最近,AI 编码工具层出不穷,几乎每天都有新概念诞生。而当 GitHub 这样的行业巨头携“Vibe Coding”概念入场时,所有开发者的期待值都被瞬间拉满。GitHub Spark,一个承诺能用自然语言将你的想法直接变成全栈应用的工具,听起来就像是未来的敲门砖。

然而,在满怀希望地深入体验后,我却发现现实与理想之间存在着一条巨大的鸿沟。这趟旅程,与其说是对未来的探索,不如说是一次对“大厂产品设计哲学”的深刻反思。

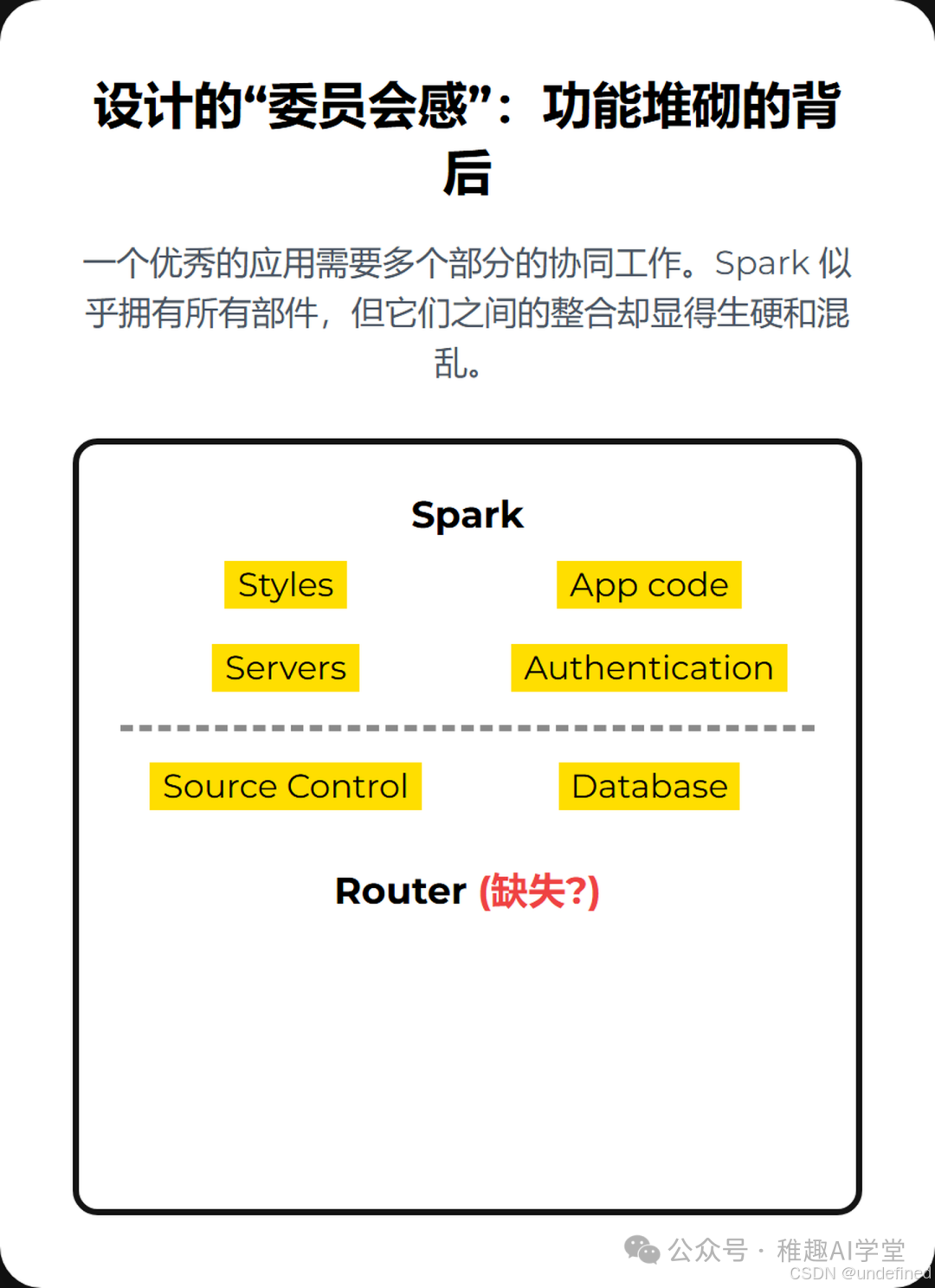
设计的“委员会感”:功能堆砌的背后
一个优秀的应用,无论是代码层面还是用户体验层面,都需要各个部分的和谐统一。这包括清晰的UI(Styles)、稳健的应用逻辑(App code)、可靠的后端服务(Servers)、无缝的认证体系(Authentication)、结构化的数据存储(Database)、明确的路由规则(Router)以及版本控制(Source Control)。
