一、简介
Ovis2.5 旨在实现原生分辨率的视觉感知和增强的多模态推理。它集成了一个原生分辨率的视觉变换器(NaViT),可以处理原始、可变分辨率的图像,消除了固定分辨率切片的需要,并保留了精细细节和全局布局——这对于图表和图示等视觉密集型内容至关重要。
为了加强推理能力,Ovis2.5 不仅在链式思维(CoT)上进行了训练,还加入了反思性推理,包括自我检查和修订。 这种高级功能在推理时作为可选的 思考模式 提供,使用户能够在复杂输入上以延迟换取更高的准确性。
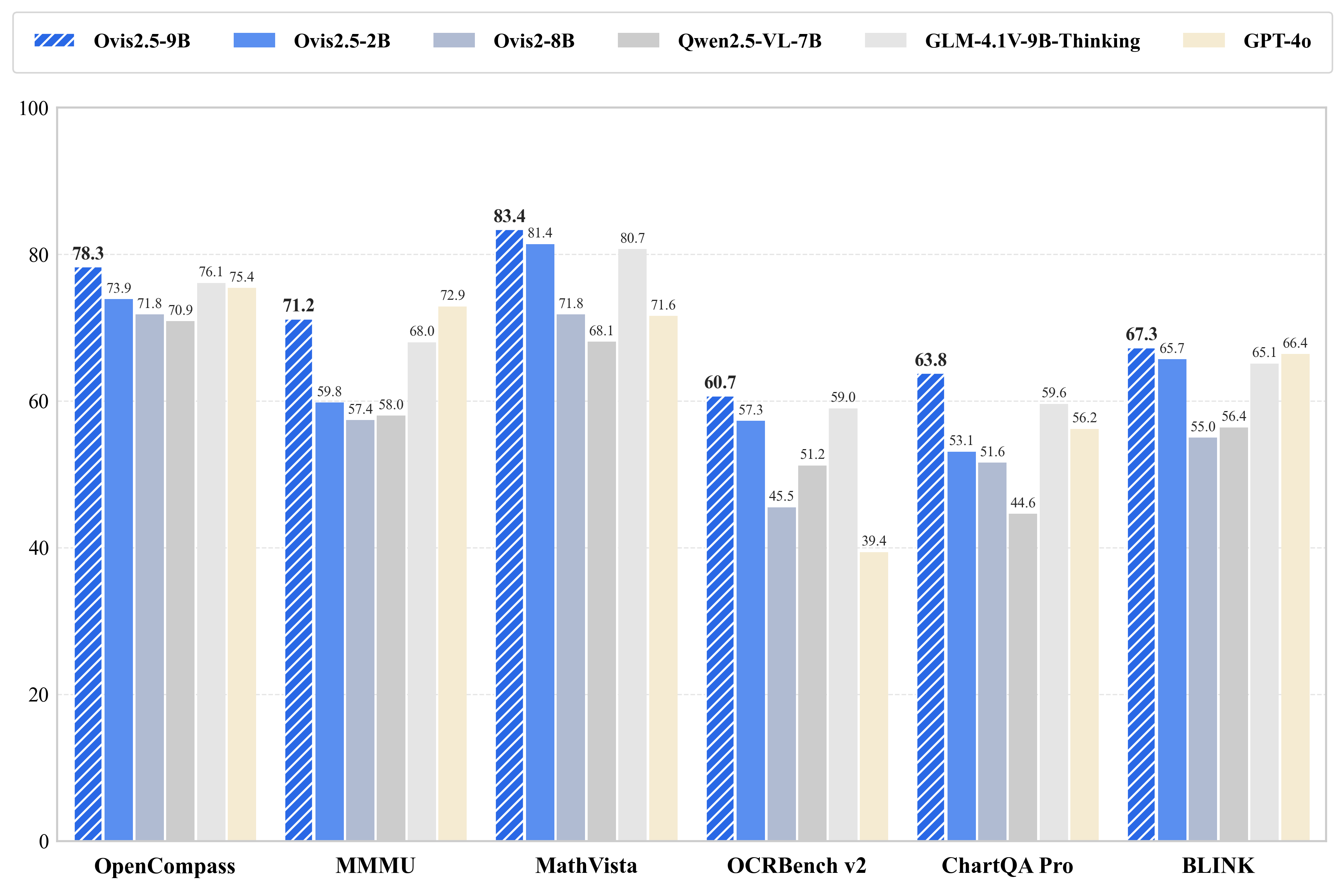
Ovis2.5-9B 在 OpenCompass 多模态评估套件中达到了 78.3 的平均得分(在参数少于 40B 的开源 MLLM 中处于 SOTA 水平),而轻量级的 Ovis2.5-2B 则得分为 73.9,延续了“小模型,大性能”的理念,适用于资源受限的场景。
二、环境部署
1.基础环境
4090*2,Ubuntu:22.04,cuda12.4.1
注:处理视频或者是大尺寸图像时,需要两张显卡;
2.使用vllm 推理
创建环境:
conda create -n ovis python=3.12 -y
conda activate ovis
安装vllm:
git clone https://github.com/vllm-project/vllm.git
cd vllm
VLLM_USE_PRECOMPILED=1 pip install .
