文章目录
- 0 前言
- 1 主要功能的实现
- 2 拖拽运行的实现
- 3 检查细节【未成功实现】
- 4 总结
0 前言
不知道大家是否遇到过这种情况,提交材料时需要将多个图片材料整合到一个PDF中上传。这个时候我们需要找一个工具,其作用为接收我们给它的若干张图片,并将其按照我们需要的顺序(有时可能也没要求)生成一个PDF文件。对于我本人,之前只能上网找个线上的网站进行整合,不过这种方式需要将自己的图片数据上传,不是很安全,并且上传、处理和下载过程都需要联网,很不方便。于是,今天兴起想用Python写一个脚本工具。
对该工具的期望功能如下:
- 能接收图片输入,并输出合并PDF;
- 操作简单,只需将多张图片选中,拖拽到py脚本即可运行。
1 主要功能的实现
就一个脚本文件,完整代码如下:
import os
import pymupdf
import argparsedef images_to_pdf(image_paths, output_path):"""使用 PyMuPDF 将多张图片合并为一个PDF文件:param image_paths: 图片路径列表:param output_path: 输出的PDF路径"""doc = pymupdf.open() # 创建一个新的PDF文档# 按文件名排序图片sorted_images = sorted(image_paths)for img_path in sorted_images:try:img = pymupdf.open(img_path) # open pic as documentrect = img[0].rect # pic dimensionpdfbytes = img.convert_to_pdf() # make a PDF streamimg.close() # no longer neededimgPDF = pymupdf.open("pdf", pdfbytes) # open stream as PDFpage = doc.new_page(width=rect.width, # new page with ...height=rect.height) # pic dimensionpage.show_pdf_page(rect, imgPDF, 0) # image fills the pageprint(f"已添加图片: {os.path.basename(img_path)}")except Exception as e:print(f"处理图片 {img_path} 时出错: {e}")continueif len(doc) == 0:print("没有有效的图片可以转换为PDF")return# 保存PDF文件try:doc.save(output_path)print(f"成功生成PDF文件: {output_path}")except Exception as e:print(f"保存PDF失败: {e}")finally:doc.close()def main():# 设置命令行参数parser = argparse.ArgumentParser(description='将图片合并为PDF')parser.add_argument('images', nargs='*', help='要合并的图片文件')parser.add_argument('-o', '--output', default='output.pdf', help='输出的PDF文件名')args = parser.parse_args()# 如果没有拖拽文件,提示用法if not args.images:print("请将图片文件拖拽到本脚本上,或使用命令行参数指定图片文件")print("用法: python images_to_pdf.py 图片1.jpg 图片2.png [...] [-o 输出.pdf]")input("按回车键退出...")return# 检查输出文件扩展名if not args.output.lower().endswith('.pdf'):args.output += '.pdf'# 转换图片为PDFpy_dir = os.path.dirname(__file__) # 当前脚本所在的目录images_to_pdf(args.images, os.path.join(py_dir, args.output))# 保持窗口打开以便查看结果input("按任意键关闭窗口...")if __name__ == "__main__":main()
