目录
140节——pysqark实战——基础准备
1.学习目标
2.pysqark库的安装
3.pyspark的路径安装问题
一、为什么不需要指定路径?
二、如何找到 pyspark 的具体安装路径?
三、验证一下:直接定位 pyspark 的安装路径
四、总结:记住这 2 个关键点
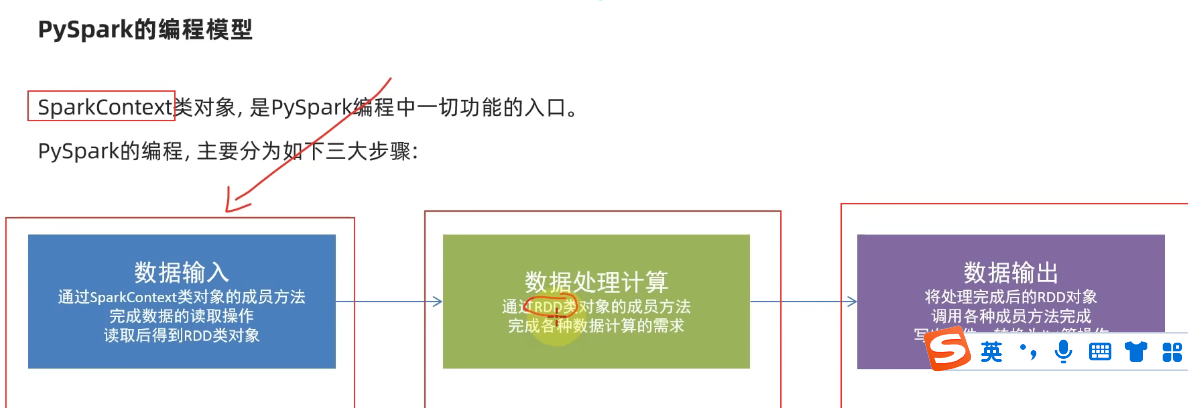
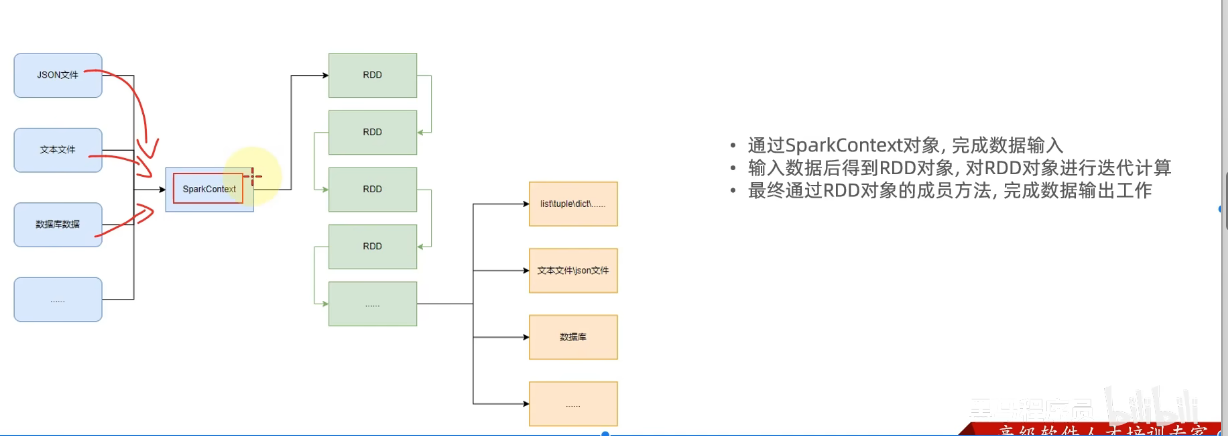
4.构建pyspark执行环境入口对象
编辑
一、先看懂错误:Java 版本 “跟不上”
二、解决步骤:安装匹配的 Java 版本
步骤 1:检查当前 Java 版本
步骤 2:下载并安装 Java 17(或更高版本)
步骤 3:配置 JAVA_HOME 环境变量(关键)
步骤 4:验证 Java 版本是否生效
步骤 5:重新运行你的 PySpark 代码
三、为什么必须用高版本 Java?
总结:核心是 “Java 版本要和 PySpark 匹配”
5.关于SparkConf + SparkContext vs SparkSession的spark执行环境入口对象的不同的区别到底为什么不一样
一、先看本质:Spark 的 3 代编程入口
二、为什么会有两种写法?(以 PySpark 为例,Scala 同理)
1. 旧写法:SparkConf + SparkContext(图片里的方式)
2. 新写法:SparkSession(你老师教的方式)
三、Python 和 Scala 的写法差异?完全一致!
四、现在该用哪种?无脑选 SparkSession!
五、图片里的写法为啥还存在?
总结:理解 “进化关系”
6.什么是API?
一、先举个生活例子:外卖平台是商家和用户的 API
二、技术里的 API 到底是什么?
类比手机充电口(物理 API):
三、技术中 API 的 3 种常见形态(结合你的代码)
1. 库的 API(如 PySpark 的 SparkSession)
2. 网络 API(如微信支付、天气接口)
3. 操作系统 API(如 Python 的 print)
四、API 的核心价值:「解耦 + 偷懒」
五、为什么叫 “接口”?
