前言
在当今数字化时代,文字识别(OCR)技术已经渗透到我们生活和工作的方方面面,从扫描文档的自动排版到车牌识别、票据信息提取等,都离不开 OCR 技术的支持。而在众多 OCR 实现方案中,QtC++ 结合 tesseract 和 OpenCV 的组合因其高效性、灵活性和跨平台特性,成为许多开发者的首选。
本文将详细介绍如何在 QtC++ 环境下,调用 tesseractOCR 引擎,并搭配 OpenCV 进行图像处理,从而实现高效准确的文字识别功能。重点将围绕 tesseract 的导入方法、核心接口以及在整个 OCR 流程中的作用展开。
一、文字识别技术与工具链解析
1.1 文字识别(OCR)的应用场景与技术难点
文字识别,即 Optical Character Recognition,简称 OCR,是指通过电子设备(如扫描仪、相机等)将图像中的文字转换为可编辑的文本格式的技术。其应用场景极为广泛:如电子文档转换,车牌识别系统的自动识别和管理;金融的票据识别提取支票、发票上的关键信息;翻译类 APP 通过摄像头识别外文并实时翻译,极大地便利了人们的跨语言交流。
然而,OCR 技术的实现并非易事,面临着诸多技术难点。首先是图像质量的影响,如模糊、倾斜、光照不均、存在噪声等,都会导致文字识别准确率下降。其次,文字的字体、大小、颜色各异,以及可能存在的复杂背景,也会给识别带来挑战。此外,对于手写体文字,由于其个性化强、规范性差,识别难度更大,所以这也是引入OpenCV来搭配处理图像的主要原因。
1.2 tesseract 与 OpenCV 在 OCR 中的角色
tesseract 是一款开源的 OCR 引擎,由 Google 维护。它支持多种语言的文字识别,具有较高的识别准确率和良好的扩展性。tesseract 的核心作用是对经过预处理的图像进行分析,提取其中的文字信息并转换为文本。它可以处理不同字体、大小和格式的文字,并且能够通过训练来提高对特定场景文字的识别能力。
OpenCV 是一个开源的计算机视觉库,包含了大量的图像处理和计算机视觉算法。在 OCR 流程中,OpenCV 主要负责图像的预处理工作,如图像的灰度化、二值化、降噪、倾斜校正等。通过这些预处理操作,可以改善图像的质量,突出文字区域,为后续 tesseract 的文字识别创造良好的条件,从而提高整个 OCR 系统的识别准确率。
1.3 协同工作的基本流程
tesseract 和 OpenCV 协同实现文字识别的基本流程如下:
首先,通过文件操作或摄像头接口获取需要识别的图像文件或实时图像。然后,将获取到的图像传递给 OpenCV 进行预处理,包括灰度化处理(将彩色图像转换为黑白图像,减少计算量)、二值化处理(将图像转换为只有黑白两种颜色,使文字与背景分离)、降噪处理(去除图像中的噪声点,避免干扰识别)、倾斜校正(将倾斜的文字图像校正为水平状态,便于 tesseract 识别)等。
预处理完成后,将处理后的图像数据传递给 tesseractOCR 引擎。tesseract 对图像进行分析,识别出其中的文字,并将其转换为文本信息。最后,将 tesseract 返回的文本信息进行展示、存储或进一步处理,如通过 UI 界面显示识别结果,或将结果保存到文件中。
二、开发环境搭建
2.1 OpenCV 的安装与 Qt 配置
OpenCV 的安装步骤详情可参考之前的文章,在此就简单说下:
- 从 OpenCV 官网(https://opencv.org/)下载对应操作系统的 OpenCV 安装包,解压到指定目录。或者自行编译源码得到。
- 配置 OpenCV 的环境变量,将 OpenCV 的 bin 目录添加到系统的 PATH 环境变量中,这样在运行程序时,系统能够找到 OpenCV 的动态链接库。
- 在 Qt 项目中配置 OpenCV。打开 Qt Creator,创建一个新的 Qt 项目。然后在项目的.pro 文件中添加 OpenCV 的头文件路径和库文件路径。例如:
