😘个人主页:@Cx330❀
👀个人简介:一个正在努力奋斗逆天改命的二本觉悟生
📖个人专栏:《C语言》《LeetCode刷题集》《数据结构-初阶》《C++知识分享》
🌟人生格言:心向往之行必能至

前言:上篇博客中,我们掌握了引用的小部分,这篇博客会接着把引用剩余的部分讲解给大家,然后还会给大家认识内联函数与nullptr的核心用法,掌握号这些知识,我们就可以进入类和对象的学习中去了
目录
一.引用(补充)
const引用:
关键点:
举例说明:
图示如下:
指针和引用的关系:(面试考点)
二.inline内联函数
关键点:
举例说明:
三.nullptr
关键点:
举例说明:
一.引用(补充)
const引用:
关键点:
- 可以引用⼀个const对象,但是必须用const引用。const引用也可以引用普通对象,因为对象的访问权限在引用过程中可以缩小,但是不能放大。
- 需要注意的是,在一些场景下,比如类型转换中会产生临时对象存储中间值,也就是说我下面的rb和rp引用的都是临时对象,而C++规定临时对象具有常性,所以这里就触发了权限放大,必须要使用常引用才可以
- 所谓临时对象就是编译器需要⼀个空间暂存表达式的求值结果时临时创建的⼀个未命名的对象,C++中把这个未命名对象叫做临时对象。
举例说明:
1.引用和指针的权限放大和缩小问题(放大不行,缩小可以):
#include<iostream>
using namespace std;
int main()
{const int a = 0;//权限放大(不能)//int& b = a;int c = 0;//权限缩小(能)const int& d = c;return 0;
}//权限的放大和缩小,只存在于const指针和const引用
//我们再来看看指针#include<iostream>
using namespace std;int main()
{const int a = 0;const int* p1 = &a;//int& p2 = p1;//这个也属于权限的放大,得写成下面这样const int* p2 = p1;//但是权限缩小还是可以的int c = 0;int* p3 = &c;const int* p4 = p3;return 0;
}2.const可以引用常量,作为函数参数时如果不是为了让形参的改变可以影响实参,是可以const修饰引用的,这样传参的时候选择更多 :
#include<iostream>
using namespace std;int main()
{int i = 0;double d = i;//这个是可以通过编译的,涉及隐式类型转换,因为int和double本质上都是关于数据类型大小的。//像整型和指针就只能用强制类型转换,如下int p = (int)&i;//但是我们再来看看引用里面的使用int j = 1;//double& rd = j;//不行const double& rd = j;//这个就可以了//为什么呢?--我们先不急再看一个例子//int& rp = (int)&j;//不行const int& rp = (int)&j;//可以//-------------------------具体原因分析(配合图片)------------------------------------//这是因为在引用里面,转换的过程中会产生一个临时对象保存中间值。//所以实际上rb,rp引用的都是中间值,在C++里这个临时对象是具有常性的(即被const修饰)//因此我们这里如果直接转换的话,就会出现权限放大的错误,我们必须使用常引用(即const修饰)return 0;
}图示如下:

指针和引用的关系:(面试考点)
C++中指针和引用就像两个性格迥异的亲兄弟,指针是哥哥,引用是弟弟,在实践中他们相辅相成,相得益彰。功能有重叠性,但是也有各自的特点,互相不可替代:
- 语法概念上引用是一个变量的取别名不开空间,指针是存储⼀个变量地址,要开空间。(我们一般尽量取谈语法层,底层只在一些特殊场景下用来辅助了解)
- 引用在定义时必须初始化,指针建议初始化,但是语法上不是必须的。
- 引用在初始化时引用⼀个对象后,就不能再引用其他对象;而指针可以在不断地改变指向对象。
