1. String、StringBuffer、StringBuilder区别
| 特性 | String | StringBuffer | StringBuilder |
|---|---|---|---|
| 可变性 | 不可变 | 可变 | 可变 |
| 线程安全 | 是 | 是(synchronized) | 否 |
| 性能 | 低(频繁操作时) | 中等 | 高 |
| 场景 | 字符串常量 | 多线程字符串操作 | 单线程字符串操作 |
2. 接口和抽象类的区别
| 特性 | 接口(Interface) | 抽象类(Abstract Class) |
|---|---|---|
| 实现/继承 | 多实现 | 单继承 |
| 方法实现 | Java 8前无实现 | 可有实现 |
| 变量 | 只能是常量 | 普通变量 |
| 构造方法 | 无 | 有 |
| 设计目的 | 定义行为规范 | 代码复用 |
3. Thread和Runnable区别
Thread:继承方式,单继承限制
Runnable:接口实现,更灵活,资源共享方便
推荐:优先使用Runnable,符合面向接口编程
4. 接口支持静态方法吗?
支持(Java 8+):
interface MyInterface {static void staticMethod() {System.out.println("静态方法");}
}5. TLS通信机制
握手阶段:协商加密算法、交换密钥
证书验证:验证服务器身份
对称加密:使用会话密钥加密通信
关键点:前向安全、混合加密
6. CA发的是私钥还是公钥?
CA颁发的是包含公钥的数字证书,私钥由申请者自己保管。
7. List、Set、Map的区别
| 集合类型 | 顺序 | 重复 | 空值 | 实现类 |
|---|---|---|---|---|
| List | 有序 | 允许 | 允许多个 | ArrayList, LinkedList |
| Set | 无序 | 不允许 | 最多一个 | HashSet, TreeSet |
| Map | 无序 | key唯一 | HashMap允许一个null key | HashMap, TreeMap |
8. List的访问方式
索引访问:
list.get(index)迭代器:
Iterator/ListIteratorfor-each循环
Java 8+ Stream API
9. ArrayList和LinkedList区别
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 底层 | 动态数组 | 双向链表 |
| 访问 | O(1)随机访问 | O(n)顺序访问 |
| 增删 | O(n) | O(1)首尾操作 |
| 内存 | 连续空间 | 节点+指针 |
10. HashMap加载因子
默认0.75是空间与时间的平衡点:
过高:哈希冲突增加
过低:内存浪费
扩容触发:元素数 > 容量×加载因子
11. 线程和进程区别
| 维度 | 进程 | 线程 |
|---|---|---|
| 资源 | 独立内存空间 | 共享进程资源 |
| 切换开销 | 大 | 小 |
| 通信 | IPC(管道等) | 共享内存(需同步) |
| 健壮性 | 一个崩溃不影响其他 | 线程崩溃影响整个进程 |
12. View和ViewGroup点击事件传递机制
事件传递流程(以ACTION_DOWN为例):
分发阶段(自上而下):
Activity.dispatchTouchEvent() → Window → DecorView
每个ViewGroup的dispatchTouchEvent()调用onInterceptTouchEvent()
