基于muduo库的图床云共享存储项目(一)
- 项目简介
- 整体架构
- 项目依赖基础组件
- muduo库
- Channel类
- Poller / EpollPoller 类
- EventLoop
- Acceptor类
- FastDfs
- JSON的使用
项目简介
当前所实现的项目是一个基于muduo库的图床云共享存储项目,他的主要的功能就是我们可以注册对应的账号,然后登录到系统当中,然后进行各类文件的上传操作,同时,我们也可以将对用的文件进行共享,包括对应的一个下载热榜,下面就是该项目的部分功能截图: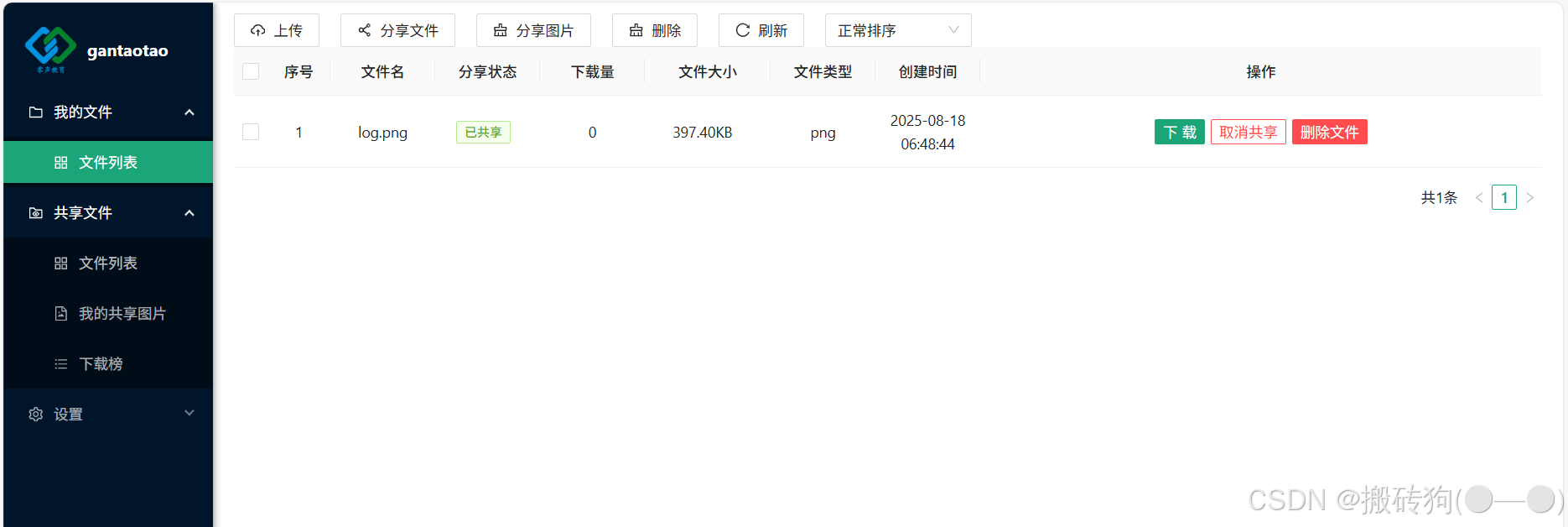
当然,当前项目我们实现是 C++ 后端部分,前端部分就不会涉及到,对于当前项目涉及到一些知识点就如下:Redis,MySQL,线程池,reactor网络模型,http协议,fastfds等等诸多的知识点联系在一起。
整体架构
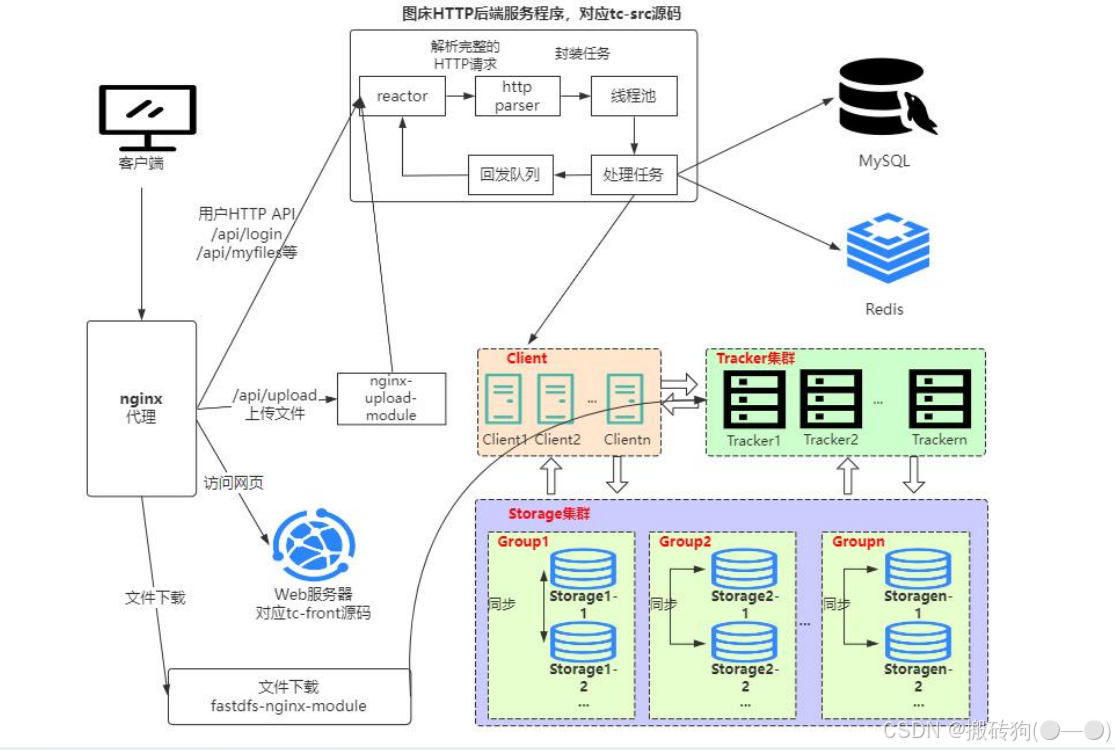
该项目的整体架构如下图所示,简单理解就是客户端发起一个 HTTP 请求以后(比如注册,上传文件等),通过 nginx 代理将请求发送到我们的服务端,服务端就会对请求进行处理,报错请求的解析,任务处理(将数据保存到 MySQL ,Redis,FastDfs),然后将处理结果进行回发,最终我们对上传的文件进行下载同样是通过 nginx 代理进行下载的。
项目依赖基础组件
了解项目的整体架构以后,接下我们就引入几个新的知识点,也是我们项目所依赖的东西
muduo库
Muduo网络库:底层实质上为Linux的epoll + pthread线程池,且依赖boost库。 muduo的网络设计核心为一个线程一个事件循环,有一个main Reactor负载accept连接,然后把连接分发到某个sub Reactor(采用轮询的方式来选择sub Reactor),该连接的所用操作都在那个sub Reactor所处的线程中完成。多个连接可能被分派到多个线程中,以充分利用CPU,Reactor poll的大小是固定的,根据CPU的数目确定。如果有过多的耗费CPU I/O的计算任务,可以提交到创建的ThreadPool线程池中专门处理耗时的计算任务。
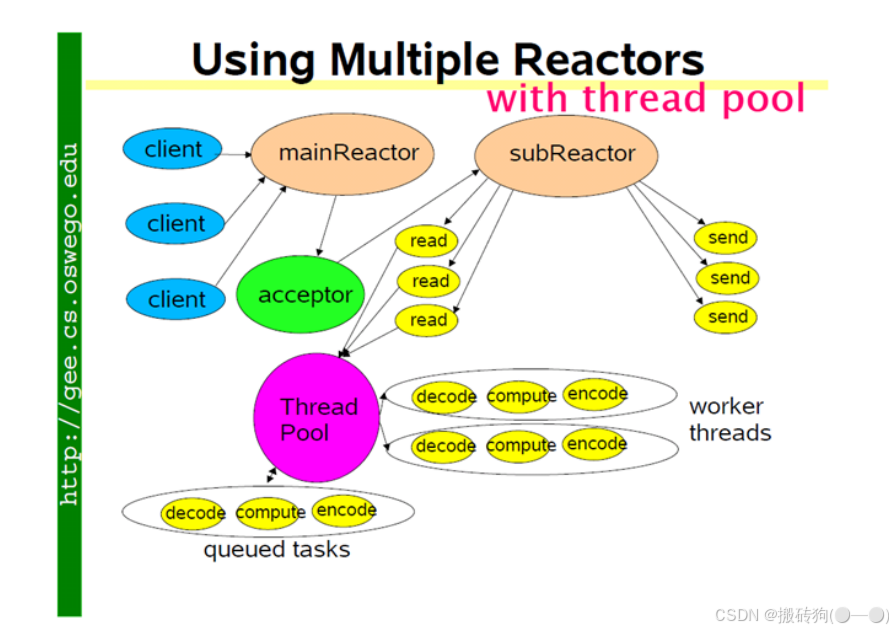
他的核心原理就在于:
- mainRecator 负责监听所有连接请求,并且将这些连接均匀的分配给 subReactor ,后续新连接的 read ,write 事件由 subReactor 进行处理;
- subReactor 可以有多个,每一个 subReactor 会为其分配一个线程;
- ThreadPool 并不是针对某一个 subReactor ,而是针对于所有的 subReactor ,这儿需要注意的是,每一个 fd 对应的接收和发送数据以及最后的关闭,他其实都是在自己的 subReactor 中去实现的,并不会跳进别的 subReactor 中去;
- 读取到数据以后,可以将数据封装成一个任务,然后交给线程池进行处理,而且读取数据以后,也并不是直接调用 send 函数进行发送,而是先将数据存入到缓冲区当中去,最终封装成任务交给线程池进行处理。
Channel类