INCLUDEPATH += D:/opencv/build/include
LIBS += -LD:/opencv/build/x64/vc15/lib -lopencv_world455d.lib
其中,INCLUDEPATH 指定了 OpenCV 头文件的所在目录,LIBS 指定了 OpenCV 库文件的所在目录以及需要链接的库文件。需要根据实际的 OpenCV 安装路径和版本进行修改。
2.2 tesseract 的安装与 Qt 配置
tesseract 的安装和配置相对复杂一些,具体步骤如下:
- 下载 tesseract 安装包。可以从 tesseract 的官方 GitHub 仓库(https://github.com/tesseract-ocr/tesseract)下载源码自行编译,也可以下载别人编译好的库来用。对于 Windows 系统,注意别直接下载tesseract 的安装包,里边只有Dll没有lib静态库,也没有头文件,只能拿他的测试程序来试试效果,没法引入到代码中调用。
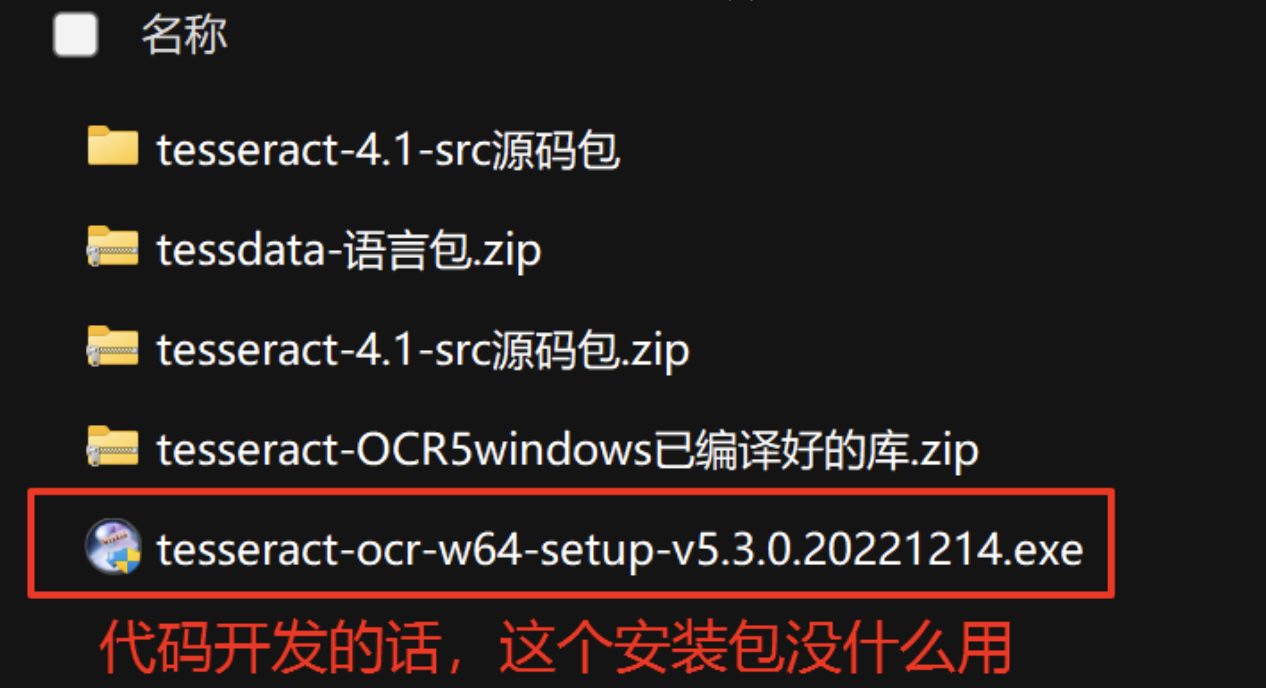
想要代码调用的话,要么就直接下载源码包,自己用CMake搭配VS进行编译,要么就找别人编译好的库(包含动态库,静态库,头文件)。 - 安装 tesseract 其实跟OpenCV一样,就是将压缩包或者编译好的文件放置到指定目录即可,然后将 tesseract 的安装目录添加到系统环境变量中。此外,还可以选择安装需要的语言数据包,如英文、中文等,这些语言数据包用于支持对应语言的文字识别。
- 在 Qt 项目中配置 tesseract。首先,需要将 tesseract 的头文件目录和库文件目录添加到 Qt 项目的.pro 文件中。例如:
INCLUDEPATH += C:/Program Files/Tesseract-OCR/include
LIBS += -LC:/Program Files/Tesseract-OCR/lib \-ltesseract51.lib
除了在.pro 文件中配置,还需要将 tesseract 的动态链接库(如 tesseract51.dll)复制到 Qt 项目的可执行文件所在目录,否则程序运行时会出现找不到库文件的错误。
三、tesseract 的深入解析
3.1 tesseract 的特点
tesseract 最初是由惠普公司开发的 OCR 引擎,后来被 Google 收购并开源。经过多年的发展和优化,tesseract 已经成为目前最受欢迎的开源 OCR 引擎之一。
tesseract 具有以下特点:
- 开源免费:可以自由使用和修改,无需支付任何费用,降低了开发成本。
多语言支持:支持超过 100 种语言的文字识别,包括中文、英文、日文、韩文等,满足不同场景的需求。 - 高识别准确率:在经过适当的图像预处理和训练后,tesseract 能够达到较高的识别准确率,尤其是对于印刷体文字。
- 跨平台性:可以在 Windows、Linux、Mac 等多个操作系统上运行。
- 可扩展性:支持用户自定义训练数据,以提高对特定字体、特定场景文字的识别能力。
3.2 tesseract 的核心功能与工作原理
tesseract 的核心功能是对图像中的文字进行识别并转换为文本。其工作原理主要包括以下几个步骤:
- 图像预处理:tesseract 首先会对输入的图像进行一些基本的预处理,如二值化、去噪等,但这部分功能相对简单,通常需要结合 OpenCV 进行更复杂的预处理。
- 文字区域检测:tesseract 会分析图像,找出其中可能包含文字的区域。
- 字符分割:将文字区域中的字符逐个分割出来,以便进行单独识别。
- 特征提取:对每个分割出来的字符提取特征,如形状、轮廓、笔画等。
- 字符识别:将提取到的字符特征与训练数据中的特征进行比对,从而识别出字符。
- 文本输出:将识别出的字符组合成文本,并输出给用户。