- 指针很容易出现空指针和野指针的问题,引用很少出现,引用使用起来相对更安全⼀些。
- 引用可以直接访问指向对象,指针需要解引用才是访问指向对象。
- sizeof中含义不同,引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节,64位下是8byte)
二.inline内联函数
关键点:
- 用inline修饰的函数叫做内联函数,编译时C++编译器会在调用的地方展开内联函数,这样调用内联函数就不需要建立栈帧了,可以提高效率。
-
inline对于编译器而言只是一个建议,也就是说,你加了inline编译器也可以选择在调用的地方不展开,不同编译器关于inline什么情况展开各不相同,因为C++标准没有规定这个。inline适用于频繁调用的短小函数,对于递归函数,代码相对多⼀些的函数,加上inline也会被编译器忽略。
- C语言实现宏函数也会在预处理时替换展开,但是宏函数实现很复杂很容易出错的,且不方便调试,C++设计了inline目的就是替代C的宏函数。
- vs编译器 debug版本下面默认是不展开inline的,这样方便调试,debug版本想展开需要设置⼀下两个地方(后面的举例说明中会有)。
- inline不建议声明和定义分离到两个文件,分离会导致链接错误。因为inline被展开,就没有函数地址,链接时会出现报错。
举例说明:
先来看看之前C语言中宏函数里面的一些坑吧,以ADD函数为例:
错误一:
#define ADD(int x,int y) return x+y;这个错误很离谱,我们要牢记宏是一种替换机制,这里直接写成了一个函数,很明显是错误的
错误二:
//宏是一种替换机制
//#define ADD(int x,int y) return x+y;
//错误写法二:
//#define ADD(a,b) a+b;
//宏定义不要带分号
//我们把分号去掉,但是还是有问题的
#define ADD(a,b) a+busing namespace std;int main()
{int ret1 = ADD(1, 2);//展开之后:int ret1 = 1 + 2;;,会出现两个分号,这里还不会报错,我们再来看看下面的//int ret2 = ADD(1, 2) * 3;//这里就出问题了//我们就算不带分号,上面这个ret2最后的值也是错的int ret2 = ADD(1, 2) * 3;//我们想要得到的是9,但是我们打印出来是7cout << ret2 << endl;//因为展开之后:1 + 2 * 3 = 7//这里的优先级被影响了return 0;
}宏定义时,不要加分号,还需要加上()来保持优先级
错误三:
#define ADD(a,b) (a+b)
#include<iostream>
using namespace std;int main()
{//这样写ret2打印出来的结果是我们想要的9int ret2 = ADD(1, 2) * 3;cout << ret2 << endl;//但是这种写法还是存在一些问题的int x = 0, y = 1;ADD(x | y, x & y);//展开会变成:(x | y + x & y)//+号的优先级高于 |和& 所以这里相当于(x|(y+x)&y)return 0;
}带上了外面的括号,ret2的问题解决了。但是在一些场景下还是有问题
正确写法:
//正确写法:
#define ADD(a,b) ( (a) + (b) )
#include<iostream>
using namespace std;int main()
{//这样写ret2打印出来的结果是我们想要的9int ret2 = ADD(1, 2) * 3;cout << ret2 << '\n';//这种写法也没问题了int x = 0, y = 1;ADD(x | y, x & y);//展开会变成:( (x | y) + (x & y) ),符合我们的目的return 0;
}💡Tips:
宏函数这么复杂,容易写出问题,还不能调试。
那我们为什么还要用它呢,它的优势在于什么呢?
