、环境等方面的评价,也蕴含了大量的潜在用户需求。然而,由于在线评论数量庞大、内容形式复杂、语言表达自由,传统的人工筛选与分析方法已难以满足景区运营方对于高效洞察游客需求的实际要求。
因此,如何利用自然语言处理和深度学习等先进技术手段,从海量的用户评论中自动提取有价值的信息,成为当前旅游管理与智慧景区建设中的一个研究热点与实际需求。
二、研究目标与意义
本项目旨在通过采集与挖掘三亚地区四个主要旅游景点的在线评论数据,构建多层次的文本分析模型,识别游客对不同景区项目和服务的偏好与关注点。项目结合浅层统计方法与深度语义模型,建立一套适用于旅游评论分析的主题提取与聚类框架,以此为景区管理者提供更具针对性的优化建议,实现精准化服务和个性化营销。
该研究不仅有助于提高景区服务质量与游客满意度,也为旅游大数据分析提供了可复制、可扩展的方法路径,具有重要的理论价值与实际应用前景。
三、数据获取与处理
为了保证研究数据的广泛性与代表性,项目选取了携程旅行网作为数据源,围绕三亚市的四个热门景点展开分析,分别为:亚特兰蒂斯水世界、蜈支洲岛、亚龙湾热带天堂森林公园和天涯海角。
通过自编Python网络爬虫程序,团队成功获取了来自上述景点的数万条游客评论数据。每条评论包括但不限于评论文本、评分等级、点赞数、发布时间和用户身份信息等。为了规避平台的反爬虫机制,数据采集过程中采用了动态请求头、访问延迟控制与模拟用户浏览等策略,有效保障了数据获取的稳定性与连续性。
在数据预处理阶段,首先对来自各景区的原始评论文件进行合并,并剔除了重复记录和缺失字段,确保数据完整性。随后利用中文分词工具(如jieba)进行文本分词,同时引入常用停用词库,对评论内容进行清洗与规范化,为后续的文本建模打下基础。
四、文本分析与主题建模方法
1. 传统方法探索
初期尝试使用TF-IDF(Term Frequency-Inverse Document Frequency)方法对评论文本进行关键词提取与主题判断。虽然该方法在信息检索中具有良好表现,但在实际应用中发现其对长文本与语义边界识别能力不足,难以揭示评论中隐含的多层次主题关系。
2. 主题模型比较与优化
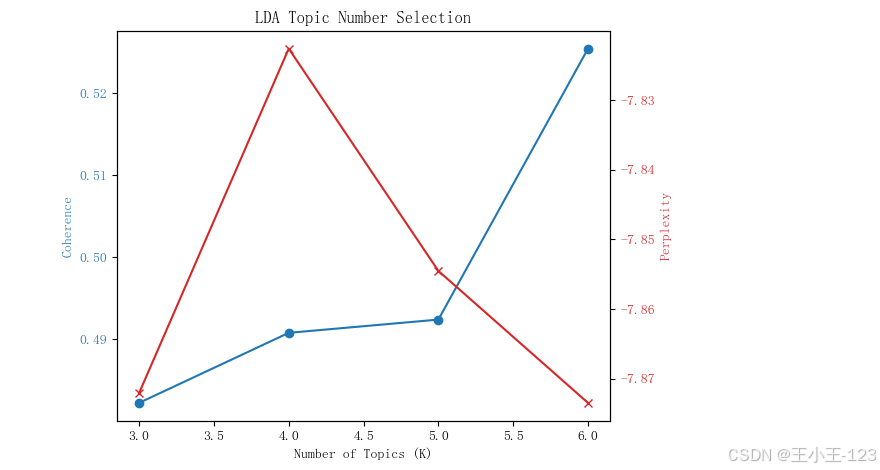
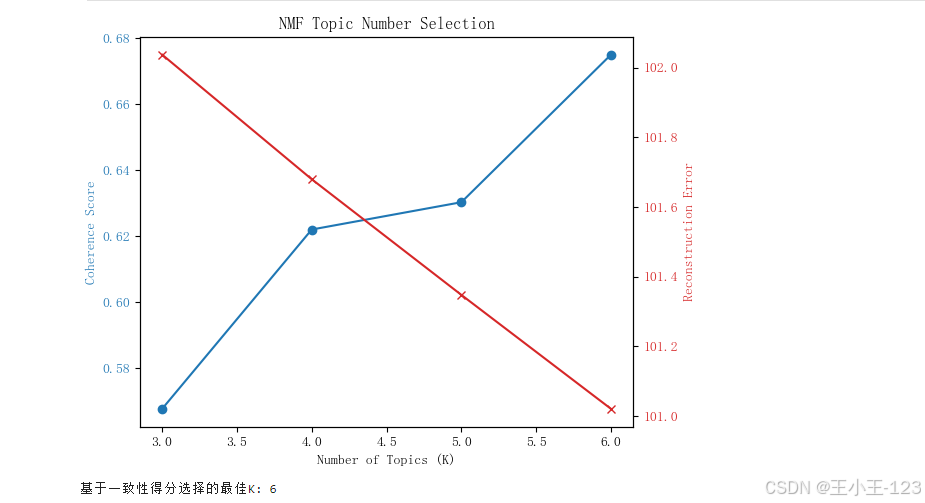