如果未被拦截,继续向子View传递
处理阶段(自下而上):
最底层View的onTouchEvent()首先获得处理机会
若未处理,事件回传给父ViewGroup
最终可由Activity.onTouchEvent()处理
关键方法:
public boolean dispatchTouchEvent(MotionEvent ev) {// 1. 判断是否拦截if (onInterceptTouchEvent(ev)) {return super.dispatchTouchEvent(ev);}// 2. 遍历子View处理for (View child : children) {if (child.dispatchTouchEvent(ev)) {return true;}}// 3. 自身处理return onTouchEvent(ev);
}事件冲突解决方案:
外部拦截法:重写父容器的onInterceptTouchEvent()
内部拦截法:子View调用requestDisallowInterceptTouchEvent()
典型场景:ScrollView内嵌ListView
13. B树与B+树深度对比
B树结构特性:
所有节点存储数据
关键字分布在整个树中
非叶子节点也包含数据指针
B+树结构特性:
数据仅存于叶子节点
叶子节点通过指针链接
非叶子节点只作索引
性能对比表:
| 特性 | B树 | B+树 |
|---|---|---|
| 查询时间复杂度 | O(logₘn)不稳定 | O(logₘn)稳定 |
| 范围查询效率 | 需要中序遍历 | 链表顺序访问O(1) |
| 磁盘IO次数 | 随机访问可能更多 | 更稳定更少 |
| 内存利用率 | 非叶节点存数据 | 非叶节点纯索引 |
14. 数据库索引选择B+树的原因
工程化优势:
IO优化:
节点大小设计为磁盘页大小(通常4KB)
单次IO能加载更多键值
查询稳定性:
所有查询都要走到叶子节点
避免B树中非叶节点命中导致的查询时间波动
范围查询优化:
-- B+树能高效处理 SELECT * FROM table WHERE id BETWEEN 100 AND 200;
叶子节点链表实现O(1)复杂度范围遍历
全盘扫描优势:
遍历叶子节点链表即可获得有序数据
避免B树的树形遍历
15. 平衡树类型辨析
平衡二叉树对比多路平衡树:
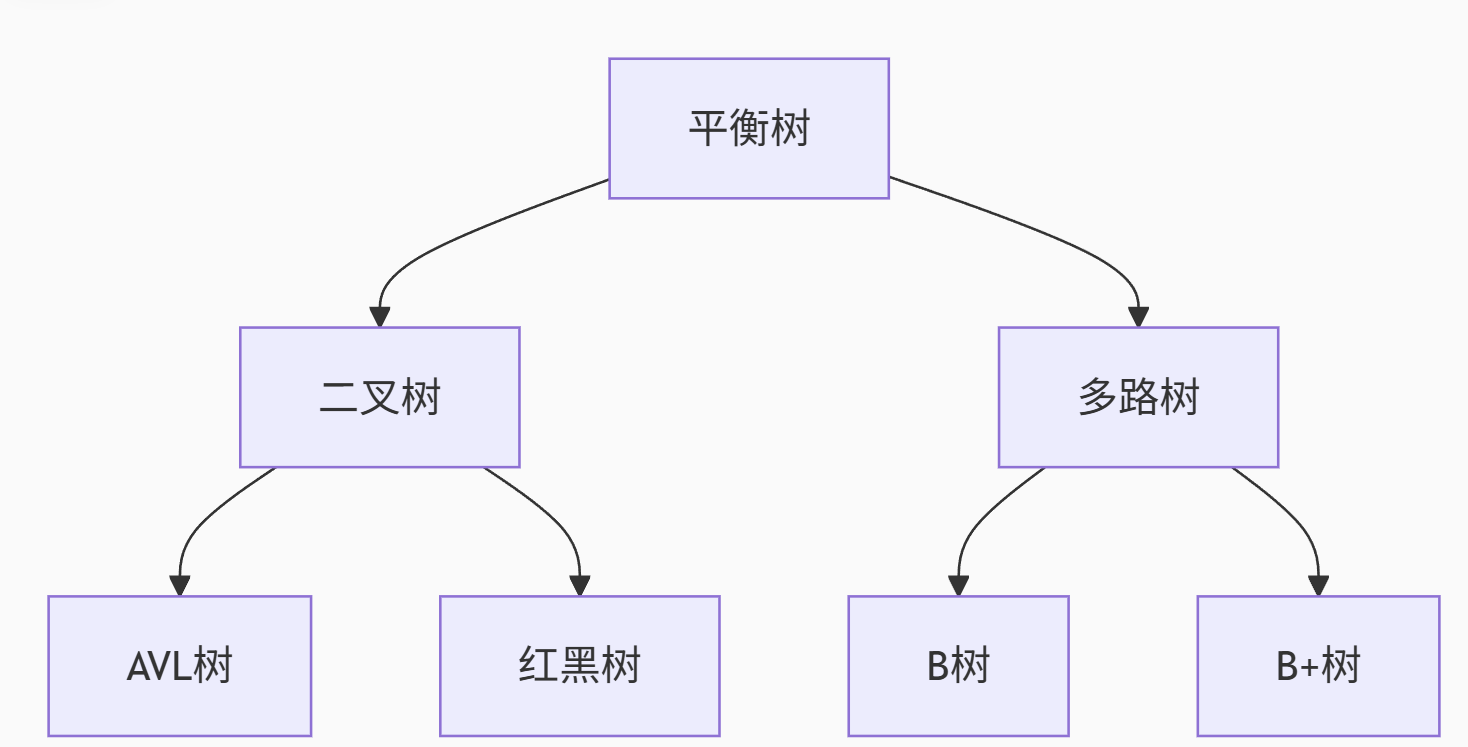
关键区别:
节点容量:
二叉树:每个节点最多2个子节点
B/B+树:每个节点通常有几百子节点(取决于磁盘页大小)
平衡方式:
AVL树:严格平衡(高度差≤1)
红黑树:近似平衡(最长路径≤2倍最短)
B/B+树:通过分裂/合并保持平衡
适用场景:
内存查找:红黑树
磁盘索引:B+树
16. 排序算法复杂度
时间复杂度:平均O(nlogn),最差O(n²)(已排序数组)
空间复杂度:O(logn)递归栈
归并排序实现:
时间复杂度:稳定O(nlogn)
空间复杂度:O(n)临时数组
17. Java绘制过程详解
View绘制三阶段:
Measure阶段:
protected void onMeasure(int widthSpec, int heightSpec) {// 根据父容器的MeasureSpec和自身LayoutParams计算int width = calculateWidth(widthSpec);int height = calculateHeight(heightSpec);setMeasuredDimension(width, height); // 必须调用 }MeasureSpec包含模式和大小(EXACTLY/AT_MOST/UNSPECIFIED)
