如果你用Pytorch训练的模型那么可以参考我的步骤,使用的是Tensorflow的话参考官方文档即可,但流程都是一样的,每一步我都会提到部分操作细节及注意事项
官方教程
要详细学习的话tflite-micro里的微控制器章节下都详细看(页面左侧目录最下方),要先尝试跑通就直接跳到下一节内容跟着做,

一切的开始,环境踩坑提示(已经有模型不需要训练可跳过)
如果是自己用搭建模型结构从0训练,按正常模型构建、训练流程即可,要用预训练的模型的话可以参考官方步骤,本笔记仅为个人探索过程的记录不详细展开模型训练过程了,最后要导出的模型为文件为.tflite格式的,建议不要用太高版本的tensorflow,详情看tensorflow官方的tflite micor相关说明,关于版本可能会踩非常多坑,如果用pytorch的话会用到onnx进行转化,也有版本的坑,所以友情提示把以下需要确认对应版本在官方文档里找到,新建一个虚拟环境,然后先初步过一遍确定没有版本冲突再开始自己的模型代码开发,否则环境的坑会导致不停重来,一定要新建一个虚拟环境,不要偷懒用自己已有的环境!!!!
- GPU驱动
- CUDA版本
- pytorch/tensorflow(二选一,推荐tensorflow)和python版本
- Numpy版本
- onnx、onnxtf、onnxruntime版本(pytorch)
我用的是服务器,CUDA11.2,python3.9,主Pytorch ,本地的ESP-IDF版本是5.4.1,这里贴一个我的环境版本(太长了放在另一篇笔记里),
模型训练注意事项
官方文档里有这样的提示

使用预训练模型
如果要用预训练模型的话一定要参考tflite-micro官方文档确定可支持的模型有哪些,并不是在PC上能跑通就可以的,还要考虑在ESP32上的部署。
自己构建模型从0训练
不管是Pytorch还是tensorflow框架,仅使用tflite-micro支持的算子,否则就要自己添加自定义算子,我碰到了这个坑感兴趣可以看我的这篇笔记【踩坑随笔】TensorFlowLite_ESP32库中不包含REDUCE_PROD算子,手动移植
预处理注意事项
一定要确定模型的输入输出以及图片的预处理,我的模型输入为[1,3,64,64], 转化部署模型考虑采用uint8量化,所以在训练环节的预处理我直接不做0~1的归一化,而是采用[0,255],以下是我的预处理代码,重点是最后的归一化操作用transforms.Lambda(lambda x: x * 255)而不用Normalize
def get_transforms():train_transform = transforms.Compose([transforms.Resize((72, 72)),transforms.RandomCrop(64),transforms.RandomHorizontalFlip(0.5),transforms.RandomRotation(10),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),transforms.ToTensor(),# transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])transforms.Lambda(lambda x: x * 255) # 转为 [0,255]])val_transform = transforms.Compose([transforms.Resize((64, 64)),transforms.ToTensor(),# transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])transforms.Lambda(lambda x: x * 255)])return train_transform, val_transform模型导出转换
Tensorflow模型可以直接转存tflite格式,前面提到我采用的是Pytorch导出的是pth格式,所以走pth–>onnx->tensorflow模型–>tflite模型的路线,这个思路是ai生成的,可能会有冗余,感觉饶了很大的弯子,等我探索完有更好的方式再来更新
pth转tflite(INT8量化)
参数里的路径只是示例,改成你自己的对应文件路径即可,model_path是训练完保存好的pth格式的模型,data_path是数据集的文件夹,output_dir是转换完保存tflite格式的模型的文件夹,重点注意converter.inference_input_type = tf.uint8,这决定了部署模型的输入
def pytorch_to_tflite(model_path="./models/best_model.pth", data_path="./datasets49",output_dir="./models/tfmodels"):"""将PyTorch模型转换为TensorFlow Lite模型"""print("Starting model conversion process...")# 1. 加载PyTorch模型print("Loading PyTorch model...")checkpoint = torch.load(model_path, map_location='cpu')num_classes = checkpoint['num_classes']model = ESPNetV2(num_classes=num_classes)model.load_state_dict(checkpoint['model_state_dict'])model.eval()print(f"Model loaded with {num_classes} classes")# 2. 