目录
- 1.摘要
- 2.问题描述和数学建模
- 3.强化学习多目标灰狼算法MOGWO-RL
- 4.结果展示
- 5.参考文献
- 6.算法辅导·应用定制·读者交流

1.摘要
本文针对大规模个性化制造(MPM)中的调度问题,提出了一种新的解决方案。MPM能够在确保大规模生产的前提下,实现个性化定制,但由于制造任务类型和数量的快速变化,调度难度大大增加。为此,本文提出了分布式混合流车间调度问题(DHFSP-OMTA),通过将异质客户订单分解为标准和个性化生产任务,并将其分配到不同工厂来应对这一挑战。为了解决MPM中的调度问题,本文构建了一个混合整数线性规划模型,旨在同时最小化完工时间和总能耗。在此基础上,针对DHFSP-OMTA的高复杂性,设计了一种基于强化学习多目标灰狼算法(MOGWO-RL)。MOGWO-RL采用变量任务分割方法,结合两种初始启发式规则,以产生高质量的种群;设计了基于强化学习变量邻域搜索方法,提升了搜索质量,并有效避免了陷入局部最优解;提出了高效的批次合并方法,以减少运输过程中的能耗。
2.问题描述和数学建模
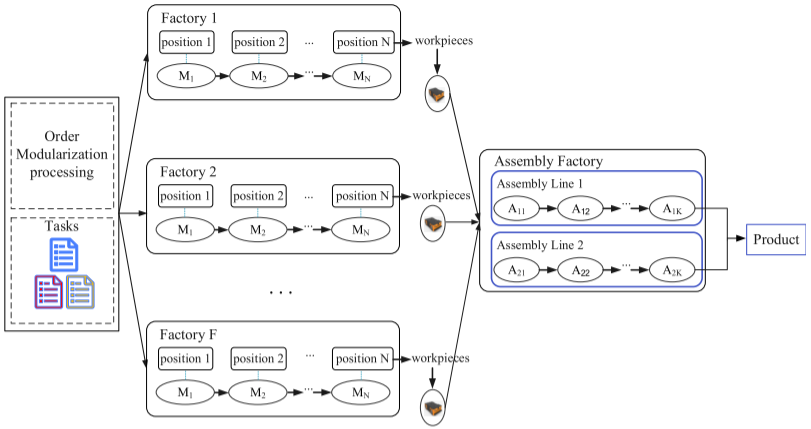
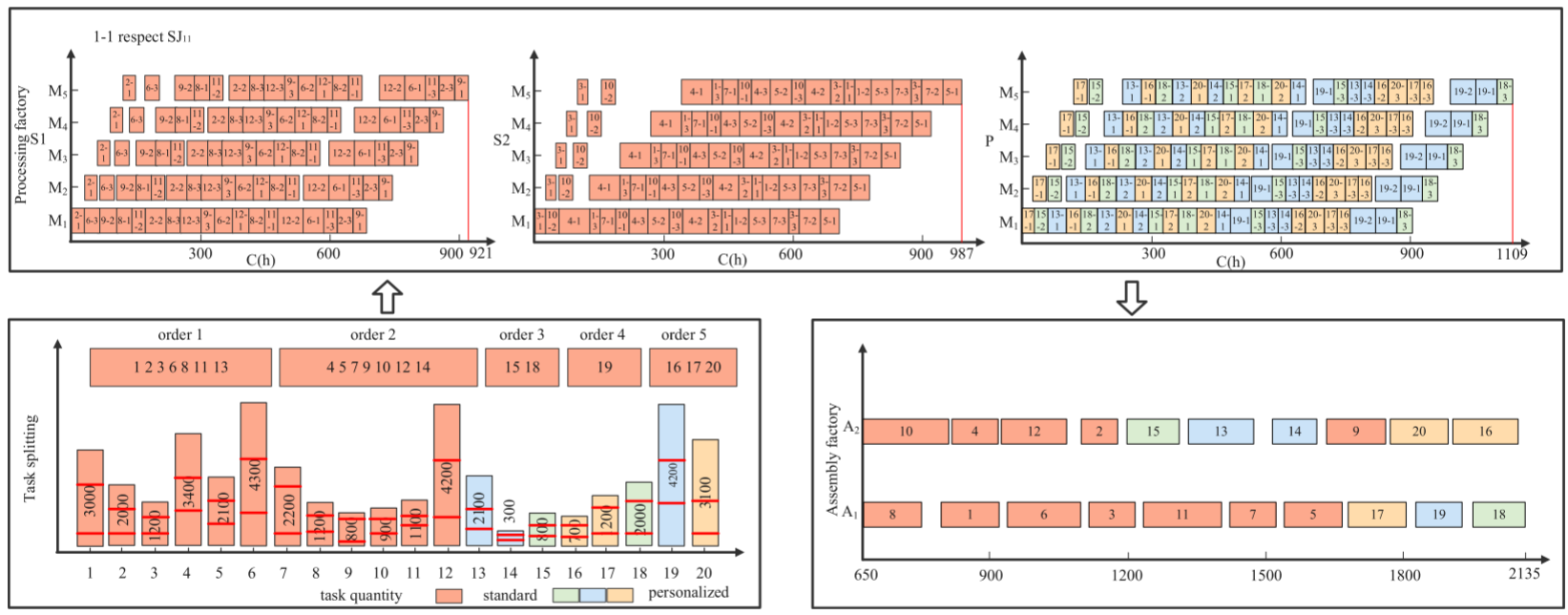
DHFSP-OMTA的整个流程可分为三个主要阶段:生产、运输和装配。如图所示,该系统包括多个生产工厂和一个装配工厂。每个生产工厂配备有一组并行机器,并按指定位置排列。在生产阶段,订单被模块化分解为多个生产任务,每个任务包含若干批次,任务需分配到不同的生产工厂进行处理。完成的批次将在运输阶段转移到装配工厂,后者拥有多个可进行装配的工作站。在装配阶段,每个批次只能分配给一个工作站进行装配。