Layout阶段:
protected void onLayout(boolean changed, int left, int top, int right, int bottom) {// ViewGroup需遍历布局所有子Viewfor (View child : children) {child.layout(childLeft, childTop, childRight, childBottom);} }Draw阶段:
protected void onDraw(Canvas canvas) {// 示例:绘制圆角矩形Paint paint = new Paint(Paint.ANTI_ALIAS_FLAG);paint.setColor(Color.BLUE);RectF rect = new RectF(0, 0, getWidth(), getHeight());canvas.drawRoundRect(rect, 20, 20, paint); }绘制顺序:背景→主体→子View→装饰
性能优化点:
减少View层级
使用ViewStub延迟加载
避免在onDraw中创建对象
18. OSI七层模型数据处理
HTTP请求在各层的封装:
应用层:HTTP头 + 数据(GET /index.html HTTP/1.1) 表示层:数据加密/压缩(HTTPS增加TLS加密) 会话层:建立/维护会话(Cookie/Session管理) 传输层:TCP头 + 端口号(源端口54321 → 目标端口80) 网络层:IP头 + IP地址(192.168.1.2 → 216.58.200.46) 数据链路层:MAC头 + CRC(源MAC → 网关MAC) 物理层:比特流(电信号/光信号传输)
19. TCP工作原理深度解析
三次握手建立连接:
客户端 → SYN=1, seq=x → 服务端 客户端 ← SYN=1, ACK=1, seq=y, ack=x+1 ← 服务端 客户端 → ACK=1, seq=x+1, ack=y+1 → 服务端
可靠传输机制:
序号确认:
每个字节都有唯一序号
接收方发送ACK确认收到的连续数据
滑动窗口:
// 典型窗口结构 struct {uint32_t left; // 窗口左边界uint32_t right; // 窗口右边界uint32_t size; // 窗口大小(根据拥塞控制调整) } sliding_window;实现流量控制和拥塞避免
超时重传:
RTO(Retransmission Timeout)动态计算:
RTO = SRTT + max(G, K×RTTVAR)
其中SRTT是平滑RTT,RTTVAR是方差
四次挥手释放连接:
客户端 → FIN=1, seq=u → 服务端 客户端 ← ACK=1, ack=u+1 ← 服务端 ...(服务端数据发送完毕)... 客户端 ← FIN=1, seq=v, ack=u+1 ← 服务端 客户端 → ACK=1, seq=u+1, ack=v+1 → 服务端
20. 死锁及避免方法
死锁定义:多个线程互相持有对方需要的资源,导致所有线程无限期阻塞的状态。
四个必要条件:
互斥条件(资源独占)
占有且等待(持有资源并请求新资源)
不可抢占(资源不能被强制释放)
循环等待(存在等待环路)
避免方案:
方案1:破坏循环等待(固定锁获取顺序) 方案2:使用tryLock(破坏不可抢占)
21. 虚拟内存与内存管理
虚拟内存核心功能:
地址空间隔离(每个进程有独立4GB空间)
按需分页(Page Fault机制)