为了更全面地理解游客评论背后的核心主题,项目引入了两种主流的主题建模方法:LDA(Latent Dirichlet Allocation)和NMF(Non-negative Matrix Factorization)。在模型训练过程中,分别计算了主题一致性(coherence)和困惑度(perplexity)指标,综合评估两种模型在不同主题数下的表现。
研究结果表明:NMF模型在本数据集上展现出更高的语义聚焦能力,生成的主题更具可读性,能够准确识别游客对具体项目的关注,如“蜈支洲岛的潜水体验”、“亚龙湾的玻璃栈道”、“天涯海角的拍照打卡”等具体偏好。这种细粒度的主题划分对景区项目优化和资源配置具有较高的实用价值。
3. 深度语义建模与聚类
为进一步提升语义提取的精度,项目引入了基于BERT预训练语言模型的句向量生成方法。BERT(Bidirectional Encoder Representations from Transformers)能够捕捉评论语句中上下文间的深层语义关系,尤其在处理口语化、非结构化文本方面具有显著优势。
在得到每条评论的高维句向量后,利用K-Means算法对评论进行聚类分析,最终提取出若干个高相似度的评论群组。这些群组之间具有明确的情感倾向和内容特征,便于景区管理者快速掌握游客在交通、服务态度、排队时间、项目体验等方面的主要反馈内容。
五、研究成果与应用价值
本项目结合多种文本分析技术,成功构建了一个适用于旅游评论数据的“获取—清洗—建模—分析—应用”的完整流程。研究成果不仅从数据层面清晰呈现了游客关注的热点话题与潜在痛点,还通过可视化手段将模型输出结果转化为直观、易解读的图表和主题词云,极大提升了非技术用户的理解效率。
该分析框架已在三亚市某大型景区运营团队中进行试点应用,为其定制营销活动、优化导览路径、增强游客互动等方面提供了有力支撑。未来,该框架还可推广至全国其他旅游热点城市,支持更加智能、精准的文旅管理体系建设。
六、总结与展望
本研究通过融合机器学习与深度学习模型,创新性地构建了面向旅游评论数据的多层次语义识别机制,有效提升了用户需求挖掘的效率与精度。下一步,项目计划引入情感分析与多模态数据融合(如图文评论分析),进一步丰富游客画像与情境识别能力。同时,将探索实时分析与反馈机制的部署方式,为旅游行业的数字化转型与智慧景区建设提供更具前瞻性的解决方案。