3.模型下载
从 modelscope 下载模型:
modelscope download --model AIDC-AI/Ovis2.5-9B --local_dir ./AIDC-AI/Ovis2.5-9B
通过软链接从数据社区调用模型:
ln -s /root/sj-data/LargeModel/TextGeneration/AIDC-AI/Ovis2.5-9B/ /Ovis2.5-9B
4.vLLM 推理使用
vllm serve Ovis2.5-9B/ --trust-remote-code --served-model-name Ovis2.5-9B --tensor-parallel-size 2 --max-model-len 40960 --max-num-seqs 100
5.open-webui 使用模型
安装open-webui
pip install open-webui
启动open-webui,先在其它窗口启动 vllm
export HF_ENDPOINT=https://hf-mirror.com
export ENABLE_OLLAMA_API=False
export OPENAI_API_BASE_URL=http://127.0.0.1:8000/v1
export DEFAULT_MODELS="Ovis2.5-9B"
open-webui serve
第一次登录需要注册账号,邮箱随便填。
注:如果忘记账号密码导致无法登入界面,可以删除账号信息,选择重新注册:
(1)点击文件管理,输入 /root/miniconda3/lib/python3.12/site-packages/open_webui/data 的路径并进入
(2)删除 webui.db 这个文件,然后重新启动即可
注:只能输入图片识别,不能输入视频识别;
6.自定义webui
调用vllm 启动的模型服务接口实现:
主要实现以下功能:
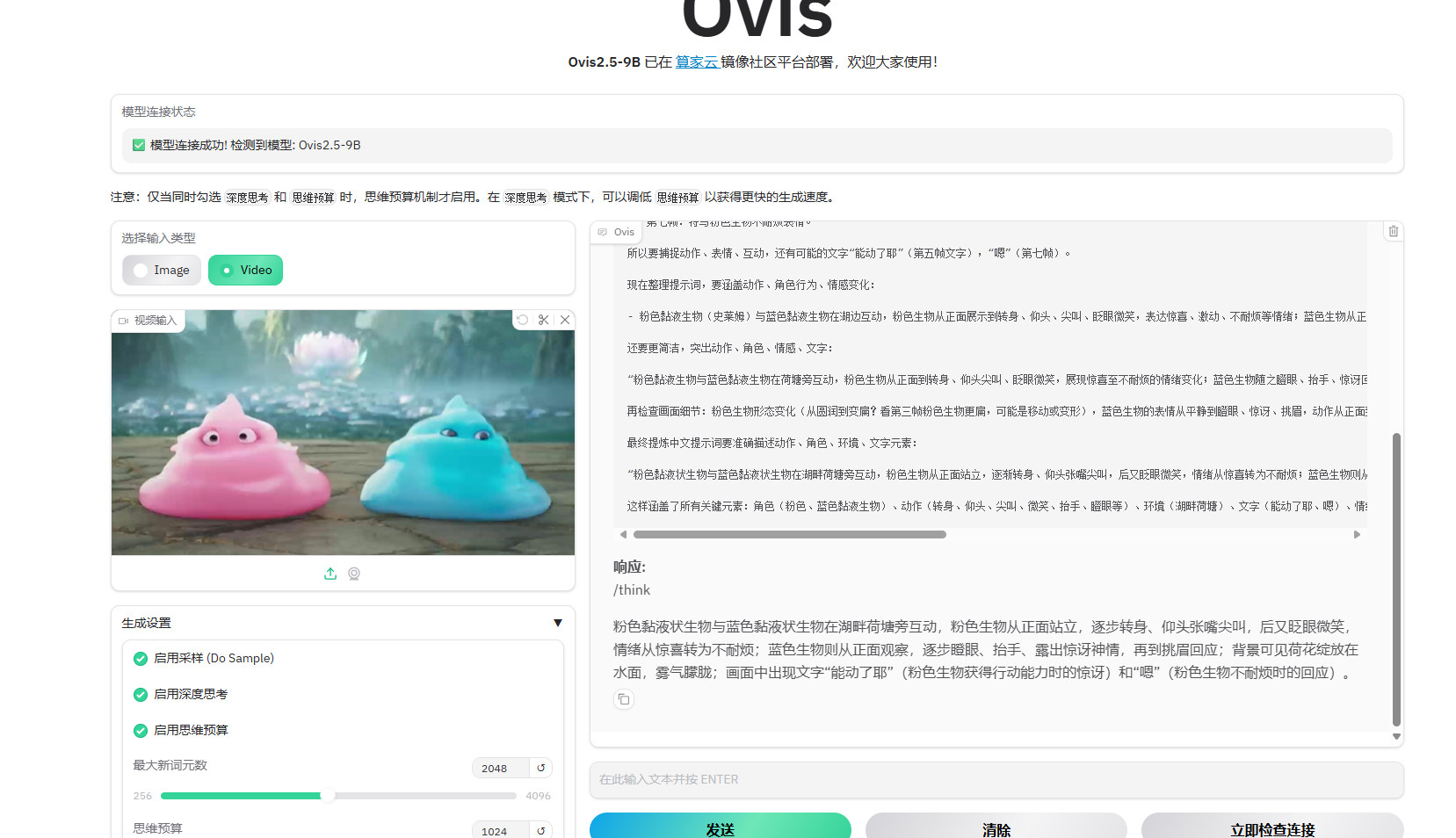
- 通过openai 接口调用vllm 服务,实现图像和视频输入(以关键帧的形式);
- 输入视频时对于关键帧的调整,默认是自动根据视频时长调整关键帧数;
- 模型连接状态展示。
三、错误及解决
1.缺少依赖 flash_attn
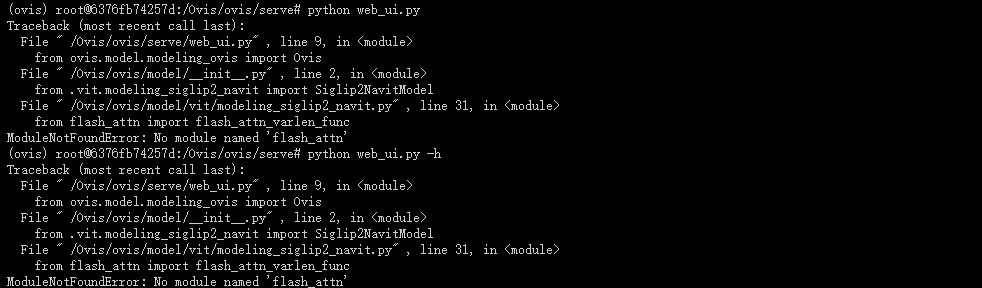
解决方法:
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.0.post2/flash_attn-2.7.0.post2+cu12torch2.4cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
pip install flash_attn-2.7.0.post2+cu12torch2.4cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
2.PyTorch 版本和 flash-attention 库兼容性问题
这个错误 AttributeError: module 'torch.library' has no attribute 'wrap_triton' 通常表明您使用的 PyTorch 版本和 flash-attention 库(特别是其 Triton 操作)之间存在 兼容性问题 。
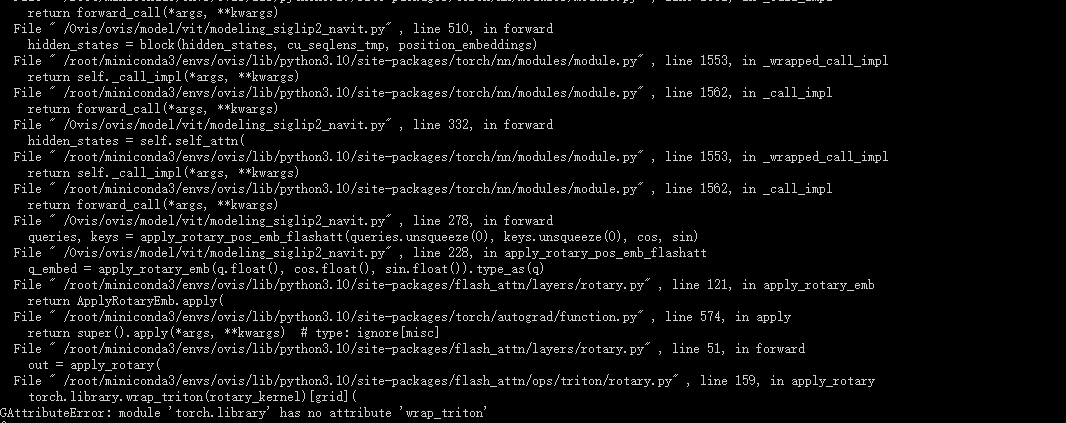
解决方法:安装兼容版本,torch==2.4.0 时,安装的 flash_attn-2.7.0.post2
四、自定义webui 源码
import subprocess
# subprocess.run('pip install flash-attn==2.7.0.post2 --no-build-isolation', env={'FLASH_ATTENTION_SKIP_CUDA_BUILD': "TRUE"}, shell=True)import spacesimport argparse
import os
import re
import logging
import tempfile
import shutil
from typing import List, Optional, Tuple, Generator
from threading import Thread
from openai import OpenAI
import requests
import timeimport gradio as gr
import PIL.Image
import torch
import numpy as np
from moviepy import VideoFileCliplogging.getLogger("httpx").setLevel(logging.WARNING)
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# --- OpenAI客户端配置 ---
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1" # 修改为你的API服务器地址client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)# 这应指向包含你的 SVG 文件的目录。
CUR_DIR = os.path.dirname(os.path.abspath(__file__))# --- 模型连接状态检查 ---