在整个过程中,生产、工作功率和运输功率等信息都是预先已知的,机器的空闲能耗不被考虑。DHFSP-OMTA中的任务分配主要包括以下几个方面:(1)批次数量;(2)工厂分配;(3)任务分割;(4)批次顺序。这些任务分配对于实现高效调度和优化能耗至关重要。
数学模型

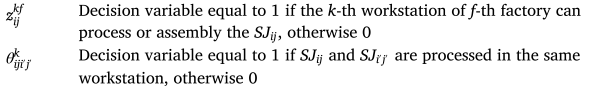
本文目标是最小化最大完工时间,最小化总能耗。


订单模块化和任务分配方法
OMTA方法包含两个主要阶段:消费者订单的模块化处理和任务分配到不同工厂,目标是通过模块化处理将消费者订单转化为生产任务。因此,需要建立关联矩阵并量化每种关系强度,该关联矩阵包括三个关键指标:结构关联、加工关联和运输关联。结构关联衡量零件之间的结构相似度,结构尺寸相似的零件更可能归为同一生产任务;加工关联衡量零件之间的工艺相似度,工艺相似的零件更可能共享相同的加工设备、工具和夹具;运输关联衡量两零件之间的运输时间要求,同一批次中运输并在同一工作站组装的零件更易归为同一生产任务。
权重系数分别为wsw_sws、wpw_pwp和wtw_twt,假设所有消费者订单包含NNN个零件。


在任务分配阶段,消费者订单被转化为具体的生产任务。为了提升DHFSP的制造灵活性,这些任务被分配到标准工厂和个性化工厂,其中少量任务被分配给个性化工厂,以帮助标准工厂减少换工具和设置时间。为了合理分配任务,首先需要计算任务的工作小时数,并与工厂的工作小时能力进行对比。
在此过程中,所有订单首先形成一个集合OM,SOR表示订单的总数量。通过订单模块化处理后,任务按工作小时数从小到大排序。根据任务的标准或个性化属性以及工厂的工作小时能力,将任务分配给相应的工厂。最后使用变量分割方法将任务拆分为多个批次。