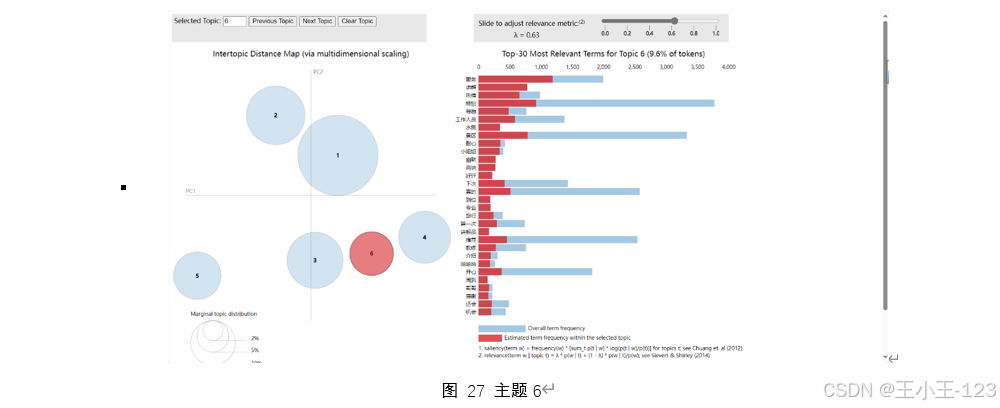

该主题清晰指向了“三亚天涯海角”景区。核心关键词有“石头”、“海边”、“拍照”、“门票”、“沙滩”等。天涯海角景区最具代表性的标志就是海边独特造型的巨型石头,而拍照打卡和欣赏海景正是游客来到此地的主要目的之一。从游客的实际评论出发,可以观察到游客更加关注于景区自然环境的美丽以及景点的标志性特征,NMF模型精准抓住这一景区特点,清晰地体现出与景点关联度高的关键词,表现出相较于其他主题模型更高的景区特征提取能力。
总结
在本研究中,我尝试将多种文本主题提取技术应用于旅游评论数据,旨在探索一种既具备语义聚合能力,又具备良好可解释性的分析路径。研究从中文分词后的评论语料出发,先后采用传统的主题模型方法,并逐步引入语义向量表达与深度学习手段,通过对比实验评估不同方法的适用性与效果。
在初步阶段,选用了TF-IDF方法作为文本特征提取的起点,并通过人工解读关键词来理解语义主题。但由于该方法依赖词频权重,缺乏语境理解能力,其在主题边界识别方面存在明显不足。随后,我引入了LDA(潜在狄利克雷分配)模型,并结合“困惑度”和“主题一致性”等指标,辅助判断最佳主题数。实验表明,尽管LDA可以初步对评论文本进行方向性划分,但生成的主题之间存在较大重叠,关键词容易分散在多个主题中,语义聚焦不明显。尤其是在旅游评论这类包含大量感性表达和场景描述的文本中,LDA难以有效剥离具体地名、项目名称与情绪性词汇的混合,导致主题抽象不清晰,更适用于结构统一、用词规范的文本场景。
为优化建模效果,我进一步尝试了NMF(非负矩阵分解)模型,在TF-IDF特征基础上对评论文本进行线性分解,形成更具辨析力的主题空间。结果显示,NMF在提取景区特征和游客兴趣点方面表现更优,特别是在主题集中性和关键词清晰度方面具有显著优势。例如,该方法能够有效聚合出“亲子娱乐”“自然景观拍照”“讲解服务体验”等具体主题类别。词云结果也表明,NMF生成的主题内关键词语义更为统一,主题边界更清晰,展现出其在非结构化内容聚类中的良好表现。
为了进一步增强模型对上下文信息的理解能力,我引入了基于BERT预训练语言模型的语义表示方法,并结合K-Means聚类算法对评论进行向量化处理与聚类分析。该方法通过上下文敏感的句子编码方式,准确捕捉评论中的深层语义特征。实验结果表明,相较于传统主题模型,BERT向量与K-Means组合能显著提高语义聚类的纯度,主题区分度更强,边界更明确。例如,有的聚类集中体现“视觉景观”“自然生态”等景区特色,部分则强调“项目互动性”“亲子游玩”等功能需求,还有一类明显聚焦于“岛屿风格与特色项目组合”等细分主题。这种基于句向量的深度建模在处理口语化、内容跳跃性强的旅游评论时,表现出更高的适配性和识别能力。
总体而言,BERT-KMeans方法在语义辨析与主题清晰度方面远优于LDA与NMF,尤其适合应对用户表达多样、意图模糊的文本场景。实验结果也表明,借助深度语言模型进行语义建模,为旅游评论类数据提供了更高质量的主题分析结果,具备良好的推广潜力和实际应用价值。
每文一语
抓住机会,学习一个新的境界
 的核心介绍与使用教程)
)
)

集合类详解)
 等待事件(1)-概述)

)











)