def check_model_connection():"""检查模型API是否可用,返回状态和消息"""try:# 增加超时时间,模型启动初期可能响应较慢response = requests.get(f"{openai_api_base}/models", timeout=15)if response.status_code == 200:models = response.json().get("data", [])for model in models:if "Ovis" in model.get("id", ""):return True, f"✅ 模型连接成功! 检测到模型: {model.get('id')}"return True, "✅ API服务器连接成功,但未检测到Ovis模型"elif response.status_code == 503:return False, "⏳ 服务暂时不可用,模型正在启动中,请稍候..."else:return False, f"❌ API服务器返回错误: {response.status_code},模型正在启动中"except requests.exceptions.ConnectionError:return False, "⏳ 无法连接到服务器,模型正在启动中,请稍候..."except requests.exceptions.Timeout:return False, "⏳ 连接超时,模型正在初始化,请稍候..."except Exception as e:return False, f"⚠️ 连接异常: {str(e)},模型正在启动中"def update_connection_status_periodically(status_box, interval=5):"""定期更新连接状态,interval为检查间隔(秒)"""while True:# 先显示检查中状态status, msg = False, "🔍 正在检查模型连接..."status_box.update(value=msg)# 实际检查连接status, msg = check_model_connection()status_box.update(value=msg)# 等待指定间隔后再次检查time.sleep(interval)# --- 聊天和推理功能 ---
def submit_chat(chatbot, text_input):# Ensure chatbot is a list of tuples (user, assistant)if not chatbot:chatbot = []# Add user message and empty assistant responsechatbot.append((text_input, ""))return chatbot, ''# --- 辅助函数 ---
latex_delimiters_set = [{"left": "\\(","right": "\\)","display": False},{"left": "\\begin{equation}","right": "\\end{equation}","display": True},{"left": "\\begin{align}","right": "\\end{align}","display": True},{"left": "\\begin{alignat}","right": "\\end{alignat}","display": True},{"left": "\\begin{gather}","right": "\\end{gather}","display": True},{"left": "\\begin{CD}","right": "\\end{CD}","display": True},{"left": "\\[","right": "\\]","display": True}
]def check_video_integrity(file_path):"""检查视频文件完整性"""try:file_size = os.path.getsize(file_path)if file_size == 0:return False, "文件大小为0,可能已损坏"# 检查文件头with open(file_path, 'rb') as f:header = f.read(100)# 检查是否是有效的视频文件if b'ftyp' not in header and b'moov' not in header and b'mdat' not in header:return False, "文件头不匹配,可能不是有效的MP4文件"return True, "文件完整"except Exception as e:return False, f"检查文件完整性时出错: {e}"def safe_video_processing(video_path: str, n_frames: int = 8) -> Optional[List[PIL.Image.Image]]:"""安全地处理视频文件,避免损坏文件导致的问题"""try:# 检查文件完整性is_valid, msg = check_video_integrity(video_path)if not is_valid:logger.warning(f"视频文件可能损坏: {msg}")return None# 创建临时副本以避免中文路径问题with tempfile.NamedTemporaryFile(suffix='.mp4', delete=False) as temp_file:temp_path = temp_file.nametry:# 复制文件到临时路径shutil.copy2(video_path, temp_path)# 使用更健壮的方式读取视频 - 使用VideoFileClipwith