3.3 tesseract 的主要接口及使用说明
tesseract 提供了丰富的 C++ 接口,方便开发者进行调用。下面介绍一些主要的接口及其使用说明。
- tesseract::TessBaseAPI类:这是 tesseract 的核心类,提供了文字识别的主要功能。
构造函数:tesseract::TessBaseAPI(),创建一个 TessBaseAPI 对象。 - Init方法:用于初始化 tesseract 引擎。其原型为:
int Init(const char* datapath, const char* language, OcrEngineMode oem = OEM_DEFAULT);
其中,datapath是语言数据包所在的目录,如果为 NULL,则使用默认目录;language是要识别的语言,如 “eng” 表示英文,“chi_sim” 表示简体中文;oem是 OCR 引擎模式,默认使用 OEM_DEFAULT。
例如:
tesseract::TessBaseAPI tess;
if (tess.Init(NULL, "chi_sim+eng") != 0) {qDebug() << "无法初始化tesseract引擎!";return -1;
}
上述代码就是初始化 tesseract 引擎,并设置支持简体中文和英文识别。
- SetImage方法:设置要识别的图像。其原型有多种,常用的有:
void SetImage(const unsigned char* imagedata, int width, int height, int bytes_per_pixel, int bytes_per_line);
其中,imagedata是图像数据的指针;width和height是图像的宽度和高度;bytes_per_pixel是每个像素的字节数,如灰度图像为 1,RGB 图像为 3;bytes_per_line是每行图像的字节数。
调用方法如下(结合 OpenCV):
cv::Mat image = cv::imread("test.png");
if (image.empty()) {qDebug() << "无法读取图像!";return -1;
}
tess.SetImage(image.data, image.cols, image.rows, image.channels(), image.step);
代码中将 OpenCV 读取的图像设置为 tesseract 要识别的图像。
- GetUTF8Text方法:获取识别到的 UTF-8 编码的文本。其原型为:
char* GetUTF8Text();
调用如下:
char* outText = tess.GetUTF8Text();
qDebug() << "识别结果:" << QString(outText);
delete[] outText; // 注意释放内存
- End方法:释放 tesseract 引擎占用的资源。其函数原型为:
void End();
在程序结束时,调用该方法释放资源。
- SetPageSegMode方法:设置页面分割模式,用于指定 tesseract 如何分割图像中的文字区域。例如:
tess.SetPageSegMode(tesseract::PSM_AUTO); // 自动页面分割模式
- SetVariable方法:设置 tesseract 的一些变量参数,以调整识别效果。例如:
tess.SetVariable("tessedit_char_whitelist", "0123456789"); // 只识别数字
3.5 tesseract 在 OCR 流程中的作用
tesseract 在整个 OCR 流程中扮演着最核心的文字识别角色。在经过 OpenCV 的图像预处理后,图像的质量得到了改善,文字区域更加突出。此时,tesseract 接收预处理后的图像,通过其内部的一系列算法,对图像中的文字进行分析和识别。