优点:高频调用小函数时,写成宏函数,可以提高效率,预处理阶段宏会替换,提高效率,不建立栈帧
我们在C++中使用inline内联函数代替宏函数该怎么写:
inline int ADD(int x, int y)
{return x + y;
}和函数的写法差不多,但是是不一样的。它编译是直接展开的跟宏一样,不会创建栈帧空间
因为默认debug版本下,为了方便调试,inline也不展开。我们需要完成两设置:
代码:
#include<iostream>
using namespace std;//转反汇编看,发现还是有call还是创建了栈帧,这是为什么
inline int ADD(int a, int b)
{return a + b;
}
//因为默认debug版本下,为了方便调试,inline也不展开。
//我们需要设置一下--这里大家可以自己测试看看,最号=好用低版本的vsint main()
{int ret2 = ADD(1, 2) * 3;cout << ret2 << '\n';//打印出来也是9,完全没有问题return 0;
}设置步骤:
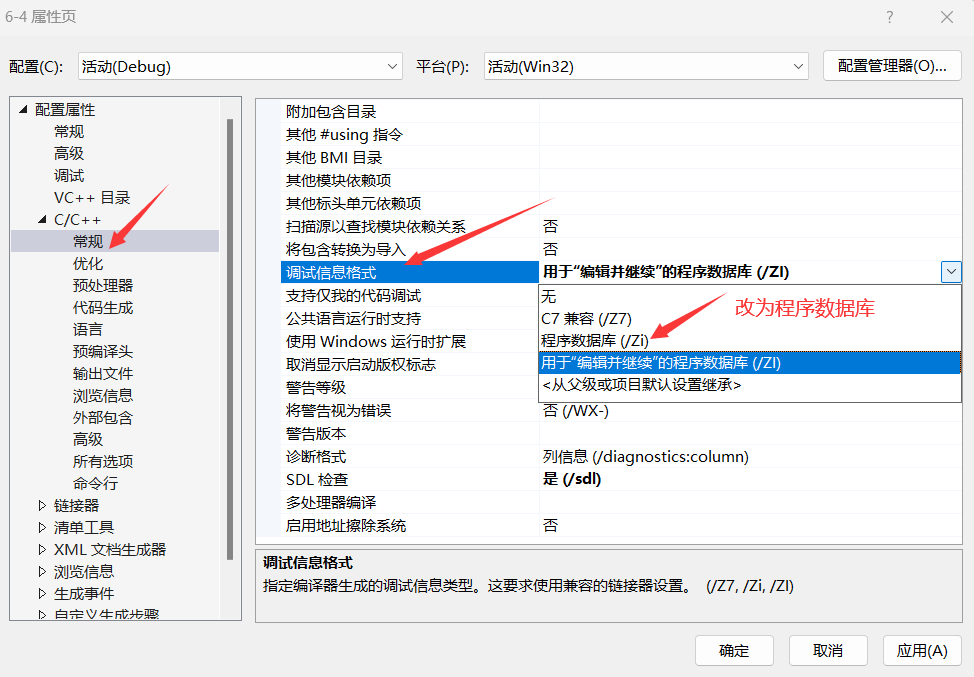