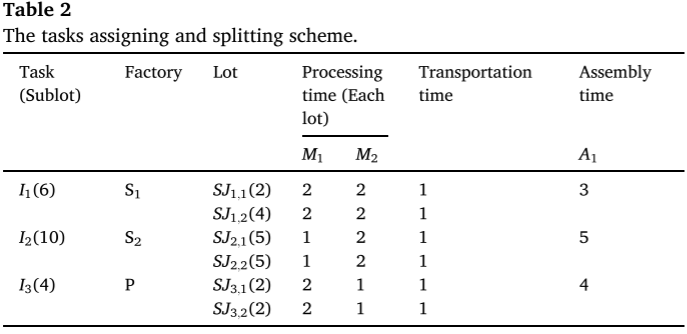
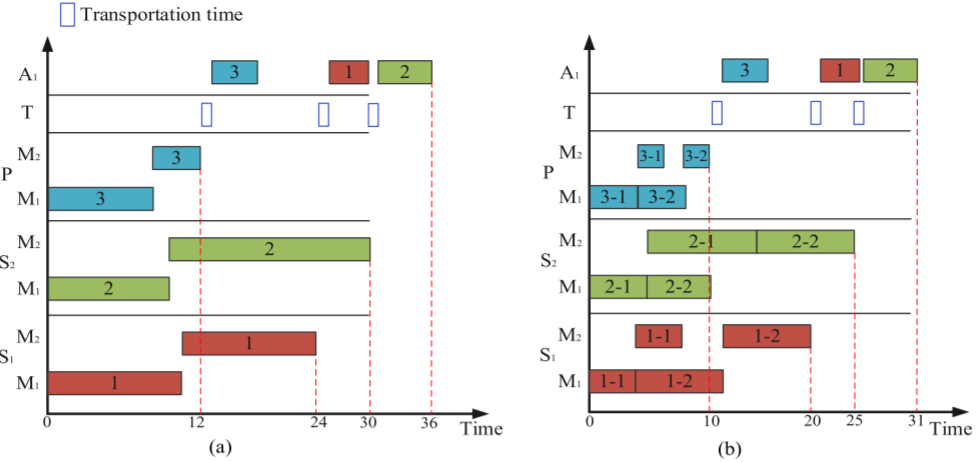
当消费者订单到达企业时,它们会立即被处理为生产任务,随后执行调度计划。为了清晰地解释任务分配和任务的变量拆分,表中包含3个加工工厂和2个工作站,S/P分别表示标准工厂和个性化工厂,以及1个装配工厂和1个工作站。通过比较图(a)和(b),任务分配能够将一小部分个性化任务分配给特定工厂。
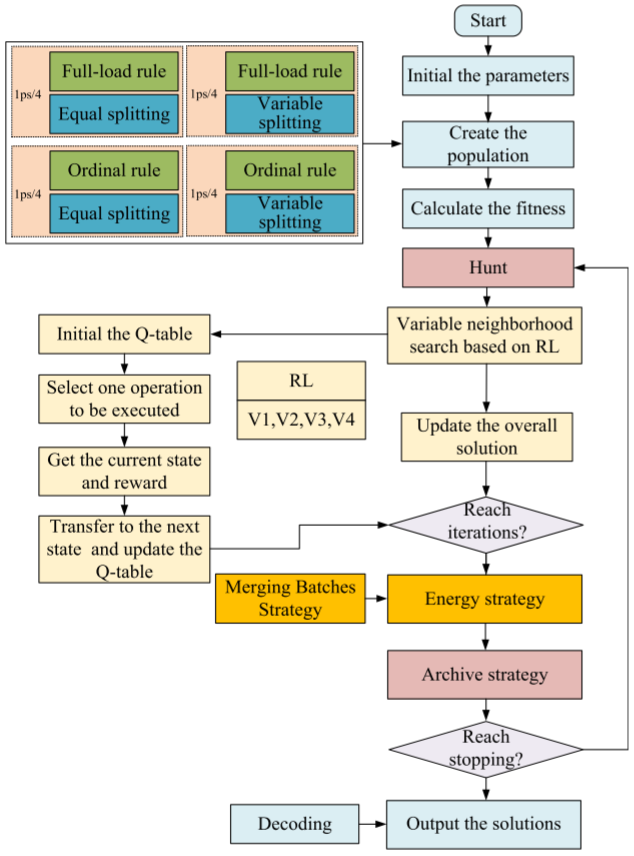
3.强化学习多目标灰狼算法MOGWO-RL
编码与解码
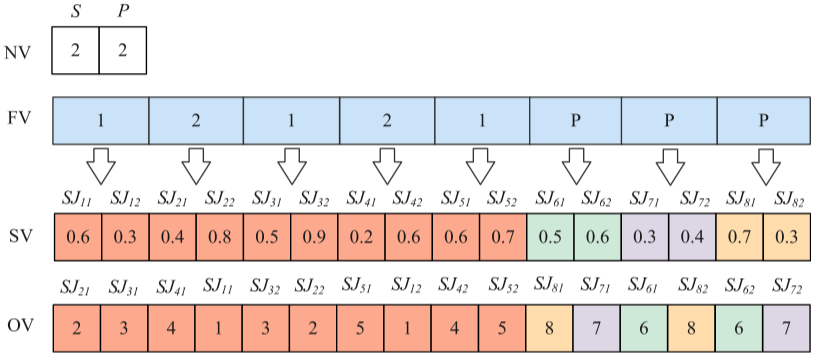
在编码过程中,四个一维向量用于表示解决方案,包括批次数量、任务分配、每个批次的大小和批次顺序。数量向量(NV)表示批次数量,基因的取值范围为[1, 2, 3]。工厂向量(FV)表示任务分配的工厂类型,个性化任务用P表示,标准任务则用[1, Fs]表示,其中Fs为标准工厂数量。大小向量(SV)表示每个批次的大小,采用变量任务拆分方法,批次数量不超过3,最大批次为任务总数的90%,最小批次为10%。SV的基因采用一个小数表示不同批次之间数量的比例。
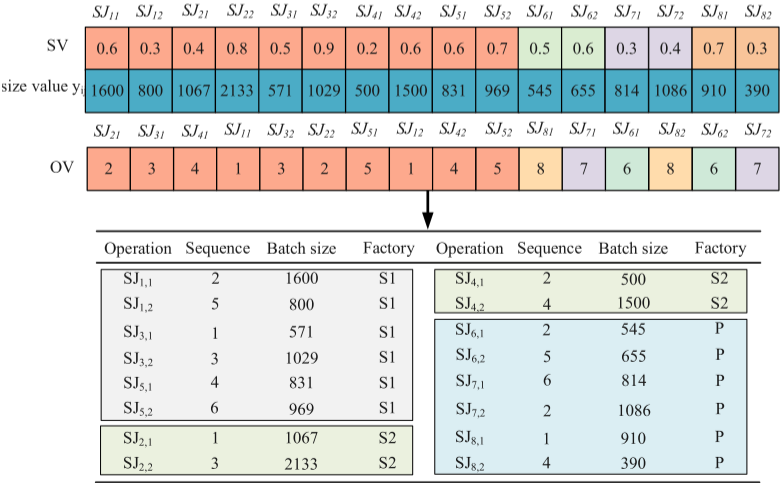
在解码过程中,计算每个批次的大小并按照OV向量对各工厂的加工顺序进行排序。任务的工厂分配依据FV向量的值,最终的完工时间由装配工作站的完成时间确定。
