在分布式数据平台(如 Databricks + Spark)中跑视频处理任务时,你是否遇到过这种恶心的报错?
Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe. : org.apache.spark.SparkException: Python worker exited unexpectedly (crashed): Fatal Python error: Segmentation fault
这不是 Python 代码写错了,而是 底层 C/C++ 扩展(OpenCV/NumPy/FFmpeg)崩溃,直接触发 SIGSEGV。问题在于:
👉 Python 的 try/except 根本捕获不到这类崩溃,因为解释器还没来得及抛异常就被操作系统杀掉了。
结果就是:
整个 Spark Task 挂掉
分区里所有文件的结果丢失
任务反复重试,最终 Stage 失败
今天我就带大家看看 如何用子进程隔离(subprocess/multiprocessing)机制,优雅规避 OpenCV 的崩溃,并且保证分布式任务健壮运行。
1、为什么 OpenCV 在 Spark 里容易崩溃?
多线程冲突
OpenCV 默认开启 OpenMP 线程池 (cv2.setNumThreads(8)),而 Spark Executor 本身也有并行任务。多层并发叠加,容易踩内存。FFmpeg 兼容问题
Databricks Runtime 的 FFmpeg/Ubuntu 依赖和opencv-python编译参数可能不一致,导致 VideoCapture 解码异常。视频文件问题
即使ffprobe验证过,轻微损坏或不支持的编码格式也可能让 OpenCV 在解码时崩溃。
👉 这些都属于 底层 C 库 bug,Python 级别的 try/except 根本无能为力。
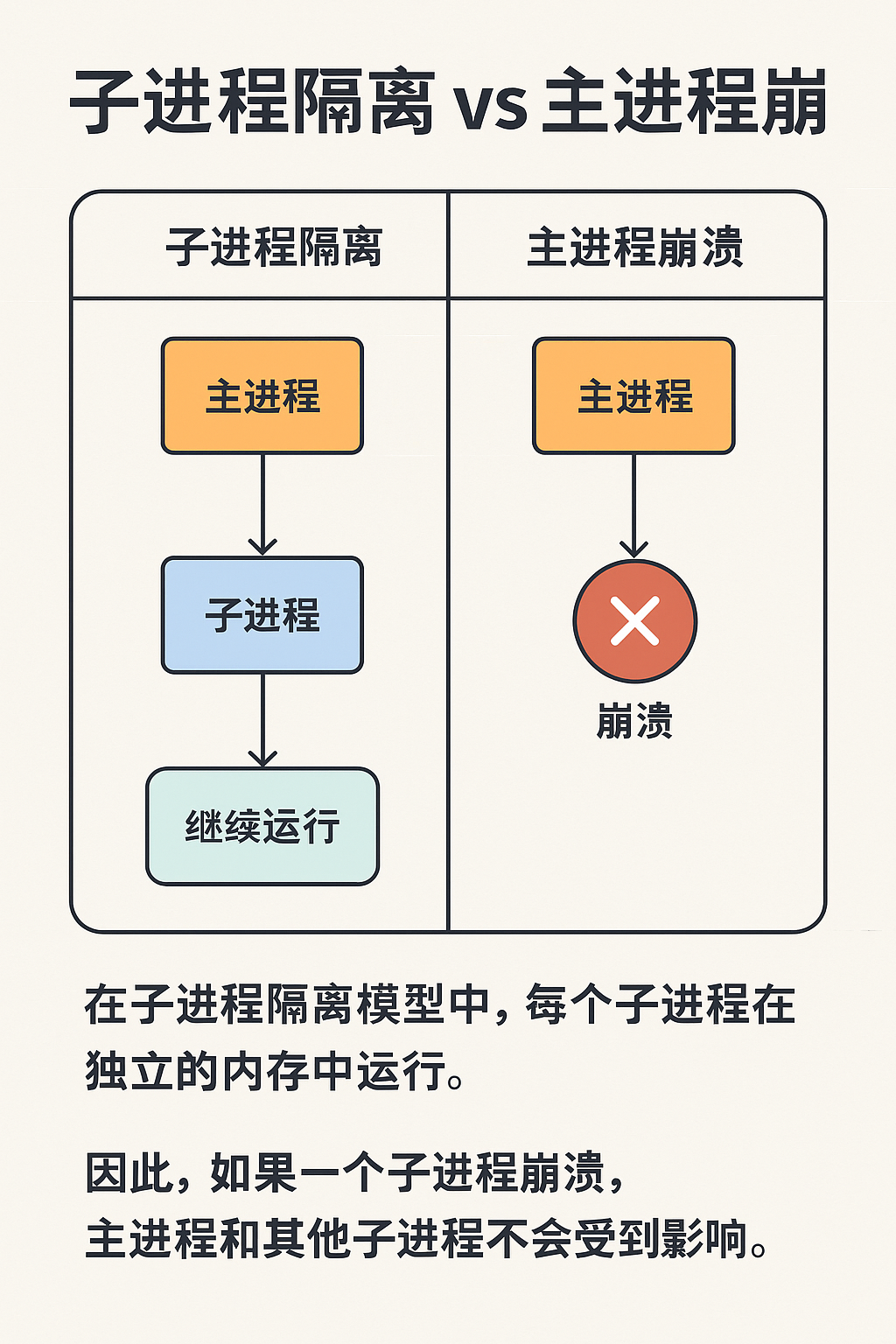
2、解决思路:子进程隔离(Crash Isolation)
核心原理:
用 子进程(独立 Python 解释器)运行不稳定的 OpenCV 代码
如果子进程崩溃(退出码 -11 = SIGSEGV),只影响它自己
父进程还能捕获退出码,记录错误,更新数据库状态为
FAILED,并继续跑其他文件
这就好比给 OpenCV 套了个“防爆盾牌”:它崩溃归它崩溃,主进程和 Spark Executor 不被拖死。
3、实现代码
以下示例展示了如何改造 单摄像头视频处理函数,用 multiprocessing 包裹 OpenCV 操作:
import multiprocessing as mp
import datetime, os
import cv2class NonRetryableError(Exception):"""不可重试的异常:用于标记为FAILED"""passdef process_single_camera_video_executor(video_path, output_dir):"""Executor端:处理单摄像头视频,使用multiprocessing隔离OpenCV崩溃"""timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]print(f"[{timestamp}] [VIDEO] 开始处理单摄像头视频(隔离子进程)")def target(q, video_path, output_dir):"""子进程运行的OpenCV逻辑"""try:cap = cv2.VideoCapture(video_path)if not cap.isOpened():raise ValueError("无法打开视频")total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))step = max(1, total_frames // 5)os.makedirs(output_dir, exist_ok=True)saved_count = 0for i in range(5):cap.set(cv2.CAP_PROP_POS_FRAMES, i * step)ret, frame = cap.read()if