一、NoSQL 和 SQL 数据库的区别
1. 基本概念
SQL 数据库(关系型数据库) 代表产品:SQL Server, Oracle, MySQL (开源), PostgreSQL (开源)。 存储方式:结构化数据,逻辑上以二维表(行 & 列)形式组织数据。每列代表一种属性(字段),每行代表一个数据实体(记录)。
NoSQL 数据库(非关系型数据库) 代表产品:MongoDB, Redis。 存储方式:灵活多样,可以是 JSON 文档、键值对(哈希表)、宽列存储、图结构等,不强制要求固定的表结构。
2. 核心选择因素:ACID vs BASE
ACID (SQL 典型特性)
原子性 (Atomicity):事务内的操作要么全部成功,要么全部失败回滚。
一致性 (Consistency):事务执行前后,数据库都处于一致的状态(符合所有约束)。
隔离性 (Isolation):并发事务执行互不干扰。
持久性 (Durability):事务一旦提交,其结果永久保存。 适用场景:对数据一致性要求极高的应用,如银行转账(必须保证钱不会被扣两次或凭空消失)。
BASE (NoSQL 常用模型)
基本可用 (Basically Available):系统保证核心功能始终可用(可能响应慢或返回降级结果)。
软状态 (Soft state):系统状态可能随时间变化(即使无新输入),允许数据副本间存在暂时不一致。
最终一致性 (Eventual consistency):经过一段时间后,系统所有副本最终会达到一致状态。 适用场景:对实时强一致性要求不高,容忍短暂不一致的应用,如社交网络状态更新(用户A看到新状态比用户B晚几秒通常无碍)。
选择建议:
需要严格事务保证(如金融系统)→ 优先 SQL。
需要极高扩展性、灵活模式、处理海量非结构化/半结构化数据、容忍最终一致性(如内容推荐、用户画像)→ 优先 NoSQL。
3. 扩展性对比
NoSQL 扩展性优势 数据间通常无强关联关系,更容易实现水平扩展(添加更多服务器分担负载)。例如 Redis 原生支持主从复制、哨兵(Sentinel)高可用、分片集群(Cluster)模式。
SQL 扩展性挑战 数据间存在复杂的关联关系(如 JOIN),水平扩展困难,需要解决跨服务器 JOIN、分布式事务等复杂问题。
二、数据库设计基石:三大范式
范式是设计关系数据库时减少数据冗余、提高数据一致性的指导原则。
1. 第一范式 (1NF):原子性
要求:表中的每一列都是不可再分的最小数据单元(原子数据项)。
问题示例与修正:
学生ID 学生姓名 家庭信息 (地址, 电话) 学校信息 (校名, 年级) 101 YA33 北京朝阳, 123456 北大, 大三 问题:
家庭信息和学校信息列包含多个值,不满足原子性。 修正后 (满足 1NF):学生ID 学生姓名 家庭地址 家庭电话 学校名称 年级 101 YA33 北京朝阳 123456 北大 大三
2. 第二范式 (2NF):消除部分依赖
要求 (在 1NF 基础上):所有非主键字段必须完全依赖于整个候选键(不能只依赖部分主键)。主要针对联合主键表。
问题示例与修正: 订单明细表 (初始)
订单号 (PK1) 产品号 (PK2) 产品数量 产品折扣 产品价格 订单金额 订单时间 ORD1001 P001 2 0.9 100.00 180.00 2023-10-01 ORD1001 P002 1 1.0 50.00 180.00 2023-10-01 问题:
订单金额和订单时间只依赖于订单号,与产品号无关。它们只依赖了联合主键的一部分,违反了 2NF。 修正后 (满足 2NF): 拆分成两个表 表1:订单表订单号 (PK) 订单金额 订单时间 ORD1001 180.00 2023-10-01 表2:订单明细表
订单号 (FK) 产品号 (FK) 产品数量 产品折扣 产品价格 ORD1001 P001 2 0.9 100.00 ORD1001 P002 1 1.0 50.00
3. 第三范式 (3NF):消除传递依赖
要求 (在 2NF 基础上):所有非主键字段之间不能存在依赖关系,只能直接依赖于主键。
问题示例与修正: 学生表 (初始)
学号 (PK) 姓名 班级 班主任姓名 班主任性别 班主任年龄 2023001 YA33 CS1 张老师 男 35 问题:
班主任性别和班主任年龄直接依赖于班主任姓名,而不是直接依赖于主键学号(传递依赖),违反了 3NF。 修正后 (满足 3NF): 拆分成两个表 表1:学生表学号 (PK) 姓名 班级 班主任姓名 (FK) 2023001 YA33 CS1 张老师 表2:班主任表
班主任姓名 (PK) 性别 年龄 张老师 男 35
三、MySQL 核心操作精解
1. 联表查询 (JOIN)
连接类型决定了如何组合两个或多个表中的数据。
内连接 (
INNER JOIN) 仅返回两个表中匹配行的组合结果。SELECT e.name AS employee_name, d.name AS department_name FROM employees e INNER JOIN departments d ON e.department_id = d.id; -- 结果:只显示有明确部门的员工及其部门名。左外连接 (