SJij=⌊tsi∙yij∑yij⌋,SJij∈IiSJ_{ij}=\left\lfloor ts_{i}\bullet\frac{y_{ij}}{\sum y_{ij}}\right\rfloor,SJ_{ij}\in I_{i} SJij=⌊tsi∙∑yijyij⌋,SJij∈Ii
初始化策略
本文提出了两种初始启发式规则——任务分配和任务拆分,用于初始化工厂向量(FV)和大小向量(SV)。任务分配通过满负荷和顺序规则将任务分配给不同工厂,确保任务合理分配;任务拆分结合等分拆分和变量拆分规则,以增加SV的多样性。此外,批次数量和批次顺序采用随机规则,进一步提升初始种群的多样性。

捕猎策略
调度问题属于离散问题,因此MOGWO捕猎策略需要进行重新设计。在每次迭代的捕猎操作中,www狼会选择与三位领导者之一进行交叉,用来探索解空间。
μit+1={cross(μit,μαt),ifrand<13cross(μit,μβt),if13≤rand<23cross(μit,μγt),otherwise\left.\mu_{i}^{t+1}= \begin{cases} cross(\mu_{i}^{t},\mu_{\alpha}^{t}),ifrand<\frac{1}{3} \\ cross\left(\mu_{i}^{t},\mu_{\beta}^{t}\right),if\frac{1}{3}\leq rand<\frac{2}{3} \\ cross\left(\mu_{i}^{t},\mu_{\gamma}^{t}\right),otherwise & \end{cases}\right. μit+1=⎩⎨⎧cross(μit,μαt),ifrand<31cross(μit,μβt),if31≤rand<32cross(μit,μγt),otherwise