准备校准数据print("Preparing calibration data...")_, val_transform = get_transforms()val_dataset = CustomImageDataset(data_path, transform=val_transform, train=False)val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False)# 3. 导出为ONNXprint("Exporting to ONNX...")dummy_input = torch.randn(1, 3, 64, 64)onnx_path = os.path.join(output_dir, "model.onnx")torch.onnx.export(model,dummy_input,onnx_path,export_params=True,opset_version=11,do_constant_folding=True,input_names=['input'],output_names=['output'],dynamic_axes={'input': {0: 'batch_size'},'output': {0: 'batch_size'}})print(f"ONNX model saved to: {onnx_path}")# 4. 使用 onnx-tf 转换为 TensorFlow SavedModelprint("Converting ONNX to TensorFlow using onnx-tf...")try:subprocess.check_call([sys.executable, "-m", "pip", "install", "onnx-tf"])from onnx_tf.backend import prepareexcept Exception as e:print("Failed to import or install onnx-tf:", e)returnonnx_model = onnx.load(onnx_path)tf_rep = prepare(onnx_model)tf_model_dir = output_dirtf_rep.export_graph(tf_model_dir)print(f"TensorFlow SavedModel saved to: {tf_model_dir}")# 5. 创建校准数据生成器def representative_dataset():for i, (data, _) in enumerate(val_loader):if i >= 100: # 只使用100个样本进行校准breakyield [data.numpy().astype(np.float32)]# 6. 转换为TensorFlow Lite (INT8量化)print("Converting to TensorFlow Lite with INT8 quantization...")converter = tf.lite.TFLiteConverter.from_saved_model(tf_model_dir)converter.optimizations = [tf.lite.Optimize.DEFAULT]converter.representative_dataset = representative_datasetconverter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] # 确保形状操作兼容converter.inference_input_type = tf.uint8converter.inference_output_type = tf.uint8 tflite_model = converter.convert()# 保存TFLite模型tflite_path = os.path.join(output_dir, "model_quantized.tflite")with open(tflite_path, 'wb') as f:f.write(tflite_model)print(f"Quantized TFLite model saved to: {tflite_path}")print(f"Model size: {len(tflite_model) / 1024:.2f} KB")# # 评估转换后的模型# print("\nEvaluating converted model...")# evaluate_tflite_model(tflite_path, data_path)return tflite_path提取tflite模型的量化参数和算子
这一步只是为了方便做验证,如果对模型结构和转化过程非常确定的话可以不提取,具体代码看【浅学】从tflite模型提取算子和量化参数,会提取到以下信息,主要用来在部署中做验证,包括输入输出格式、量化参数和采用的算子
{"input": {"name": "serving_default_input:0","shape": [1,3,64,64],"dtype": "<class 'numpy.uint8'>","scale": 1.0,"zero_point": 0},"output": {"name": "PartitionedCall:0","shape": [1,51],"dtype": "<class 'numpy.uint8'>","scale": 0.060637399554252625,"zero_point": 150}