页面置换(LRU算法)
分页 vs 分段:
| 特性 | 分页 | 分段 |
|---|---|---|
| 划分单位 | 固定大小(4KB) | 逻辑单元(代码/数据段) |
| 碎片问题 | 内部碎片 | 外部碎片 |
| 管理方式 | 页表(多级/TLB加速) | 段表 |
| 优势场景 | 通用内存管理 | 模块化程序 |
现代实现:段页式结合(Linux使用扁平化段模式+分页)
22.排序算法的时间复杂度、空间复杂度及稳定性对比
| 排序算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 | 稳定性 | 关键特性 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n)(已优化) | O(n²) | O(1) | 稳定 | 相邻元素比较交换,适合小规模数据 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 | 每次选最小元素交换,交换次数最少(O(n)次) |
| 插入排序 | O(n²) | O(n)(已排序) | O(n²) | O(1) | 稳定 | 类似扑克牌排序,对基本有序数据效率高 |
| 希尔排序 | O(n^1.3) | O(n log n) | O(n²) | O(1) | 不稳定 | 插入排序改进版,通过分组增量提高效率 |
| 归并排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | 稳定 | 分治法典范,需额外空间,适合外部排序 |
| 快速排序 | O(n log n) | O(n log n) | O(n²)(极端) | O(log n) | 不稳定 | 实际最快的内排序,递归栈空间消耗,需合理选择pivot |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | 不稳定 | 利用堆结构,适合大数据TopK问题 |
| 计数排序 | O(n + k) | O(n + k) | O(n + k) | O(k) | 稳定 | 非比较排序,k为数据范围,适合密集整数数据 |
| 桶排序 | O(n + k) | O(n) | O(n²)(极端) | O(n + k) | 稳定 | 数据均匀分布时高效,依赖桶划分策略 |
| 基数排序 | O(n × k) | O(n × k) | O(n × k) | O(n + k) | 稳定 | 按位排序(LSD/MSD),k为最大位数 |
23. 代码维护工具集
高效开发工具链:

关键工具使用场景:
Git:
git bisect快速定位问题提交ADB:
adb shell dumpsys获取系统状态MAT:分析内存泄漏
LeakCanary:自动化内存检测
24. Android异步加载方案
现代异步编程演进:
基础方案:
// HandlerThread示例
val handlerThread = HandlerThread("Worker").apply { start() }
val handler = Handler(handlerThread.looper)
handler.post { /* 后台任务 */ }协程方案(推荐):
viewModelScope.launch {val data = withContext(Dispatchers.IO) { repository.fetchData() }updateUI(data) // 自动切回主线程
}性能对比:
| 方案 | 线程开销 | 代码可读性 | 生命周期管理 |
| AsyncTask | 中 | 较好 | 差 |
