文章目录
- 一、SAM(Segment Anything Model) —— 致力于建立第一个图像分割基础模型(Foundation Model)
- 1、项目背景
- 2、核心任务设计
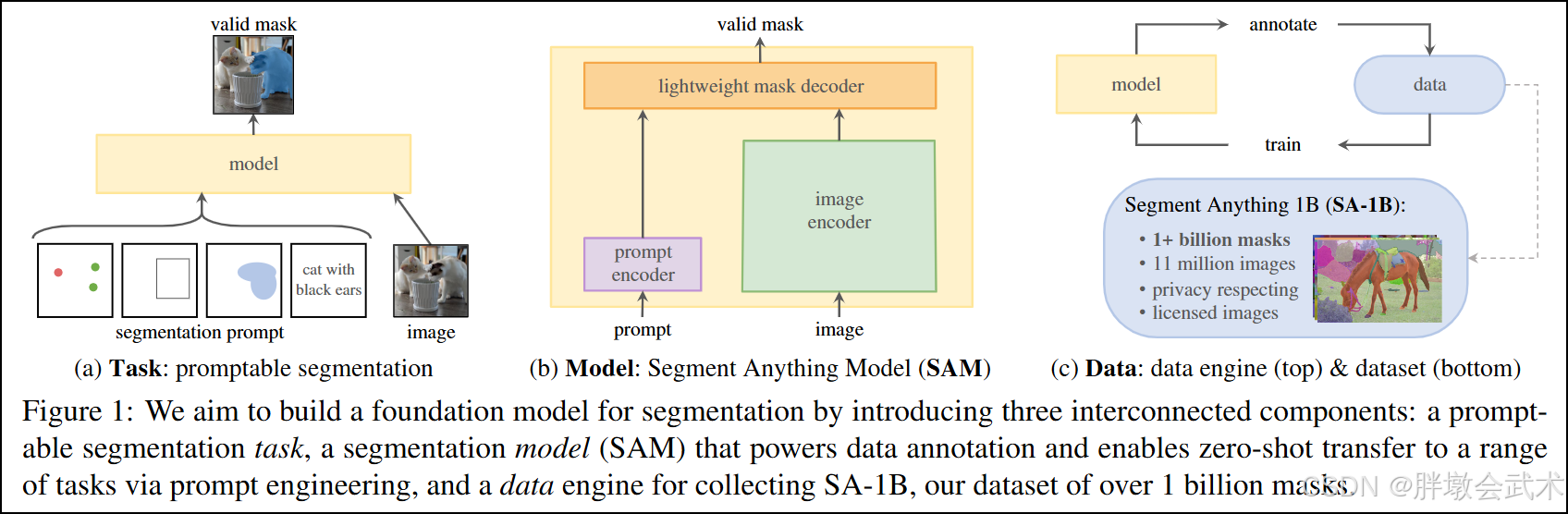
- 3、模型架构:图像编码器 + 提示编码器 + 掩码解码器
- 4、核心创新:可提示分割任务(Promptable Segmentation Task)
- (1)四种分割模式:提示的实例化
- (2)创新理念:从“交互模式”到“可提示任务”
- 5、数据引擎
- 二、注意事项(概念冲击)
- (1)输出 Mask 是几分类?
- (2)模型能否微调?
- (3)SAM与传统分割模型的本质区别
- (4)SAM版本(SAM1 + SAM2)与社区版本(FastSAM + MobileSAM + EfficientSAM)
- 三、项目实战
- 1、环境配置 —— 与SAM github官网教程一致
- (1)下载源码
- (2)下载模型权重
- (3)安装依赖环境 —— SAM支持GPU / CPU
- 2、函数详解(四种分割模式)
- 3、执行代码:run.py
- (1)点提示分割 —— 支持两种方式:鼠标点击 / 代码指定
- 【扩展】鼠标点击 —— 支持循环执行 + 支持多点输入
- 【扩展】鼠标点击 —— 支持循环执行 + 支持多点输入 + 目标提取 + 距离计算
- (2)框提示分割 —— 支持两种方式:鼠标框选 / 代码指定
- (3)掩码提示分割 —— 输入二值掩码,引导 SAM 细化或者修正分割结果。
- (4)全自动分割

一、SAM(Segment Anything Model) —— 致力于建立第一个图像分割基础模型(Foundation Model)
SAM模型(Segment Anything Model)是由Meta AI提出的一种通用图像分割模型,旨在实现对任何图像中任意物体的快速、高质量分割,具备极强的通用性和零样本能力。
支持零样本分割 + 只适用于2D图像分割
| 项目 | 内容 |
|---|---|
| 全称 | Segment Anything Model(SAM) |
| 发布方 | Meta AI(Facebook) |
| 发布时间 | 2023年4月 |
| 官方网站 | ① 官网首页:https://segment-anything.com ② 网端 Demo:点击图像区域生成分割掩码 —— 用户点击图像中的任意区域,即提供了输入Prompt,SAM将以此预测该区域对应的分割掩码 |
| 模型类型 | 基于 Vision Transformer(ViT)的视觉大模型 |
| 核心特点 | - 支持任意目标分割 - 支持多种输入提示:点、框、掩码、全自动 - 超大规模训练数据(SA-1B:1100万图像 + 10亿掩码),具备极强泛化能力 - 可输出多个候选掩码及置信度评分 |
| 模型组成 | 1. 图像编码器(Image Encoder):使用 ViT 对整幅图像提取全局特征,支持三种尺寸(vit_h / vit_l / vit_b) 2. 提示编码器(Prompt Encoder):将用户输入的点、框或掩码编码为向量 token,并与图像特征联合使用 3. 掩码解码器(Mask Decoder):融合图像特征与提示 token,生成精细掩码,可输出多个候选结果 |
| 分割模式 | - 点提示(Point):用户提供前景/背景点 - 框提示(Box):用户提供目标边界框 - 掩码提示(Mask):对已有掩码进行细化 - 全自动(Automatic):无需输入,由模型自动生成掩码 |
| 适用场景 | - 零样本分割任务- 数据集快速标注和批量图像处理 - 多目标、复杂背景下的精细分割 - 原型开发和快速实验 |
| 局限性 | - 原生仅支持二维图像输入,不直接处理 3D 数据或视频序列 - 高精度模型(vit_h)对显存要求高 |
1、项目背景
基于大规模网络数据集预训练的基础模型在自然语言处理(NLP)领域展现出强大的零样本(zero-shot)和少样本(few-shot)泛化能力。类似的理念正在推动计算机视觉的发展。尤其是视觉-语言模型如 CLIP 和 ALIGN,通过对比学习对齐图像与文本编码器,实现了对新视觉概念的零样本泛化。
SAM(Segment Anything Model)将这一理念引入图像分割领域,目标是开发一个可提示(promptable)的分割模型,能够在面对未见过的图像或目标时依然生成高质量分割掩码。其核心理念是利用灵活的提示(点、框、掩码或文本)实现广泛的下游分割任务,形成视觉基础模型。
2、核心任务设计
SAM 的预训练目标是可提示分割任务(Promptable Segmentation Task),其特点包括:
- 通用性:提示可以是点、框、掩码甚至文本,用于指定图像中要分割的内容。
- 交互性:模型能够即时生成分割掩码,支持实时迭代提示。
- 健壮性:在提示含糊或存在多目标的情况下,模型仍能生成合理掩码,支持自然处理歧义。
通过该任务,SAM 可以在训练过程中学习对广泛目标和多样化数据分布的泛化能力。
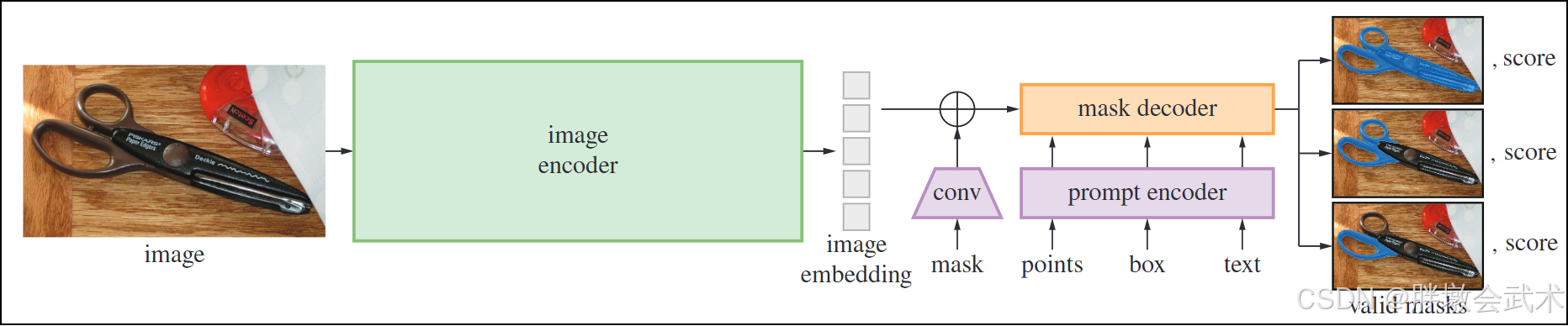
3、模型架构:图像编码器 + 提示编码器 + 掩码解码器
- 论文地址:Segment Anything
- 技术博客:Segment Anything 简介:致力于建立第一个图像分割基础模型