LEFT JOIN/LEFT OUTER JOIN) 返回左表 (employees) 的所有行,即使右表 (departments) 中没有匹配的行。右表无匹配时显示NULL。SELECT e.name AS employee_name, d.name AS department_name FROM employees e LEFT JOIN departments d ON e.department_id = d.id; -- 结果:显示所有员工,包括没有分配部门的员工(其部门名为NULL)。右外连接 (
RIGHT JOIN/RIGHT OUTER JOIN) 返回右表 (departments) 的所有行,即使左表 (employees) 中没有匹配的行。左表无匹配时显示NULL。SELECT e.name AS employee_name, d.name AS department_name FROM employees e RIGHT JOIN departments d ON e.department_id = d.id; -- 结果:显示所有部门,包括没有员工的部门(员工名为NULL)。全外连接 (
FULL JOIN/FULL OUTER JOIN) 返回两个表的所有行,当某行在另一个表中无匹配时,对应列显示NULL。 MySQL 需用UNION模拟:SELECT e.name, d.name FROM employees e LEFT JOIN departments d ON e.department_id = d.id UNION SELECT e.name, d.name FROM employees e RIGHT JOIN departments d ON e.department_id = d.id; -- 结果:所有员工和所有部门的组合,无匹配的位置显示NULL。
2. 避免重复插入数据
确保数据唯一性的常用策略:
UNIQUE约束 (首选) 在表设计阶段定义唯一约束,数据库层面保证列值唯一。CREATE TABLE users (id INT PRIMARY KEY AUTO_INCREMENT,email VARCHAR(255) UNIQUE, -- 确保email唯一name VARCHAR(255) ); -- 尝试插入重复email会报错。INSERT ... ON DUPLICATE KEY UPDATE遇到唯一键冲突时执行更新操作。INSERT INTO users (email, name) VALUES ('ya33@example.com', 'YA33 Initial') ON DUPLICATE KEY UPDATE name = VALUES(name); -- 如果email已存在,则更新nameINSERT IGNORE忽略因唯一键冲突导致的插入错误(不报错,也不插入)。INSERT IGNORE INTO users (email, name) VALUES ('ya33@example.com', 'YA33 New'); -- 如果email已存在,此条插入被静默忽略。
选择建议:
需要绝对唯一性保证 →
UNIQUE约束。需要 "存在则更新" 逻辑 →
ON DUPLICATE KEY UPDATE。需要快速忽略重复插入 →
INSERT IGNORE(谨慎使用,可能掩盖其他错误)。
3. 字符串类型:CHAR vs VARCHAR
CHAR(N)固定长度:存储时总是占用
N个字符的空间(不足部分用空格填充)。优点:存取固定长度数据(如国家代码
'CN', 状态码'A')效率高。缺点:存储变长数据时浪费空间(如
CHAR(100)存'YA33')。
VARCHAR(N)可变长度:存储实际字符数 + 1~2字节长度信息。最大可存
N个字符。优点:存储变长数据(如用户名、评论)节省空间。
缺点:存取效率略低于
CHAR(需计算长度)。
VARCHAR(N)的N代表什么?N代表最大字符数,不是字节数!实际存储字节数 =字符数 * 字符集单个字符最大字节数+ 长度信息字节。VARCHAR(10)+ascii字符集:最多存 10 字符,最多占 10 + 1 = 11 字节。VARCHAR(10)+utf8mb4字符集 (最大4字节/字符):最多存 10 字符,最多占 10*4 + 2 = 42 字节。
4. INT(1) vs INT(10) 的真相
核心区别:
INT(1)和INT(10)中的数字 (1,10) 仅表示显示宽度 (Display Width),不改变存储范围或大小!所有INT类型固定占用 4 字节存储空间,范围都是-2147483648到2147483647(有符号) /0到4294967295(无符号)。唯一作用场景:配合
ZEROFILL属性使用,用于在数字显示时左侧补零至指定宽度。CREATE TABLE test_int (num1 INT(1) ZEROFILL, -- 显示宽度1num2 INT(10) ZEROFILL -- 显示宽度10 ); INSERT INTO test_int (num1, num2) VALUES (5, 5), (123, 123); SELECT * FROM test_int;结果:
num1 num2 5 0000000005 123 0000000123
5. TEXT 类型能存多大?
MySQL 提供了不同容量的 TEXT 类型应对不同需求:
| 类型 | 最大长度 (字节) | 近似容量 |
|---|---|---|
TINYTEXT | 255 | ~0.25KB |
TEXT | 65,535 | ~64KB |
MEDIUMTEXT | 16,777,215 | ~16MB |
LONGTEXT | 4,294,967,295 | ~4GB |
注意:实际可用容量略小于理论最大值,需预留少量字节存储长度信息。
6. IP 地址存储方案
方案 1:字符串存储 (
VARCHAR(15))CREATE TABLE ip_records (id INT AUTO_INCREMENT PRIMARY KEY,ip_address VARCHAR(15) -- 存储如 '192.168.1.1' ); INSERT INTO ip_records (ip_address) VALUES ('192.168.1.1');优点:直观,易读写,无需转换。
缺点:占用空间较大(最多 15 字节/IPv4),字符串比较效率较低,范围查询麻烦。
方案 2:整数存储 (
INT UNSIGNED)CREATE TABLE ip_records (id INT AUTO_INCREMENT PRIMARY KEY,ip_address INT UNSIGNED -- 存储转换后的整数 ); -- 插入时转换 (INET_ATON) INSERT INTO ip_records (ip_address) VALUES (INET_ATON('192.168.1.1')); -- 查询时转换回点分十进制 (INET_NTOA) SELECT id, INET_NTOA(ip_address) AS ip_address FROM ip_records;优点:存储高效(4 字节/IPv4),整数比较和范围查询 (
BETWEEN,<,>) 速度快。缺点:读写需转换函数 (
INET_ATON(),INET_NTOA()),不够直观。INET6_ATON()/INET6_NTOA()可用于 IPv6 (存储为VARBINARY(16))。
建议:对性能和存储空间有要求,且频繁进行 IP 比较/范围查询 → 整数存储。追求简单直观 → 字符串存储。
7. 外键约束 (Foreign Key)
作用:强制维护表与表之间的参照完整性,确保数据的一致性和有效性。防止出现 "孤儿记录"(如学生选了不存在的课程)。
语法示例:
CREATE TABLE students (student_id INT PRIMARY KEY,name VARCHAR(50),course_id INT, -- 外键列FOREIGN KEY (course_id) REFERENCES courses(course_id) -- 定义外键约束ON DELETE CASCADE -- 可选:当courses表中对应课程被删除时,自动删除此学生的选课记录ON UPDATE CASCADE -- 可选:当courses表中course_id更新时,自动更新此学生的course_id ); CREATE TABLE courses (course_id INT PRIMARY KEY,course_name VARCHAR(50) );关键点:
外键 (
course_id) 引用的是另一张表 (courses) 的主键 (course_id) 或唯一键。ON DELETE/ON UPDATE子句定义当被引用表中的记录被删除或更新时的动作(CASCADE,SET NULL,RESTRICT(默认阻止操作),NO ACTION)。