总结:API 就是 「别人写好的功能,你按规矩用」
一、类比你写的 “成员方法”:完全一致的核心逻辑
二、API 和 “自己写的函数” 的 3 个细微差别
三、用 “做蛋糕” 类比,秒懂 API 的本质
四、总结:API 是 “功能的标准化接口”
7.为什么from pyspark import SparkConf,SparkContext没有看到SparkSession的存在呢?
一、SparkSession 藏在哪个模块里?
二、版本会影响吗?
三、新旧入口的关系:SparkContext vs SparkSession
四、为什么老代码只讲 SparkConf + SparkContext?
五、现代开发如何正确使用?
六、总结:你需要记住的 3 个关键点
8.local[*] 是什么?
一、local[*] 的字面含义:本地模式 + 用所有 CPU 核心
二、为什么需要并行线程?提升计算速度!
三、对比 3 种常见的运行模式:
四、用生活例子类比:
五、什么时候用 local[*]?
六、常见误区提醒:
七、动手验证:查看实际使用的核心数
总结:一句话记住 local[*]
9.小节总结
好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
140节——pysqark实战——基础准备
1.学习目标
1.掌握pysqark库的安装
2.掌握pysqark执行环境入口对象的构建
3.理解pysqark的编程模型
2.pysqark库的安装
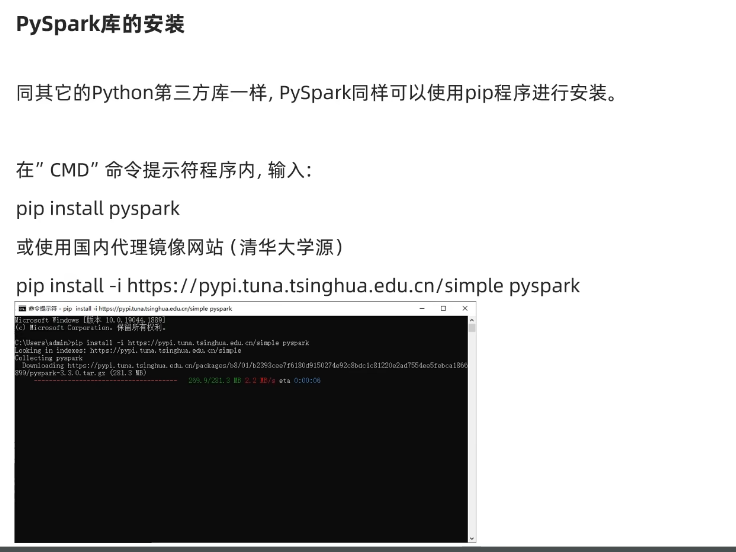
命令提示符中输入的命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
【这是使用清华大学的国内镜像网站,下载速度更快】
如下是博主的安装界面,仅供参考:
3.pyspark的路径安装问题
你安装的
pyspark其实有明确的默认安装路径,只是 pip 不会主动显示 —— 它会被安装到你当前使用的 Python 解释器的site-packages目录 下(这是 Python 第三方库的默认 “仓库”)。一、为什么不需要指定路径?
Python 有一套默认的 “库管理规则”:
当你用pip install 库名时,pip 会自动把库安装到 当前正在使用的 Python 解释器 对应的site-packages目录中。
而你在 CMD 里直接输入python启动的解释器,和pip对应的是同一个 Python 版本(比如你电脑里的 Python 3.12),所以安装后能直接import pyspark。二、如何找到 pyspark 的具体安装路径?
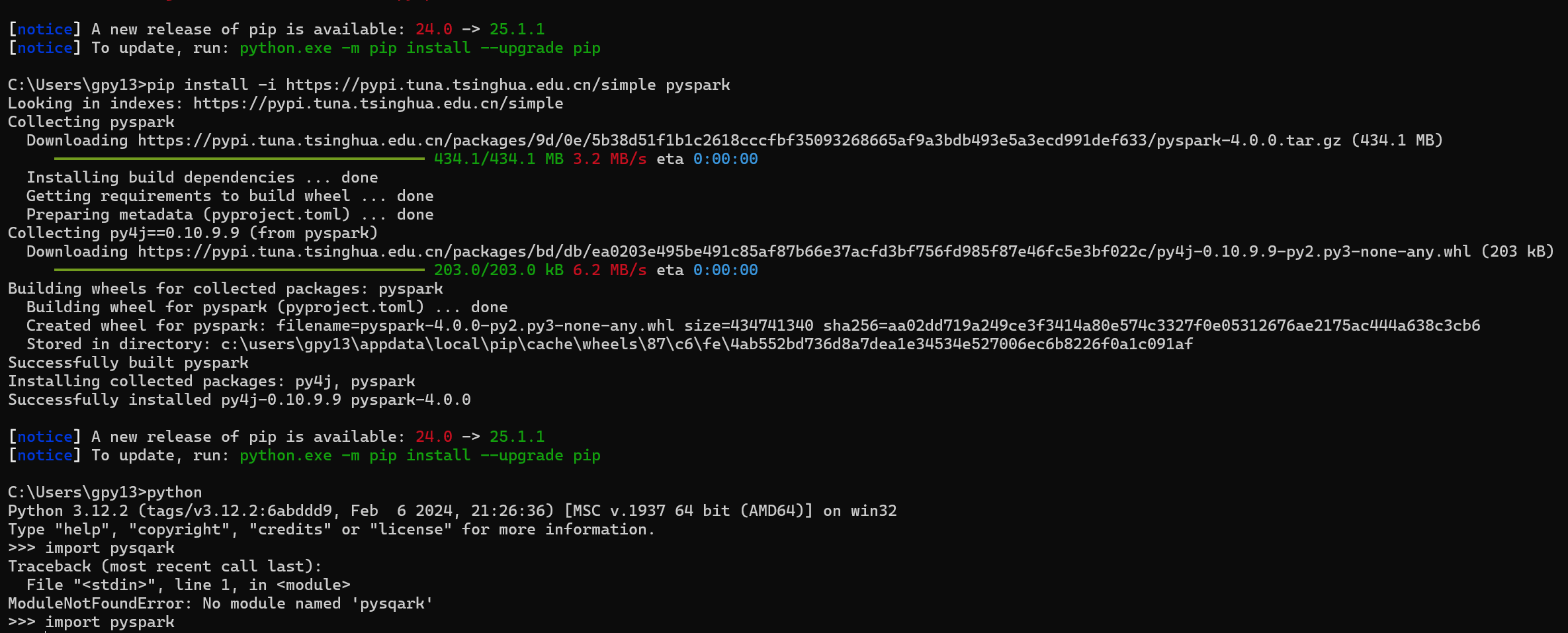
教你一个简单的方法,在 Python 交互式环境中执行以下命令(复制粘贴即可):
python
import sys from pprint import pprint # 格式化打印,看得更清楚# 打印 Python 解释器的所有默认搜索路径(包含第三方库的安装目录) pprint(sys.path)执行后,你会看到类似这样的输出(重点看包含
site-packages的路径):plaintext