}
inline tflite::MicroMutableOpResolver<8> CreateModelResolver() {tflite::MicroMutableOpResolver<8> resolver;// 注册 CONV_2Dmicro_op_resolver.AddConv2d();// 注册 DEPTHWISE_CONV_2Dmicro_op_resolver.AddDepthwiseConv2d();// 注册 FULLY_CONNECTEDmicro_op_resolver.AddFullyConnected();// 注册 MEANmicro_op_resolver.AddMean();// 注册 PADmicro_op_resolver.AddPad();// 注册 QUANTIZEmicro_op_resolver.AddQuantize();// 注册 RESHAPEmicro_op_resolver.AddReshape();// 注册 TRANSPOSEmicro_op_resolver.AddTranspose();return resolver;
}
上面提取生成的这个算子文件不能直接用哈,写法不对,但是算子是对应的,需要对应上tflite-micro支持的算子,只是大小写不一样的话实际是同一个算子部署的代码用对的写法就行,但是如果提取到的算子在tflite-micro里没有就要自定义了,参考tflite官方文档
tflite转C数组
模型训练好导出.tflite格式后,可以通过执行以下命令转换成C数组,这个在Windows系统上直接用Git bash切换到model.tflite文件夹下,然后执行这个命令(或者安装了git配有git环境直接在终端里也可以)要注意文件路径不能有空格和中文,然后我们就能得到一个model.cc文件,里面包含一个数组和一个表示数组大小的常量,确认一下数组大小,如果明显比例程的大很多可能会导致Flash不够用
$ xxd -i model.tflite > model.cc
图片格式转换
准备好你要进行图像分类的10张图片重命名为image0~image9,自己记录好这10张图片对应的类别方便你验证最终推理结果对不对,然后进行转换,转换成二进制文件,一定要注意在转换过程就做好了预处理,跟训练环节的保持一致,convert_image_to_binary_pytorch(image_path, output_path, target_size=(64,64))这个函数里的对应你自己的输入和预处理进行修改
import os
import glob
from PIL import Image
import numpy as np
import torchvision.transforms as transformsdef convert_image_to_binary_pytorch(image_path, output_path, target_size=(64,64)):"""使用 PyTorch transform 处理图片并保存为二进制文件确保和训练/验证输入一致"""# 打开图片并转换为 RGBimg = Image.open(image_path).convert('RGB')# 定义 transform,和验证集一致transform = transforms.Compose([transforms.Resize(target_size),transforms.ToTensor(), # float32, [0,1]transforms.Lambda(lambda x: x * 255) # float32, [0,255]])img_tensor = transform(img) # C,H,W, float32img_tensor = img_tensor.byte().numpy() # uint8# 保证是 NCHWimg_tensor = img_tensor.astype(np.uint8)# 保存二进制文件with open(output_path, 'wb') as f:f.write(img_tensor.tobytes())# 打印信息,便于检查print(f"Converted {os.path.basename(image_path)} -> {os.path.basename(output_path)}")print(f"Shape: {img_tensor.shape}, dtype: {img_tensor.dtype}, min/max: {img_tensor.min()}/{img_tensor.max()}\n")return output_pathdef convert_folder_to_binary_pytorch(folder_path, output_folder=None):"""批量将文件夹下图片转换为二进制文件"""# 支持的图片格式image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.bmp']if output_folder is None:output_folder = folder_pathos.makedirs(output_folder, exist_ok=True)for ext in image_extensions:for image_path in glob.glob(os.path.join(folder_path, ext)):output_name = os.path.splitext(os.path.basename(image_path))[0]output_path = os.path.join(output_folder, output_name)try:convert_image_to_binary_pytorch(image_path, output_path)except Exception as e:print(f"Failed to convert {image_path}: {e}")# 使用示例