VideoFileClip(temp_path) as clip:if clip.duration <= 0:return Nonetotal_frames = int(clip.fps * clip.duration)if total_frames <= 0:return None# 如果n_frames为0,则根据视频长度自动计算帧数if n_frames <= 0:# 每秒钟提取一帧,最多不超过30帧n_frames = min(int(clip.duration), 30)logger.info(f"自动计算帧数: {n_frames}")num_to_extract = min(n_frames, total_frames)if num_to_extract <= 0:return None# 均匀采样帧 - 使用参考代码中的方法indices = [int(i * total_frames / num_to_extract) for i in range(num_to_extract)]frames = []for idx in indices:try:frame_time = idx / clip.fpsframe = clip.get_frame(frame_time)if frame is not None and frame.size > 0:pil_image = PIL.Image.fromarray(frame)frames.append(pil_image)except Exception as frame_error:logger.warning(f"提取第 {idx} 帧时出错: {frame_error}")continueif not frames:return Nonereturn framesfinally:# 清理临时文件try:os.unlink(temp_path)except:passexcept Exception as e:logger.error(f"处理视频 {video_path} 时严重错误: {e}")return Nonedef load_video_frames(video_path: Optional[str], n_frames: int = 8) -> Optional[List[PIL.Image.Image]]:"""从视频文件中提取指定数量的帧。"""if not video_path:return None# 添加警告过滤import warningswarnings.filterwarnings("ignore", category=UserWarning, module="moviepy")try:return safe_video_processing(video_path, n_frames)except Exception as e:logger.error(f"处理视频 {video_path} 时严重错误: {e}")return Nonedef parse_model_output(response_text: str, enable_thinking: bool) -> str:"""格式化模型输出,如果启用,则分离 '思考' 和 '响应' 部分。"""if enable_thinking:# 使用更强大的正则表达式处理嵌套内容和变体think_match = re.search(r"<think>(.*?)<|FunctionCallEnd|>", response_text, re.DOTALL)if think_match:thinking_content = think_match.group(1).strip()# 从原始文本中移除 think 块以获取响应response_content = re.sub(r"<think>.*?<|FunctionCallEnd|>", "", response_text, flags=re.DOTALL).strip()return f"**思考:**\n```\n{thinking_content}\n```\n\n**响应:**\n{response_content}"else:return response_text # 未找到 think 标签,按原样返回else:# 如果禁用思考,则移除标签,以防模型仍然生成它们return re.sub(r"<think>.*?</think>", "", response_text, flags=re.DOTALL).strip()def image_to_base64(image: PIL.Image.Image) -> str:"""将PIL图像转换为base64字符串"""import base64from io import BytesIObuffered = BytesIO()image.save(buffered, format="JPEG")img_str = base64.b64encode(buffered.getvalue()).decode()return f"data:image/jpeg;base64,{img_str}"# --- 核心推理逻辑 ---
@spaces.GPU
def run_inference(chatbot: List,image_input: Optional[PIL.Image.Image],video_input: Optional[str],do_sample: bool,max_new_tokens: int,enable_thinking: bool,enable_thinking_budget: bool,thinking_budget: int,n_frames: int,