- github开源代码:facebookresearch / segment-anything
SAM由三部分组成:
- (1)图像编码器(Image Encoder):使用ViT(Vision Transformer)结构,对整幅图像进行特征编码
支持模型尺寸:
vit_h:最高精度,参数量最大vit_l:中等精度和参数量vit_b:轻量版本,速度快,适合小显存或快速实验- (2)提示编码器(Prompt Encoder):将用户输入的提示信息(Prompt)转化为token,并与图像特征联合使用
支持输入类型:
- 点:前景点 / 背景点
- 框:指定目标边界框
- 掩码:初始遮罩引导分割(mask refinement)
- 全自动:无需显式输入,由模型自动生成提示特征
- (3)掩码解码器(Mask Decoder):融合图像与提示token,生成精细分割结果
- 输入 =
图像特征 + 提示token- 输出 = 多个候选 mask(通常为 3 个),每个mask附带置信度评分,用于选择最优分割。
4、核心创新:可提示分割任务(Promptable Segmentation Task)
在自然语言处理 (NLP) 中,大规模语言模型通过下一个标记预测任务进行预训练,并借助提示工程 (prompt engineering)实现零样本和少样本迁移。受到这一理念的启发,SAM 将“提示”的概念引入图像分割,提出了可提示分割任务 (Promptable Segmentation)。
核心思想:给定任意提示(点、框、掩码、文本,甚至更复杂的输入),模型必须返回一个有效的分割蒙版。
- “有效”意味着即使提示存在歧义(例如:一件衬衫上的点,可能指代“衬衫”或“人”),模型也应输出至少一个合理的蒙版。
- 这种机制不仅能处理人工交互(点/框),还能作为更大系统的组件被调用,实现组合式智能。
与传统交互式分割不同,SAM 的目标不是仅在足够用户输入后才得到正确结果,而是始终对任意提示给出合理输出。
(1)四种分割模式:提示的实例化
在 SAM 中,提示被具体化为以下四种模式。它们既是用户直接使用的交互方式,也是“可提示分割”任务的训练与推理实例:
| 分割模式 | 输入提示 | 在“可提示分割”框架中的作用 |
|---|---|---|
| 点提示分割 | 前景点 / 背景点 | 最细粒度的提示,常用于交互式标注。通过前景点与背景点组合,模型学习在高度模糊的条件下输出合理 mask,增强其模糊感知与交互能力。 |
| 框提示分割 | 边界框 | 粗粒度空间提示,适用于快速标注。模型必须学会在不精确的定位下生成清晰目标边界,这种“粗到精”的泛化能力非常关键。 |
| 掩码提示分割 | 初始掩码 | 用于 refine(细化)已有分割,训练中确保模型能在已有结果基础上继续优化。这让模型在下游任务(如实例分割)中可作为可组合组件使用。 |
| 全自动分割 | 无提示 | 在无监督条件下自动生成候选 mask,支持批量标注和新任务探索。SAM 在训练中需学会“自举”掩码,从而支撑数据引擎(半自动 / 全自动标注)和大规模预训练。 |
(2)创新理念:从“交互模式”到“可提示任务”
| 创新点 | 说明 | 对应价值 |
|---|---|---|
| 预训练机制自然统一 | 训练时为图像随机生成多种提示(点、框、掩码),预测结果与真值掩码对齐;与传统交互式分割不同,SAM 始终需输出一个合理 mask,即使提示模糊或不完整。 | 迫使模型具备模糊感知能力,保证其在歧义提示下仍能稳定工作。 |
| 零样本迁移能力 | 下游任务都可被重新表述为“提示”:实例分割(框提示)、语义分割(点或掩码提示)、自动标注(规则点提示)等。 | 将分割任务统一到一个通用框架中,使 SAM 成为 通用分割基础模型,可直接迁移到新任务。 |
| 与基础模型的类比 | NLP 中 GPT 的“下一个词预测”,视觉中 CLIP 的“图文对齐”,分割中 SAM 的“可提示分割”,三者都通过单一预训练任务获得跨任务泛化能力。 | 强化了 SAM 作为 分割领域基础模型 的地位,证明其理念与大规模预训练模型的发展方向一致。 |
| 可组合性 | SAM 既可供人类交互使用,也能作为组件嵌入检测器、生成模型等系统,执行训练时未见过的新任务。 | 超越传统“多任务分割模型”的局限,实现 任务开放性 与 系统可扩展性,支持更大规模视觉应用生态的构建。 |
5、数据引擎
为实现对新数据分布的强泛化,
SAM 使用了自研的数据引擎(Data Engine)进行大规模掩码数据收集和增强:
- 辅助手动阶段:SAM 协助注释者生成掩码,提高标注效率。
- 半自动阶段:SAM 自动生成部分对象掩码,注释者只修正剩余区域。
- 全自动阶段:通过规则前景点网格提示,SAM 平均每幅图像生成约 100 个高质量掩码。
最终构建的数据集 SA-1B 包含来自 1100 万张图像的超过 10 亿个掩码,是现有分割数据集的数百倍,并经过质量验证,保证多样性和准确性。
二、注意事项(概念冲击)
(1)输出 Mask 是几分类?
- 全自动分割:输出结果为:多个 mask(候选掩码集合),每个 mask 没有具体语义标签 → 本质上是“无标签的多实例分割”。
- 点提示 / 框提示 / 掩码提示:输出结果为:1 个或多个 mask,每个 mask 只区分 前景 vs 背景(二分类)。不会直接给出类别名称,需要下游模型进一步识别。
(2)模型能否微调?