它首先对图像进行文字区域检测,确定哪些部分包含文字;然后将文字区域分割成单个字符;接着提取每个字符的特征,并与训练数据中的特征进行比对,从而识别出字符;最后将识别出的字符组合成完整的文本并输出。
可以说,tesseract 是 OCR 系统的 “大脑”,负责将图像中的视觉信息转换为文本信息,是实现文字识别功能的关键环节。
四、OpenCV 图像处理在 OCR 中的应用
4.1 图像预处理的重要性
图像预处理是 OCR 流程中至关重要的一步,其质量直接影响后续文字识别的准确率。原始图像可能存在各种问题,如光照不均、噪声干扰、图像倾斜、文字与背景对比度低等,这些都会导致 tesseract 识别困难。通过图像预处理,可以解决这些问题,改善图像质量,使文字更加清晰、突出,从而提高 tesseract 的识别效率和准确率。
4.2 OpenCV 的主要图像处理功能
OpenCV 提供了丰富的图像处理函数,以下是在 OCR 中常用的一些功能:
- 图像读取与保存:cv::imread函数用于读取图像,cv::imwrite函数用于保存图像。
cv::Mat image = cv::imread("input.png"); // 读取图像
cv::imwrite("output.png", image); // 保存图像
- 灰度化处理:将彩色图像转换为灰度图像,减少图像的通道数,降低计算量。cv::cvtColor函数可以实现这一功能。
cv::Mat grayImage;
cv::cvtColor(image, grayImage, cv::COLOR_BGR2GRAY); // 将BGR彩色图像转换为灰度图像
- 二值化处理:将灰度图像转换为二值图像(只有黑白两种颜色),使文字与背景分离。cv::threshold函数是常用的二值化函数。
cv::Mat binaryImage;
cv::threshold(grayImage, binaryImage, 127, 255, cv::THRESH_BINARY); // 简单阈值二值化
其中,127 是阈值,大于阈值的像素被设置为 255(白色),小于等于阈值的像素被设置为 0(黑色)。
- 降噪处理:去除图像中的噪声点,常用的方法有中值滤波、高斯滤波等。
cv::Mat denoisedImage;
cv::medianBlur(binaryImage, denoisedImage, 3); // 中值滤波,3是滤波器大小
- 倾斜校正:对于倾斜的文字图像,需要进行校正,使其水平。可以通过霍夫变换检测图像中的线条,计算倾斜角度,然后进行旋转校正。
cv::Mat edges;
cv::Canny (denoisedImage, edges, 50, 150, 3); // 边缘检测
cv::Mat lines;
cv::HoughLinesP (edges, lines, 1, CV_PI / 180, 50, 50, 10); // 霍夫变换检测直线
double angle = 0;
int count = 0;
for (int i = 0; i < lines.rows; i++) {
cv::Vec4i l = lines.atcv::Vec4i(i);
double theta = atan2 (l [3] - l [1], l [2] - l [0]) * 180 / CV_PI;
if (fabs (theta) < 45 && fabs (theta) > 5) { // 过滤接近水平或垂直的线
angle += theta;
count++;
}
}
if (count > 0) {
angle /= count; // 计算平均倾斜角度
}
cv::Point2f center((denoisedImage.cols - 1) / 2.0f, (denoisedImage.rows - 1) / 2.0f);