):"""通过OpenAI API运行单轮推理并为 gr.Chatbot 产生输出流。"""# 检查模型连接状态is_connected, _ = check_model_connection()if not is_connected:gr.Warning("模型连接尚未建立,请等待模型启动完成后再试")# 移除最后一条空消息if chatbot and chatbot[-1][1] == "":chatbot.pop(-1)yield chatbotreturn# 修复IndexError: 检查chatbot是否为空if not chatbot:gr.Warning("聊天历史为空,请输入消息。")yield []returntry:prompt = chatbot[-1][0]except (IndexError, TypeError):gr.Warning("无法获取用户消息。")yield chatbotreturnif (not image_input and not video_input and not prompt) or not prompt:gr.Warning("生成需要文本提示。")# 移除最后一条空消息if chatbot and chatbot[-1][1] == "":chatbot.pop(-1)yield chatbotreturn# 构建消息内容content = []# 处理图像输入if image_input:base64_image = image_to_base64(image_input)content.append({"type": "image_url","image_url": {"url": base64_image}})# 处理视频输入(提取关键帧作为图像)if video_input:frames = load_video_frames(video_input, n_frames)if frames:# 为每一帧创建一个image_urlfor frame in frames:base64_frame = image_to_base64(frame)content.append({"type": "image_url","image_url": {"url": base64_frame}})else:gr.Warning("处理视频文件失败。视频文件可能已损坏或格式不受支持。")# 移除最后一条空消息if chatbot and chatbot[-1][1] == "":chatbot.pop(-1)yield chatbotreturn# 添加文本提示content.append({"type": "text", "text": prompt})messages = [{"role": "user", "content": content}]# 避免在日志中输出完整的base64内容logger.info(f"Sending messages to API: {len(content)} content parts")for i, part in enumerate(content):if part.get("type") in ["image_url", "video_url"]:logger.info(f"Content part {i}: {part['type']} (base64 data omitted from log)")else:logger.info(f"Content part {i}: {part}")try:# 构建extra_body参数extra_body = {"chat_template_kwargs": {"enable_thinking": enable_thinking,}}if enable_thinking_budget:extra_body["chat_template_kwargs"]["enable_thinking_budget"] = Trueextra_body["chat_template_kwargs"]["thinking_budget"] = thinking_budget# 调用OpenAI APIresponse = client.chat.completions.create(model="Ovis2.5-9B", # 修改为你的模型名称messages=messages,max_tokens=max_new_tokens,temperature=0.7 if do_sample else 0.0,stream=True,extra_body=extra_body)# 流式处理响应response_text = ""for chunk in response:if chunk.choices[0].delta.content is not None:new_text = chunk.choices[0].delta.contentresponse_text += new_text# 更新chatbot中的最后一条消息if chatbot:chatbot[-1] = (chatbot[-1][0], response_text)yield chatbot# 生成完成后格式化最终响应formatted_response = parse_model_output(response_text, enable_thinking)if chatbot:chatbot[-1] = (chatbot[-1][0], formatted_response)yield chatbotlogger.info("\n[OVIS_CONV_START]")[print(f'Q{i}:\n {request}\nA{i}:\n {answer}\n') for i, (request, answer) in enumerate(chatbot, 1)]logger.info("[OVIS_CONV_END]")except Exception as e:gr.Warning(f"API调用期间出错: {e},可能是模型暂时不可用")# 移除最后一条空消息if chatbot and chatbot[-1][1] == "":chatbot.pop(-1)yield chatbot# --- UI 辅助函数 ---