SAM 是一个庞大且难以直接迁移/微调的模型,但它具备极强的零样本分割能力。
在实际应用中,往往不会进行全量微调,而是通过 轻量化适配 或 作为通用掩码生成器 来使用。
📌 为什么 SAM 难以迁移 / 微调?
- 模型过大:参数规模数亿~十亿,显存与算力需求极高。全量 fine-tune 成本远超普通科研/工业条件。
- 预训练目标不同:SAM设计是“分割任何东西”,而不是某个特定类别,因此它输出的是掩码候选集,而不是语义标签。要迁移到下游语义分割/实例分割任务,还需要额外的分类头或判别器。
- 数据依赖:传统微调需要标注好的语义类别,而 SAM 的掩码并不自带语义标签,需要再构造数据集。
- 泛化特性强:SAM已经具备很强的零样本分割能力,往往不如在其上直接堆叠一个轻量模块(Adapter、LoRA)来适配任务,而不是全量微调。
📌 常见做法
- 不做全量微调:直接用 SAM 作为 “掩码生成器”,再接下游模型(如分类器、检测器)。
- 参数高效微调(PEFT):通过 LoRA、Adapter、Prompt Tuning 等方法,仅调节一小部分参数。
- 蒸馏或轻量化:一些研究尝试把 SAM 蒸馏到更小的模型,以便下游任务部署。
(3)SAM与传统分割模型的本质区别
【PyTorch项目实战】语义分割:U-Net、UNet++、U2Net
| 对比项 | SAM(Segment Anything) | 传统分割模型(如UNet、DeepLab) |
|---|---|---|
| 模型规模 | 数亿 ~ 十亿参数,Transformer结构 | 相对较小,CNN主导 |
| 输入形式 | 图像 + 提示(点、框、掩码、全自动) | 图像(无需交互) |
| 输出形式 | 交互式分割掩码,可提供多候选和置信度 | 语义标签图 |
| 训练数据 | SA-1B数据集:包含10亿个掩码和1100万图像 | 依赖有限数据集(如COCO、Pascal VOC) |
| 泛化能力 | 强,可跨领域/多模态提示 | 弱,依赖目标类别分布 |
| 应用范式 | 支持零样本迁移应用 | 需迁移训练 |
结论:SAM 属于类别无关的实例分割,可以独立分割图像中的每个目标实例,但不输出固定类别标签。
(4)SAM版本(SAM1 + SAM2)与社区版本(FastSAM + MobileSAM + EfficientSAM)
| 版本名称 | 发布时间 | 核心改动与特点 | 典型场景 | 链接 |
|---|---|---|---|---|
| SAM | 2023-04 | 原生通用分割模型。结构由三部分组成:**图像编码器(ViT-B/L/H)**实现图像特征提取;提示编码器支持点/框/掩码提示;掩码解码器生成高质量候选mask。基于 SA-1B 数据集(11M图像、10亿掩码)预训练,零样本跨领域泛化能力极强。支持多种输入提示(交互式点/框/掩码)和全自动生成mask。精度高、灵活性强,但推理速度和显存占用较高。 | 交互式分割、数据标注、图像编辑前景抠图 | 论文:arXiv:2304.02643; 代码:GitHub; 主页:segment-anything.com |
| SAM 2 | 2024-08 | 第二代 SAM,新增视频支持与记忆索引模块,可在长序列中保持提示和掩码信息,实现视频目标分割与跟踪。保持原有图像分割能力,同时提升时序一致性和交互效率。兼容原生点/框/掩码/全自动提示模式,支持视频帧间迁移和多目标跟踪。优化了长序列处理、缓存机制和视频显存占用。 | 视频目标分割/跟踪、视频编辑、长序列交互标注 | 论文:arXiv:2408.00714; 代码:GitHub; 主页:ai.meta.com/sam2 |
| SAM-HQ | 2023-06 | 高精度掩码版本,对边界和细节进行优化,尤其适合薄物体或复杂结构。保持原有输入提示模式(点/框/掩码/全自动),改进掩码解码器以提高边缘清晰度和细粒度精度,同时在保持零样本能力的前提下减少小目标丢失。训练采用高分辨率图像增强策略,提高边界拟合能力。 | 高精细抠图、工业缺陷标注 | 论文:arXiv:2306.01567 |
| TinySAM | 2023-12 | 轻量化版本,采用小型ViT编码器+简化解码器,显著降低显存和计算需求,适用于边缘端或算力受限设备。保持原有提示模式,但可能略牺牲细节精度。训练策略包含知识蒸馏与参数剪枝,保证小模型在速度与精度间取得平衡。 | 边缘端、低算力交互分割 | 论文:arXiv:2312.13789 |
| FastSAM | 2024-02 | 针对实时性优化,轻量化主干+加速解码器,实现接近实时提示分割。精度/速度折中优化,保持零样本能力,支持点/框/掩码/全自动输入。训练采用稀疏注意力和并行解码策略,降低延迟,适合批量自动标注或视频帧处理。 | 实时分割、批量自动标注 | 论文:arXiv:2306.14289 |
| MobileSAM | 2024-03 | 移动端优化版本,将ViT-H/L/B替换为轻量ViT或混合轻量化编码器,降低计算和显存消耗。兼容点/框/掩码/全自动模式,支持手机、嵌入式或低算力设备快速分割。采用深度可分离卷积、量化和轻量解码器策略,实现移动端可用。 | 手机/嵌入式交互分割、低成本部署 | 代码/主页:Mobile SAM |
| PerSAM | 2024-04 | 个性化适配版本,可在单张图像上快速生成专属分割,无需全量训练。通过轻量适配模块(Adapter)对预训练SAM进行微调,实现图像特定目标的高精度分割。保持原有提示输入方式,零样本基础上增强个性化目标识别能力。 | 个性化分割、快速适配 | 代码:GitHub |
| Grounded-SAM | 2024-01 | 融合 Grounding DINO 的文本检测能力,实现文本→检测→掩码的一站式开放集分割。支持文本驱动掩码生成,同时保留原生提示方式(点/框/掩码/全自动)。改进了提示编码器以接收文本向量并与图像特征联合,增强开放词汇分割能力。 | 文本驱动自动标注、开放词汇实例分割 | 论文:arXiv:2401.14159 |
| Grounded-SAM 2 | 2024-08 | 基于 SAM 2 的视频版本,结合 Grounding DINO 支持文本驱动的视频分割和跟踪。新增视频记忆模块和文本特征与帧间关联机制,实现多帧稳定文本掩码。保留全提示模式,增强跨帧一致性和开放词汇识别。 | 文本驱动的视频找物、跨帧跟踪与掩码生成 | 代码:GitHub |
| EfficientSAM | 2024-01 | 高效轻量化版本:通过 SAMI 预训练对轻量编码器(ViT-Tiny/Small)进行掩码重建;保持 SAM 精度的同时显著降低计算复杂度;在 COCO/LVIS 上性能提升约 4 AP;适用于边缘端或快速原型开发。 | 零样本实例分割、低资源部署、快速原型开发 | 论文:arXiv:2312.00863; 代码:GitHub; 主页:EfficientSAM |
| ISAT with SAM | 2024-05 | 交互式半自动标注工具,封装 SAM/SAM2,优化标注工作流。增加提示选择、掩码迭代优化和可视化功能,提升人工标注效率。适合多目标图像和批量标注场景。 | 数据标注、可控交互分割 | 代码:GitHub |
三、项目实战
1、环境配置 —— 与SAM github官网教程一致
(1)下载源码
# 虚拟环境配置:
conda create -n opennmt -y
conda activate opennmt
##################################################################
# 源码下载:
git clone https://github.com/facebookresearch/segment-anything.git
cd segment-anything
pip install -e .
