最初发布时间:2020-09-19 23:17:48
以前写这篇文章,主要是接触到一些非计算机学院的同学,为了交流方便我写下了这篇文章……虽然现在回过头来看写得也比较草率,但确实是我对电脑的基础操作的最早的认识,放到现在我绝对写不出来哪个功能是最常用的了,因为我觉得哪个功能都常用。
文章目录
- git
- 1.下载
- 2.git内登录github账号
- 3.github上不太方便而git很方便做的某些事
- 大学计算机基础
- 小彩蛋
- 数组
- 参考文章
- 计算元素地址(i、j 均开始于 1)
- 按列序存放(高下标优先)
- 树
- 参考文章
- 树
- 二叉树
- 完全二叉树
- 存储结构
- 二叉树遍历:
- 队列
- 参考文章
- 总结
- 非循环队列
- 循环队列
- 双端队列(Deque)
- 优先队列(不遵循 FIFO)
github使用非常简单,和百度一样用就行,也支持下载上传,多看看就能掌握基本操作,暂时不讲,先说git。
git
1.下载
链接:https://pan.baidu.com/s/1-QimGqEr7fLtpfkSP35waA
提取码:b9lm
以上是我自己在用的Git-2.11.1-64-bit。
在官网上下载也行,但是不推荐,因为官网下的也差不多,而且官网常常难以打开难以下载,容易链接失败,点一年都不一定能生成下载链接。(个人体验)
然后按默认选项安装即可。
2.git内登录github账号
之后的不赘述,直接给链,廖雪峰大神讲得比我好。由于还在入门,我们只想简单知道git而不是立即搞事情,版本库可以先不建。后面的如何回退也可以不用看。登录成功就行。
https://www.liaoxuefeng.com/wiki/896043488029600/896067074338496
3.github上不太方便而git很方便做的某些事
git clone xxx
xxx是github下载按钮处的链接。
还有的方便的就是用git删文件。直接在本地库上操作,再往上push一下就好了,这种需要建库的事情请继续看廖大佬的教程。
如果看不懂的话,或者说有些基础指令有问题的话,请看下面的有关大学计算机基础的教程。
大学计算机基础
链接:https://pan.baidu.com/s/1-QimGqEr7fLtpfkSP35waA
提取码:b9lm
以上还有我们计算机基础的课件。
这个是讲cmd之类的东西的,很多东西都是依赖这些指令的,所以建议随便看看用用。
其实吧,说起来就这么几条指令必用:
cd ..
cd Desktop
dir
第一条,退回上一级目录;
第二条,去下一级名字叫做Desktop也就是桌面的目录;
第三条,展示当前目录下的所有文件。
为什么说这三条是必备的,而不是删除之类的呢?
第一二条让你便捷地前后跳转,而第三条让你知道你现在能去哪。
一级一级跳转有时候属实不便,所以建议再会一条指令,cd 绝对路径
绝对路径:假设你已知能去的地方是长沙,同时假设最大的描述词是地球,绝对路径就是地球的中国的湖南的长沙。如E:\资料\大物\大物实验。
相对路径:假设你在中国,你想去长沙,相对路径就是湖南的长沙。如大物\大物实验。
前后跳转以及随便翻找就是我认为的文件结构了。
小彩蛋
- win+R -> 输入taskmgr ->方便清理后台进程,检查恶意弹窗广告,还电脑清净。
- 在系统变量里的环境变量里添加某个文件夹,之后就可以直接用win+R并输入这个文件夹的相对路径,访问这个文件夹的内容。也就是,如果把快捷方式全部放到一个文件夹里并且为它添加环境变量,就可以用键盘呼出应用和资料,不需要鼠标点点点,也不用把快捷方式放桌面上。
暂时想到这么多,之后再补充。【补充的都在网盘里了,可以自己看】
接下来顺便再贴另一篇文章,我懒得贴成两篇了,内容量不够。
数组
参考文章
计算元素地址(i、j 均开始于 1)
- 主要是要分析出该元素前面有多少个(记为 n)元素,分析出来了即可知道下标为 n,LOC(i)=LOC(0)+size(L)*n。
- 分析过程:以行序或列序优先将矩阵中的元素依次排列。以按行序优先排列为例,假设 k 元素在第 i 行,则前面应至少有 x 个元素,再假设 k 在第 j 列,在当前行中前面应再有 y 个元素,从而得到 k 元素与 i、j 的对应关系。
按列序存放(高下标优先)
- 对于 Am*n,有 LOC(i,j)=LOC(0,0)+(j*m+i)*sizeof(L)。
- 对于 Aabc,有 LOC(i,j,k)=LOC(0,0)+(k*a*b+j*a+i)*sizeof(L)。
- 同理可推至 n 维数组。
树
参考文章
树
-