基于强化学习的可变邻域搜索
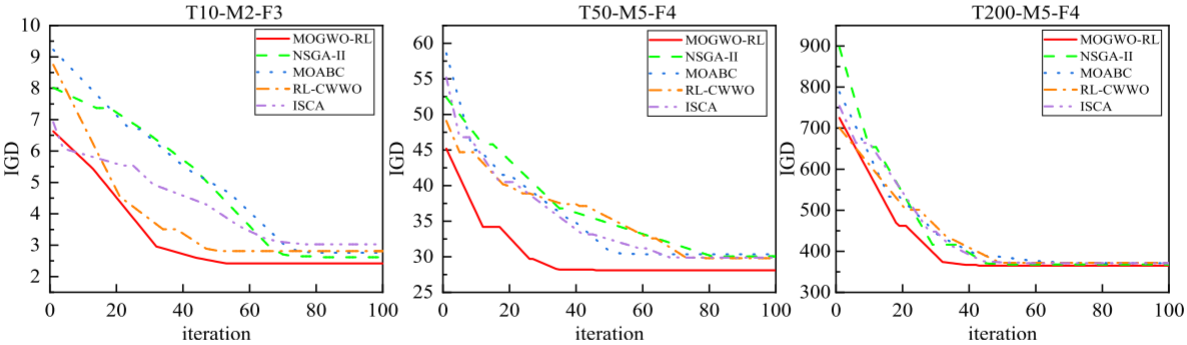
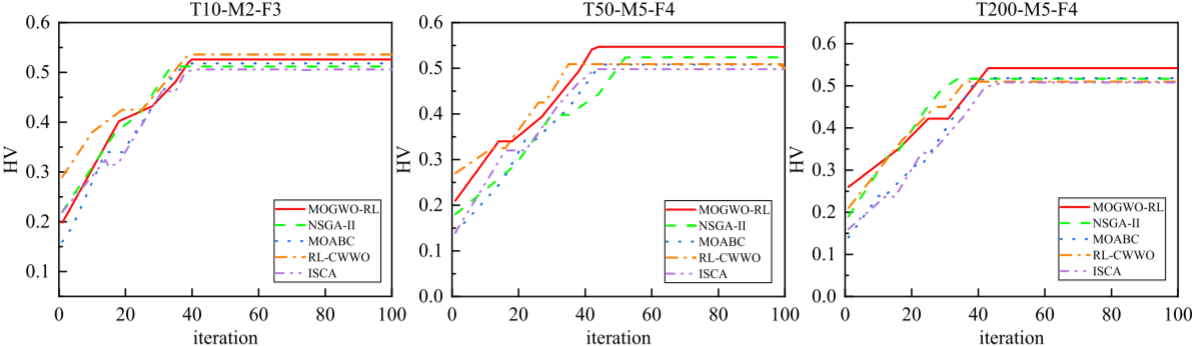
为了提高MOGWO的性能,本文设计了基于强化学习的可变邻域搜索方法,该方法通过四种邻域算子优化解:交换关键工厂任务(V1)、调整批次大小(V2)、调整任务顺序(V3)和改变批次大小(V4)。强化学习用于自动选择最佳操作,避免陷入局部最优解,并通过IGD和HV评估搜索的收敛性和多样性。
批次合并策略
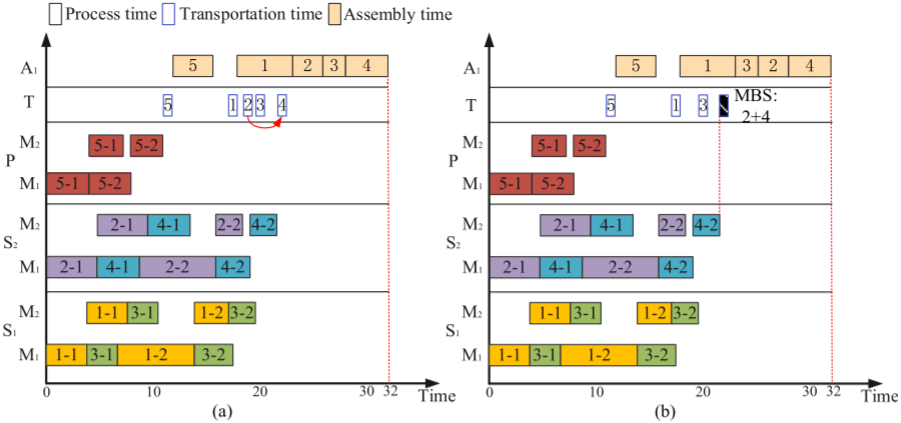
DHFSP-OMTA中的TEC包括工作站和运输能耗,而流车间的工作站能耗难以降低。通过提出的批次合并策略(MBS)在不增加完成时间的情况下优化TEC。通过在运输过程中合并装配阶段有时间冲突的批次,可以减少运输能耗,同时保持完成时间不变。
4.结果展示
5.参考文献
[1] Chen X, Li Y, Wang L, et al. Multi-objective grey wolf optimizer based on reinforcement learning for distributed hybrid flowshop scheduling towards mass personalized manufacturing[J]. Expert Systems with Applications, 2025, 264: 125866.



