def toggle_media_input(choice: str) -> Tuple:"""在图像/视频输入之间切换可见性。"""if choice == "Image":return gr.update(visible=True, value=None), gr.update(visible=False, value=None)else: # Videoreturn gr.update(visible=False, value=None), gr.update(visible=True, value=None)# --- 构建 Gradio 应用 ---
def build_demo():"""为模型构建 Gradio 用户界面。"""model_name_display = "Ovis2.5-9B"logo_html = ""logo_svg_path = os.path.join(CUR_DIR, "resource", "logo.svg")if os.path.exists(logo_svg_path):with open(logo_svg_path, "r", encoding="utf-8") as svg_file:svg_content = svg_file.read()font_size = "2.5em"svg_content_styled = re.sub(r'(<svg[^>]*)(>)', rf'\1 height="{font_size}" style="vertical-align: middle; display: inline-block;"\2', svg_content)logo_html = f'<span style="display: inline-block; vertical-align: middle;">{svg_content_styled}</span>'else:logo_html = '<span style="font-weight: bold; font-size: 2.5em; display: inline-block; vertical-align: middle;">Ovis</span>'# 初始检查模型连接状态connection_status, connection_message = check_model_connection()html_header = f"""<p align="center" style="font-size: 2.5em; line-height: 1;">{logo_html}</p><center><font size=3><b>Ovis2.5-9B</b> 已在 <a href='https://www.suanjiayun.com/mirror'> 算家云 </a> 镜像社区平台部署,欢迎大家使用!</font></center>"""# --- 滑块同步逻辑函数 ---def adjust_max_tokens(thinking_budget_val: int, max_new_tokens_val: int) -> gr.Slider:"""调整 max_new_tokens 至少为 thinking_budget + 128。"""new_max_tokens = max(max_new_tokens_val, thinking_budget_val + 128)return gr.update(value=new_max_tokens)def adjust_thinking_budget(max_new_tokens_val: int, thinking_budget_val: int) -> gr.Slider:"""调整 thinking_budget 至多为 max_new_tokens - 128。"""new_thinking_budget = min(thinking_budget_val, max_new_tokens_val - 128)return gr.update(value=new_thinking_budget)# --- 结束: 滑块同步逻辑函数 ---prompt_input = gr.Textbox(label="提示", placeholder="在此输入文本并按 ENTER", lines=1, container=False)with gr.Blocks(theme=gr.themes.Ocean()) as demo:gr.HTML(html_header)# 添加连接状态提示connection_status_box = gr.Textbox(value=connection_message,label="模型连接状态",interactive=False,visible=True)gr.Markdown("注意:仅当同时勾选 `深度思考` 和 `思维预算` 时,思维预算机制才启用。在 `深度思考` 模式下,可以调低 `思维预算` 以获得更快的生成速度。")