参数说明:
-e / --editable:以可编辑模式 / 开发模式安装(editable mode),便于调试和自定义;.:指代当前目录,即含有 setup.py 或 pyproject.toml 的项目根目录。- 安装后可在代码中直接使用:
from segment_anything import sam_model_registry, SamPredictor
开发模式(editable mode)是什么?
- 普通安装(非 -e):
- 会把项目代码复制到 Python 的 site-packages 目录;
- 后续你对源码的修改不会生效,除非重新安装。
- 开发模式安装(-e):
- 不会复制代码;
- 会在 site-packages 中创建一个指向当前源码目录的链接(.egg-link);
- 所以你在编辑源码时,代码立即生效,无需重新安装。
这非常适合:本地开发调试、参与开源项目贡献代码、开发 CLI 工具或库
pip install -e . 是对旧命令 python setup.py develop 的替代,是更现代、推荐的做法。
(2)下载模型权重
SAM提供了三个模型权重供选择:
| 模型类型 | 权重文件 | 权重大小 | 下载地址(官方) | 适用场景 |
|---|---|---|---|---|
| ViT-H | sam_vit_h_4b8939.pth | ~2.5GB | 下载链接 | 精细分割、复杂场景、高精度需求 |
| ViT-L | sam_vit_l_0b3195.pth | ~1.0GB | 下载链接 | 中等精度分割,适合批量标注或普通实验 |
| ViT-B | sam_vit_b_01ec64.pth | ~375MB | 下载链接 | 小显存设备、快速实验、快速原型开发 |
下载后,建议放置在本地路径下,如:./models/sam_vit_h_4b8939.pth
project_root/
├── segment-anything/ # GitHub源码
├── models/
│ └── sam_vit_h_4b8939.pth
└── images/└── image.jpg
├── run.py # 主函数(详见下文)
(3)安装依赖环境 —— SAM支持GPU / CPU
Python 版本:
Python ≥ 3.8
必须依赖:pip install torch torchvision opencv-python matplotlib
可选依赖(用于交互式操作):pip install ipython scikit-image
2、函数详解(四种分割模式)
| 分割模式 | 输入提示 | 原理 | 实现方法 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|---|---|
| 点提示 | 前景点 / 背景点 | 用户提供少量点作为提示,编码器将点信息转换为向量,与图像特征结合,掩码解码器生成完整mask | predictor.predict(point_coords=input_point, point_labels=input_label, multimask_output=True) | 精确定位目标,灵活交互,可迭代优化 | 依赖点位置,点太少可能导致误分割 | 单目标或少量目标交互式分割,复杂背景下精细分割 |
| 框提示 | 边界框 | 用户提供目标的粗略框,编码为提示向量,与图像特征结合生成mask | predictor.predict(box=input_box, multimask_output=True) | 操作简单、快速生成mask,适合粗略标注 | 精度略低,框大小不合适会影响分割 | 批量标注目标,快速分割单个物体 |
| 掩码提示 | 初始mask | 输入已有mask,引导SAM生成改进或细化掩码,实现mask refinement | predictor.predict(mask_input=initial_mask, multimask_output=True) | 可迭代优化已有mask,精细控制目标边界 | 依赖初始mask质量,对新目标无法直接分割 | 对已有掩码精细优化,复杂形态目标分割,遮挡场景 |
| 全自动 | 无提示 | SAM扫描图像特征空间,自动生成候选目标mask,输出多个mask供选择 | mask_generator = SamAutomaticMaskGenerator(sam); masks = mask_generator.generate(image_rgb) | 零人工干预,可批量处理,快速生成多目标mask | 对小物体或复杂边界目标可能误分割 | 数据集自动标注、批量图像处理、多目标场景初步分割 |
SAM 模型权重与 model_type 对应如下:
sam_vit_b_01ec64.pth → model_type="vit_b" → 小显存或快速实验
sam_vit_l_0b3195.pth → model_type="vit_l" → 中等显存、精度要求一般
sam_vit_h_4b8939.pth → model_type="vit_h" → 高显存、复杂图像或精细分割"""#############################################################################################
# 函数功能:点提示分割(Point Prompt Segmentation)
# 基于用户指定的前景点/背景点生成候选掩码。
# 函数说明:predictor.predict(point_coords, point_labels, multimask_output=True)
# 参数说明:
# point_coords:np.ndarray, 形状为 (N, 2),每个点的坐标[y, x],N为点数。
# point_labels:np.ndarray, 形状为 (N,),点标签,1=前景,0=背景。
# multimask_output:bool,是否生成多个候选mask。
# - True(默认):生成 3 个候选mask
# - False:生成 1 个mask
# 返回值:
# masks:np.ndarray, 候选mask数组
# scores:每个mask的置信度
# logits:mask解码器原始输出
#############################################################################################""""""#############################################################################################
# 函数功能:框提示分割(Box Prompt Segmentation)
# 基于用户提供的目标边界框生成候选掩码。
# 函数说明:predictor.predict(box, multimask_output=True)
# 参数说明:
# box:np.ndarray, 形状为 (4,) 或 (x_min, y_min, x_max, y_max),目标边界框坐标。
# multimask_output:bool,是否生成多个候选mask。
# - True(默认):生成 3 个候选mask
# - False:生成 1 个mask
# 返回值:
# masks:np.ndarray, 候选mask数组
# scores:每个mask的置信度
# logits:mask解码器原始输出
#############################################################################################""""""#############################################################################################
# 函数功能:掩码提示分割(Mask Prompt Segmentation / Refinement)
# 基于已有mask进行优化或细化生成新的mask。
# 函数说明:predictor.predict(mask_input, multimask_output=True)
# 参数说明:
# mask_input:np.ndarray,已有初始mask,用于引导SAM refinement。
# multimask_output:bool,控制输出数量,但mask提示模式通常只返回1个优化mask。
# 返回值:
# masks:np.ndarray, refinement后的mask(通常1个)
# scores:每个mask的置信度
# logits:mask解码器原始输出
#############################################################################################""""""#############################################################################################
# 函数功能:全自动分割(Automatic Mask Generation)
# 扫描整个图像特征空间,自动生成候选目标mask。
# 函数说明:
# mask_generator = SamAutomaticMaskGenerator(sam)
# masks = mask_generator.generate(image)
# 参数说明:
# image:np.ndarray, RGB图像数组
# mask_generator 可选参数:
# pred_iou_thresh:float, mask置信度阈值,默认0.88
# stability_score_thresh:float, mask稳定性阈值,默认0.95
# min_mask_region_area:int, 最小mask面积,过滤小区域,默认100
# 返回值:
# masks:list[dict],每个dict包含:
# - 'segmentation':二值mask
# - 'bbox':mask边界框[x_min, y_min, x_max, y_max]
# - 'area':mask面积
#############################################################################################"""