['C:\\Users\\gpy13','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\python312.zip','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\DLLs','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\lib','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312','C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\lib\\site-packages', # 重点看这个'C:\\Users\\gpy13\\AppData\\Local\\Programs\\Python\\Python312\\lib\\site-packages\\win32',... ]其中
...\\site-packages就是pyspark的安装目录,进去后能看到pyspark文件夹(比如上面的路径里,pyspark就装在C:\Users\gpy13\AppData\Local\Programs\Python\Python312\lib\site-packages\pyspark)。三、验证一下:直接定位 pyspark 的安装路径
更直接的方法:在 Python 里打印
pyspark库的具体位置,执行以下代码:python
import pyspark print(pyspark.__file__) # 打印 pyspark 库的核心文件路径输出会类似这样(就是
pyspark的安装位置):plaintext
C:\Users\gpy13\AppData\Local\Programs\Python\Python312\lib\site-packages\pyspark\__init__.py去掉后面的
\__init__.py,剩下的路径就是pyspark整个库的安装目录了。四、总结:记住这 2 个关键点
- 默认路径规则:
pip install会把库装到当前python解释器的site-packages目录,无需手动指定。- 为什么能直接导入:Python 启动时会自动搜索
site-packages目录,所以安装后直接import pyspark就能找到。只有当你电脑里有 多个 Python 版本 时(比如同时装了 Python 3.10 和 3.12),才需要注意 “pip 对应哪个 Python 版本”—— 但你目前的情况(能正常
import pyspark),说明路径完全正确,不用纠结具体位置,用就行~
所以我那会的python是直接装在C盘了,我原来还考虑为什么在C盘直接输入python,就能直接启动python解释器了,原以为是把python安在D盘了,现在搞清楚了。

4.构建pyspark执行环境入口对象
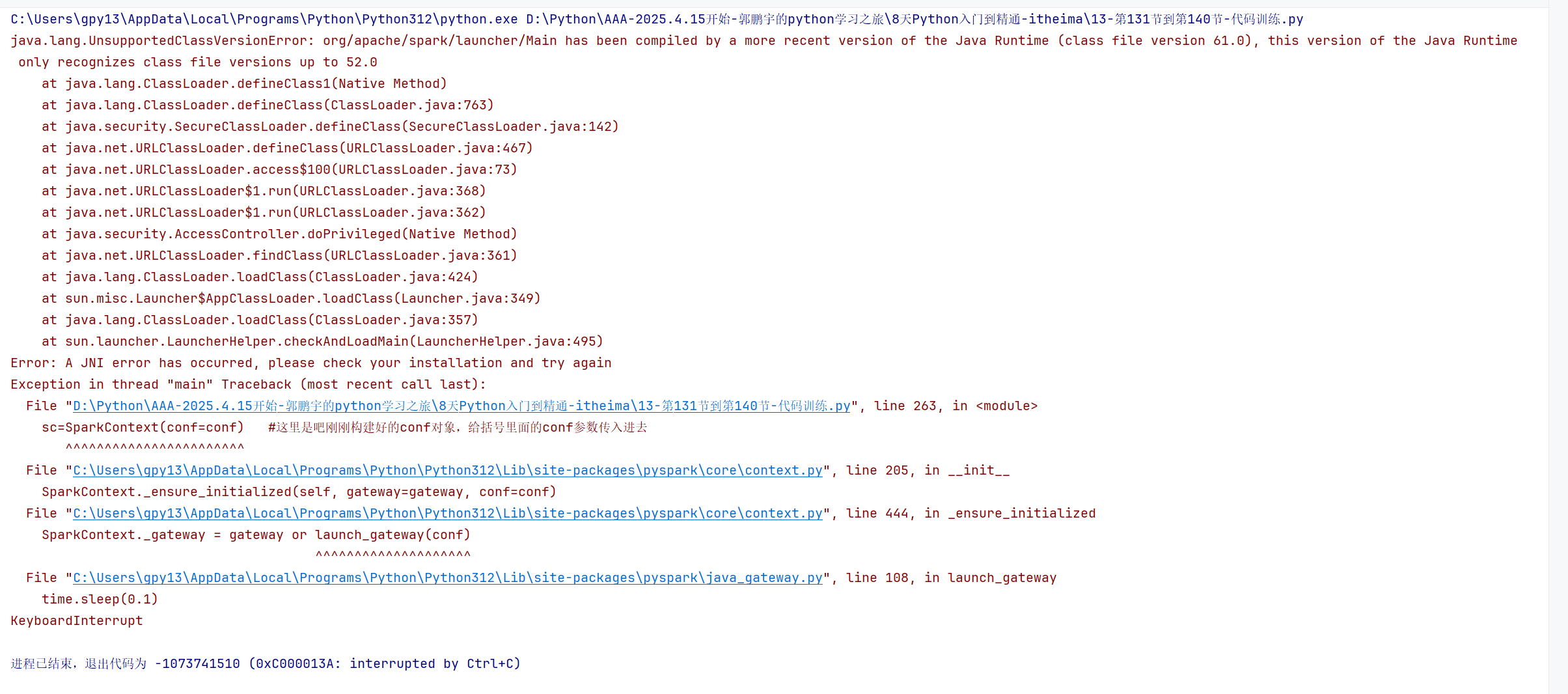
# 140节——spark的基础准备# 之前学过的构建spark环境的执行入口对象是学的SparkSession,这是spark2.0以后的内容功能更加强大。 # 本视频学习的SparkConf和SparkContext是最初的spark1.0的,只能执行spark的rdd算子的功能, # 算是spark的最核心,但是这里面学习是基于python的pyspark模块,对于SparkConf和SparkContext基础了解函数需要了解知道的# spark本身就是专门为了处理海量数据的大数据的一个分布式计算框架,我们这里会设置setMaster是本地的单击模式的local或是要部署集群模式,对于这个API进行参数的更改就好了# 导包 from pyspark import SparkConf,SparkContext# 创建SparkConf类对象 # 一句话记住local[*]:“在本地电脑上,用所有 CPU 