if __name__ == "__main__":folder_path = "orignal_img"output_folder = "images"if os.path.isdir(folder_path):convert_folder_to_binary_pytorch(folder_path, output_folder)else:print("错误:指定的路径不是一个有效的文件夹")
模型和数据验证
写个脚本批量执行,分别使用转换前的pth模型和tflite模型、原始图片和转换的二进制图片进行组合推理验证,如果原始模型原始图片的推理结果有误识别不用管,那也是正常的是模型准确率的问题,确保这四种组合的输出结果都是一致的(误识别的也是一样的输出),否则根据这四个推理结果进行对比去查是哪一个环节出的问题,同一原始图片pth模型和tflite模型输出一致确保转换的tflite模型没问题,tflite模型使用原始图片和转换的二进制图片输出一致说明转换的图片没有问题
代码部署
例程创建
步骤参照这篇vscode+ESP-IDF+ESP32S3N16R8跑通TensorFlow Lite Micro for Espressif Chipsets的hello_word例程,把例程hello_world换成
person_detection即可,先跑通这个例程确保你的环境和硬件都没有问题
idf.py create-project-from-example "esp-tflite-micro:person_detection"
修改宏用图片测试
例程直接运行成功使用摄像头获取图片进行推理,然后我们选择用本地二进制图片测试,打开eap_main.h,取消#define CLI_ONLY_INFERENCE 1的注释
// Enable this to do inference on embedded images
#define CLI_ONLY_INFERENCE 1
运行成功的话在串口的终端输入detect_image 0 (0~9的任意数字都可以),就可以看到检测结果了。!!!!!!以下的前提是先把例程跑通哈!例程的README,md里有例程操作说明
模型加载
然后把前面转化的model.cc复制到main文件夹下,打开,第一行添加头文件#include "model.h",把model_tflite[]数组类型改成下面这样,只改类型其他不动
#include "model.h"alignas(8) const unsigned char model_tflite[] = {....};
const int model_tflite_len = 12345;
然后再main文件夹下新建一个model.h,输入以下代码
#ifndef MODEL_H
#define MODEL_Hextern const unsigned char model_tflite[];
extern const int model_tflite_len;#endif
然后打开main文件夹下的CMakeLists.txt,SRCS后面添加“model.cc”
idf_component_register(SRCS"detection_responder.cc""image_provider.cc""main.cc""main_functions.cc""model_settings.cc""person_detect_model_data.cc""app_camera_esp.c""esp_cli.c""model.cc"# PRIV_REQUIRES console static_images spi_flashPRIV_REQUIRES console test_images spi_flashINCLUDE_DIRS "")
打开main文件夹下的main_functions.cc,找到void setup()函数,修改模型加载,把原来加载的例程的模型g_person_detect_model_data换成了我们自己的模型model_tflite
void setup() {// Map the model into a usable data structure. This doesn't involve any// copying or parsing, it's a very lightweight operation.// model = tflite::GetModel(g_person_detect_model_data);model = tflite::GetModel(model_tflite);
然后往下滑找到算子注册的部分,替换成你自己的算子,比如我改成我自己用到的算子(跟前面提取的是对应的)
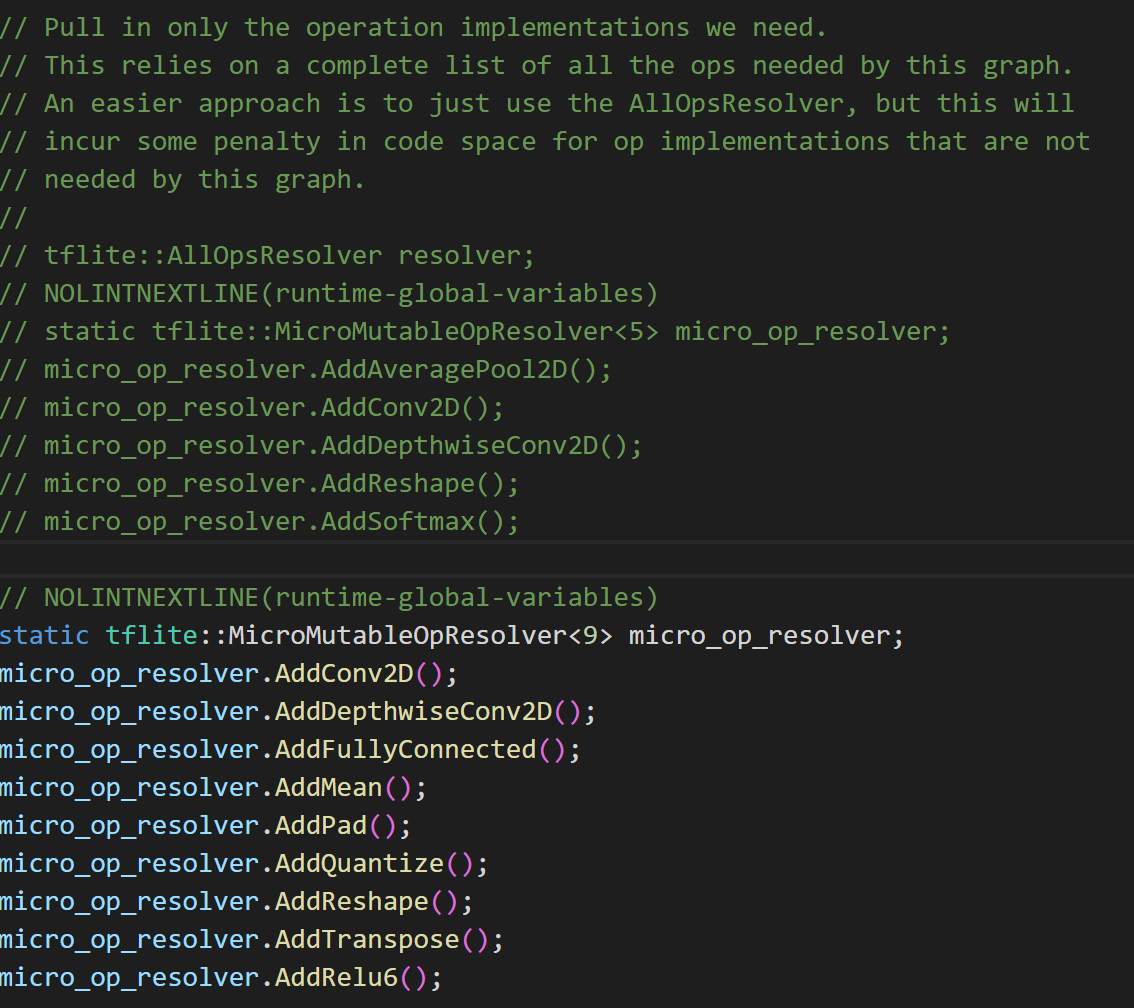
模型设置
打开main文件夹的model_settings.cc,把kCategoryLabels[kCategoryCount]数组中的类别替换为你的类别