3、执行代码:run.py
(1)点提示分割 —— 支持两种方式:鼠标点击 / 代码指定

#####################################################################################
# SAM点提示分割(支持两种方式:鼠标点击 / 代码指定)
# 功能:
# - 用户可以选择用鼠标在图像上点击前景点,或者直接在代码里指定点
# - 输出图像上显示指定的点(红色)和分割mask(半透明)
# 备注:人工指定需要提前知道目标位置
#####################################################################################import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号# -----------------------------
# 1. 配置模型
# -----------------------------
sam_checkpoint = "./models/sam_vit_h_4b8939.pth" # 模型权重路径
model_type = "vit_h" # 模型类型:vit_h / vit_l / vit_b
device = "cuda" if torch.cuda.is_available() else "cpu"# 加载模型
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)# -----------------------------
# 2. 加载图像
# -----------------------------
image_path = "./images/WD-5mm-1.png" # 图像路径
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 转为RGB
predictor.set_image(image_rgb)# -----------------------------
# 3. 获取点提示
# -----------------------------
def get_input_point(mode="click", preset_point=None):"""获取用户指定点mode:- "click": 用户鼠标点击选择点- "preset": 使用代码预设点preset_point: 预设点 (y, x),如 (250, 150)"""if mode == "click":clicked_point = []def onclick(event):if event.inaxes is not None:x, y = int(event.xdata), int(event.ydata)clicked_point.clear()clicked_point.append([y, x]) # SAM输入顺序为[y, x]plt.close()plt.figure(figsize=(10, 10))plt.imshow(image_rgb)plt.title("请用鼠标点击一个前景点")cid = plt.gcf().canvas.mpl_connect('button_press_event', onclick)plt.axis('off')plt.show()if not clicked_point:raise RuntimeError("未检测到点击点,请重新运行并点击图像。")return np.array(clicked_point), np.array([1])elif mode == "preset":if preset_point is None:raise ValueError("preset模式需要提供 preset_point=(y, x)")return np.array([preset_point]), np.array([1])else:raise ValueError("mode 必须是 'click' 或 'preset'")# -----------------------------
# 4. 选择点提示方式
# -----------------------------
# 方法1:鼠标点击
input_point, input_label = get_input_point(mode="click")# 方法2:代码指定
# input_point, input_label = get_input_point(mode="preset", preset_point=(250, 150)) # (y, x)# -----------------------------
# 5. 预测mask
# -----------------------------
masks, scores, logits = predictor.predict(point_coords=input_point,point_labels=input_label,multimask_output=True # 返回多个候选mask
)# -----------------------------
# 6. 可视化
# -----------------------------
plt.figure(figsize=(10, 10))
plt.imshow(image_rgb)
plt.imshow(masks[0], alpha=0.5, cmap='jet') # 叠加mask
plt.scatter(input_point[:, 1], input_point[:, 0], color='red', s=100) # 显示点击点
plt.axis('off')
plt.title("SAM点提示分割")
plt.show()
【扩展】鼠标点击 —— 支持循环执行 + 支持多点输入
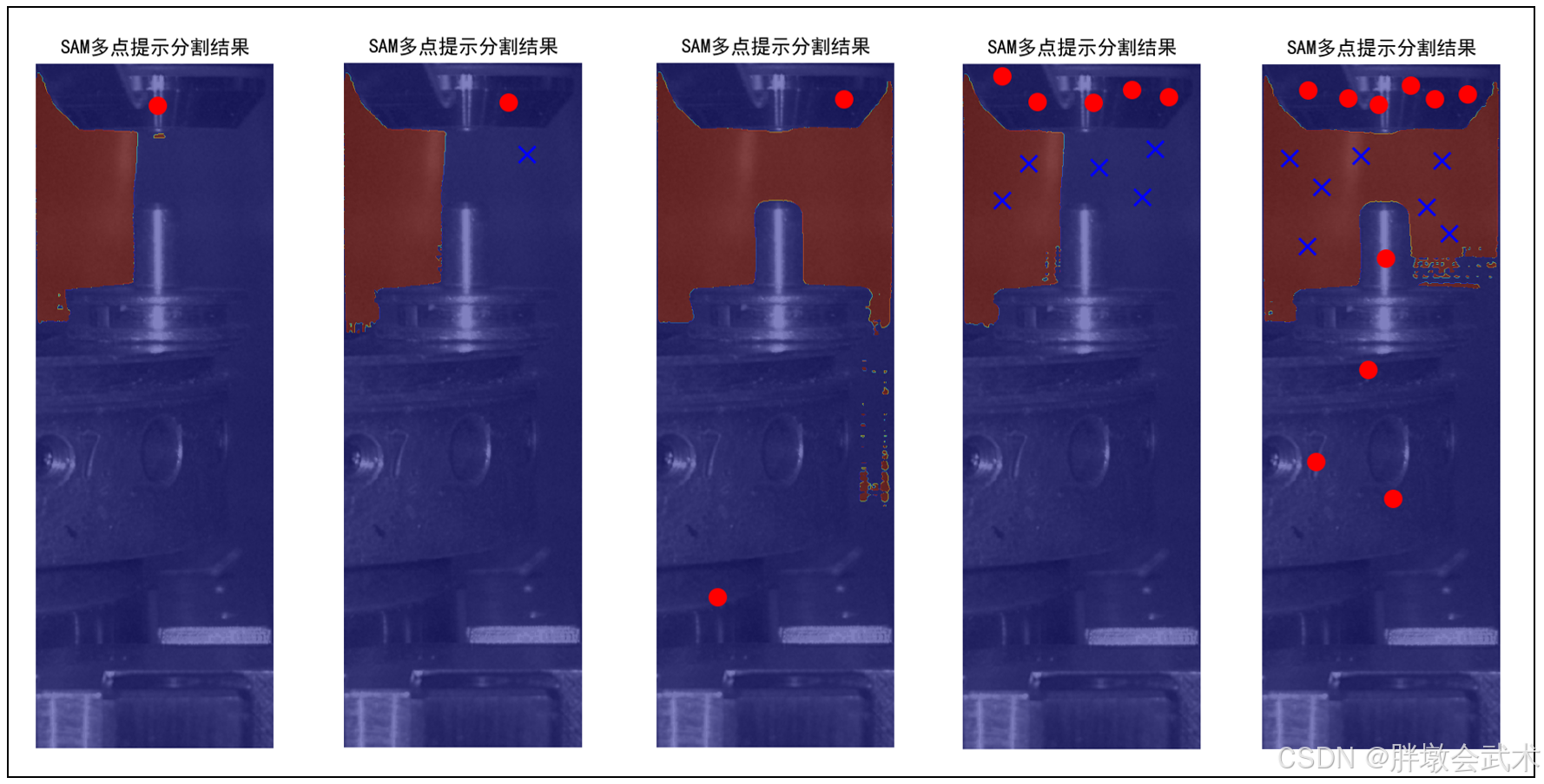
点提示分割:支持同时提供多个前景点(label=1)或背景点(label=0),帮助模型更好锁定目标范围。
#####################################################################################
# SAM点提示分割(支持多点输入:左键前景 / 右键背景)
# 功能:
# - 用户在图像上点击多个点:
# 左键 = 前景点(红色)
# 右键 = 背景点(蓝色)
# - 关闭点击窗口后,执行一次分割并可视化结果
# - 循环执行,直到用户 Ctrl+C 退出
#####################################################################################import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文正常显示
plt.rcParams['axes.unicode_minus'] = False # 负号正常显示# -----------------------------
# 1. 配置模型
# -----------------------------
sam_checkpoint = "./models/sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda" if torch.cuda.is_available() else "cpu"sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)# -----------------------------
# 2. 加载图像
# -----------------------------
image_path = "./images/WD-5mm-1.png"
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image_rgb)# -----------------------------
# 3. 点击多点 + 分割
# -----------------------------
def get_click_points():"""获取用户点击的多个点 (左键=前景, 右键=背景)"""points, labels = [], []def onclick(event):if event.inaxes is not None:x, y = int(event.xdata), int(event.ydata)if event.button == 1: # 左键 → 前景points.append([y, x])labels.append(1)plt.scatter(x, y, color='red', s=80, marker='o')elif event.button == 3: # 右键 → 背景points.append([y, x])labels.append(0)plt.scatter(x, y, color='blue', s=80, marker='x')plt.draw()fig, ax = plt.subplots(figsize=(10, 10))ax.imshow(image_rgb)ax.set_title("左键=前景(红),右键=背景(蓝),关闭窗口确认")cid = fig.canvas.mpl_connect('button_press_event', onclick)plt.axis('off')plt.show()if not points:return None, Nonereturn np.array(points), np.array(labels)# -----------------------------