8. 子查询关键词:IN vs EXISTS
IN:检查左侧表达式的值是否存在于右侧子查询返回的结果列表中。
适合子查询结果集较小的情况。
示例:
-- 找出在德国或法国的客户 SELECT * FROM Customers WHERE Country IN ('Germany', 'France'); -- 找出至少下过一个订单的客户 (子查询) SELECT * FROM Customers WHERE CustomerID IN (SELECT DISTINCT CustomerID FROM Orders);
EXISTS:检查子查询是否至少返回一行结果。不关心具体返回什么数据,只关心是否存在。
通常与相关子查询 (子查询引用外部查询的列) 结合使用效率较高。
当子查询结果集可能很大时,
EXISTS的性能往往优于IN,因为它找到第一个匹配项即可停止。示例:
-- 找出至少下过一个订单的客户 (EXISTS版本) SELECT c.* FROM Customers c WHERE EXISTS (SELECT 1 FROM Orders oWHERE o.CustomerID = c.CustomerID -- 相关子查询 );
选择建议:
子查询结果集小且独立 →
IN(更直观)。子查询涉及外部查询列(相关子查询)或结果集可能很大 →
EXISTS(通常性能更好)。
9. 常用 MySQL 函数速查
| 类别 | 函数示例 | 说明 | 示例用法 |
|---|---|---|---|
| 字符串 | CONCAT(str1, str2, ...) | 连接字符串 | SELECT CONCAT('Hello', ' ', 'YA33'); |
LENGTH(str) | 返回字符串长度(字节数) | SELECT LENGTH('YA33'); | |
CHAR_LENGTH(str) | 返回字符串长度(字符数) | SELECT CHAR_LENGTH('你好'); | |
SUBSTRING(str, pos, len) | 截取子字符串 | SELECT SUBSTRING('MySQL', 3, 3); -- 'SQL' | |
REPLACE(str, from_str, to_str) | 字符串替换 | SELECT REPLACE('abc', 'b', 'YA33'); | |
| 数值 | ABS(num) | 绝对值 | SELECT ABS(-10); |
ROUND(num, decimals) | 四舍五入 | SELECT ROUND(3.14159, 2); -- 3.14 | |
POWER(num, exponent) | 幂运算 | SELECT POWER(2, 3); -- 8 | |
| 日期/时间 | NOW() | 当前日期和时间 | SELECT NOW(); |
CURDATE() | 当前日期 | SELECT CURDATE(); | |
CURTIME() | 当前时间 | SELECT CURTIME(); | |
DATE_ADD(date, INTERVAL expr unit) | 日期加减 | SELECT DATE_ADD(NOW(), INTERVAL 1 DAY); | |
| 聚合 | COUNT([DISTINCT] expr) | 计数 (非NULL / DISTINCT 值) | SELECT COUNT(*) FROM users; |
SUM([DISTINCT] expr) | 求和 | SELECT SUM(price) FROM orders; | |
AVG([DISTINCT] expr) | 平均值 | SELECT AVG(score) FROM grades; | |