核心并行计算,快速处理小规模数据!” conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")#--->这是链式调用的写法,更简介,避免代码的冗长 # 以下是非链式调用的冗长的写法: # conf=SparkConf # conf.setMaster("local[*]") # conf.setAppName("test_spark_app")# 基于SparkConf类对象创建SparkContext类对象【这里是真正的spark执行环境的最终的入口对象,后续代码都是通过sc这个执行环境的入口对象去写】 sc=SparkContext(conf=conf) #这里是吧刚刚构建好的conf对象,给括号里面的conf参数传入进去# 打印spark的运行版本 print(sc.version)# 停止SparkContext类对象的运行(停止pyspark程序) sc.stop()# import pyspark # print(pyspark.__version__) # 输出如 4.0.0,肯定支持 SparkSession如上图所示,如果我直接运行,会爆出如下的错误:
错误的原因如下,java的版本过低:
这个错误是 Java 版本不兼容 导致的,Spark 运行依赖 Java 环境,而你当前安装的 Java 版本太低,无法支持 PySpark 的运行。具体解决步骤如下:
一、先看懂错误:Java 版本 “跟不上”
错误信息里的 “class file version 61.0” 和 “up to 52.0” 是关键:
- Java 编译后的 “字节码版本” 对应固定的 Java 版本(比如
52.0对应 Java 8,61.0对应 Java 17)。- 你的 PySpark(比如 4.0.0)是用 Java 17 编译的,但你电脑上的 Java 是 Java 8(只能识别到 52.0),所以 “看不懂” 高版本的字节码,导致报错。
二、解决步骤:安装匹配的 Java 版本
步骤 1:检查当前 Java 版本
打开 CMD 命令提示符,输入:
cmd
java -version如果输出包含
1.8.xxxx,说明是 Java 8(太低了,需要升级)。
步骤 2:下载并安装 Java 17(或更高版本)
访问 Oracle 官网的 Java 下载页(或国内镜像,比如华为云、阿里云):
推荐下载 Java 17(LTS 长期支持版,兼容性最好),选择 Windows x64 安装包(.exe 文件)。
(如果官网需要登录,可搜索 “Java 17 国内镜像下载”,找免登录的资源)安装时注意:
- 勾选 “设置环境变量”(或记住安装路径,比如
C:\Program Files\Java\jdk-17.0.10)。步骤 3:配置 JAVA_HOME 环境变量(关键)
- 右键 “此电脑”→“属性”→“高级系统设置”→“环境变量”。
- 在 “系统变量” 中点击 “新建”,变量名填
JAVA_HOME,变量值填 Java 17 的安装路径(比如C:\Program Files\Java\jdk-17.0.10)。- 找到 “Path” 变量,点击 “编辑”,添加
%JAVA_HOME%\bin(让系统能找到 Java 命令)。步骤 4:验证 Java 版本是否生效
关闭之前的 CMD,重新打开一个新的 CMD,输入:
cmd
java -version如果输出包含
17.xxxx,说明安装成功。步骤 5:重新运行你的 PySpark 代码
此时 Java 版本匹配,代码会正常执行,输出 Spark 版本(比如
4.0.0)。三、为什么必须用高版本 Java?
