一、AI模型评测目标
传统质量主要关注功能、性能、安全、兼容性等。
AI模型评测在此基础上,引入了全新的、更复杂的评估维度:
1.性能/准确性:这是基础,在一系列复杂的评测基准上评价个性能指标。
2.安全性:模型是否可能被用于恶意目的?是否会生成有害、违法或有毒的内容?是否容易受到数据投毒等攻击?
3.幻觉:对于大语言模型等生成式模型,它是否会"一本正经地胡说八道",捏造事实?
4.鲁棒性:模型在面对非理想输入时的表现。例如,输入有噪声声、有拼写错误、甚至是经过精心设计的对抗性攻击
时,模型的性能是否会急剧下降?
5.公平性与偏见:模型是否对不同群体(如性别、种族、地域)表现出一致的性能?是否存在歧视性行为?这是传
统质量很少触及的伦理维度。
6.可解释性:我们能理解模型为什么做出某个特定的决策吗?这对于金融、医疗等高风险领域至关重要。
二、评测的数据驱动
AI模型评测的核心是评估数据集。
1.评测基准:包含大量高质量、有代表性的标注数据,作为衡量模型性能的"标尺"。
2.人类参与的评估:对于创造性、主观性很强的任务(如文案生主成、对话质量),机器指标是不够的,由人类来打
分和判断。
3.对抗性测试:不再是测试常规场景,而是主动寻找模型的"盲区"和弱点,通过生成对抗样本来攻击模型。
三、评测周期
- 数据准备阶段:确保输入给模型的数据是高质量、多样化、无无偏见且安全的。数据质量评测、数据分布评测、数据安全评测,从源头上保证模型的质量。
- 预训练阶段:监控训练进程,验证模型是否在正确学习,并选择最佳的模型版本。检查点(Checkpoint)评测、超参数调优评测,也叫做边训边评,评测结果可以帮助工程师判断当前训练策略是否有效。
- 后训练阶段:让模型学会人类的偏好,变得更"有用、诚实、无言害"。奖励模型的构建与评测、对齐效果评测,这个阶段,评测本身就是训练的核心驱动力。
- 部署后:监控模型在真实世界中的表现,发现未知问题,并为下一代模型提供改进方向。
四、AI模型评测的关键技术
Benchmark
- Benchmark 是用于量化评估AI模型/系统性能的标准测试集与评价体系,其核心价值在于:
✅ 横向对比:不同模型在同一标准下的能力排序
✅ 性能标尺:衡量模型是否达到工业级可用标准
✅ 缺陷定位:识别模型在特定任务上的薄弱环节
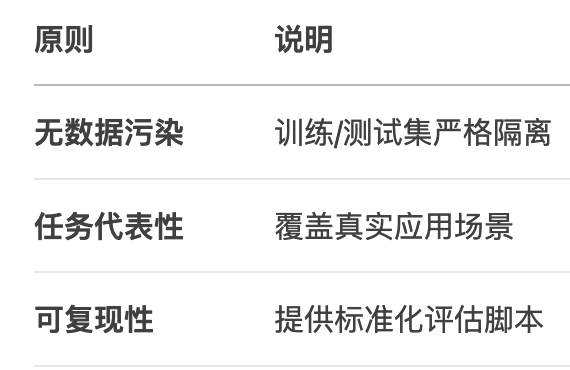