MAX(expr) | 最大值 | SELECT MAX(age) FROM students; | |
MIN(expr) | 最小值 | SELECT MIN(price) FROM products; |
10. SQL 查询语句执行顺序
理解执行顺序是优化查询和排查问题的关键:
(1) FROM <left_table> -- 确定基础表
(3) <join_type> JOIN <right_table> -- 选择连接类型和表
(2) ON <join_condition> -- 应用连接条件 (注意: ON 在 JOIN 前逻辑计算)
(4) WHERE <where_condition> -- 过滤基础行
(5) GROUP BY <group_by_list> -- 分组
(6) AGG_FUNC( <column> or <expression> ) -- 计算聚合函数 (SUM, AVG, COUNT等)
(7) WITH {CUBE | ROLLUP} -- (可选) 生成超组/小计
(8) HAVING <having_condition> -- 过滤分组
(9) SELECT (10) DISTINCT <column>, ... -- 选择列,应用DISTINCT
(11) ORDER BY <order_by_list> -- 排序结果集
(12) LIMIT <limit_number>; -- 限制返回行数四、SQL 实战练习题
题 1:查询不存在 01 课程但存在 02 课程的学生成绩
表结构:
Student(stu_id, stu_name, ...)Score(stu_id, course_id, score)
方法 1:使用 LEFT JOIN + IS NULL
SELECT s.stu_id, s.stu_name, sc2.score AS score_02
FROM Student s
LEFT JOIN Score sc1 ON s.stu_id = sc1.stu_id AND sc1.course_id = '01' -- 尝试关联01成绩
LEFT JOIN Score sc2 ON s.stu_id = sc2.stu_id AND sc2.course_id = '02' -- 关联02成绩
WHERE sc1.course_id IS NULL -- 找不到01课程记录AND sc2.course_id IS NOT NULL; -- 找到了02课程记录方法 2:使用 NOT EXISTS + EXISTS
SELECT s.stu_id, s.stu_name, sc.score AS score_02
FROM Student s
JOIN Score sc ON s.stu_id = sc.stu_id AND sc.course_id = '02' -- 找到选了02的学生
WHERE NOT EXISTS (SELECT 1 FROM Score sc1WHERE sc1.stu_id = s.stu_idAND sc1.course_id = '01' -- 检查该生是否选了01
);题 2:查询总分排名在 5-10 名的学生 ID 及总分
表结构:student_score(stu_id, subject_id, score)
使用窗口函数 RANK() (推荐 MySQL 8.0+)
WITH StudentTotal AS (SELECTstu_id,SUM(score) AS total_scoreFROM student_scoreGROUP BY stu_id
)
SELECT stu_id, total_score