打开main文件夹的model_settings.h,把下面的参数修改为你的输入尺寸,比如我的是(1,3,64,64),对应NCHW,我的类别总共有51类,输出为(1,51),对应修改以下内容
constexpr int kNumCols = 64; //W
constexpr int kNumRows = 64; //H
constexpr int kNumChannels = 3; //Cconstexpr int kCategoryCount = 51; //类别
图片数据替换
找到static_images文件夹中的sample_iamges文件夹,把里面的image图片文件删掉,把我们前面转换好的自己的没有后缀的image0~image9复制到这个文件夹下
推理代码修改
打开main文件夹下的main_functions.cc文件,void run_inference(void *ptr)函数里第一个#if到最后一个#endif的内容不动,其他内容删掉,然后修改成以下代码,结合注释自行理解一下,跟PC端的推理操作其实是一样的步骤
void run_inference(void *ptr) {memcpy(input->data.uint8, ptr, input->bytes);#if defined(COLLECT_CPU_STATS)long long start_time = esp_timer_get_time();
#endif// Run the model on this input and make sure it succeeds.if (kTfLiteOk != interpreter->Invoke()) {MicroPrintf("Invoke failed.");}#if defined(COLLECT_CPU_STATS)long long total_time = (esp_timer_get_time() - start_time);printf("Total time = %lld\n", total_time / 1000);//printf("Softmax time = %lld\n", softmax_total_time / 1000);printf("FC time = %lld\n", fc_total_time / 1000);printf("DC time = %lld\n", dc_total_time / 1000);printf("conv time = %lld\n", conv_total_time / 1000);printf("Pooling time = %lld\n", pooling_total_time / 1000);printf("add time = %lld\n", add_total_time / 1000);printf("mul time = %lld\n", mul_total_time / 1000);/* Reset times */total_time = 0;//softmax_total_time = 0;dc_total_time = 0;conv_total_time = 0;fc_total_time = 0;pooling_total_time = 0;add_total_time = 0;mul_total_time = 0;
#endifTfLiteTensor* output = interpreter->output(0);float output_probs[kCategoryCount];float sum = 0.0f;// 量化 uint8 -> float (反量化)for (int i = 0; i < kCategoryCount; i++) {output_probs[i] = (output->data.uint8[i] - output->params.zero_point) * output->params.scale;sum += expf(output_probs[i]); // softmax}// 计算 softmax 概率static float max_val = output_probs[0];for (int i = 1; i < kCategoryCount; i++) {if (output_probs[i] > max_val) max_val = output_probs[i];}float sum_exp = 0.0f;for (int i = 0; i < kCategoryCount; i++) {output_probs[i] = expf(output_probs[i] - max_val); // 防止 exp 溢出sum_exp += output_probs[i];}int max_idx = 0;float max_prob = 0.0f;for (int i = 0; i < kCategoryCount; i++) {output_probs[i] /= sum_exp;if (output_probs[i] > max_prob) {max_prob = output_probs[i];max_idx = i;}}int category_score_int = (max_prob) * 100 + 0.5;MicroPrintf("Detected: %s, score: %d%%",kCategoryLabels[max_idx], category_score_int);;
}到这里就可以编译运行了,前提是先把例程跑通哈!例程的README,md里有例程操作说明!!!!



