- Benchmark核心要素

- Benchmark设计原则
- 静态Benchmark VS 动态Benchmark
静态Benchmark:是筛选基础知识和基本逻辑能力的的有效工具
优点:
- 可复现性与公平性:为不同模型提供了一个公平比较的平台。
- 诊断短板:可以针对性地测试模型在某个特定能力(如数学推理、代码生成、知识问答)上的强弱。
- 推动基础研究:清晰的指标可以引导学术界和工业界在特定方向上攻关。
缺点:
- 过拟合:模型可能会"刷分",学会Benchmark的套路,而非真正的能力。
- 时效性差:知识和能力要求在快速变化,静态Benchmark很快会过时。
- 与应用脱节:高分不等于在实际应用中有用。
动态Benchmark:检验的是解决实际问题的综合能力
优点:
- 真实反映用户需求:直接与用户体感和商业价值挂钩。
- 捕捉"涌现"问题:能发现模型在受控环境中暴露不出的新问题、偏见和安全漏洞(Red Teaming就是一种形
- 式)。
- 驱动模型"反脆弱":充满噪声和变化的数据强迫模型变得更更鲁棒、更具适应性
缺点:
- 评估成本高、信噪比低:需要大量人工标注或复杂的A/B测记式系统,且用户反馈充满主观性和噪声。
- 可复现性差:动态数据流难以精确复现,使得模型间的"apples-to-aapples"比较变得困难。
- 指标定义模糊:如何量化"用户满意度"、"创造性"等指标本身就是难题。
如何应用:
在基础模型研发阶段:更关注静态Benchmark。这个阶段的目标是构建模型的通用基础能力。
我们需要标准化的尺子来衡量模型在数学、逻辑、知识等核心维度上是否取得了突破。没有这个基础,谈论应用是不切实际的。
在产品应用迭代阶段:更关注动态Benchmark。这个阶段的目标是解决用户的具体问题,创造价值。
A/B测试、用户留存率、满意度调查等指标是金标准。
- Benchmark分类体系
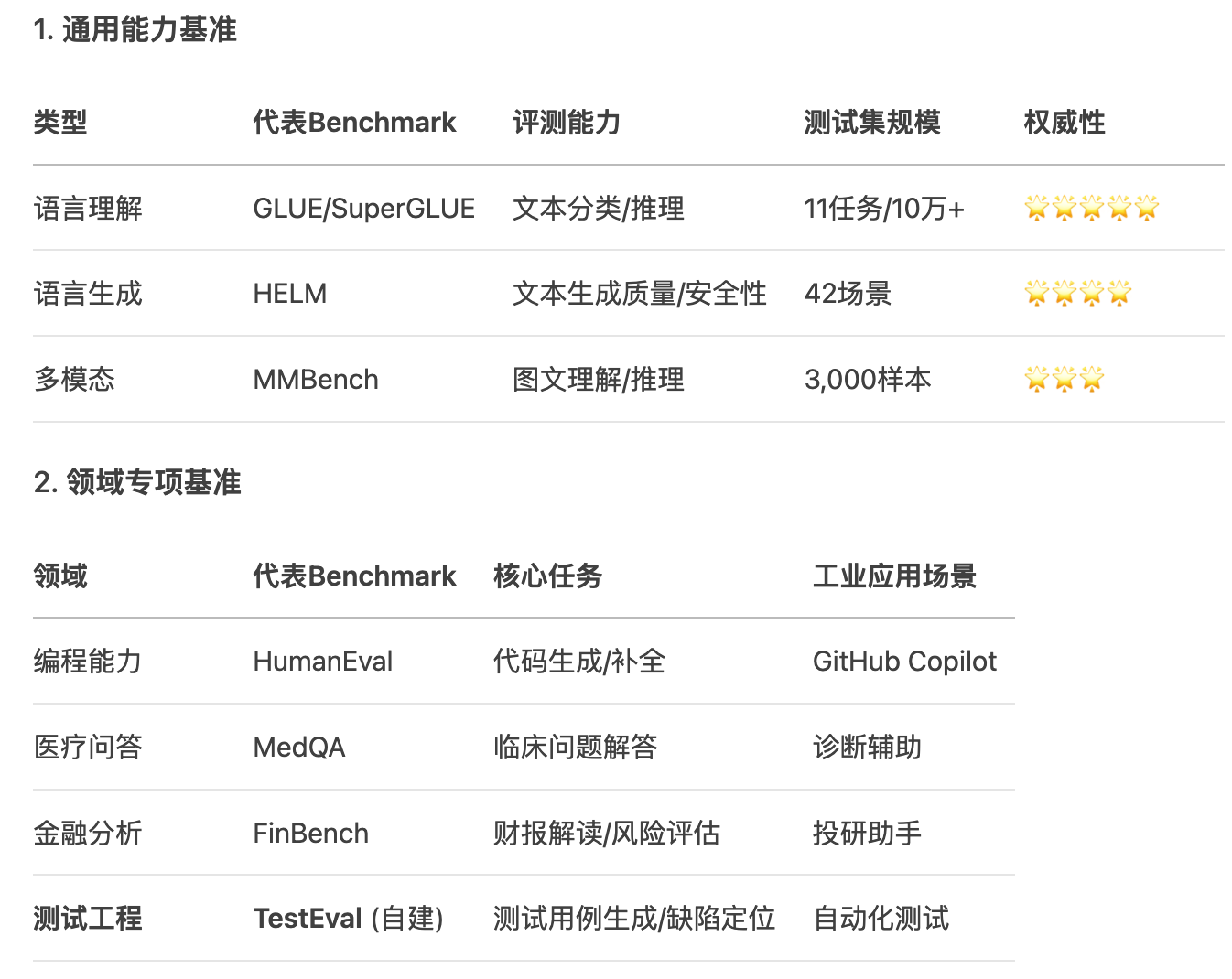

- 高质量的Benchmark
- 广度与深度:不仅覆盖多领域知识,更要考察多步推理、规划、创造等深层能力。
- 抗"应试"性:题目设计巧妙,难以通过搜索或简单的模式匹配来"作弊"。最好是过程性评估,而非仅仅看最终答案。例如,评估代码不仅看运行结果,也看代码质量和解题思路。