with gr.Row():with gr.Column(scale=4):input_type_radio = gr.Radio(choices=["Image", "Video"], value="Image", label="选择输入类型")image_input = gr.Image(label="图像输入", type="pil", visible=True)video_input = gr.Video(label="视频输入", visible=False)with gr.Accordion("生成设置", open=True):do_sample = gr.Checkbox(label="启用采样 (Do Sample)", value=True)enable_thinking = gr.Checkbox(label="启用深度思考", value=True)enable_thinking_budget = gr.Checkbox(label="启用思维预算", value=True)max_new_tokens = gr.Slider(minimum=256, maximum=4096, value=2048, step=32, label="最大新词元数")thinking_budget = gr.Slider(minimum=128, maximum=3968, value=1024, step=32, label="思维预算")# 新增关键帧数量滑块n_frames = gr.Slider(minimum=0, maximum=30, value=8, step=1, label="关键帧数量 (0=自动)",info="设置从视频中提取的关键帧数量,设为0将根据视频长度自动计算")with gr.Column(scale=7):chatbot = gr.Chatbot(label="Ovis", height=600, show_copy_button=True, layout="panel", latex_delimiters=latex_delimiters_set)prompt_input.render()with gr.Row():generate_btn = gr.Button("发送", variant="primary")clear_btn = gr.Button("清除", variant="secondary")check_connection_btn = gr.Button("立即检查连接", variant="secondary")# --- UI 元素的事件处理器 ---input_type_radio.change(fn=toggle_media_input,inputs=input_type_radio,outputs=[image_input, video_input])# 耦合滑块的事件处理器thinking_budget.release(fn=adjust_max_tokens,inputs=[thinking_budget, max_new_tokens],outputs=[max_new_tokens])max_new_tokens.release(fn=adjust_thinking_budget,inputs=[max_new_tokens, thinking_budget],outputs=[thinking_budget])# 检查连接按钮def update_connection_status():status, message = check_model_connection()return gr.update(value=message)check_connection_btn.click(fn=update_connection_status,inputs=[],outputs=[connection_status_box])# 启动定时检查连接状态的线程def start_periodic_check():thread = Thread(target=update_connection_status_periodically,args=(connection_status_box,),daemon=True # 确保线程在主线程退出时自动结束)thread.start()# 在页面加载时启动定时检查demo.load(start_periodic_check)# 推理输入参数run_inputs = [chatbot, image_input, video_input, do_sample, max_new_tokens, enable_thinking, enable_thinking_budget, thinking_budget, n_frames]generat_click_event = generate_btn.click(submit_chat, [chatbot, prompt_input], [chatbot, prompt_input]).then(run_inference, run_inputs, chatbot)submit_event = prompt_input.submit(submit_chat, [chatbot, prompt_input], [chatbot, prompt_input]).then(run_inference, run_inputs, chatbot)clear_btn.click(fn=lambda: ([], None, None, ""),outputs=[chatbot, image_input, video_input, prompt_input])# --- 结束: UI 元素的事件处理器 ---return demo# --- 主执行块 ---
if __name__ == "__main__":demo = build_demo()demo.queue().launch(server_name="0.0.0.0", server_port=8080)
)

)
)



)
:静态路由、动态路由、默认路由)