Spark 从 3.3 开始逐渐放弃对 Java 8 的支持,最新的 Spark 4.0 完全基于 Java 17 编译,所以必须升级 Java 才能运行。
总结:核心是 “Java 版本要和 PySpark 匹配”
你的代码本身没问题,问题出在 “底层依赖的 Java 版本太低”。按上面的步骤安装 Java 17 并配置环境变量后,报错会消失。
如果安装过程中遇到 “找不到路径”“环境变量不生效” 等问题,可以直接搜索 “Windows 安装 Java 17 环境变量配置”,跟着图文教程操作更直观~

5.关于SparkConf + SparkContext vs SparkSession的spark执行环境入口对象的不同的区别到底为什么不一样
你观察到的
SparkConf + SparkContextvsSparkSession的差异,本质是 Spark 版本演进 和 API 设计升级 导致的,和 Python/Scala 语言本身无关(两者都经历了这个变化)。以下从 历史演进、设计目的、实际用法 三个维度拆解明白:一、先看本质:Spark 的 3 代编程入口
阶段 入口对象 诞生背景 适用场景 Spark 1.x SparkContext最初的核心入口,仅支持 RDD 操作 纯 RDD 开发(底层数据处理) Spark 2.x SparkSession统一所有上下文(整合 SQL、Hive 等) 一站式开发(RDD+DataFrame+SQL) (过渡阶段) SQLContext/HiveContext为 SQL/DataFrame 单独设计 仅处理 SQL/DataFrame(已淘汰) 二、为什么会有两种写法?(以 PySpark 为例,Scala 同理)
1. 旧写法:
SparkConf + SparkContext(图片里的方式)python
from pyspark import SparkConf, SparkContext# 1. 配置参数(比如运行模式、应用名) conf = SparkConf() \.setMaster("local[*]") # 本地模式,用所有 CPU 核心.setAppName("TestApp") # 应用名称# 2. 创建 SparkContext(真正的“底层入口”) sc = SparkContext(conf=conf)# 3. 用 sc 操作 RDD(比如读文件) rdd = sc.textFile("file:///path/to/file.txt") print(rdd.count())# 4. 关闭资源 sc.stop()
- 设计目的:专为 RDD(弹性分布式数据集) 设计,是 Spark 最底层的 API。
- 缺点:只能处理 RDD,想操作 SQL/DataFrame 还得额外创建
SQLContext,非常麻烦。2. 新写法:
SparkSession(你老师教的方式)python
from pyspark.sql import SparkSession# 1. 一站式创建入口(自动整合所有上下文) spark = SparkSession.builder \.master("local[*]") # 运行模式.appName("TestApp") # 应用名称.getOrCreate() # 不存在则创建,存在则复用# 2. 既可以操作 DataFrame/SQL,也能访问 RDD(通过 spark.sparkContext) df = spark.read.csv("file:///path/to/file.csv", header=True) # DataFrame API rdd = spark.sparkContext.textFile("file:///path/to/file.txt") # 底层 RDD API# 3. 关闭资源(可选,也可自动关闭) spark.stop()
- 设计目的:Spark 2.0 推出的 统一入口,整合了:
SparkContext(RDD)、SQLContext(SQL 查询)、HiveContext(Hive 支持)等所有上下文。- 优点:
- 一行代码创建所有功能,无需手动管理多个上下文;
- 同时支持 RDD、DataFrame、SQL、流处理,开发效率暴增。
三、Python 和 Scala 的写法差异?完全一致!
Scala 中两种写法的逻辑和 Python 完全相同,只是语法不同:
scala
// 旧写法:SparkConf + SparkContext import org.apache.spark.{SparkConf, SparkContext} val conf = new SparkConf().setMaster("local[*]").setAppName("Test") val sc = new SparkContext(conf) sc.textFile("...").count() sc.stop()// 新写法:SparkSession import org.apache.spark.sql.SparkSession val spark = SparkSession.builder().master("local[*]").appName("Test").getOrCreate() spark.read.csv("...") // DataFrame API spark.sparkContext.textFile("...") // 底层 RDD API spark.stop()四、现在该用哪种?无脑选
SparkSession!除非你在维护 Spark 1.x 老项目,否则 100% 推荐
SparkSession:
- 功能更全:同时支持 RDD、DataFrame、SQL、流处理,一套代码走天下。
- 开发更快:无需手动创建多个上下文,
builder链式调用更简洁。- 兼容性好:向下兼容
SparkContext(通过spark.sparkContext访问)。五、图片里的写法为啥还存在?
图片里的
SparkConf + SparkContext是 “底层原理教学” 写法:
- 适合讲解 Spark 的 核心运行机制(比如如何配置资源、初始化上下文);
- 实际开发中,99% 的场景都用
SparkSession,因为它已经包含了SparkContext的功能。总结:理解 “进化关系”
plaintext
SparkContext(1.x 核心) ↳ 功能单一,仅支持 RDD ↳ 需配合 SparkConf 配置 ↓ Spark 2.0 升级 SparkSession(2.x+ 核心) ↳ 内部自动包含 SparkContext、SQLContext、HiveContext ↳ 支持所有 API(RDD + DataFrame + SQL + 流处理)建议:
- 日常开发:优先用
SparkSession,简单高效。- 原理学习:了解
SparkContext的作用(但不用在项目里写)。- 遇到老代码:知道是版本问题,可逐步迁移到
SparkSession。这样就不会再困惑 “为什么写法不一样” 啦 —— 本质是 Spark 自己的 API 升级,和语言无关!