非线性,一对多。(定义是递归形式的)
-
根(根结点的层为 1)、根的子树、结点的度(结点的子树数目)、叶子结点(也叫终端节点)、分支节点、双亲(虽然叫双亲但是 parent 只有一个)、树的深度(又称高度,叶子结点的层数)、兄弟、堂兄弟(同层不同双亲的结点)、祖先、子孙(所有子树的结点)、有序树(子树的顺序从左到右有限定,更换则不是同一颗树)、无序树。
-
森林:m 棵互不相交的数的集合,如 F={T1,T2,T3},任何一棵非空树可表示为 Tree=(root,F),F 是子树森林。
因为 root 根结点被拆掉了之后剩下的子树就散了互不相交可以看作森林)
二叉树
- 递归定义:根节点,左子树右子树。每个结点的孩子是不会重复的。
- 每个结点至多两个子树,是有序树。
- 叶子结点的个数 n0=度为 2 的结点数 n2+1。(不直观,需要记)
总数 n=n0+n1+n2,孩子的个数=n-1=2n2+n1。
- 含有 n 个结点的二叉链表中,有 n+1 个空链域。
利用 n0=n2+1,空链域数=2n0+n1。
- 满二叉树:深度为 k 且有 2k-1 个结点的二叉树。
完全二叉树
- 每个结点都和同深度的满二叉树中的编号从 1 至 n 的结点一一对应。其叶结点只可能出现在层次最大或者第二大的层上。结点数 2k-1-1<n<=2k。
- 对于完全二叉树的第 i 个结点,若 2i>n,则该结点没有左孩子结点;若 2i+1>n,则该结点没有右孩子结点。若结点有双亲结点,则双亲结点的编号必然是 i/2 向下取整。
存储结构
- 采用链式存储结构比较方便。
- 三叉链表比二叉链表多一个指向双亲结点的指针。
- 静态链表也可以用来描述二叉树,此时的左孩子右孩子指针只要是孩子结点对应的标号(当然也可以是指针,但没必要)就可以了,整体看起来是一个结构数组。
二叉树遍历:
D----访问根节点,输出根节点
L----递归遍历左子树
R----递归遍历右子树
- 先序遍历 DLR
- 中序遍历 LDR
- 后序遍历 LRD
队列
参考文章
- 看完这篇你还不知道这些队列,我这些图白作了
- Java 中的 queue 和 deque 对比详解
总结
- 队列遵循 FIFO 原则,但是不一定以 FIFO 的方式排序各个元素。
非循环队列
-
数据迁移只需要在 tail=MaxSize&&head!=0 时进行,以节省使用代价。
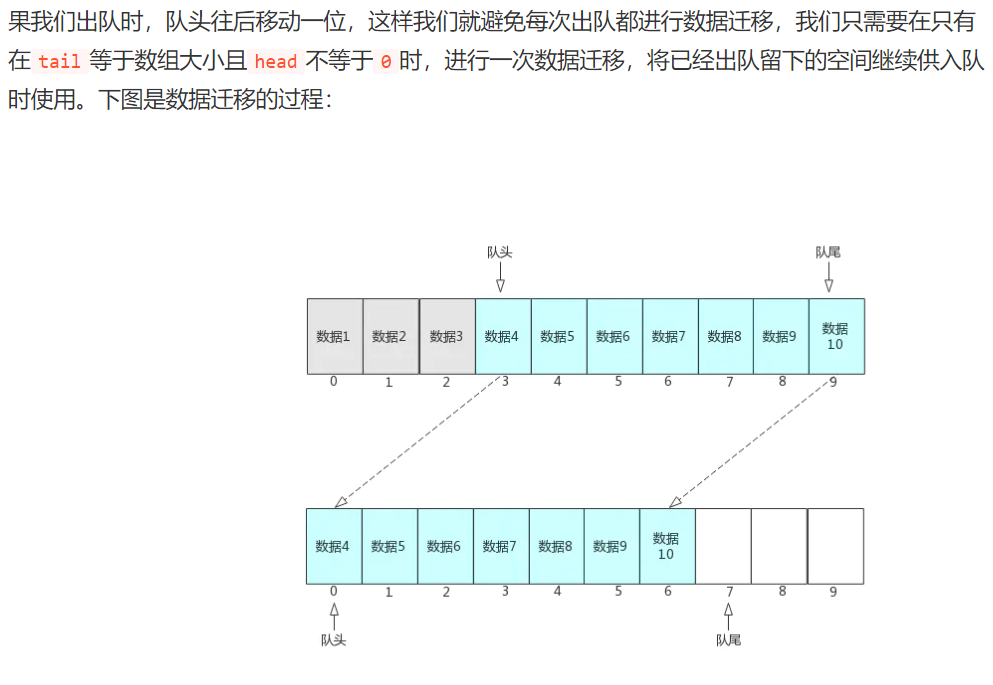
-
判断队列满了的条件,tail = MaxSize,head = 0。
-
链式队列与顺序队列比起来不需要进行数据的迁移,实现相对简单很多,但是链式队列增加了存储成本。
循环队列
- 对于一个存储空间为 n 的循环队列,只能存放 n-1 位数据,令 tail 与 head 重合时为队空条件,(tail+1)%MaxSize==head 时为队满条件。
- 出入队列都应该取模。比如入队 tail=(tail+1)%MaxSize,出队 head=(head+1)%MaxSize。
- 队列长度 length=(tail-head+MaxSize)%MaxSize。一般队列长度仅需要 tail-head,而循环队列中,head 可能会比 tail 大,所以需要加上 MaxSize 并取模。
- 由长度公式以及队满条件知,显然,循环队列队满时 length 为 MaxSize-1。
双端队列(Deque)
- 队头、队尾都可以进行入队、出队操作。总之它即有栈的功能,也有队列的功能。
- 在将双端队列用作队列时,将得到 FIFO 行为;在将双端队列用作堆栈时,将得到 LIFO 行为;
优先队列(不遵循 FIFO)
- 从队头出队,队尾入队。不过每次入队时,都会按照入队数据项的关键值进行排序。保证优先级最高的最先出队。
- 一般用堆实现。
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://shandianchengzi.blog.csdn.net/article/details/149937984。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。











![[2025CVPR-图象生成方向]ODA-GAN:由弱监督学习辅助的正交解耦比对GAN 虚拟免疫组织化学染色](http://pic.xiahunao.cn/[2025CVPR-图象生成方向]ODA-GAN:由弱监督学习辅助的正交解耦比对GAN 虚拟免疫组织化学染色)

SLAM卷不动了,机器人还有哪些方向能做?)


网上商城)