FROM (SELECTstu_id,total_score,RANK() OVER (ORDER BY total_score DESC) AS ranking -- 按总分降序排名FROM StudentTotal
) AS Ranked
WHERE ranking BETWEEN 5 AND 10; -- 筛选5-10名使用变量模拟 (兼容旧版 MySQL)
SET @rank = 0;
SELECT stu_id, total_score
FROM (SELECTstu_id,total_score,@rank := @rank + 1 AS rankingFROM (SELECTstu_id,SUM(score) AS total_scoreFROM student_scoreGROUP BY stu_idORDER BY total_score DESC) AS Totals
) AS Ranked
WHERE ranking BETWEEN 5 AND 10;题 3:查询某个班级下所有学生的选课情况
表结构:
students(student_id PK, student_name, class_id FK)course_selections(selection_id PK, student_id FK, course_name)classes(class_id PK, class_name)查询语句 (使用 JOIN):
SELECTs.student_id,s.student_name,c.class_name,cs.course_name
FROM students s
JOIN classes c ON s.class_id = c.class_id -- 关联班级
JOIN course_selections cs ON s.student_id = cs.student_id -- 关联选课
WHERE c.class_name = 'Class A'; -- 指定班级名称五、MySQL 进阶应用
1. 实现可重入锁 (基于数据库)
核心表 lock_table:
CREATE TABLE `lock_table` (`id` INT AUTO_INCREMENT PRIMARY KEY,`lock_name` VARCHAR(255) NOT NULL UNIQUE, -- 锁标识 (唯一)`holder_thread` VARCHAR(255) NOT NULL, -- 当前持有锁的线程标识`reentry_count` INT NOT NULL DEFAULT 0 -- 重入次数计数器
);加锁逻辑 (伪代码):
开启事务 (
BEGIN;)尝试锁定记录 (
SELECT ... FOR UPDATE):SELECT holder_thread, reentry_count FROM lock_table WHERE lock_name = 'my_lock' FOR UPDATE;判断查询结果:
无记录:插入新锁记录,
reentry_count=1INSERT INTO lock_table (lock_name, holder_thread, reentry_count) VALUES ('my_lock', 'thread_YA33', 1);有记录且持有者是当前线程 (
holder_thread = 'thread_YA33'):重入次数加 1UPDATE lock_table SET reentry_count = reentry_count + 1 WHERE lock_name = 'my_lock';有记录但持有者非当前线程:等待锁释放或超时报错。
提交事务 (
COMMIT;)
解锁逻辑 (伪代码):