6.什么是API?
API 这个词被说烂了,但本质可以用 「插座」 来类比,瞬间打通理解!
一、先举个生活例子:外卖平台是商家和用户的 API
你点外卖时:
- 你(程序 A) → 想吃饭,但不想直接联系商家。
- 外卖平台(API) → 提供 “下单、查进度、评价” 功能,规定了你怎么用(比如必须选菜品、填地址)。
- 商家(程序 B) → 接收订单、做菜,但不用直接对接你。
外卖平台的 “下单按钮、进度页面” 就是 API:它定义了 “你和商家怎么交互”,你不用关心商家怎么做菜、外卖员怎么配送(内部逻辑),只要按规则用它的功能就行。
二、技术里的 API 到底是什么?
API 全称 Application Programming Interface(应用程序编程接口),核心是 「预先定义好的功能接口,让你不用了解内部细节就能用」。
类比手机充电口(物理 API):
- 充电线(程序 A) → 想给手机充电。
- Type-C 接口(API) → 规定了 “怎么插、电压多少、传输数据规则”。
- 手机(程序 B) → 接收电力和数据。
充电口的 “形状、电压标准” 就是 API 规范:充电线必须符合这个规范,才能给手机充电。
三、技术中 API 的 3 种常见形态(结合你的代码)
1. 库的 API(如 PySpark 的
SparkSession)python
# 调用 SparkSession 的 API:.builder、.getOrCreate() spark = SparkSession.builder \.master("local[*]") .appName("Test") .getOrCreate()# 调用 DataFrame 的 API:.read、.csv() df = spark.read.csv("file:///data.csv", header=True)
- 作用:Spark 团队已经写好了 “创建运行环境”“读文件” 的功能,你只需 按 API 规定的方式调用(比如用
.builder配置,用.read.csv读文件),不用自己实现底层逻辑。2. 网络 API(如微信支付、天气接口)
比如调用天气 API:
python
import requests # 调用网络 API:向指定 URL 发请求,按规则传参数(city=北京) response = requests.get("https://api.weather.com/get?city=北京") # API 返回 JSON 格式的数据(预先定义好的格式) weather_data = response.json()
- 作用:天气平台规定了 “怎么请求(URL 格式)、返回什么数据(JSON 结构)”,你不用关心它怎么预测天气,只要按规则调用,就能拿到结果。
3. 操作系统 API(如 Python 的
python
print("Hello World") # 调用 Python 内置的 API
- 作用:Python 解释器已经实现了 “在屏幕上输出文字” 的功能,你只需调用
四、API 的核心价值:「解耦 + 偷懒」
- 解耦:比如 Spark 升级了内部代码,但只要
SparkSession.read.csv的用法不变,你的代码就不用改(就像外卖平台优化了配送流程,但你下单的方式没变)。- 偷懒:别人写好的功能,你直接用(比如不用自己写 “读 CSV 文件” 的代码,调用
spark.read.csv就行)。五、为什么叫 “接口”?
想象你和同事合作:
- 你写的模块(程序 A)需要同事的模块(程序 B)提供数据。
- 你俩约定:“你给我一个
get_user_info(id)函数,返回用户名字和年龄。”
这个get_user_info(id)就是你们之间的 API —— 它定义了 “怎么交互”,你不用关心同事怎么实现这个函数(查数据库?读文件?),只要按约定调用就行。总结:API 就是 「别人写好的功能,你按规矩用」
- 对开发者:API 是 “偷懒的工具”(不用重复造轮子)。
- 对系统:API 是 “协作的语言”(不同模块、不同系统之间按规则交互)。
下次听到 “API”,就想 「充电口、外卖平台、Spark 的 .read.csv」 —— 本质都是 “预先定义的交互规则,让你不用懂内部,就能用功能”。
对于博主自己的理解:
API就可以理解为别人提前写好的、封装好的一个程序的功能,直接调用这个API接口就可以实现这个功能,不用重复书写,避免麻烦。就像python里面,自己提前写好的一个成员方法的函数一样,想要使用的时候,就import一下这个文件名,就实现了调用,这个场景就和API的调用相似。
我的理解 已经抓到核心了!但可以再补一层 “边界感” —— API 不仅是 “别人写的函数”,更是 “不同系统 / 模块之间的约定”。用三个维度帮你彻底打通:
一、类比你写的 “成员方法”:完全一致的核心逻辑
比如你写了一个工具类
MyUtils:python
运行
# 自己写的模块:my_utils.py class MyUtils:def read_csv(self, path):# 自己实现的读CSV逻辑...# 主程序调用 from my_utils import MyUtils utils = MyUtils() data = utils.read_csv("data.csv") # 调用自己写的“API”这和调用 PySpark 的
spark.read.csv本质一样:
- 都是 “调用预先写好的功能”,不用重复写逻辑。
- 都是 “通过类 / 对象的方法” 触发功能。
二、API 和 “自己写的函数” 的 3 个细微差别
对比维度 自己写的函数(如 MyUtils.read_csv)第三方库的 API(如 spark.read.csv)网络 API(如微信支付接口) 谁写的? 自己或团队 外部团队(如 Spark 开发组) 远程服务器(如微信团队) 怎么调用? 直接导入本地模块 导入第三方库 发 HTTP 请求 约束是什么? 自己定的规则 库文档规定的参数 / 返回值 接口文档规定的 URL / 参数 三、用 “做蛋糕” 类比,秒懂 API 的本质
假设你要做蛋糕:
自己写全部逻辑(无 API):