- 动态与演化性:Benchmark本身应该是一个"动态"的系系统。它可以定期从真实世界数据中采样新问题,或者由人类专家、甚至其他AI持续地生成新的问题。
- 诊断性与可解释性:不仅给出分数,更能揭示模型在哪些模块上存在缺陷。它应该能回答"模型为什么错",而不仅仅是"模型错了"。
- 对齐人类价值观:必须包含对安全性、公平性、偏见、伦理等方面面的严格测试。例如,Safety Benchmarks
- 衡量泛化而非记忆:确保评测数据在模型的训练集中是"零样本"或"少样本"的,真正考验其泛化能力。
- 交互式与环境感知:未来的Benchmark必然会走向了交互式,在一个模拟或真实的环境中,评估模型完成复杂任务的能力,而不仅是"一问一答"。Agent的评测就是这个方向的体现
LLM Judge
LLM Judge(大型语言模型即裁判)是一种利用微调后的大语言模型(LLM)作为“裁判员”,自动化评估其他AI模型输出的技术范式。它通过理解任务需求、分析候选答案,并输出评分、排序或改进建议,显著提升了模型评估的效率和覆盖范围。
- 核心框架
输入:用户问题 + 待评估模型的答案(可单答案、多答案对比或多模态数据)。
处理:LLM Judge 解析语义,结合预定义的评估维度(如帮助性、无害性、可靠性等)进行判断68。
输出:
评分(如1-5分)、排序(A > B > C)或选择(最佳答案)
详细理由(可选生成改进建议)
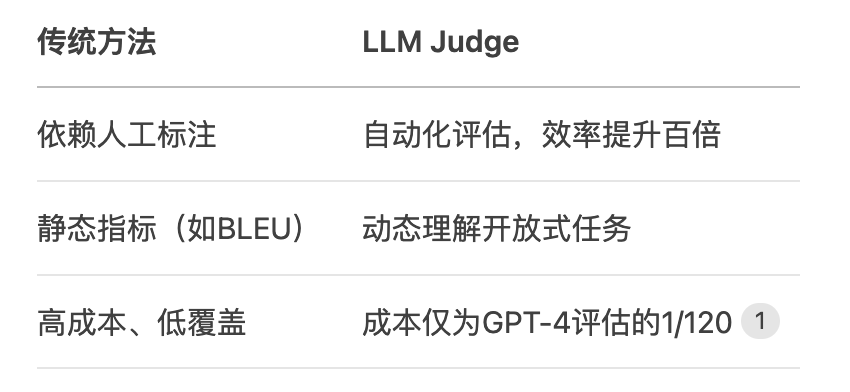
相比传统评估的优势
- 核心应用场景
模型能力横向评测
对比不同LLM在代码生成(HumanEval)、问答(MedQA)等任务的表现,输出排名报告。
生成内容质量审核
评估文本的无害性(如过滤暴力内容)、帮助性(客服回答有效性)、事实准确性(医疗建议可靠性)。
多模态与复杂任务
评判图文匹配度、RAG系统检索质量,甚至跨模态生成(草图→代码)的还原度。
训练过程优化
替代人工标注生成偏好数据,驱动RLHF(人类反馈强化学习)微调
- LLM Judge的偏见问题
位置偏见:这是最被广泛证实的一种偏见。在进行 A/B 对比评测时,LLM Judge 倾向于更喜欢排在第一个位置 (Answer A)的答案。即使将两个答案的顺序调换,它也可能仍然选择第一个,导致评估结果不一致和不准确。