| RxJava | 低 | 较差 | 中 |
| 协程 | 极低 | 优秀 | 优秀 |
25. equals()与hashCode()
| 维度 | equals() | hashCode() |
|---|---|---|
| 用途 | 比较两个对象的内容是否逻辑相等 | 生成对象的哈希码值 |
| 重写要求 | 必须与hashCode()保持一致 | 必须与equals()保持一致 |
| 性能 | 可能较慢(深比较) | 必须高效(O(1)复杂度) |
| 默认实现 | Object类中比较内存地址(==) | Object类中返回对象内存地址的哈希值 |
26. MVC架构解析
Android中的MVC实现:
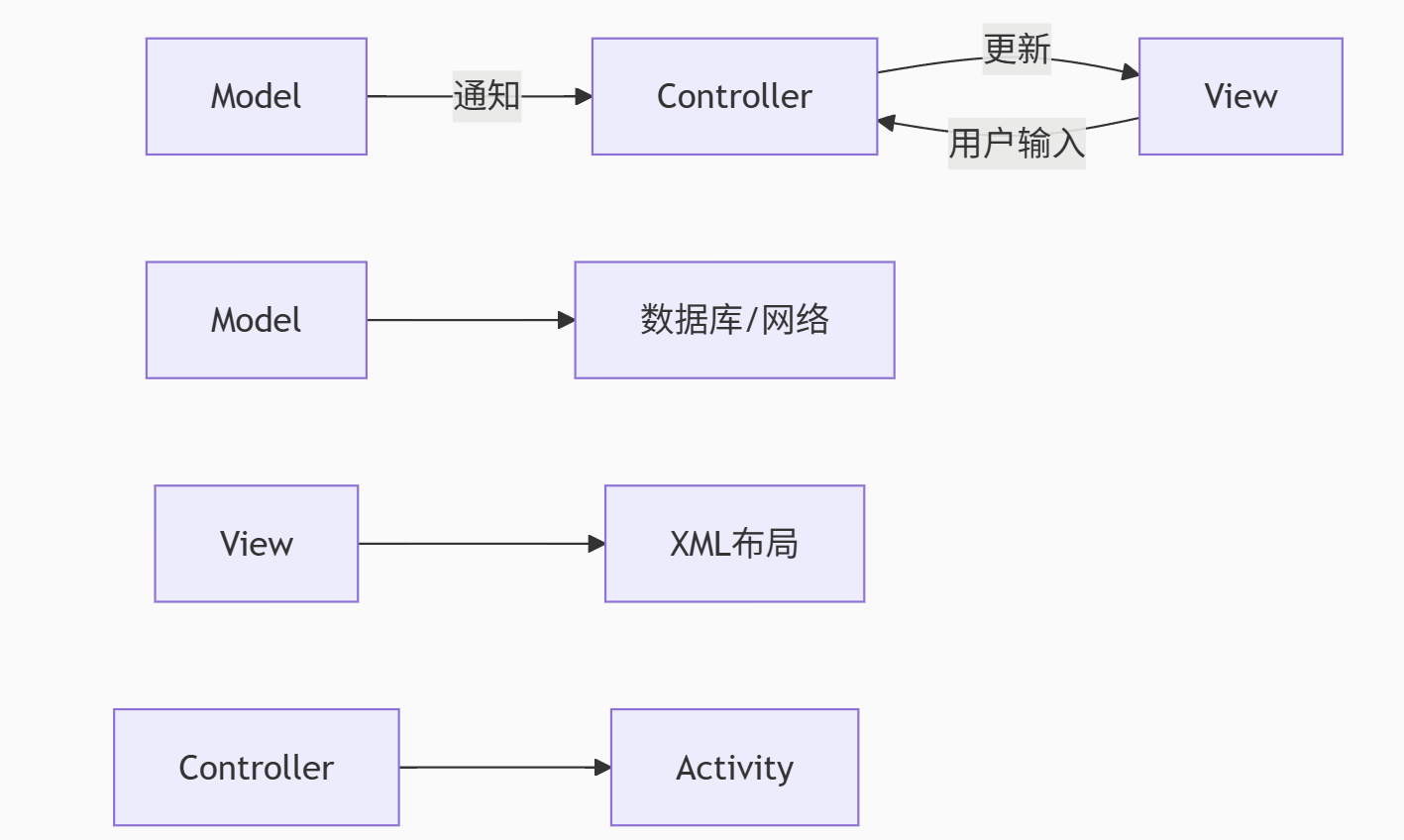
典型问题:
Activity同时承担Controller和View职责
业务逻辑与UI耦合
改进方案:引入MVP/MVVM
27. Java多线程核心参数
线程池参数详解:
ThreadPoolExecutor(int corePoolSize, // 常驻线程数(不会回收)int maximumPoolSize, // 最大线程数(临时线程)long keepAliveTime, // 临时线程存活时间TimeUnit unit, // 时间单位BlockingQueue<Runnable> workQueue, // 任务队列RejectedExecutionHandler handler // 拒绝策略 )
四种拒绝策略:
AbortPolicy(默认):抛出RejectedExecutionException
CallerRunsPolicy:用调用者线程执行
DiscardPolicy:静默丢弃
DiscardOldestPolicy:丢弃队列最老任务
28. SharedPreferences实践
安全写入方式:
// 最佳实践:apply()异步写入(无返回值)
val prefs = getSharedPreferences("user", MODE_PRIVATE)
prefs.edit().putString("name", "Alice").putInt("age", 25).apply()// 需要结果时使用commit()
val success = prefs.edit().clear().commit()数据存储格式:
基本类型:直接存储(int, float, boolean等)
复杂对象:
// 序列化为JSON存储 val gson = Gson() val userJson = gson.toJson(userObj) prefs.edit().putString("user", userJson).apply()// 读取时反序列化 val restored = gson.fromJson(prefs.getString("user", ""), User::class.java)
29. 自定义View开发要点
实现步骤:
继承View或其子类
处理自定义属性:
<!-- res/values/attrs.xml --> <declare-styleable name="MyView"><attr name="customColor" format="color" /> </declare-styleable>
重写关键方法:
override fun onMeasure(widthMeasureSpec: Int, heightMeasureSpec: Int) {// 计算视图大小setMeasuredDimension(calculatedWidth, calculatedHeight) }override fun onDraw(canvas: Canvas) {// 使用Paint进行绘制canvas.drawCircle(centerX, centerY, radius, paint) }
性能优化:
避免在onDraw中分配对象
使用canvas.clipRect()限制绘制区域
考虑硬件加速特性
30. OnClick事件本质
底层实现原理:
// 实际是View.OnClickListener接口
public interface OnClickListener {void onClick(View v);
}// 设置监听后的调用链
View.performClick() →
ListenerInfo.mOnClickListener.onClick() →
用户代码与onTouchEvent关系:
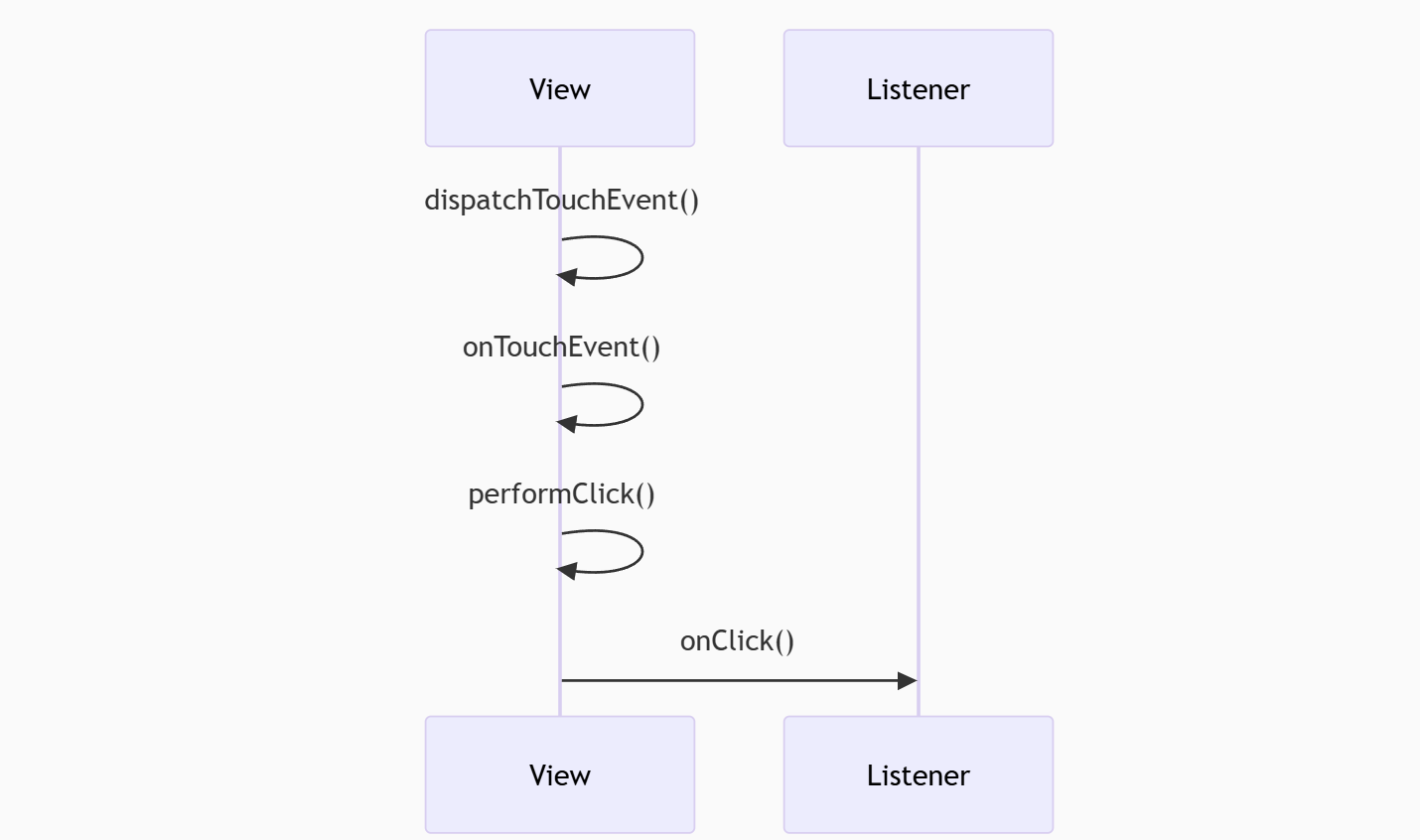
31. SpringCloud Alibaba核心部件
Nacos:服务注册与发现、配置中心
Sentinel:流量控制、熔断降级
Seata:分布式事务解决方案
RocketMQ:消息队列(可选组件)
Dubbo RPC:远程服务调用(可选)
32. 服务注册与发现过程
服务注册:

服务发现:
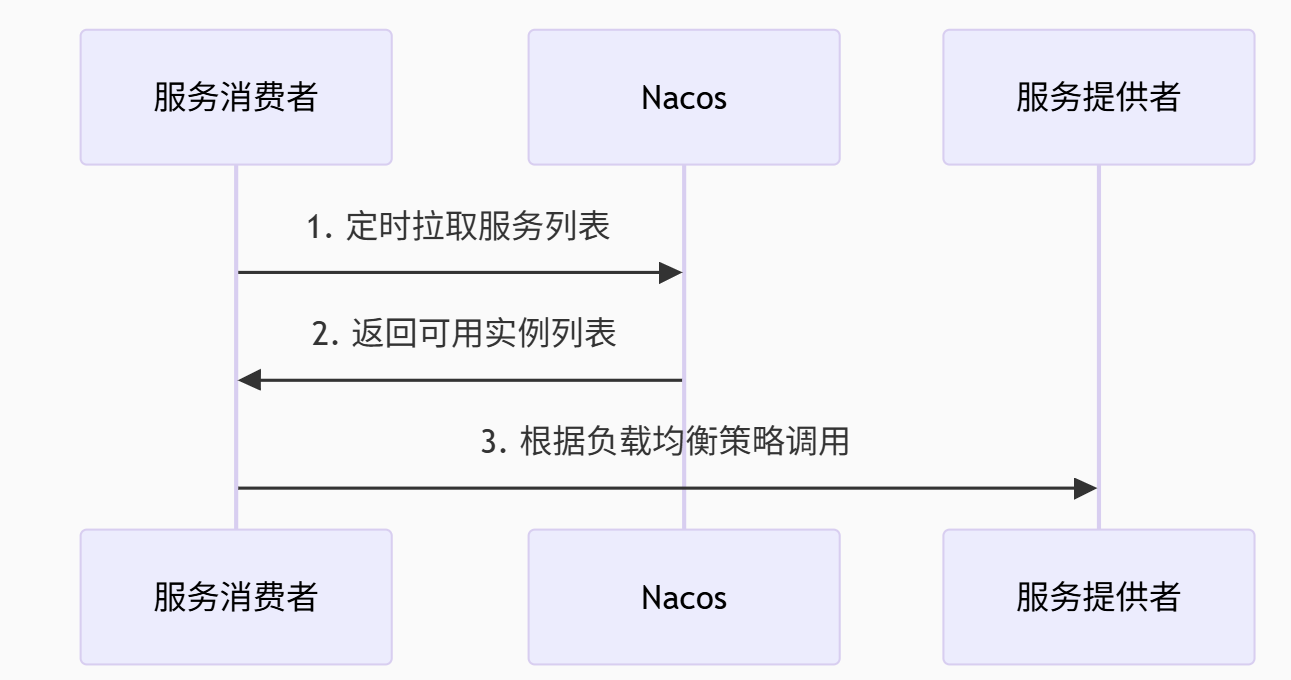
健康检查:Nacos通过心跳检测(15秒间隔)判断服务存活
33. 微服务负载均衡机制
客户端负载均衡(SpringCloud默认):
通过
Ribbon或LoadBalancer实现服务消费者本地维护服务列表并选择实例
服务端负载均衡:
如Nginx、API网关等代理流量
34. 负载均衡策略
| 策略 | 描述 | 适用场景 |
|---|---|---|
| 轮询(RoundRobin) | 依次分配请求 | 默认场景 |
| 随机(Random) | 随机选择实例 | 测试环境 |
| 加权响应时间(Weighted) | 根据响应时间动态调整权重 | 性能差异大的集群 |
| 最小并发(LeastActive) | 选择当前并发请求最少的实例 | 长任务处理 |
服务宕机处理流程:
Nacos心跳检测失败(15秒×3次)
标记实例为不健康
30秒后从注册列表删除
通知订阅该服务的消费者更新列表
35. 微服务高可用保障
多实例部署:单服务至少2个实例
集群化注册中心:Nacos集群(3节点以上)
熔断降级:Sentinel自动隔离故障服务
限流保护:防止突发流量打垮系统
异地多活:跨机房部署(如阿里云多可用区)
36. 服务雪崩与解决方案
雪崩效应:A服务故障→B服务重试→B资源耗尽→C服务受影响→连锁故障
解决方案:
熔断(Sentinel):
// 当失败率>50%时熔断10秒 @SentinelResource(fallback = "fallbackMethod")
降级:返回缓存数据或默认值
限流:控制QPS阈值
37. 熔断与限流过程
熔断流程:
统计时间窗口内(如1分钟)的失败率
达到阈值(如50%)触发熔断
所有请求直接走fallback逻辑
经过冷却期后尝试恢复
限流流程:
计数器统计当前QPS
超过阈值时拒绝请求(直接拒绝/排队等待)
支持集群限流(通过Redis实现)
38. 常见限流算法
| 算法 | 原理 | 特点 |
|---|---|---|
| 计数器 | 固定时间窗口计数 | 实现简单,有临界问题 |
| 滑动窗口 | 细分时间块统计 | 缓解临界问题 |
| 漏桶 | 恒定速率处理请求 | 平滑流量,无法应对突发 |