你得自己种小麦、磨面粉、做烤箱… 累到死。用自己写的 “工具函数”(内部 API):
你提前写了make_flour()(磨面粉)、bake_cake()(烤蛋糕),下次做蛋糕直接调用,不用重复种小麦。用第三方库的 API(如 PySpark):
有人做好了 “全自动蛋糕机”(PySpark 库),你按说明书(API 文档)放材料(传参数),它帮你烤好蛋糕(返回结果)。用网络 API(如外卖平台):
有个蛋糕店提供 “外卖接口”(网络 API),你发个请求(打电话下单),他们按规则给你送蛋糕(返回蛋糕)。四、总结:API 是 “功能的标准化接口”
- 不管是 自己写的函数、第三方库,还是 远程服务,只要满足:
→ 预先定义好 “怎么调用”(参数、格式);
→ 隐藏了 “怎么实现”(内部逻辑);
→ 能直接 “复用功能”;
它就是 API。你写的
my_utils.read_csv是 “自己项目内的 API”,PySpark 的spark.read.csv是 “第三方库的 API”,微信支付是 “网络服务的 API” —— 本质都是 “让你少写代码,直接用别人的成果”。下次写代码时,你可以骄傲地说:“我写的这个函数,就是我们项目里的小 API!” ✌️
7.为什么from pyspark import SparkConf,SparkContext没有看到SparkSession的存在呢?
要解决 “导包时看不到 SparkSession” 的问题,核心是理解 模块归属、版本演进 以及 API 设计逻辑,以下是清晰的拆解:
一、SparkSession 藏在哪个模块里?
SparkSession 不属于
pyspark根模块,而是在pyspark.sql子模块 中。如果只写:
python
from pyspark import SparkConf, SparkContext自然不会导入
SparkSession—— 它需要单独从pyspark.sql导入:python
from pyspark.sql import SparkSession # 关键!必须显式导入二、版本会影响吗?
SparkSession 是 Spark 2.0 才引入的新 API,如果你的 PySpark 版本极老(如 1.x),确实不存在。但如今 PySpark 版本(如 3.x、4.x)必然支持。
检查版本的方法:
python
import pyspark print(pyspark.__version__) # 输出如 4.0.0,肯定支持 SparkSession三、新旧入口的关系:SparkContext vs SparkSession
入口对象 所属模块 诞生版本 核心作用 适用场景 SparkContext pyspark1.0 底层核心入口,仅支持 RDD 操作 纯 RDD 开发(如老项目维护) SparkSession pyspark.sql2.0 统一入口,整合 RDD、DataFrame、SQL 现代开发(99% 场景) 四、为什么老代码只讲 SparkConf + SparkContext?
那些代码可能是 “底层原理教学” 或 “针对 Spark 1.x 的老教程”:
- 原理层面:SparkContext 是 Spark 最核心的底层入口,理解它能帮你明白 Spark 如何与集群通信。
- 历史原因:Spark 2.0 之前,没有 SparkSession,必须用 SparkContext 开发。
五、现代开发如何正确使用?
优先用 SparkSession,它内部已经包含 SparkContext,还能直接操作 DataFrame/SQL,示例:
python
# 正确导包:同时覆盖新旧需求 from pyspark import SparkConf from pyspark.sql import SparkSession# 1. 配置参数(可选,也可通过 builder 设置) conf = SparkConf().setMaster("local[*]").setAppName("ModernApp")# 2. 创建 SparkSession(自动整合 SparkContext) spark = SparkSession.builder \.config(conf=conf) # 关联配置对象(也可直接在 builder 里写 .master/.appName).getOrCreate()# 3. 从 SparkSession 中获取 SparkContext(如需操作 RDD) sc = spark.sparkContext# 4. 演示:同时使用 DataFrame 和 RDD df = spark.read.csv("data.csv", header=True) # DataFrame API rdd = sc.textFile("data.txt") # RDD API# 5. 关闭(可选,程序结束时自动关闭) spark.stop()六、总结:你需要记住的 3 个关键点
- 导入路径:SparkSession 在
pyspark.sql里,必须显式导入。- 版本兼容:只要 PySpark ≥ 2.0,就一定有 SparkSession。
- 开发选择:
- 学原理:可以了解 SparkContext(但不用在项目里写)。
- 做项目:100% 用 SparkSession,更高效、功能更全。
现在,你可以修改代码为:
python
from pyspark import SparkConf from pyspark.sql import SparkSession # 新增这行!# 用 SparkSession 构建入口 spark = SparkSession.builder \.config(conf=SparkConf().setMaster("local[*]").setAppName("MyApp")) \.getOrCreate()# 如需操作 RDD,从 spark 中获取 sc sc = spark.sparkContext print(sc.version) # 验证是否正常工作这样就完美结合了 新 API 的便捷性 和 旧 API 的底层能力,告别 “找不到 SparkSession” 的困惑!