# 4. 循环分割
# -----------------------------
while True:try:input_points, input_labels = get_click_points()if input_points is None:print("未点击任何点,退出循环。")break# SAM预测masks, scores, logits = predictor.predict(point_coords=input_points,point_labels=input_labels,multimask_output=True)# 可视化plt.figure(figsize=(10, 10))plt.imshow(image_rgb)plt.imshow(masks[0], alpha=0.5, cmap='jet')# 前景点红色,背景点蓝色for (y, x), lbl in zip(input_points, input_labels):if lbl == 1:plt.scatter(x, y, color='red', s=100, marker='o')else:plt.scatter(x, y, color='blue', s=100, marker='x')plt.axis('off')plt.title("SAM多点提示分割结果")plt.show()except KeyboardInterrupt:print("用户手动退出。")break【扩展】鼠标点击 —— 支持循环执行 + 支持多点输入 + 目标提取 + 距离计算

#####################################################################################
# SAM点提示分割(支持多点输入:左键前景 / 右键背景)
# 功能:
# - 用户在图像上点击多个点:
# 左键 = 前景点(红色)
# 右键 = 背景点(蓝色)
# - 关闭点击窗口后,执行一次分割并可视化所有分割结果(mask)
# - 计算第一个mask中的两个最大背景连通域面积,并计算其y轴距离并标注
# - 循环执行,直到用户 Ctrl+C 退出 或 不点击任何点
#####################################################################################import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文正常显示
plt.rcParams['axes.unicode_minus'] = False # 负号正常显示# -----------------------------
# 1. 配置模型
# -----------------------------
sam_checkpoint = "./models/sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda" if torch.cuda.is_available() else "cpu"sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)# -----------------------------
# 2. 加载图像
# -----------------------------
image_path = "./images/WD-5mm.png"
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image_rgb)# -----------------------------
# 3. 点击多点 + 分割
# -----------------------------
def get_click_points():"""获取用户点击的多个点 (左键=前景, 右键=背景)"""points, labels = [], []def onclick(event):if event.inaxes is not None:x, y = int(event.xdata), int(event.ydata)if event.button == 1: # 左键 → 前景points.append([y, x])labels.append(1)plt.scatter(x, y, color='red', s=80, marker='o')elif event.button == 3: # 右键 → 背景points.append([y, x])labels.append(0)plt.scatter(x, y, color='blue', s=80, marker='x')plt.draw()fig, ax = plt.subplots(figsize=(10, 10))ax.imshow(image_rgb)ax.set_title("左键=前景(红),右键=背景(蓝),关闭窗口确认")cid = fig.canvas.mpl_connect('button_press_event', onclick)plt.axis('off')plt.tight_layout()plt.show()if not points:return None, Nonereturn np.array(points), np.array(labels)# -----------------------------
# 4. 循环分割
# -----------------------------
while True:try:input_points, input_labels = get_click_points()if input_points is None:print("未点击任何点,退出循环。")break# SAM预测masks, scores, logits = predictor.predict(point_coords=input_points,point_labels=input_labels,multimask_output=True)mask = masks[0] # 只取第一个mask# 将x的前30和后30像素置为1(前景点),避免边缘像素干扰center = int(mask.shape[1]/2) # 取x轴中心mask[:, :center - 50] = 1 # mask[:, :30] = 1 ———— 过宽mask[:, center + 50:] = 1 # mask[:, -30:] = 1print(f"mask尺寸:{mask.shape}")# 可视化分割结果plt.figure(figsize=(10, 10))plt.imshow(image_rgb)plt.imshow(mask, alpha=0.5, cmap='spring')plt.title(f"分割结果")plt.axis('off')plt.tight_layout()plt.show()# 计算背景区域(mask==0)的连通域background = (mask == 0).astype(np.uint8)num_bg_labels, bg_labels_im = cv2.connectedComponents(background)bg_areas = []for label in range(1, num_bg_labels): # label=0是背景area = np.sum(bg_labels_im == label)bg_areas.append((label, area))if len(bg_areas) < 2:print("背景连通区域不足两个,无法计算。")continue# 按面积排序,取最大的两个bg_areas_sorted = sorted(bg_areas, key=lambda x: x[1], reverse=True)largest_bg = bg_areas_sorted[0]second_largest_bg = bg_areas_sorted[1]print(f"最大背景连通域面积: {largest_bg[1]} 像素, 标签: {largest_bg[0]}")print(f"第二大背景连通域面积: {second_largest_bg[1]} 像素, 标签: {second_largest_bg[0]}")# 计算两个最大背景区域的y轴距离# 获取最大和第二大背景区域的y坐标范围largest_bg_mask = (bg_labels_im == largest_bg[0])second_largest_bg_mask = (bg_labels_im == second_largest_bg[0])# 最大背景区域y范围largest_ys, largest_xs = np.where(largest_bg_mask)if len(largest_ys) == 0:print("最大背景区域无像素,跳过。")continuelargest_ymin = np.min(largest_ys)largest_ymax = np.max(largest_ys)# 第二大背景区域y范围second_ys, second_xs = np.where(second_largest_bg_mask)if len(second_ys) == 0:print("第二大背景区域无像素,跳过。")