本文介绍了基于Wenet语音识别工具包的实时敏感词屏蔽技术方案。该方案通过客户端缓存25秒直播内容,利用Wenet的流式识别和断句检测功能,实时检测讲师语音中的敏感词,并将对应位置的语音替换为"哔"声。文章详细阐述了Wenet的两种识别方式(流式/非流式)、三种部署方案及其性能指标,重点说明了客户端4.x的接入方案:采用流式识别+智能断句方式,在子线程处理敏感词检测,主推流流程不受影响,最大延迟不超过25秒。该技术可在直播过程中实现敏感内容的实时自动屏蔽。
直播敏感语音,实现"哔哔"屏蔽技术。

直播场景实际应用中的需求:在客户端直播的时候,实时检测讲师的语音内容,检测到敏感词后,自动把对应的语音内容用“哔”声代替 。
客户端缓存25s直播内容,在语音识别引擎识别到屏蔽词后,找到屏蔽词在语音缓存的位置,将语音内容替换为“哔”声的语音内容。
1. wenet简述:
Wenet是出门问问语音团队联合西工大语音实验室开源的一款面向工业落地应用的语音识别工具包,该工具用一套简洁的方案提供了语音识别从训练到部署的服务。
1.1. wenet识别方式
流式:语音以实时流的方式推入引擎;(识别结果不太准确,较快)
非流式:语音以一整段语音的方式推入引擎。(识别结果较准确,较慢)
断句检测:如果语音以流式推入引擎,则需要断句检测,原理参考:
WeNet 更新:支持 Endpoint 检测
Endpoint 检测是语音识别系统的重要组成部分,可以提高人机交互的效能和质量。它的任务是确定用户何时结束讲话,这对于实时长语音转写和语音搜索等交互式语音应用非常重要。
最近,WeNet 的更新则支持了 endpoint 的检测。有了 endpoint 检测,我们就可以愉快地进行实时长语音转写了。下面将从实现原理和应用方面介绍 endpoint 检测和实时长语音转写的使用。
①. 识别出文字之前,检测到了 5s 的静音;
②. 识别出文字之后,检测到了 2s 的静音;
③. 解码到概率较小的 final state,且检测到了 1s 的静音;
④. 解码到概率较大的 final state,且检测到了 0.5s 的静音;
⑤. 已经解码了 20s。
注意:wenet同时支持流失、非流失、以及断句检测。当数据以流失输入wenet时,wenet可在返回流式结果的同时智能断句,并返回整句的最终结果。
1.2. wenet部署方案
①. 部署在端上:win64、mac-intel64、Linux-64;
APP直接调用wenet接口(C++)-(本次demo采用)
②. 部署在服务器上:Linux-docker
APP调用websocket接口,上传音频,由服务器通过websocket返回结果。
1.3. wenet延时性能
①. 处理延时:处理10s音频不超过1s;
②. 模型带来的流式延时:不超过0.4s;
③. 断句并重打分计算:不超过0.14s。
1.4. 参考资料
https://github.com/wenet-e2e/wenet
Welcome to wenet’s documentation! — wenet documentation
https://zhuanlan.zhihu.com/p/349586567
1.5.WeNet Endpoint 实现
WeNet 中 endpoint 检测相关代码的实现在 decoder/ctc_endpoint.h 和 decoder/ctc_endpoint.cc 中。
// 遍历每一个时间步
for (int t = 0; t < ctc_log_probs.size(0); ++t) {torch::Tensor logp_t = ctc_log_probs[t];// 获取当前时间步 blank 标签的概率float blank_prob = expf(logp_t[config_.blank].item<float>());// 解码帧数加一num_frames_decoded_++;// 判断 blank 标签的概率是否大于阈值(默认 0.8)if (blank_prob > config_.blank_threshold) {// 是,则尾部 blank 标签的帧数加一num_frames_trailing_blank_++;} else {// 否,则尾部 blank 标签的帧数置零num_frames_trailing_blank_ = 0;}
}三条规则的表示如下所示,可以手动添加更多的规则或者更改规则中的时间,以满足各种不同场景下的需求。
// rule1 times out after 5000 ms of silence, even if we decoded nothing.
CtcEndpointRule rule1;
// rule2 times out after 1000 ms of silence after decoding something.
CtcEndpointRule rule2;
// rule3 times out after the utterance is 20000 ms long, regardless of
// anything else.
CtcEndpointRule rule3;CtcEndpointConfig(): rule1(false, 5000, 0), rule2(true, 1000, 0), rule3(false, 0, 20000) {}2. 基于保利威客户端4.x接入方案
2.1. 采用的识别方式
①.流失:数据以流失推入wenet;
②.断句:由于流失实时识别结果并不准确,且不带时间戳,无法准确定位音频。因此,使用wenet的断句功能,断句后获取整句结果;
2.2. 原理
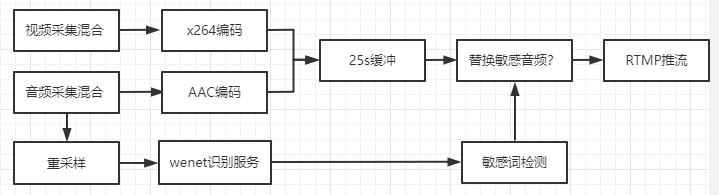
①. 接入方式:4.x采用直接调用wenet-C++接口的方式接入;
②. 延时直播:识别方式采用流失+智能断句的方式,断句最长会导致20s延时,加上其他延时,因此,最长不超过25s。
③. 主流程不打断:OBS的采集→编码→缓冲→推流,该流程不会进行任何阻塞。 wenet识别→敏感词检测均在子线程处理,若无法找到敏感词对应的音频数据包,则会直接丢弃。
 配图企业直播客户端软件接入敏感语音屏蔽技术
配图企业直播客户端软件接入敏感语音屏蔽技术
我的热门文章汇总:
- 开通微信视频号直播需要满足哪些条件?
- 彻底永久关闭WIN10系统的自动更新(操作步骤)
- 视频码率、帧率、分辨率、视频标清、高清、全高清的全面介绍与参考表
- Thinkpad电脑系列产品进入Bios设置和U盘启动(重装系统)
- 网线水晶头接法图解详细8根线芯顺序排序图示
我的在线教育原创文章汇总:
- Vue3框架对接保利威云点播播放器的实践(实例)
- 视频点播web端AI智能大纲(自动生成视频内容大纲)的代码与演示
- html5视频播放器的断点续播和记忆播放是如何做的?
- 视频安全之视频防盗链和视频防盗录
- 课程学习网站视频禁止拖拽快进是如何做的?


核心机制剖析:持久化与共享的终极解决方案)





![[自动化Adapt] GUI交互(窗口/元素) | 系统配置 | 非侵入式定制化](http://pic.xiahunao.cn/[自动化Adapt] GUI交互(窗口/元素) | 系统配置 | 非侵入式定制化)


+数据结构数组、树、队列【旧文搬运】)







