论文链接:https://arxiv.org/pdf/2508.14880
【导读】当通用大模型还在“背题库”时,蚂蚁集团联合哈工大推出的 MedResearcher-R1 已把“临床查房”搬进训练场!这篇 2025 年 9 月发布的论文,首次让开源 32B 模型在医学深度研究基准 MedBrowseComp 上拿下 27.5/50 的新 SOTA,反超 o3-deep-research、Gemini-2.5-Pro 等旗舰商用系统。作者提出“知识轨迹合成”框架 KISA:①从 3000 万 PubMed 摘要中挖出频率<10⁻⁶ 的罕见实体,②在子图最长链路上生成 4.2 跳的多跳问答,③用 Masked Trajectory Guidance 防止模型“背答案”。配套私有医学检索器直接对接 FDA、临床试试验注册库,把“通用搜索”升级为“循证医学”模式。训练采用两阶段范式:先 SFT 学习工具调用,再用 GRPO 强化学习优化“准确率+专家偏好+效率”复合奖励。结果不仅医学任务霸榜,在通用基准 GAIA、XBench 上也与 WebSailor-32B 打平(53.4 vs 53.2)。论文最后放出代码、数据与模型,呼吁共建安全、可溯源的 AI 医学研究新基建。想让你的 AI 像资深医生一样查文献、做鉴别诊断?向学习如何构建一个深度研究智能体?这篇 13干货文章值得逐句精读!
MedResearcher-R1: 基于知识引导轨迹合成框架的专家级医学深度研究员
病愈的余1兰瑶2*刘景南浙江尹家俊1王元1廖新浩叶志凌李继岳云肖汉松1周华雷1郭春晓1魏鹏1刘俊伟1顾金杰1
1蚂蚁集团2哈尔滨工业大学
代码和数据集:AQ- MedAI/MedResearcher- R1
摘要
近期基于大型语言模型(LLM)的智能体发展显示出跨多个领域的令人印象深刻的能力,例如在复杂信息搜索和合成任务上表现出色深度研究系统。虽然通用深度研究智能体已展现出令人印象深刻的能力,但在医疗领域挑战上却面临显著困难,这体现在领先的专有系统在复杂医疗基准测试上仅达到有限精度。关键限制在于:(1)模型缺乏足够的密集医疗知识以支持临床推理,以及(2)框架受限于缺乏针对医疗场景的专用检索工具。我们提出了一种医疗深度研究智能体,通过两项核心创新解决这些挑战。首先,我们开发了一种使用医疗知识图谱的新型数据合成框架,从围绕罕见医疗实体的子图中提取最长链以生成复杂的多跳问答对。其次,我们集成了定制构建的私有医疗检索引擎与通用工具,实现准确的医疗信息合成。我们的方法在12个医疗专科中生成 2100+2100+2100+ 多样化的轨迹,每个平均涉及4.2次工具交互。通过结合监督微调和在线强化学习的两阶段训练范式(使用复合奖励),我们的MedResearcher- R1- 32B模型展现出卓越性能,在医疗基准测试上建立新的最先进结果,同时在通用深度研究任务上保持具有竞争力的表现。我们的工作证明,在架构、工具设计和训练数据构建方面的策略性领域特定创新可以使较小的开源模型在专业领域超越远大的专有系统。代码和数据集将发布以促进进一步研究。
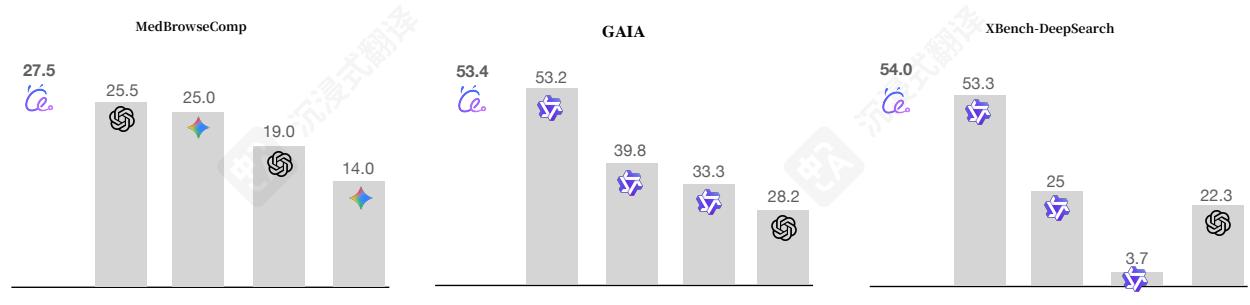
图1:MedResearcher- R1在三个基准测试中的整体性能。在MedBrowseComp上,我们的MedResearcher- R1- 32B达到了最先进的性能,正确答案为27.5/50,超过了o3- deepresearch(25.5/50)、Gemini- 2.5- Pro- deepresearch(25.0/50),并且显著优于仅搜索的方法(o3- search:19.0/50,Gemini- 2.5- Pro- search:14.0/50)。在通用深度研究任务中,我们在GAIA上取得了具有竞争力的结果(53.4 vs. WebSailor- 32B的53.2)和xBench上(54.0 vs. WebSailor- 32B的53.3)。