Spark 乍看之下似乎拥有了所有这些部件,但实际体验下来,却像是一个由不同部门开会决策、最后强行拼凑起来的产品。各个功能模块之间缺乏有机的联系,处处透露着一种“我们有这个功能,但没想好怎么让它好用”的尴尬。
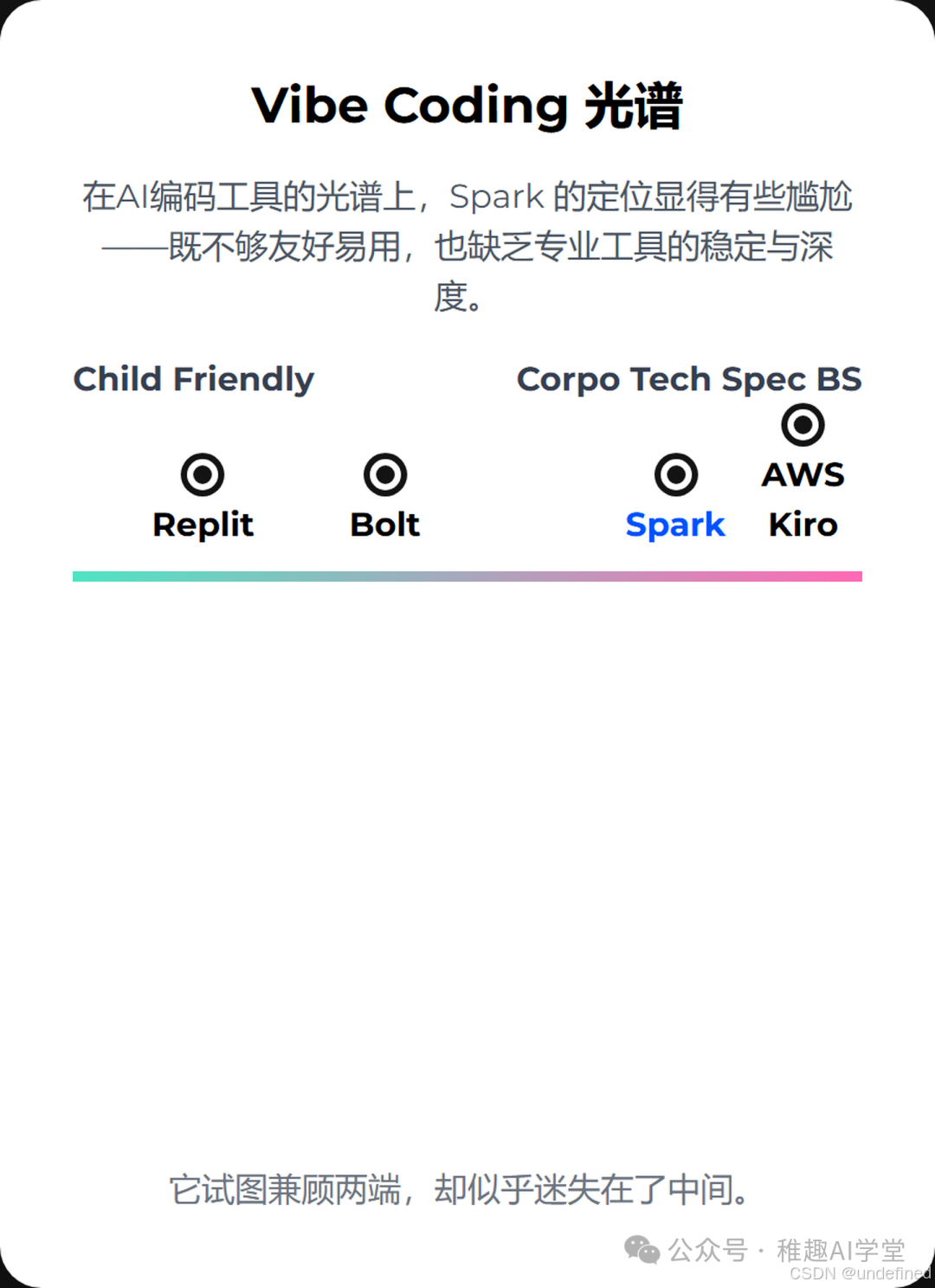
在光谱中迷失:定位模糊的尴尬
如果我们将市面上的AI编码工具放在一个光谱上,一端是极其“友好易用”,甚至可以让非程序员快速上手的工具(比如Replit的某些模式);另一端则是追求极致专业、稳定、可控的“企业级技术方案”(比如AWS Kiro)。
Spark 的定位就在这其中显得尤为尴尬。它既不像前者那样简单直观,能让人快速获得成就感;也远未达到后者在稳定性、性能和可扩展性上的专业水准。它似乎试图讨好所有人,结果却可能让两边的用户都感到不适。
通往严肃工具之路:一份给Spark的“体检报告”
那么,要让 Spark 真正从一个“酷炫的玩具”转变为开发者信赖的生产力工具,需要做些什么呢?经过一番“折腾”,我总结出了以下几点至关重要的改进方向:

让我能在本地运行代码! 这是开发者的基本人权。一个无法在本地环境轻松调试、掌控的工具,永远无法成为核心生产力工具。
“大对象”数据模型是灾难。 将所有消息历史记录存储为单个JSON对象的做法,在数据结构设计上是极其业余且危险的,这直接导致了实时性和并发性的严重问题。
请先修复BUG,再谈新功能。 当前版本的 Spark 充满了各种令人困惑的 Bug 和不稳定的表现。在产品核心体验尚未打磨好的情况下,任何新功能的增加都只会加剧混乱。
精简想法,聚焦核心。 Spark 似乎集成了太多“酷炫”但半生不熟的想法。与其做一个功能繁多但处处是坑的“瑞士军刀”,不如先做好一把锋利、可靠的主刀。
部署状态必须透明。 用户需要一个清晰、明确的指示,来了解当前预览的应用版本是否已经同步了最新的代码变更。
真正发挥GitHub的生态优势。 Spark 最大的潜力在于它背后强大的GitHub生态。它应该更深度、更灵活地与代码仓库、认证、部署流程结合,而不是像现在这样,仅仅是“拥有一个GitHub仓库”的 superficial 连接。
一个核心的疑问
在整个体验过程中,一个挥之不去的念头是:开发这个工具的团队,真的在日常工作中使用它来构建和维护自己的内部应用吗?

很多产品的设计缺陷,都源于开发者与真实用户场景的脱节。如果一个工具的创造者们自己都不是它的重度用户,那么它很难真正理解并解决用户的核心痛点。这或许是 Spark 当前面临的最大挑战。
总而言之,GitHub Spark 展现了巨大的潜力,它背后的理念和技术整合能力是毋庸置疑的。但就目前的产品形态而言,它更像一个内部技术验证项目,距离成为一个成熟、可靠、能让开发者“爱不释手”的工具,还有很长一段路要走。我们期待着它能听取社区的声音,完成一次深刻的蜕变。
写在最后——如果你觉得这篇文章对你有帮助,记得转发给更多朋友,AI的快乐要一起分享!也欢迎在评论区晒出你用这个技巧的神操作,万一你一不 小心就启发了下一个“AI爆款”呢?
我是AIGC小火龙果,一个努力让AI不再高冷的产品顽童,主业是把复杂的AI技巧变成你一看就会的小把戏。关注我,与和你一样有想法的朋友们一起,在AI时代边玩边进化!
该内容观点引自 【Theo - t3․gg】,感谢友友分享,欢迎在评论区留言,本文仅作学习与交流之用,如有任何问题或需要调整,请随时告知,我会第一时间处理。




)






的详细分析与实现)




-- 性能优化与调试)

![[新启航]新启航激光频率梳 “光量子透视”:2μm 精度破除遮挡,完成 130mm 深孔 3D 建模](http://pic.xiahunao.cn/[新启航]新启航激光频率梳 “光量子透视”:2μm 精度破除遮挡,完成 130mm 深孔 3D 建模)