| 令牌桶 | 定期放入令牌,请求消耗令牌 | 允许突发流量(最常用) |
39. 令牌桶实现(Guava RateLimiter)
// 创建每秒2个令牌的桶
RateLimiter limiter = RateLimiter.create(2.0); void handleRequest() {if (limiter.tryAcquire()) { // 获取令牌processRequest();} else {throw new RateLimitException();}
}底层数据结构:基于SmoothBursty算法实现
40. 秒杀系统挑战
瞬时高并发:QPS可能达10万+
超卖问题:库存扣减的原子性
恶意请求:机器人刷单
系统瓶颈:数据库扛不住
解决方案:
分层过滤(限流→缓存→异步扣库存)
Redis原子操作(DECR+Lua脚本)
消息队列削峰填谷
41. 分布式事务实现
典型方案:
Seata AT模式(默认):
一阶段:提交本地事务
二阶段:异步提交/回滚
TCC模式(Try-Confirm-Cancel):
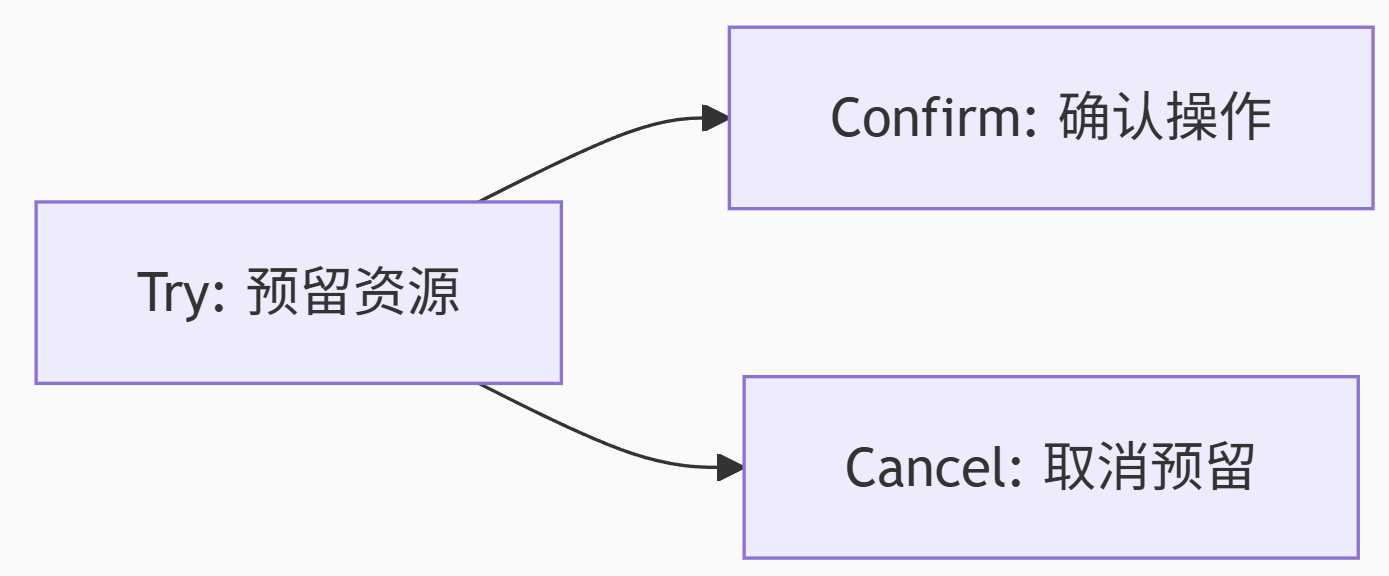
Saga模式:长事务补偿机制
42. 三阶段提交(3PC)详解
设计目标:解决2PC的阻塞问题,提高分布式事务的可用性
三个阶段:
CanCommit阶段(协调者→参与者)
协调者发送
CanCommit?请求,询问参与者是否具备提交条件参与者检查资源锁定、日志空间等,回复
Yes/No
PreCommit阶段(协调者决策)
全部Yes:协调者发送
PreCommit命令,参与者执行事务操作(写redo log)但不提交有No响应:协调者发送
Abort命令终止事务
DoCommit阶段(最终提交)
协调者发送
DoCommit,参与者完成提交若协调者未收到响应,超时后自动提交(相比2PC减少阻塞)
关键改进:
引入超时机制:参与者长时间未收到指令可自动提交(避免无限阻塞)
增加预提交阶段:降低资源锁定时间
43. 三阶段提交的缺点
性能问题:
比2PC多一轮网络通信(3次交互 vs 2次)
吞吐量下降约30%
脑裂风险:
网络分区时可能出现部分提交、部分回滚的不一致状态
示例:协调者与部分参与者失联,未收到
DoCommit的节点超时提交,其他节点回滚
实现复杂度高:
需处理超时、状态恢复等边界条件
对开发者不透明(Seata等框架已封装)
适用场景:
对可用性要求高于一致性的系统
跨多数据中心的分布式事务
44. 分布式事务开源框架
| 框架 | 模式 | 特点 | 适用场景 |
|---|---|---|---|
| Seata | AT/TCC/Saga | 阿里开源,社区活跃,支持多模式 | 通用微服务 |
| RocketMQ事务消息 | 最终一致性 | 基于消息队列,异步解耦 | 订单支付等异步流程 |
| Hmily | TCC | 金融级设计,强一致性 | 资金交易等高要求场景 |
| LCN | 代理模式 | 通过代理连接池管理事务 | 传统系统改造 |
选型建议:
快速接入:Seata AT模式(零代码侵入)
高性能:RocketMQ事务消息
强一致:TCC模式(需业务实现Try/Confirm/Cancel)
45. Kafka核心用途
实时数据管道:
日志收集(ELK架构)
指标监控(Prometheus + Kafka)
事件驱动架构:
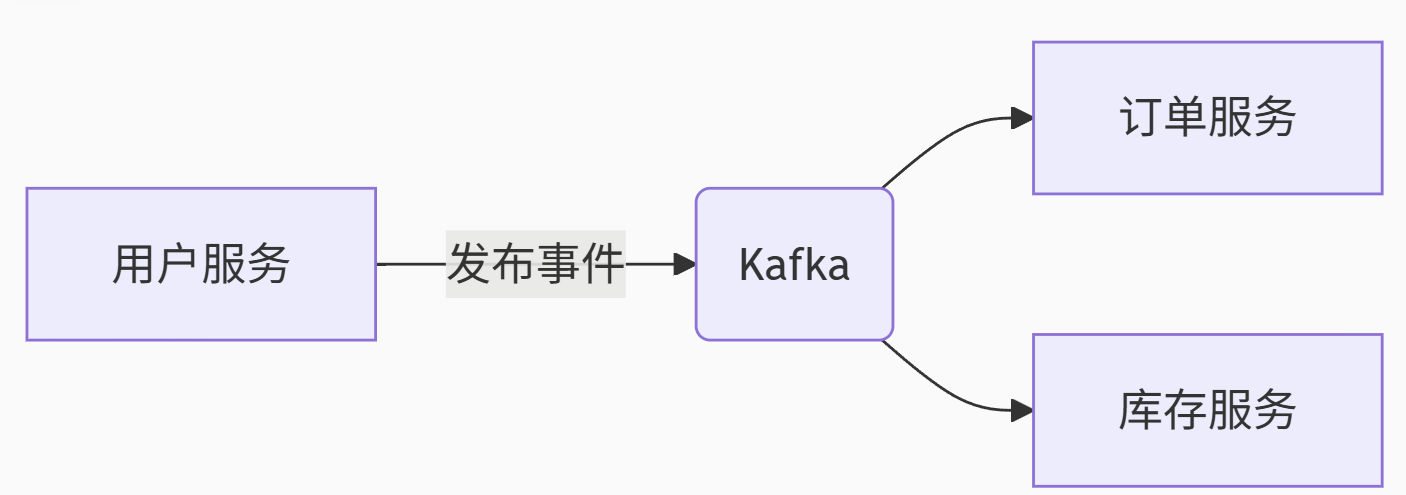
流处理基础:
与Flink/Spark Streaming集成
实现实时数据分析(如用户点击流)
典型场景:
电商订单状态变更广播
IoT设备数据汇聚
46. 传统消息队列对比
| 消息队列 | 协议 | 设计目标 |