- 右键单击解决方案资源管理器中的项目,选择“属性”。
- 在弹出的属性对话框中,找到“C/C++”选项卡,点击“常规”。
- 在“调试信息格式”下拉菜单中,选择“程序数据库(/Zi)”。
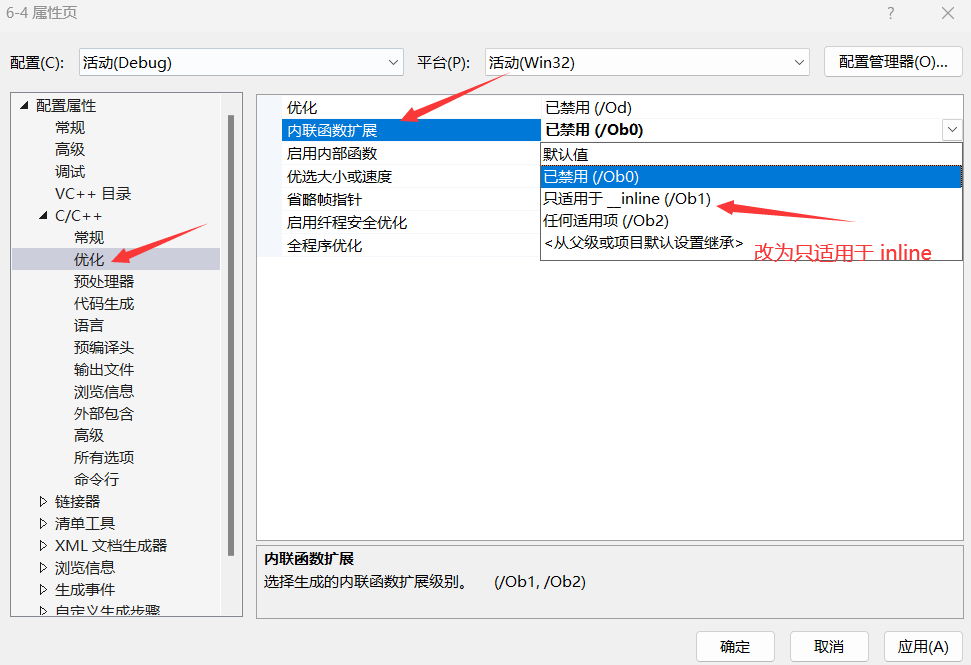
- 接着点击“C/C++”下的“优化”选项。
- 在“内联函数的扩展”下拉菜单中,选择“只适用于_inline(/Ob1)”。

inline只是一个建议,展开还是创建空间由编译器说的算,递归和代码多的函数可能就不会展开:
#include<iostream>
using namespace std;inline int ADD(int a, int b)
{a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;a *= 2;//5个的时候还是可以展开的,10个就不行了return a + b;
}int main()
{int ret2 = ADD(1, 2) * 3;cout << ret2 << '\n';return 0;
}图示如下:
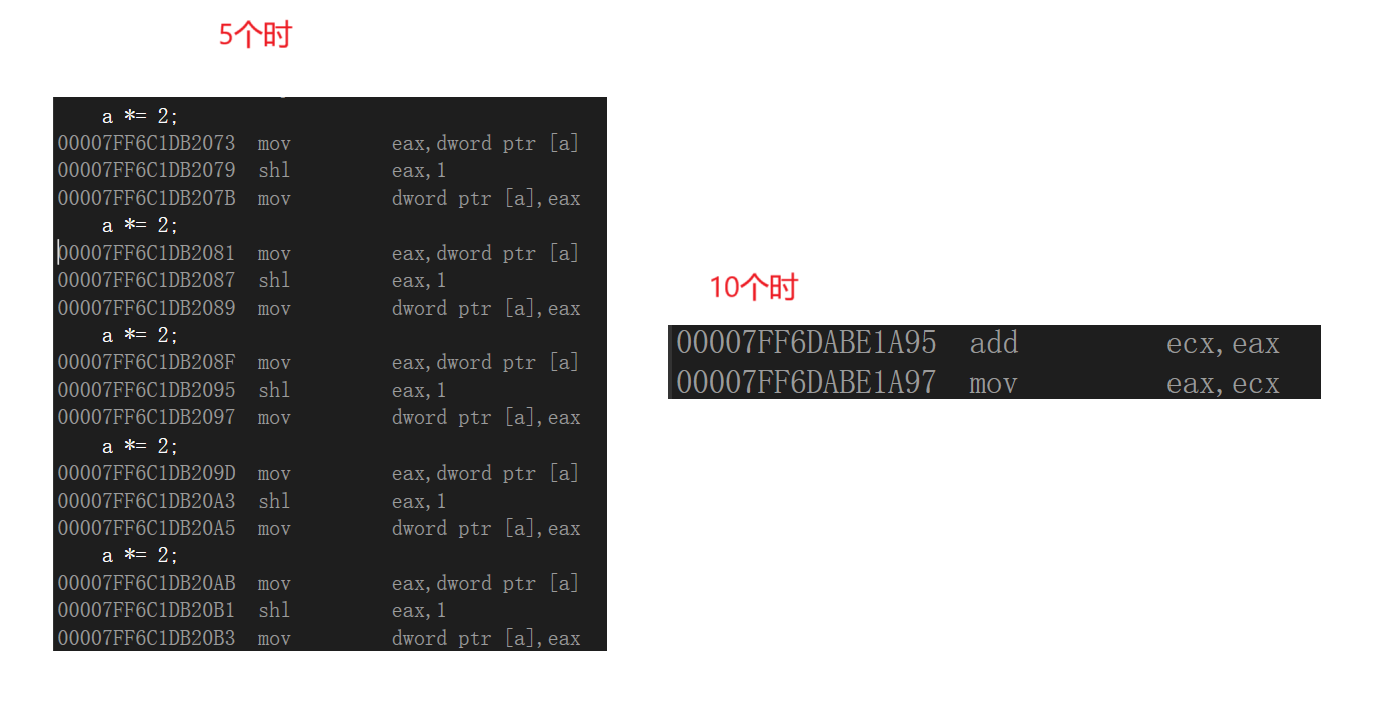
思考:为什么只是建议呢?