Channel类是指在Muduo库中负责管理文件描述符(FD)及其事件处理的类。它相当于文件描述符的“保姆”,负责监听文件描述符上的事件,并调用相应的处理函数来响应这些事件,他主要就是实现以下的四个功能:
- 监听文件描述符:Channel类跟踪文件描述符的状态,包括读写事件、连接事件等。
- 事件处理:当文件描述符上发生事件时,Channel类会调用预先注册的事件处理函数来处理这些事件。
- 封装接口:Channel类提供了统一的接口来处理各种事件,使得开发者可以更方便地管理文件描述符及其事件。
- 状态管理:Channel类管理文件描述符的就绪状态,确保在事件发生时能够及时响应。
重要的成员变量
- int fd_:Channel对象照看的文件描述符;
- int events_:代表fd感兴趣的事件类型集合;
- int revents_:代表事件监听器实际监听到该fd发生的事件类型集合,当事件监听器监听到一个fd发生了什么事件,通过Channel::set_revents()函数来设置revents值;
- EventLoop* loop:fd属于哪个EventLoop对象;
- read_callback_ 、write_callback_、close_callback_、error_callback_:这些是std::function类型,代表着这个Channel为这个文件描述符保存的各事件类型发生时的处理函数。
重要的成员方法
- 向Channel对象注册各类事件的处理函数
void setReadCallback(ReadEventCallback cb) { readCallback_ = std::move(cb); }void setWriteCallback(EventCallback cb) { writeCallback_ = std::move(cb); }void setCloseCallback(EventCallback cb) { closeCallback_ = std::move(cb); }void setErrorCallback(EventCallback cb) { errorCallback_ = std::move(cb); }
- 将Channel中的文件描述符及其感兴趣事件注册事件监听器上或从事件监听器上移除
void enableReading() { events_ |= kReadEvent; update(); }void disableReading() { events_ &= ~kReadEvent; update(); }void enableWriting() { events_ |= kWriteEvent; update(); }void disableWriting() { events_ &= ~kWriteEvent; update(); }void disableAll() { events_ = kNoneEvent; update(); }
Poller / EpollPoller 类
负责监听文件描述符事件是否触发以及返回发生事件的文件描述符以及具体事件的模块就是Poller,Poller是个抽象虚类,由EpollPoller和PollPoller继承实现,与监听文件描述符和返回监听结果的具体方法也基本上是在这两个派生类中实现。EpollPoller就是封装了用epoll方法实现的与事件监听有关的各种方法,PollPoller就是封装了poll方法实现的与事件监听有关的各种方法。