continuesecond_ymin = np.min(second_ys)second_ymax = np.max(second_ys)# 按ymin排序,确定上下if largest_ymin < second_ymin:upper_ymax = largest_ymaxupper_mask = largest_bg_masklower_ymin = second_yminlower_mask = second_largest_bg_maskelse:upper_ymax = second_ymaxupper_mask = second_largest_bg_masklower_ymin = largest_yminlower_mask = largest_bg_mask# 计算y轴距离(下区域的ymin - 上区域的ymax)y_distance = lower_ymin - upper_ymax# 取上区域ymax行的所有x,取平均作为标注点xupper_xs = np.where(upper_mask[upper_ymax, :])[0]if len(upper_xs) == 0:upper_x = image_rgb.shape[1] // 2else:upper_x = int(np.mean(upper_xs))# 取下区域ymin行的所有x,取平均作为标注点xlower_xs = np.where(lower_mask[lower_ymin, :])[0]if len(lower_xs) == 0:lower_x = image_rgb.shape[1] // 2else:lower_x = int(np.mean(lower_xs))# 可视化两个最大背景区域及距离,采用前景的可视化方式plt.figure(figsize=(10, 10))plt.imshow(image_rgb)# 叠加两个区域plt.imshow(upper_mask, alpha=0.5, cmap='Reds')plt.imshow(lower_mask, alpha=0.5, cmap='Blues')# 标注两个点plt.scatter(upper_x, upper_ymax, color='yellow', s=120, marker='^', label='上缘')plt.scatter(lower_x, lower_ymin, color='cyan', s=120, marker='v', label='下缘')# plt.text(upper_x+5, upper_ymax-5, f"上缘({upper_x},{upper_ymax})", color='yellow', fontsize=12, va='bottom')# plt.text(lower_x+5, lower_ymin+5, f"下缘({lower_x},{lower_ymin})", color='cyan', fontsize=12, va='top')# 在两点之间标注y轴距离mid_x = int((upper_x + lower_x) / 2)mid_y = int((upper_ymax + lower_ymin) / 2)plt.plot([upper_x, lower_x], [upper_ymax, lower_ymin], color='lime', linestyle='--', linewidth=2)plt.text(mid_x+10, mid_y, f"Δy={y_distance}px", color='lime', fontsize=16, weight='bold', va='center')plt.axis('off')plt.title("最大两个背景连通域的y轴距离")# plt.legend(loc='upper right')plt.tight_layout()plt.show()except KeyboardInterrupt:print("用户手动退出。")break(2)框提示分割 —— 支持两种方式:鼠标框选 / 代码指定

#####################################################################################
# SAM框提示分割(支持两种方式:鼠标框选 / 代码指定)
# 功能:
# - 用户可以选择用鼠标在图像上框选目标,或者直接在代码里指定一个框
# - 输出图像上显示框和分割mask(半透明)
# 备注:人工指定需要提前知道目标位置
#####################################################################################import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号# -----------------------------
# 1. 配置模型
# -----------------------------
sam_checkpoint = "./models/sam_vit_h_4b8939.pth" # 模型权重路径
model_type = "vit_h" # 模型类型:vit_h / vit_l / vit_b
device = "cuda" if torch.cuda.is_available() else "cpu"# 加载模型
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)# -----------------------------
# 2. 加载图像
# -----------------------------
image_path = "./images/WD-5mm-1.png" # 图像路径
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 转为RGB
predictor.set_image(image_rgb)# -----------------------------
# 3. 获取框提示
# -----------------------------
def get_input_box(mode="drag", preset_box=None):"""获取用户指定框mode:- "drag": 鼠标框选(交互)- "preset": 使用代码预设框preset_box: 预设框 [x_min, y_min, x_max, y_max]"""if mode == "drag":box = []def onselect(eclick, erelease):x1, y1 = int(eclick.xdata), int(eclick.ydata)x2, y2 = int(erelease.xdata), int(erelease.ydata)box.clear()box.extend([min(x1, x2), min(y1, y2), max(x1, x2), max(y1, y2)])plt.close()from matplotlib.widgets import RectangleSelectorfig, ax = plt.subplots(figsize=(10, 10))ax.imshow(image_rgb)ax.set_title("请用鼠标框选一个区域")toggle_selector = RectangleSelector(ax, onselect, useblit=True,button=[1], minspanx=5, minspany=5,interactive=True)plt.axis('off')plt.show()if not box:raise RuntimeError("未检测到框,请重新运行并框选目标。")return np.array(box)elif mode == "preset":if preset_box is None:raise ValueError("preset模式需要提供 preset_box=[x_min, y_min, x_max, y_max]")return np.array(preset_box)else:raise ValueError("mode 必须是 'drag' 或 'preset'")# -----------------------------
# 4. 选择框提示方式
# -----------------------------
# 方法1:鼠标拖拽框选
input_box = get_input_box(mode="drag")# 方法2:代码指定框
# input_box = get_input_box(mode="preset", preset_box=[100, 100, 400, 400]) # [x_min, y_min, x_max, y_max]# -----------------------------
# 5. 预测mask
# -----------------------------
masks, scores, logits = predictor.predict(box=input_box,multimask_output=True # 返回多个候选mask
)# -----------------------------
# 6. 可视化
# -----------------------------
plt.figure(figsize=(10, 10))
plt.imshow(image_rgb)
# 叠加mask
plt.imshow(masks[0], alpha=0.5, cmap='jet')
# 画出框
x0, y0, x1, y1 = input_box
rect = plt.Rectangle((x0, y0), x1 - x0, y1 - y0, edgecolor='red', facecolor='none', linewidth=2)
plt.gca().add_patch(rect)
plt.axis('off')
plt.title("SAM框提示分割")
plt.show()
(3)掩码提示分割 —— 输入二值掩码,引导 SAM 细化或者修正分割结果。

#####################################################################################
# SAM掩码提示分割(Mask Prompt)
# 功能:
# - 先生成一个初始掩码(例如:简单阈值分割 / 手动设定)
# - 将该掩码输入 SAM,作为提示,引导 SAM 输出更精细的分割结果
# 注意:
# - 掩码提示一般用于“细化已有分割结果”,而不是从零开始
#####################################################################################import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictorplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# -----------------------------