ret:out_path = os.path.join(output_dir, f"frame_{i}.jpg")cv2.imwrite(out_path, frame)saved_count += 1cap.release()q.put(saved_count)except Exception as e:q.put(('exception', str(e)))q = mp.Queue()p = mp.Process(target=target, args=(q, video_path, output_dir))p.start()p.join()# 🚨 检查子进程是否崩溃if p.exitcode != 0:error_msg = f"子进程崩溃,退出码: {p.exitcode} (可能是分段错误)"print(f"[{timestamp}] [VIDEO-ERROR] {error_msg}")raise NonRetryableError(error_msg)# ✅ 正常异常从队列返回result = q.get()if isinstance(result, tuple) and result[0] == 'exception':error_msg = f"子进程异常: {result[1]}"raise Exception(error_msg)print(f"[{timestamp}] [VIDEO] 成功提取 {result} 帧")return result
4、 为什么要同时做 exitcode 检查 和 队列异常检查?
exitcode != 0 → 捕获 崩溃类错误(如 C++ 层面的 Segfault),直接标记为
FAILED,不可重试队列异常返回 → 捕获 Python 级异常(如“文件打不开”、“帧为 None”),可以走
RETRY或FAILED策略
两者互补,保证了:
崩溃不拖死主进程
正常错误能被业务逻辑感知并按需重试
5、multiprocessing 与 subprocess 的区别
很多人会问:为啥用 multiprocessing,而不是直接 subprocess.run("python xxx.py")?
subprocess:适合运行外部命令,通信只能靠字符串/字节流multiprocessing:是subprocess的 Python 高级封装,支持直接传递 Python 对象(通过pickle),更适合 Spark 里函数隔离
👉 如果你只想跑 ffmpeg 命令,用 subprocess;如果是 Python 函数(如 OpenCV),用 multiprocessing。
7、最佳实践总结
禁用 OpenCV 多线程
import cv2, os os.environ["OMP_NUM_THREADS"] = "1" cv2.setNumThreads(1)首选 FFmpeg 提帧
简单场景(只需要抽帧),直接subprocess.run(["ffmpeg", "-i", ...])更稳。对子进程 exitcode 检查
0= 正常-11= Segfault → 标记FAILED
日志 + 状态更新
崩溃 →FAILED
普通异常 →RETRYorFAILED(视业务逻辑)分区隔离
每个文件单独 try/except,不要让一个文件拖死整个分区。
8、结语
在 Databricks / Spark 这类分布式环境中,不稳定的 C 扩展(如 OpenCV)就是定时炸弹。
通过 子进程隔离 + exitcode 检查 + 队列通信,我们可以优雅地把崩溃局限在单个文件级别,而不是全盘失败。
这套思路不仅适用于 OpenCV,还能推广到:
NumPy 大规模矩阵运算(偶尔崩溃)
GPU 推理代码(驱动问题导致进程挂掉)
第三方 C 扩展库
🔗 如果你在生产环境中也遇到过类似问题,欢迎在评论区交流。
📌 觉得有用记得收藏 & 点赞,让更多同学避免踩坑!
)



lossbase_v2)



)
快速入门完全指南:从零开始构建你的第二大脑(免费好用的笔记软件的知识管理系统)、黑曜石笔记)
)




![Dism++备份系统时报错[句柄无效]的解决方法](http://pic.xiahunao.cn/Dism++备份系统时报错[句柄无效]的解决方法)