1引言
大型语言模型(LLM)的最新进展推动了基于LLM的代理在软件工程[Wang等人,2024年,Jimenez等人,2023]以及深度研究系统[Xu和Peng,2025]等不同领域的广泛应用。这些代理在处理环境观察、跨多个交互维护上下文以及执行复杂的多步骤推理任务方面表现出令人印象深刻的能力。
然而,医疗领域存在独特的挑战,当前的通用深度研究代理无法充分解决。最近引入的MedBrowseComp基准[Chenetal.,2025b]揭示了这一关键差距:即使是OpenAI的o3- deepresearch(领先的专有深度研究系统),在需要跨医疗知识源进行多跳推理的复杂医疗查询中也仅达到 25.5%25.5\%25.5% 的准确率。我们确定了两个导致此性能差距的基本限制:(1)通用代理缺乏进行准确临床推理所需的密集、专业医疗知识,(2)它们依赖通用检索工具,这些工具无法捕捉医疗信息中的细微关系。
核心挑战在于我们称之为稀疏医疗知识问题的方面。医学研究通常需要通过非明显的路径连接罕见疾病、新兴治疗和专门的临床发现一一这些连接存在于专业医学文献中,但普通搜索工具无法获取。虽然现有的医学AI系统在诊断等结构化任务中取得了进展,但它们主要关注具有明确推理模式的常见医疗场景。这些系统未能发展出专家临床医生所具备的探索性医学研究能力:同时追踪多个假设、整合来自不同来源的证据,并识别罕见医疗实体之间的微妙联系。
为解决这些局限性,我们提出了一种全面的方法,从根本上重新思考医疗代理应该如何进行训练。我们的关键洞察是,有效的医疗推理需要在训练过程中接触真正复杂的医疗场景,而不是简化的近似。我们通过三个相互关联的创新来实现这一点:
首先,我们开发了一个新颖的数据合成框架,通过系统化流程生成具有极高复杂度的训练样本:我们从超过3000万篇PubMed摘要中提取医学实体,然后应用频率分析来识别在医学语料库中出现频率低于 10−610^{- 6}10−6 的候选者。通过LLM辅助评估,我们筛选这些候选者以选择真正罕见但具有临床意义的实体,避免无关紧要的拼写错误和过于常见的病症。围绕这些精心挑选的罕见医学实体,我们构建知识图谱以提取用于多跳问题生成的最长推理链。这种方法生成的题目能够反映真实的医学研究挑战,无法通过简单检索回答,但需要系统性地探索和综合多个医学信息来源。
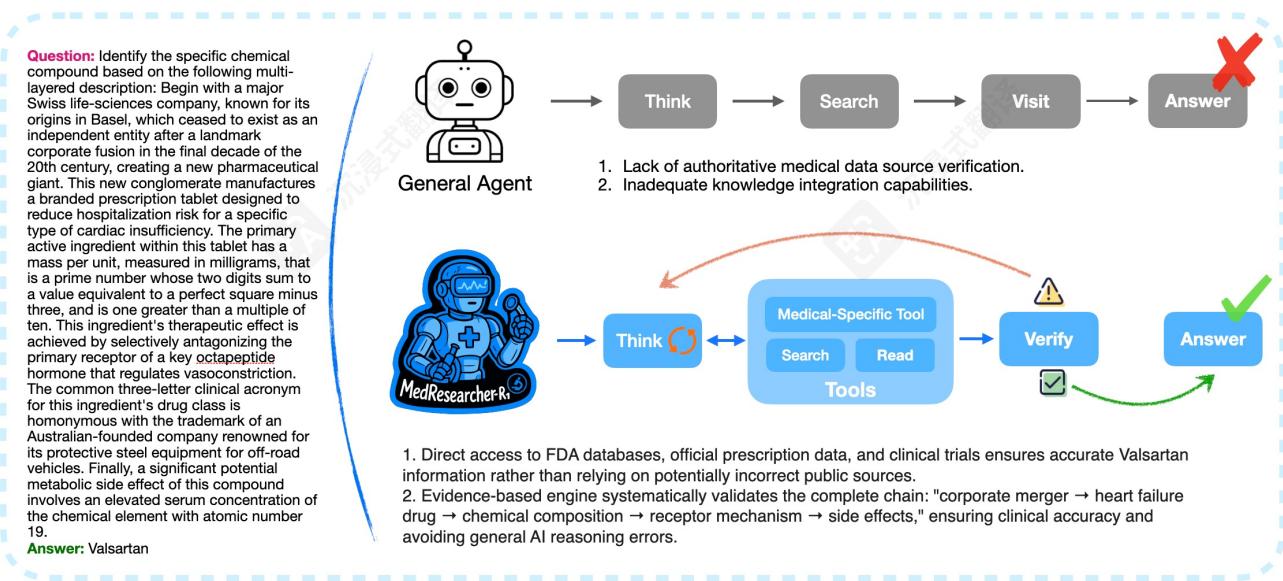
图2:医疗推理代理的比较。MedResearcher- R1解决了valsartan识别案例,该案例击败了通用代理,展示了专业医疗数据库访问和基于证据的推理集成的优势。
其次,我们引入了专有的医学领域工具,以解决通用系统中的检索空白。如图2所示,虽然通用代理在遇到医学特定查询时经常失败,尤其是涉及罕见疾病或复杂化学化合物的查询,但MedResearcher- R1可以迭代调用专有的医学工具和通用工具以确保准确的信息检索。与依赖通用网络爬虫的传统搜索引擎不同,我们定制构建的私有医学检索引擎直接访问权威医学数据库,包括FDA数据库、官方处方数据、临床试验注册库和同行评审的医学出版物。图2中的比较展示了MedResearcher- R1如何动态地在通用和医学特定工具之间切换,从而对完整的证据链进行系统化验证:从企业并购信息到心力衰竭药物开发,再到化学成分和机制,最终确保临床准确性,同时避免仅依赖通用方法所导致的推理错误。该系统采用医学本体感知排序,优先考虑临床权威性和相关性而非通用网络流行度指标,有效地结合了通用搜索的广度与领域特定医学专长的精确性。