# 工具函数:统一掩码格式
# -----------------------------
def format_mask_for_sam(mask, device="cpu"):"""将 numpy 或 tensor 掩码转成 SAM 所需格式 [1,256,256] logits- mask: numpy/tensor, shape = (H,W) or (1,H,W)"""if isinstance(mask, np.ndarray):mask = torch.from_numpy(mask)if mask.dim() == 2: # (H,W)mask = mask.unsqueeze(0) # [1,H,W]elif mask.dim() == 3 and mask.shape[0] == 1: # [1,H,W]passelse:raise ValueError(f"掩码维度不符合要求: {mask.shape}, 需要 (H,W) 或 (1,H,W)")# 缩放到 256x256mask_resized = torch.nn.functional.interpolate(mask.unsqueeze(0), # [1,1,H,W]size=(256, 256),mode="bilinear",align_corners=False).squeeze(0) # [1,256,256]# 转 logits(增强分离度)mask_logits = (mask_resized - 0.5) * 20.0return mask_logits.to(device=device, dtype=torch.float32)# -----------------------------
# 1. 配置模型
# -----------------------------
sam_checkpoint = "./models/sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda" if torch.cuda.is_available() else "cpu"sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)# -----------------------------
# 2. 加载图像
# -----------------------------
image_path = "./images/WD-5mm-1.png"
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image_rgb)# -----------------------------
# 3. 生成一个粗分割mask (例子:阈值法)
# -----------------------------
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, rough_mask = cv2.threshold(gray, 128, 1, cv2.THRESH_BINARY) # [0,1]
rough_mask = rough_mask.astype(np.float32)# 转成 SAM 所需格式
mask_input = format_mask_for_sam(rough_mask, device=device)
print("mask_input.shape =", mask_input.shape) # 应该是 [1,256,256]# -----------------------------
# 4. 使用掩码提示进行预测
# -----------------------------
masks, scores, logits = predictor.predict(mask_input=mask_input, # 掩码提示multimask_output=True # 返回多个候选
)# -----------------------------
# 5. 可视化
# -----------------------------
plt.figure(figsize=(18, 6))# 原图
plt.subplot(1, 3, 1)
plt.imshow(image_rgb)
plt.title("原图")
plt.axis('off')# 粗分割mask
plt.subplot(1, 3, 2)
plt.imshow(image_rgb)
plt.imshow(rough_mask, alpha=0.5, cmap="gray")
plt.title("初始粗分割mask")
plt.axis('off')# SAM优化后的mask(显示第一个候选)
plt.subplot(1, 3, 3)
plt.imshow(image_rgb)
plt.imshow(masks[0], alpha=0.5, cmap="jet")
plt.title("SAM掩码提示分割结果(候选1)")
plt.axis('off')plt.show()# -----------------------------
# 6. 打印多个候选分割的得分
# -----------------------------
for i, score in enumerate(scores):print(f"候选 {i+1}: 得分 = {score:.4f}")
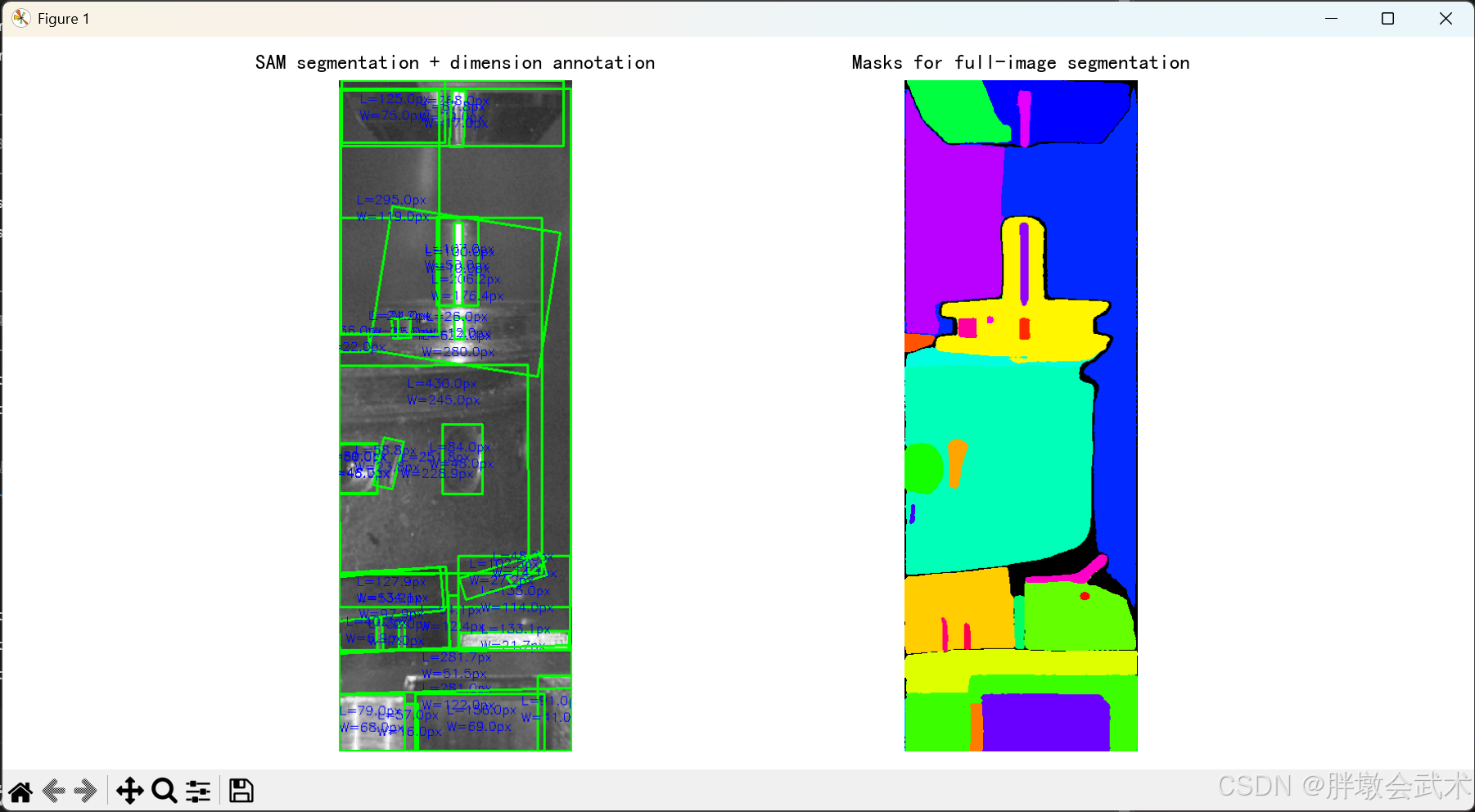
(4)全自动分割
import cv2
import numpy as np
import matplotlib.pyplot as plt
import torch
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator
from PIL import Image
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号# Step 1:读取图像
image_path = r"D:\py\CCD\WD-5mm-1.png"
image = cv2.imread(image_path)
if image is None:raise FileNotFoundError("图像文件未正确加载,请检查路径。")
######################################################################################
# Step 2:加载 SAM 模型
sam_checkpoint = r"models/sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device)
######################################################################################
# Step 3:使用自动Mask生成器进行全图分割
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image) # 每个元素是一个 dict,含mask、bbox、area等
######################################################################################
# Step 4:绘制分割轮廓并计算尺寸
annotated = image.copy()for mask_info in masks:mask = mask_info["segmentation"].astype(np.uint8)contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)for cnt in contours:if cv2.contourArea(cnt) < 100: # 过滤小目标continuerect = cv2.minAreaRect(cnt)box = cv2.boxPoints(rect)box = np.round(box).astype(np.intp)cv2.drawContours(annotated, [box], 0, (0, 255, 0), 2)(x, y), (w, h), angle = rectlength = max(w, h)width = min(w, h)cv2.putText(annotated, f"L={length:.1f}px", (int(x-40), int(y-10)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 1)cv2.putText(annotated, f"W={width:.1f}px", (int(x-40), int(y+10)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 1)# Step 5:可视化所有掩码(overlay图)
overlay = np.zeros_like(image)
colors = plt.cm.get_cmap('hsv', len(masks)+1)for i, m in enumerate(masks):mask = m["segmentation"]color = np.array(colors(i)[:3]) * 255overlay[mask] = color.astype(np.uint8)# Step 6:显示结果
annotated = cv2.cvtColor(annotated, cv2.COLOR_BGR2RGB)
overlay = cv2.cvtColor(overlay, cv2.COLOR_BGR2RGB)plt.figure(figsize=(12, 6))plt.subplot(1, 2, 1)
plt.imshow(annotated)
plt.title("SAM segmentation + dimension annotation")
plt.axis('off')plt.subplot(1, 2, 2)
plt.imshow(overlay)
plt.title("Masks for full-image segmentation")
plt.axis('off')plt.tight_layout()
plt.show()


)




)

-解决CRC校验错误)


 | 文件基本属性与链接扩展)
)
![[机械结构设计-48]:机械工程师的岗位要求](http://pic.xiahunao.cn/[机械结构设计-48]:机械工程师的岗位要求)



》人民邮电出版社,李云清杨庆红等,2023年8月)