重要成员变量
- int epollfd_:epoll_create方法返回的epoll句柄;
- ChannelMap channels_:负责记录文件描述符
--->Channel的映射; - EventLoop* ownerLoop_:所属的EventLoop对象。
对外部提供的最重要的方法
TimeStamp poll(int timeoutMs, ChannelList *activeChannels)
poll 函数是 Poller 的核心,外界调用 poll 函数,其实就是获取 epoll_wait 这个事件监听器上发生事件的fd及其对应发生的事件,每个 fd 都是由一个 Channel 封装的,通过哈希表 channels_ 可以根据fd找到封装这个 fd 的 Channel ,将事件监听器监听到该 fd 发生的事件写进这个 Channel 中的 revents 成员变量中。
然后把这个 Channel 装进 activeChannels 中,这样,当外界调用完poll之后就能拿到事件监听器的监听结果(activeChannels_),这个 activeChannels 就是事件监听器监听到的发生事件的 fd ,以及每个 fd 都发生了什么事件。
EventLoop
作为一个网络服务器,需要有持续监听、持续获取监听结果、持续处理监听结果对应的事件的能力,也就是我们需要循环的去调用Poller:poll方法获取实际发生事件的Channel集合,然后调用这些Channel里面保管的不同类型事件的处理函数。
EventLoop就是负责实现“循环”,Channel和Poller其实相当于EventLoop的手下,EventLoop整合封装了二者并向上提供了更方便的接口来使用,下面就是核心代码:
void EventLoop::loop(const int timeoutMs)
{assert(!looping_);assertInLoopThread();looping_ = true;quit_ = false; // FIXME: what if someone calls quit() before loop() ?LOG_TRACE << "EventLoop " << this << " start looping";while (!quit_){activeChannels_.clear();pollReturnTime_ = poller_->poll(timeoutMs, &activeChannels_);++iteration_;if (Logger::logLevel() <= Logger::TRACE){printActiveChannels();}// TODO sort channel by priorityeventHandling_ = true;for (Channel* channel : activeChannels_){currentActiveChannel_ = channel;currentActiveChannel_->handleEvent(pollReturnTime_);}currentActiveChannel_ = NULL;eventHandling_ = false;doPendingFunctors();}LOG_TRACE << "EventLoop " << this << " stop looping";looping_ = false;