cv::Mat rotMat = cv::getRotationMatrix2D(center, angle, 1.0);
cv::Mat rotatedImage;
cv::warpAffine(denoisedImage, rotatedImage, rotMat, denoisedImage.size(), cv::INTER_CUBIC, cv::BORDER_REPLICATE);
五、案例:构建一个简单的 OCR 应用程序
5.1 应用程序功能如下:
实战案例将构建一个简单的 OCR 应用程序,具有以下功能:
支持打开本地图像文件(如 png、jpg、bmp 等格式)。
对打开的图像进行预处理(灰度化、二值化、降噪、倾斜校正等)。
显示原始图像和预处理后的图像。
对预处理后的图像进行文字识别,并显示识别结果。
支持将识别结果保存为文本文件。
5.2 代码实现:
void MainWindow::on_btn1_clicked()
{// 1. 初始化 Tesseracttesseract::TessBaseAPI *ocrAPI = new tesseract::TessBaseAPI();// 语言包路径(Windows 为安装目录下的 tessdata,Linux 可省略路径)if (ocrAPI->Init(QString("D:/Tesseract_OCR/Tesseract_OCR5/tessdata").toStdString().c_str(), "chi_sim+eng")) {ui->textEdit->setText("初始化失败!检查语言包路径");return;}// 2. 加载图像(使用 OpenCV 读取,转为灰度图优化识别)QString fileName = QFileDialog::getOpenFileName(this,QString("文件对话框"),"/",QString("图片(*.jpg *.png);"));// 读取图像Mat img = imread(fileName.toStdString(), IMREAD_COLOR);if (img.empty()) {qDebug() << QString("无法读取图像!");return;}cv::cvtColor(img, img, cv::COLOR_BGR2GRAY); // 转为灰度图cv::threshold(img, img, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU); // 二值化// 3. 设置图像并识别ocrAPI->SetImage(img.data, img.cols, img.rows, 1, img.step); // 单通道(灰度图)ocrAPI->SetPageSegMode(tesseract::PSM_SINGLE_BLOCK); // 单块文本模式// 4. 获取识别结果char *outText = ocrAPI->GetUTF8Text();QString ocrResult(outText);ui->textEdit->setText(QString("识别结果:\n%1").arg(ocrResult));// 5. 释放资源delete[] outText;ocrAPI->End();delete ocrAPI;
}
以上即是使用tesseract 开源库实现OCR文字识别的一个基本应用。

![[Oracle] DUAL数据表](http://pic.xiahunao.cn/[Oracle] DUAL数据表)

8.5)







![[硬件电路-122]:模拟电路 - 信号处理电路 - 模拟电路与数字电路、各自的面临的难题对比?](http://pic.xiahunao.cn/[硬件电路-122]:模拟电路 - 信号处理电路 - 模拟电路与数字电路、各自的面临的难题对比?)





)