开启事务 (
BEGIN;)尝试锁定记录 (
SELECT ... FOR UPDATE):SELECT holder_thread, reentry_count FROM lock_table WHERE lock_name = 'my_lock' FOR UPDATE;判断查询结果:
无记录:错误(尝试释放未持有的锁)。
有记录且持有者是当前线程 (
holder_thread = 'thread_YA33'):如果
reentry_count > 1:重入次数减 1UPDATE lock_table SET reentry_count = reentry_count - 1 WHERE lock_name = 'my_lock';如果
reentry_count = 1:删除锁记录(完全释放)DELETE FROM lock_table WHERE lock_name = 'my_lock';
提交事务 (
COMMIT;)
关键点:
依赖事务 (
BEGIN/COMMIT) 和行锁 (SELECT ... FOR UPDATE) 保证操作的原子性。lock_name唯一索引确保锁标识唯一。holder_thread标识持有线程,实现锁的归属。reentry_count计数器实现可重入性。
2. SQL 请求执行过程剖析
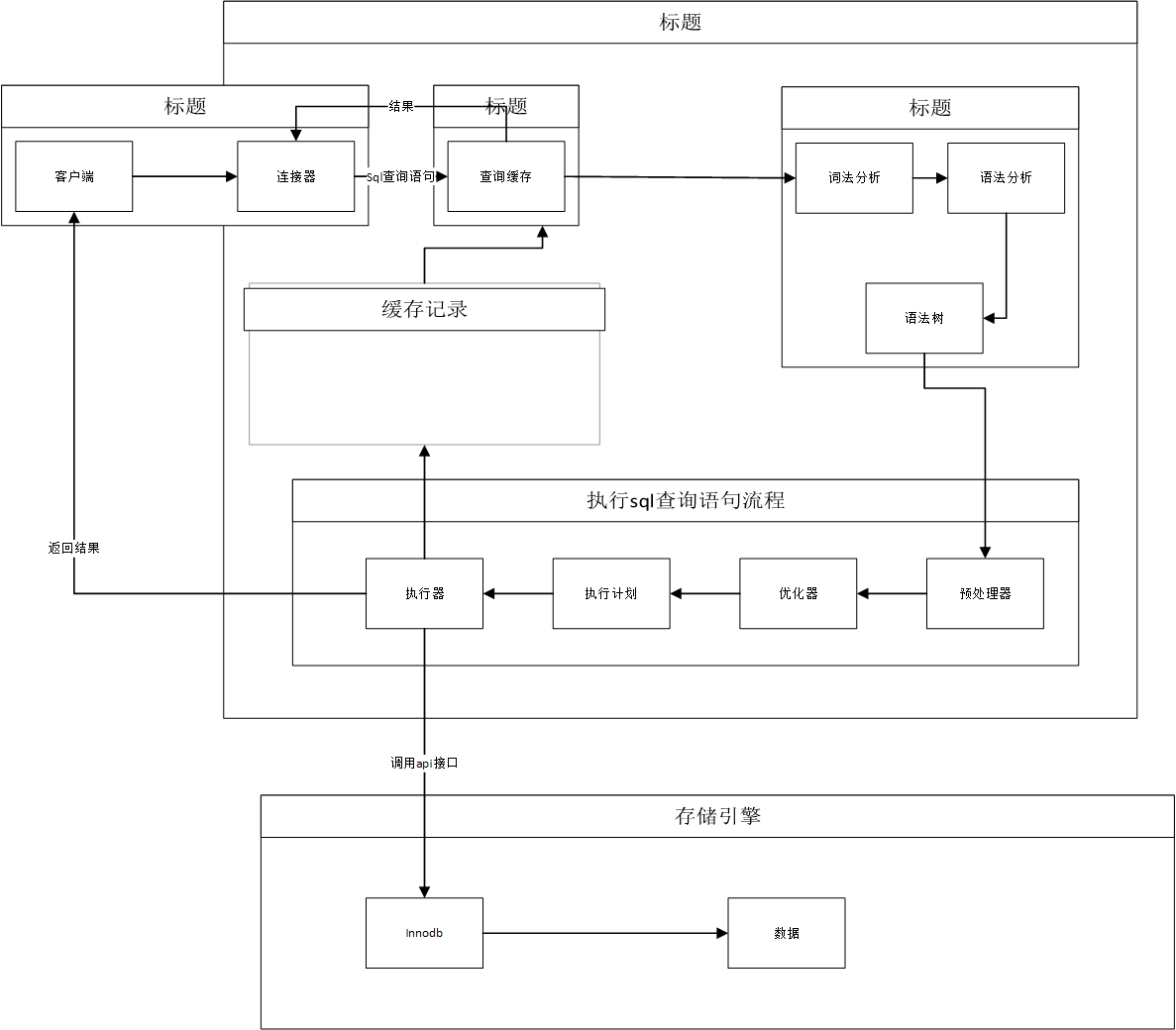
连接器:
管理客户端连接(TCP 握手、认证用户
YA33)。建立连接,维持连接状态。
查询缓存 (MySQL 8.0 已移除):
(历史版本) 检查是否缓存了完全相同的 SQL 及其结果。命中则直接返回。
解析器:
词法分析:拆分 SQL 字符串为有意义的单词(Token)。
语法分析:根据语法规则构建 语法树,检查 SQL 结构是否正确。
执行器:
预处理器:
检查表和列是否存在。
权限校验。
将
SELECT *扩展为所有列名。
优化器:
分析可能的执行计划(使用哪个索引?表连接顺序?)。
基于成本模型 (I/O, CPU, 内存估算) 选择成本最低的执行计划。
执行引擎:
调用存储引擎接口 (
InnoDB,MyISAM等)。根据优化器选择的计划,逐步读取/处理数据。
将最终结果返回给客户端。
六、MySQL 存储引擎深度解析
1. 主流引擎概览
InnoDB(默认引擎):核心特性:支持 ACID 事务、行级锁、外键约束、MVCC (多版本并发控制)、崩溃恢复 (Redo Log)。
适用场景:需要事务、高并发读写、数据一致性要求高的 OLTP 系统。
MyISAM:核心特性:表级锁、全文索引 (老版本)、高速读 (尤其 COUNT(*))、压缩表。不支持事务、行锁、崩溃恢复、外键。
适用场景:只读或读多写少、对事务要求低、需要全文索引 (MySQL 5.6 前) 的场景。数据仓库查询。
Memory(原HEAP):核心特性:数据存储在内存中,速度极快。表级锁。服务器重启数据丢失。支持哈希索引。
适用场景:临时表、缓存、会话存储、快速查找表。数据量小、可丢失的场景。
2. 为什么 InnoDB 是默认引擎?
MySQL 5.5.5 之后,InnoDB 成为默认存储引擎,主要原因包括:
事务支持 (ACID):现代应用对数据一致性和可靠性的基本要求。
行级锁:大幅提升并发读写性能,减少锁争用,尤其适合 OLTP 场景。
崩溃恢复 (Crash-Safe):通过 Redo Log (重做日志) 机制,保证数据库异常关闭后数据不丢失,能恢复到崩溃前的状态。
MyISAM损坏后修复困难且可能丢失数据。外键支持:保证关联数据的完整性。
更好的缓冲池管理:更高效地利用内存缓存数据和索引。
3. InnoDB vs MyISAM 核心区别总结