依赖PyMuPDF库实现,关键代码部分参考:PyMuPDF 文档。
新建一个txt文件,将上面的代码复制进去,保存,将其重命名为images_to_pdf.py(检查重命名后文件类型是否带PY,别是txt文本文档就行)。
2 拖拽运行的实现
新建一个txt文件,将下面代码复制进去,保存,重命名为pyfile_droppable.reg。
Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\Python.File\shellex\DropHandler]
@="{60254CA5-953B-11CF-8C96-00AA00B8708C}"[HKEY_CLASSES_ROOT\py_auto_file\shellex\DropHandler]
@="{60254CA5-953B-11CF-8C96-00AA00B8708C}"[HKEY_CLASSES_ROOT\Python.File\Shell\open\command]
@="\"H:\\anaconda3\\envs\\opencv\\python.exe\" \"%L\" %*"[HKEY_CLASSES_ROOT\py_auto_file\Shell\open\command]
@="\"H:\\anaconda3\\envs\\opencv\\python.exe\" \"%L\" %*"
其中
\"H:\\anaconda3\\envs\\opencv\\python.exe\"为需要调用执行的Python解释器,这里我是指定了安装PyMuPDF库的虚拟环境中的Python解释器。需自行修改,注意\的转义作用。
双击该文件运行,完成注册表的修改。原理参见:文件拖动到 Python 脚本上执行。
3 检查细节【未成功实现】
-
若完成步骤1、2后,还不能拖拽运行,可尝试:
- 重启资源管理器;
- 关机重启。
-
上述方法仍无效,继续尝试:
打开注册表,查看
计算机\HKEY_CLASSES_ROOT\.py的值,我这里是py_auto_file。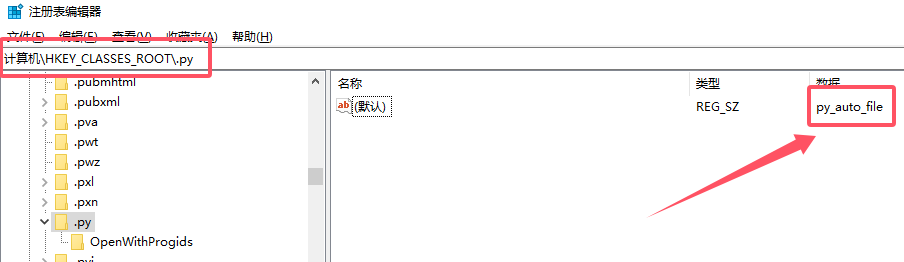
接下来打开
计算机\HKEY_CLASSES_ROOT\py_auto_file,确保该目录下的项已安装步骤2正确修改。[HKEY_CLASSES_ROOT\py_auto_file\shellex\DropHandler] @="{60254CA5-953B-11CF-8C96-00AA00B8708C}"[HKEY_CLASSES_ROOT\py_auto_file\Shell\open\command] @="\"H:\\anaconda3\\envs\\opencv\\python.exe\" \"%L\" %*"
-
上述方法仍无效,继续尝试:
右键py文件,选择打开方式,选择其他应用,如下图所示,选择Python始终作为.py文件的打开方式。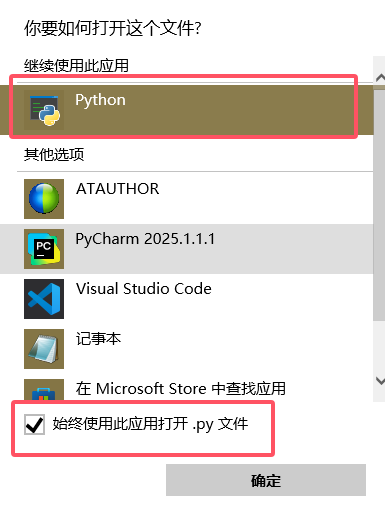
我通过这一步修改就可以成功实现拖拽运行了。
4 总结
- 该工具运行起来很快,也比较方便。使用时,如果需要图片在PDF中按顺序放置,则可以将图片重命名,在原名称前加一个数字进行排序,当然也可以在原脚本代码中添加针对输入图片路径的排序逻辑。如果对顺序没有要求,那就不需要注意这些,直接将待整合的所有图片全部选中,拖拽进py脚本文件,松手即可运行,整合的PDF文件将在脚本的同目录下输出生成。
- 后期如果有必要,也可以使用 PyInstaller 把脚本打包成exe,这样小工具运行就可以不依赖于虚拟环境了。





)


总结)
![[Shell编程] 零基础入门 Shell 编程:从概念到第一个脚本](http://pic.xiahunao.cn/[Shell编程] 零基础入门 Shell 编程:从概念到第一个脚本)
 -- 插入排序)




)


:CyclicBarrier 与 Phaser 的协同应用)