如果完全交给程序员,可能会出现代码指令恶性膨胀的问题,导致可执行程序(安装包)过大,这是特别不好的。所以编译器会自己把握这个展开还是不展开,有其自己的逻辑和判断。

inline不建议声明和定义放离到两个文件,分离会导致链接错误。因为inline被展开,就没有函数地址,链接时会出错:(注意看注释)
拿顺序表为例,我直接给正确改法了,然后它的.cpp文件和.h文件这里是截图的
SeqList.h:(内联函数直接在.h文件中实现就可以了)
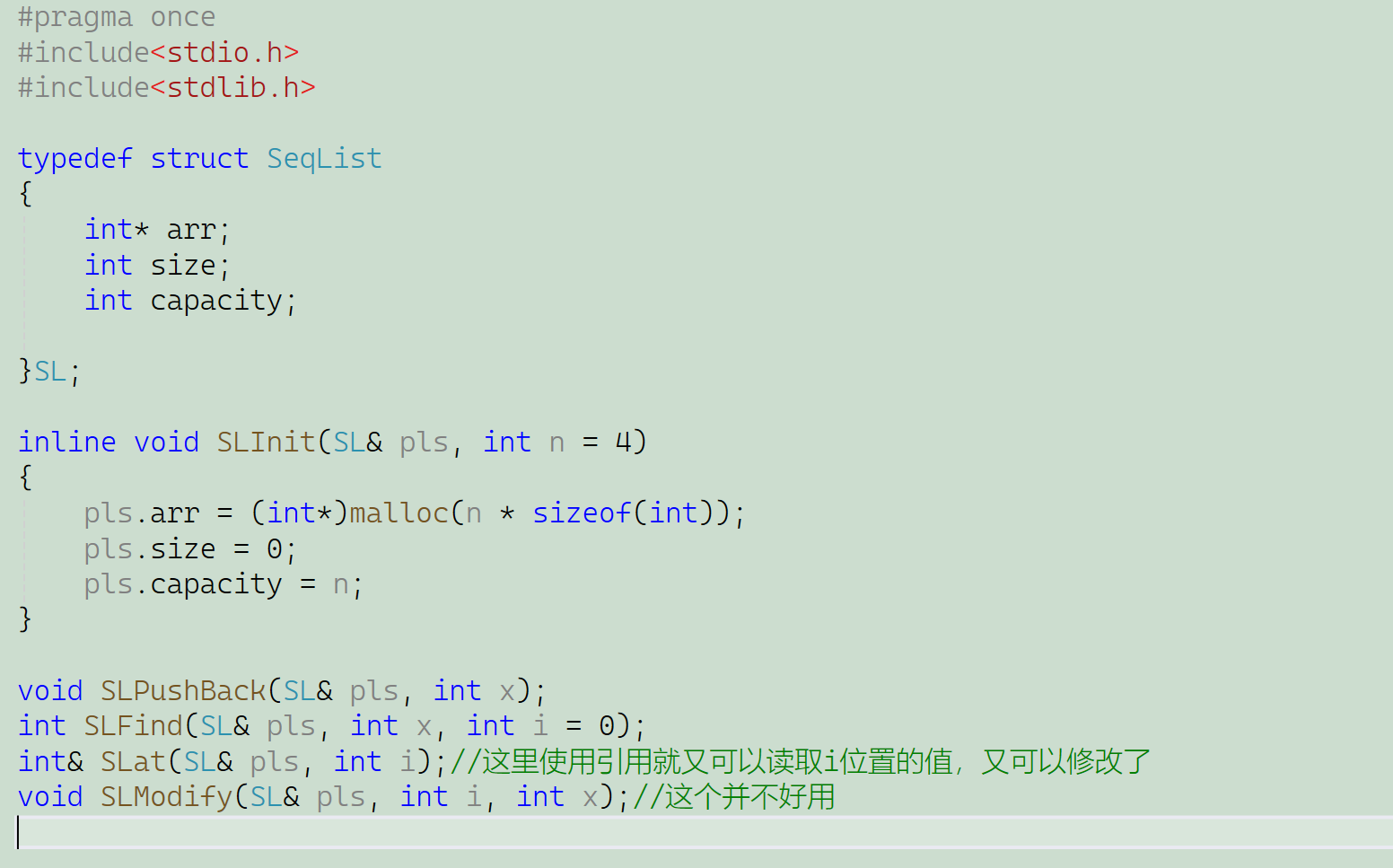
SeqList.cpp:(在.cpp文件中不需要再实现内联函数了,可以看出我这里注释掉了)
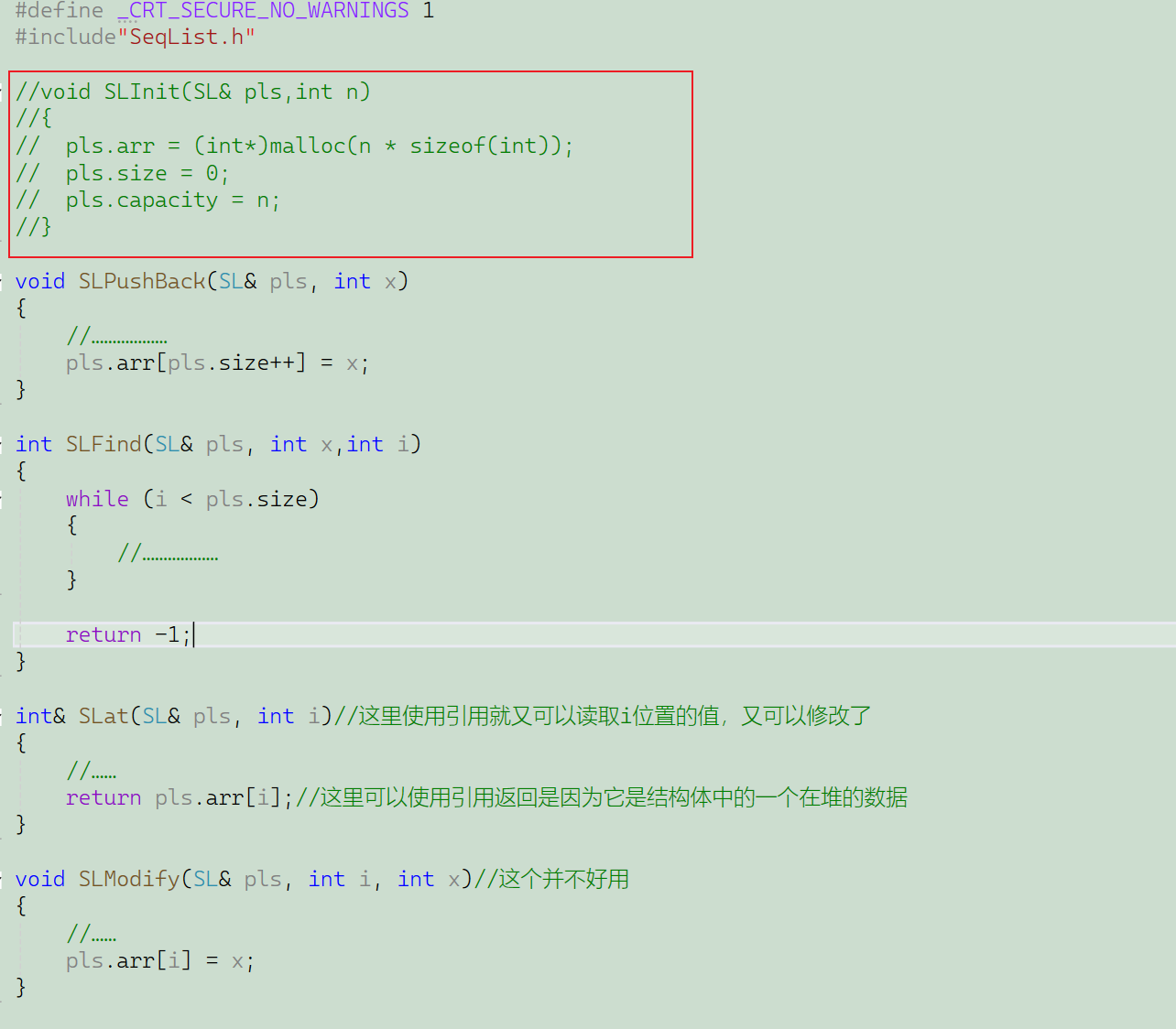
test.cpp:
#include"SeqList.h"int main()
{SL s;//我实现用的引用所以不用传地址SLInit(s); // call 地址return 0;
}三.nullptr
NULL实际是⼀个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:

关键点:
- C++中NULL可能被定义为字面常量0,或者C中被定义为无类型指针(void*)的常量。不论采取何种定义,在使用空值的指针时,都不可避免的会遇到⼀些麻烦,本想通过f(NULL)调⽤指针版本的f(int*)函数,但是由于NULL被定义成0,调用了f(int x),因此与程序的初衷相悖。f((void*)NULL);调用会报错。
- C++11中引入nullptr,nullptr是⼀个特殊的关键字,nullptr是⼀种特殊类型的字面量,它可以转换成任意其他类型的指针类型。使用nullptr定义空指针可以避免类型转换的问题,因为nullptr只能被隐式地转换为指针类型,而不能被转换为整数类型。
举例说明:
#include<iostream>
using namespace std;void f(int x)
{cout << "f(int x)" << endl;
}void f(int* ptr)
{cout << "f(int* ptr)" << endl;
}int main()
{f(0);f(NULL);//f((void*)0);--有个图片//用上面的都会执行出来函数1,而不会是函数2f(nullptr);//但是用nullptr就很清晰了,可以很好处理这个问题int* p1 = NULL;char* p2 = NULL;//以后我们在C++里面置为空都这样写int* p3 = nullptr;char* p4 = nullptr;return 0;
}
这里可以看出用NULL时并没有达到我想要的效果,但是用nullptr可以
完整源代码:
CPP专属仓库: 【CPP知识学习仓库】 - Gitee.com
往期回顾:
《C++起源与核心:版本演进+命名空间法》
《C++基础:输入输出、缺省参数,函数重载与引用的巧妙》
总结:这篇博客到这里就结束了,我们C++人们知识也就告一段落,接下来就会进入我们类和对象的学习中去,如果文章对你有帮助的话,欢迎评论,点赞,收藏加关注,感谢大家的支持。


)










:化繁为简,Spring Boot自动配置的实现之秘)


)
![[Vid-LLM] docs | 视频理解任务](http://pic.xiahunao.cn/[Vid-LLM] docs | 视频理解任务)

![[Java恶补day51] 46. 全排列](http://pic.xiahunao.cn/[Java恶补day51] 46. 全排列)