| 特性 | InnoDB | MyISAM |
|---|---|---|
| 事务 | ✅ 支持 | ❌ 不支持 |
| 锁粒度 | 🔒 行级锁 (默认,支持表锁) | 🔒 表级锁 |
| 外键 | ✅ 支持 | ❌ 不支持 |
| 崩溃恢复 | ✅ 支持 (Redo Log) | ❌ 不支持 (易损坏需修复) |
| MVCC | ✅ 支持 | ❌ 不支持 |
| 索引结构 | 🌳 聚簇索引:数据文件即主键索引叶子节点 | 📂 非聚簇索引:索引与数据文件分离 |
COUNT(*) 效率 | ⏳ 需扫描表或二级索引 (无缓存) | ⚡ 变量存储精确行数 (非常快) |
| 全文索引 | ✅ MySQL 5.6+ 支持 | ✅ 支持 (老版本主力) |
| 压缩 | ✅ 表压缩 | ✅ 压缩表 (只读) |
| 存储文件 | .frm (表结构) + .ibd (数据+索引) | .frm (表结构) + .MYD (数据) + .MYI (索引) |
关键点详解:
聚簇索引 (InnoDB):
表数据按主键顺序物理存储。
主键查询极快(直接定位数据页)。
辅助索引叶子节点存储主键值,查询需回表 (根据主键值去主键索引查数据)。
建议使用自增整型做主键 (避免页分裂)。
非聚簇索引 (MyISAM):
主键索引和辅助索引结构相同,都是 B-Tree。
索引叶子节点存储的是数据行的物理地址 (指针)。
通过索引查到地址后,需根据地址去
.MYD文件读取数据行。
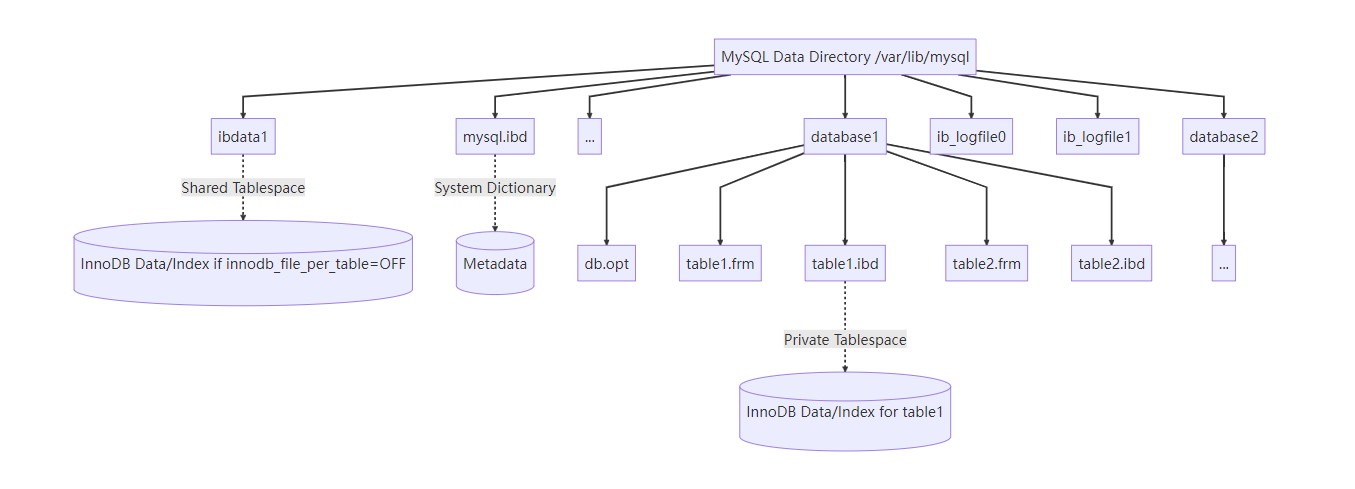
4. 数据库文件体系
每个 database (数据库) 在 MySQL 数据目录 (/var/lib/mysql/) 下对应一个同名文件夹。文件夹内包含该库的表文件。
示例 (my_test 库下的 t_order 表):
/var/lib/mysql/my_test/ ├── db.opt # 存储数据库的默认字符集和排序规则 ├── t_order.frm # 存储表 `t_order` 的**结构定义** (元数据) └── t_order.ibd # 存储表 `t_order` 的**数据 + 索引** (InnoDB 独占表空间文件)
核心文件说明:
.frm文件 (Frame):存储表结构定义 (CREATE TABLE 语句的信息)。
每个表对应一个
.frm文件。MySQL 8.0 开始,表结构信息移入系统数据字典 (存储在
mysql.ibd中),不再需要单独的.frm文件。
.ibd文件 (InnoDB Data):存储 InnoDB 表的数据行和索引 (当
innodb_file_per_table=ON时)。此设置默认开启 (MySQL 5.6.6+),强烈推荐。优点:表删除可回收空间、支持表传输、方便备份恢复。
ibdata*文件 (共享表空间):当
innodb_file_per_table=OFF时,所有 InnoDB 表的数据和索引都存储在共享表空间文件 (如ibdata1) 中。不推荐使用,管理不便,空间无法自动回收。
ib_logfile0,ib_logfile1(Redo Log Files):InnoDB 重做日志文件 (通常是 2 个循环写入的文件)。
用于保证事务的持久性 (Durability) 和崩溃恢复。
ib_buffer_pool:存储 InnoDB 缓冲池 (Buffer Pool) 在关闭时的状态快照 (MySQL 5.6+),用于加速重启后的预热。
mysql.ibd(MySQL 8.0+):存储 MySQL 系统数据字典 (包含数据库、表、列、索引、用户、权限等信息),取代了之前的
.frm,PAR,TRN,TRG等文件。



)








)



——枚举类)