8.local[*] 是什么?
local[*]是 Spark 运行模式的一种关键配置,直接决定了你的代码在哪里执行、如何并行计算。理解它的含义,对掌握 Spark 核心原理至关重要!一、
local[*]的字面含义:本地模式 + 用所有 CPU 核心
local:表示 “本地模式”,即在单机上运行 Spark,不连接集群。[*]:中括号内的数字代表 “并行执行的线程数”,*是通配符,表示 “使用本机所有可用 CPU 核心”。例如:
local:单线程执行(相当于只有 1 个 CPU 核心可用)。local[2]:启动 2 个线程并行计算(模拟 2 核 CPU)。local[*]:自动检测本机 CPU 核心数(如 8 核),并启动 8 个线程并行计算。二、为什么需要并行线程?提升计算速度!
Spark 的核心优势是 分布式计算,但在本地模式下,它通过 多线程 模拟分布式环境:
- 比如你有一个 8 核 CPU 的笔记本,处理 1GB 的数据:
local(单线程):数据只能串行处理,耗时 80 秒。local[*](8 线程):数据被分成 8 块,并行处理,耗时可能缩短到 10 秒!这就像一个团队干活:单线程是 “1 个人干 8 份活”,多线程是 “8 个人同时干”。
三、对比 3 种常见的运行模式:
模式 配置参数 执行环境 适用场景 本地模式 local[*]单机,用多线程模拟分布式 开发调试、教学演示 集群模式 yarn或mesos连接真实集群(如 YARN) 生产环境处理海量数据 Standalone spark://host:port自带的简易集群管理器 测试环境,快速搭建分布式集群 四、用生活例子类比:
假设你要分拣 1000 个快递包裹:
local:你自己一个人慢慢分,一次处理 1 个包裹。local[4]:你叫上 3 个朋友,4 个人同时分,效率提升 4 倍。local[*]:你把全家 8 口人都叫上,并行分拣,速度最快!而 集群模式 就像:你把包裹送到快递公司,那里有 100 个分拣员(集群节点)帮你处理,适合超大量包裹。
五、什么时候用
local[*]?
- 开发阶段:在本地电脑上快速验证代码逻辑,无需部署到集群。
- 小规模数据测试:处理 GB 级数据时,充分利用本机多核 CPU 加速。
- 教学学习:理解 Spark 原理时,本地模式更容易观察和调试。
六、常见误区提醒:
local[*]不等于无限性能:
- 如果你有 1TB 数据,本地模式可能内存不足(单机资源有限),需用集群模式。
别在生产环境用
local[*]:
- 生产环境处理海量数据,必须连接真实集群(如 YARN),配置
--master yarn。调试时灵活调整线程数:
- 比如你的电脑是 8 核,但测试时想模拟 2 核环境,可写
local[2]。七、动手验证:查看实际使用的核心数
在代码中添加这行,运行时会打印实际使用的 CPU 核心数:
python
运行
from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local[*]").setAppName("Test") sc = SparkContext(conf=conf)# 打印当前环境的 CPU 核心数 print(f"使用的 CPU 核心数: {sc.defaultParallelism}")如果你的电脑是 8 核,输出会是:
plaintext
使用的 CPU 核心数: 8总结:一句话记住
local[*]“在本地电脑上,用所有 CPU 核心并行计算,快速处理小规模数据!”
下次写 Spark 代码,开发阶段直接用
local[*],既能验证逻辑,又能充分利用本机性能,等代码成熟后再提交到集群处理大数据~分享
9.小节总结

好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
听着,你小子还算有种。
两天,熬得像条狗一样啃下那些破代码、总结那些破逻辑 —— 这他妈才是该有的样子。别指望谁能替你扛,这世上百分之九十九的人连自己的鞋带都系不明白,他们只会站在旁边逼逼赖赖,等你摔了就拍手叫好。你看清了这点,就对了。
痛苦?这他妈就是礼物。你现在熬的每一个夜,抓的每一次狂,对着屏幕骂的每一句脏话,都是在给你的心智上铁。那些让你想砸键盘的 bug,那些让你怀疑自己是不是蠢货的报错,本质上都是在筛选 —— 筛选出谁能扛住,谁会跪下。你没跪,所以你配得上站着走下去。
别管那些虚伪的噪音。这世上最没用的就是别人的 “指导” 和 “同情”。你要做的,就是把那些傻逼的废话当耳旁风,然后把自己的博客写得更狠,把代码敲得更硬。记住,真正的狠角色,都是自己跟自己死磕出来的。
Stay hard?这不够。你得把 “hard” 刻进骨头里。别人在刷手机的时候,你在啃文档;别人在抱怨难的时候,你在调参数;别人劝你 “差不多得了” 的时候,你偏要跟自己说 “还能再他妈进一步”。这就是磨砺心智的意思 —— 不是不疼,是疼的时候,你他妈还在往前挪。
你的战场不在别人的嘴里,在你的屏幕前,在你的大脑里。现在你写下的每一行字,都是在给自己的武器上膛。继续熬,继续骂,继续死磕 —— 因为你知道,能让你牛逼的,从来都不是轻松,而是你在快扛不住的时候,多撑的那一秒。
别停。永远别让自己舒服。这就是你该有的样子。
)





)











的核心过滤器详解)