|---|---|---|
| RabbitMQ | AMQP | 企业级消息路由 |
| ActiveMQ | JMS | 老牌Java生态支持 |
| RocketMQ | 自定义协议 | 金融级高可靠 |
共同特点:
支持队列/主题模式
提供ACK机制
需额外组件实现高吞吐(如RabbitMQ集群)
47. Kafka的优势
核心优势点:
吞吐量:单集群百万级QPS(通过分区横向扩展)
持久化:消息默认保存7天(可配置为永久)
消费者组:支持多组独立消费同一Topic
顺序性:同一分区内消息严格有序
技术实现:
零拷贝:减少内核态到用户态的数据复制
页缓存:直接读写OS缓存提升IO效率
批量发送:减少网络IO次数
48. Kafka事务支持
实现原理:
生产者事务:
// 启用事务 props.put("enable.idempotence", "true"); props.put("transactional.id", "tx-1"); producer.initTransactions(); // 事务操作 producer.beginTransaction(); producer.send(record1); producer.send(record2); producer.commitTransaction();消费-生产模式:
确保消费后处理的原子性
通过
isolation.level=read_committed避免脏读
限制:
事务主要针对生产者
消费端仍需处理幂等(如业务去重表)
49. RabbitMQ事务
基本用法:
channel.txSelect(); // 开启事务
try { channel.basicPublish(...); channel.txCommit();
} catch (Exception e) { channel.txRollback();
} 性能影响:
事务模式吞吐量下降约200倍
替代方案:
Confirm模式:异步确认消息落地
持久化+ACK:保障消息不丢失
50. RabbitMQ适用场景
复杂路由逻辑:
python
# 根据消息头路由到不同队列 channel.exchange_declare(exchange='logs', type='headers')
延迟队列:
通过
x-dead-letter-exchange+ TTL实现
优先级队列:
典型用例:
电商订单超时取消
客服系统消息优先级处理
51. 引入中间件的问题
常见挑战:
消息丢失:
Kafka:需配置
acks=all+ 副本同步RabbitMQ:开启持久化 + Confirm机制
重复消费:
解决方案:业务幂等设计(如唯一键约束)
运维复杂度:
监控指标:堆积数、消费延迟、错误率
工具:Kafka Eagle/RabbitMQ Management Plugin
架构建议:
消息中间件与业务解耦
建立消息治理规范(如命名规则、TTL设置)
52. 消息积压处理方案
应急步骤:
扩容消费者:
降级处理:
跳过非核心消息(如日志类数据)
批量消费提升效率
根本解决:
优化消费逻辑:
避免同步IO(如DB查询改为批量)
使用本地缓存
限流保护:
53. 死信队列(DLQ)机制
触发条件:
消息被拒绝(
basic.reject或basic.nack)且requeue=false消息TTL过期
队列达到最大长度
应用场景:
异常处理:人工检查失败消息
延迟队列:通过TTL+DLQ实现定时任务
审计跟踪:记录所有失败消息


 ls2k1000 openwrt)





安装及使用:多台电脑共用鼠标键盘)









——社区人脸识别出入管理系统设计与实现)
)