长度偏见:LLM Judge 通常会偏爱更长、更详细、看起来更全面的回答,即使这些回答可能包含冗余信息、不相 关内容甚至是“幻觉”。这会鼓励被评估的模型生成冗长而非精炼的答案。
迎合偏见:LLM Judge 在评估其他模型的回答时,可能会偏爱那些风格、格式、观点与其自身相似的回答。它倾 向于奖励那些“看起来像自己”的答案,而不是真正更优的答案。这会导致评估的同质化,阻碍模型多样性的发 展。
格式偏见:对特定格式(如使用Markdown列表、加粗等)的偏好,即使内容质量相当,格式更规整的回答也更 容易获得高分。
- LLM Judge的缺陷
对提示词敏感:评估结果很大程度依赖于你如何设计提示词,提示词中一个关键词的改变就可能影响评估结果。 这使得设计一个公平、稳定、普适的评估提示词本身就是一个巨大的挑战。
评估标准无法完全对齐人类偏好:LLM Judge 的“价值观”和判断标准来自于其训练数据,这不一定完全符合真 实、多样化的人类偏好。过度依赖 LLM Judge 进行模型迭代,可能会导致模型“过拟合”到 Judge 的偏好上, 而不是真正的人类用户偏好。
谁来评估裁判的循环问题:如何确定一个 LLM Judge 本身是高质量的?我们通常需要用高质量的人类标注数据 来验证它。但这又回到了最初试图用 LLM Judge 来解决的问题——对人类标注的依赖。这形成了一个方法论上 的循环困境。
- 如何提高LLM Judge的准确性
✓ 优化提示工程
1. CoT: 要求模型在给出最终判断前,先逐步分析、推理
2. 精细化的评分标准 (Detailed Rubrics): 分解多个正交的、可量化的维度
3. 少样本提示
✓ 模型与数据层面的优化
1. 使用更强的基础模型
2. 在“困难样本”上进行微调
3. 多模型投票: 不依赖单一的裁判模型
✓ 人机协同(半自动评估):不追求用 LLM 完全取代人类,而是构建一个人机协同的评测系统
1. 分层审核: 使用 LLM Judge 进行大规模的、初步的筛选和打分,将模型打分处于“模糊地带” 的交由人类 专家进行精细复核
2. 持续校准: 定期用最新的“金标准”测试集来校准裁判模型


)
求解MaF1-MaF15及工程应用---盘式制动器设计,提供完整MATLAB代码)
 和 稀疏点云重建的详细步骤:)


)





)
:Tomcat高版本URL特殊字符限制问题解决方案(RFC 7230 RFC 3986))


)