}
EventLoop起到一个驱动循环的功能,Poller负责从事件监听器上获取监听结果。而Channel类则在其中起到了将fd及其相关属性封装的作用,将fd及其感兴趣事件和发生的事件以及不同事件对应的回调函数封装在一起,这样在各个模块中传递更加方便。
EventLoop的主要功能就是持续循环的获取监听结果并且根据结果调用处理函数。
Acceptor类
Acceptor 就是接受新用户连接并分发连接给SubReactor,Accetpor 封装了服务器监听套接字fd以及相关处理方法。
重要成员变量
- acceptSocket_:服务器监听套接字的文件描述符;
- acceptChannel_:把acceptSocket_及其感兴趣事件和事件对应的处理函数都封装进去;
- EventLoop *loop:监听套接字的fd由哪个EventLoop负责循环监听以及处理相应事件,其实这个EventLoop就是main EventLoop;
- newConnectionCallback_:TcpServer构造函数中将TcpServer::newConnection( )函数注册给了这个成员变量。这个TcpServer::newConnection函数的功能是公平的选择一个subEventLoop,并把已经接受的连接分发给这个subEventLoop。
重要成员方法
- listen():开启对acceptSocket_的监听同时将acceptChannel及其感兴趣事件(可读事件)注册到main EventLoop的事件监听器上;
- handleRead():要注册到acceptChannel_上的, 同时handleRead( )方法内部还调用了成员变量newConnectionCallback_保存的函数。当main EventLoop监听到acceptChannel_上发生了可读事件时(新用户连接事件),就是调用这个handleRead( )方法。它最终实现的功能是什么,接受新连接,并且以负载均衡的选择方式选择一个sub EventLoop,并把这个新连接分发到这个subEventLoop上。
FastDfs
FastDFS 是一个开源的分布式文件系统,它旨在提供高性能、高可靠性和可扩展性的文件存储解决方案,解决海量数据存储问题。其主要的功能包括:文件存储,同步和访问。特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务,如图片分享和视频分享网站。
比如说有一个大型的网站,用户可以上传和下载大量的图片和视频文件。如果这些文件都存储在单个服务器上,可能会导致服务器负载过高、存储空间不足以及访问速度慢等问题。这时就需要将这些文件分布式地存储在多台服务器上,以提高整个系统的性能和可靠性。FastDFS 就是为了解决这个问题而设计的,它可以将大文件切分成小块,并将这些小块分散存储在多个服务器上,实现文件的分布式存储。
FastDFS由跟踪服务器(tracker server)、存储服务器(storage server)和客户端(client)三部分组成,架构如下图所示:
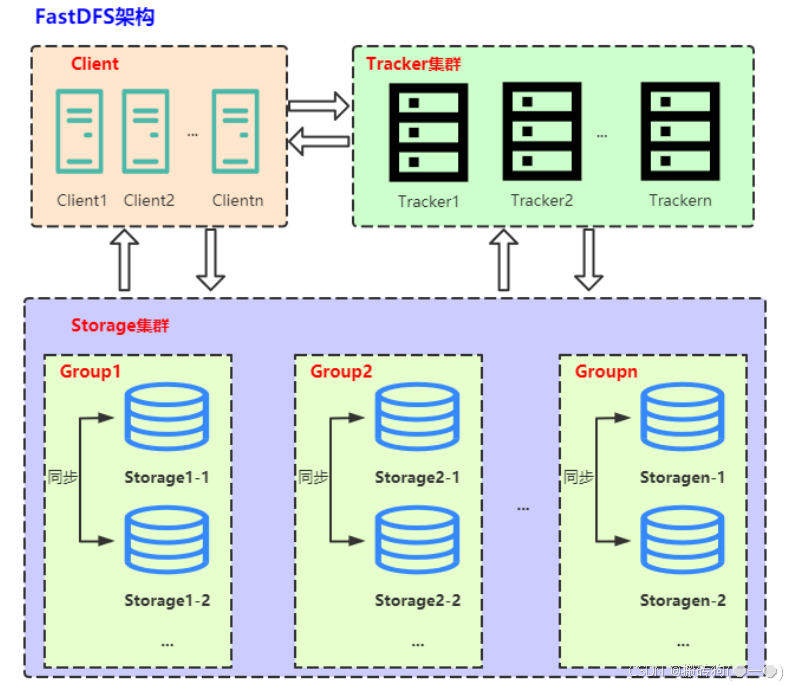
跟踪服务器(tracker server)
Tracker是FastDFS的协调者,负责管理所有的storage server和group,每个storage在启动后会连接Tracker,告知自己所属的group等信息,并保持周期性的心跳,tracker根据storage的心跳信息,建立group==>[storage server list]的映射表。
client 访问 storage server 之前,必须先访问 tracker server,动态获取到 storage server 的连接信息,最终数据是和一个可用的 storage server 进行传输。
存储服务器(storage server)
Storage server以组(卷,group或volume)为单位组织,一个group内包含多台storage机器,数据互为备份。存储空间以group内容量最小的storage为准。
以group为单位组织存储能方便的进行应用隔离、负载均衡、副本数定制,将不同应用数据存到不同的group就能隔离应用数据,根据应用的访问特性来将应用分配到不同的group来做负载均衡。
缺点是group的容量受单机存储容量的限制,同时当group内有机器坏掉时,数据恢复只能依赖group内地其他机器,使得恢复时间会很长。
group内每个storage的存储依赖于本地文件系统,storage可配置多个数据存储目录,比如有10块磁盘,分别挂载在/data/disk1 到 /data/disk10,则可将这10个目录都配置为storage的数据存储目录。
storage接受到写文件请求时,会根据配置好的规则,选择其中一个存储目录来存储文件。为了避免单个目录下的文件数太多,在storage第一次启动时,会在每个数据存储目录里创建2级子目录,每级256个,总共65536个文件,新写的文件会以hash的方式被路由到其中某个子目录下,然后将文件数据直接作为一个本地文件存储到该目录中。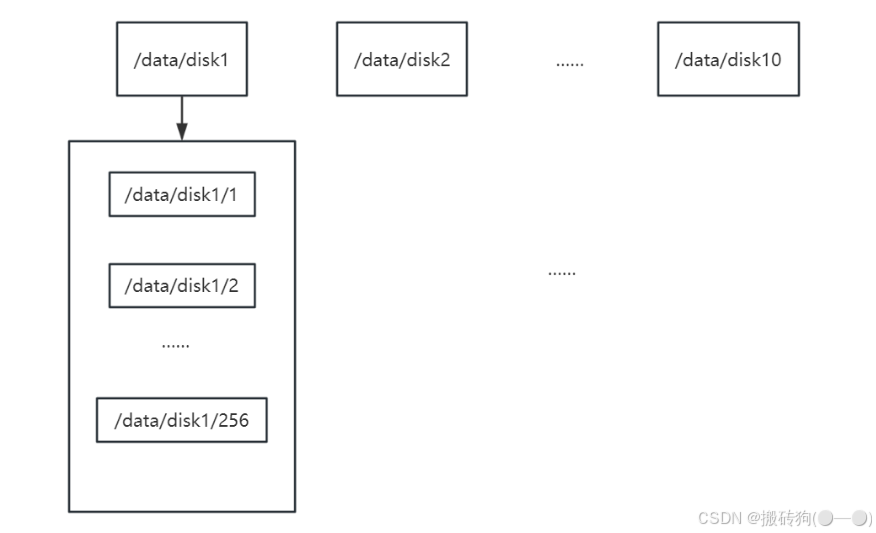
client
FastDFS向使用者提供基本文件访问接口,比如monitor、upload、download、append、delete等,以客户端库的方式提供给用户使用。
JSON的使用
在当前项目当中还涉及到了 json 的序列化以及反序列化,json 其实就属于一种独立的数据交换格式,通常是以明文字符串的形式进行组织,在网络通信中我们也是会经常用到,其实就是以键值对的形式进行进行组织,如下所示对于学生信息的组织:
{"name":"张三","age":18,"grades":[88.8, 88.9, 90.1]
}
因为对于不同主机服务器来说,对应的数据格式以及处理规则可能是不一样的,我们就需要通过这种序列化与反序列化的方式来对于不同的主机之间进行数据格式的转换操作。
我们通常进行使用的就是 Value 类,Reader 类以及 Writer 类:
Value类
Value 类通常是用于中间数据的存储,多个字段的数据要进行序列化,就必须先将数据存储在 Value 对象中,而且如果要将一个 json 对象进行解析,也需要将解析结果存放在 Value 对象中,通常 Value 类中用到的比较多的接口就是下面的接口:
Value& operator=(Value other);
Value& operator[(const char* key; // Value["name"] = "张三"
Value& append(const Value& value); // 数据组的新增,Value["grades"].append(88)
std::string asString() const; // Value["name"].asSring();
ArrayIndex size() const; // 获取数组元素个数
Value& operator[](ArrayIndex index); // 通过数组下标获取数组元素
Writer类
Writer类 主要就是提供序列化的操作的一些接口:
class JSON_API StreamWriter {
protected:JSONCPP_OSTREAM* sout_; // not owned; will not delete
public:StreamWriter();virtual ~StreamWriter();virtual int write(Value const& root, JSONCPP_OSTREAM* sout) = 0;
}class JSON_API StreamWriterBuilder : public StreamWriter::Factory {
public:Json::Value settings_;StreamWriterBuilder();~StreamWriterBuilder() JSONCPP_OVERRIDE;StreamWriter* newStreamWriter() const JSONCPP_OVERRIDE;
}
主要是通过工厂模式去创建 StreamWriter 对象然后在进行接口的调用。
Reader类
class JSON_API CharReader {
public:virtual ~CharReader() {}virtual bool parse(char const* beginDoc, char const* endDoc, Value* root, JSONCPP_STRING* errs) = 0;
}class JSON_API CharReaderBuilder : public CharReader::Factory {
public:Json::Value settings_;CharReaderBuilder();~CharReaderBuilder() JSONCPP_OVERRIDE;CharReader* newCharReader() const JSONCPP_OVERRIDE;
}
通常也是工厂模式,创建一个 CharReader 对象以后然后调用 parse 方法进行反序列化。
以上就是当前项目的一个简介,后续项目的具体实现也会逐步进行更新。


深入了解AVFoundation-编辑:视频变速功能-实战在Demo中实现视频变速)
|实战指南:构建论文分析智能体)








)
什么是 MCP?如何使用 Charry Studio 集成 MCP?)



以及行数复用)
- Mediatek KMS实现mtk_drm_drv.c(Part.1))