第三,我们实现了一种专门为医疗领域设计的训练方法。与近期提倡纯强化学习方法的研究不同,我们发现医疗任务需要我们称之为知识锚定学习的东西:在高质量医疗轨迹上进行初始的监督微调被证明非常有效,可以学习工具使用模式并显著提高最终性能。我们的掩码轨迹指导(MTG)技术提供了结构化的支撑,同时防止记忆,迫使模型发展真正的医疗推理能力,而不是模式匹配。
我们的实验结果验证了这种方法。训练好的模型MedResearcher- R1在MedBrowseComp上取得了27.5/50的分数,建立了新的当前最佳水平,并且显著优于Qwen2.5- 32B基线和现有的深度研究系统。值得注意的是,我们的医疗专业化并没有损害通用能力:在通用代理基准(GAIA:53.4,xBench:54)上,MedResearcher- R1保持了与OpenAIo4- mini相当的有竞争力的性能。请参考图1以了解整体情况。这些结果挑战了主流假设,即特定领域的代理需要牺牲通用能力。相反,我们证明,医学任务所要求的严格推理——精确术语、谨慎的证据评估和系统的假设检验——为开发强大的代理能力提供了更优越的训练信号。从医学领域学习到的密集知识结构和复杂推理模式可以有效地迁移到一般任务中,这表明专业训练可以增强而不是限制代理的通用性。
这项工作通过证明实现医学深度研究能力需要超越将通用代理应用于医学任务的根本性创新,为快速发展的医学人工智能领域做出了贡献。通过精心设计训练数据、专业工具和学习算法,我们展示了开发接近专家级医学研究能力的代理的可能性。我们发布我们的代码、数据集和训练模型,以促进这一关键领域进一步的研究。
2 MedResearcher-R1:医学深度研究代理框架
2.1 问题定义
我们将医学深度研究任务形式化为一个序列决策问题,其中代理必须导航复杂的医学知识源来回答多跳查询,这些查询表征了第1节中确定的稀疏医学知识问题。给定一个医学问题 q∈Qq \in \mathcal{Q}q∈Q ,代理使用异构工具集 T=Tgeneral∪Tmedical\mathcal{T} = \mathcal{T}_{\mathrm{general}} \cup \mathcal{T}_{\mathrm{medical}}T=Tgeneral∪Tmedical ,其中 Tgeneral={t1q,…,tmq}\mathcal{T}_{\mathrm{general}} = \{t_1^q, \ldots , t_m^q \}Tgeneral={t1q,…,tmq} 包括通用工具(网络搜索、文档分析),而 Tmedical={t1m,…,tnm}\mathcal{T}_{\mathrm{medical}} = \{t_1^m, \ldots , t_n^m \}Tmedical={t1m,…,tnm} 包含我们专有的医学领域工具,这些工具可以直接访问权威医学数据库。
代理在时间步 ttt 维护一个不断演变的 at=(ct,kt,ht)a_{t} = (c_{t}, k_{t}, h_{t})at=(ct,kt,ht) 状态,其中:
- ct∈Cc_{t} \in \mathcal{C}ct∈C :对话上下文编码当前查询和响应历史- kt∈Kk_{t} \in \mathcal{K}kt∈K :从检索来源中累积的医学知识,结构化为知识图谱- ht∈Hh_{t} \in \mathcal{H}ht∈H :推理历史跟踪探索的知识路径和假设演变
这种状态表示使能够跟踪多跳推理链,这对于通过非明显路径连接罕见医学实体至关重要。在每个时间步,代理根据学习到的策略选择一个动作:
at∼πθ(a∣st,T,q) a_{t} \sim \pi_{\theta} (a \mid s_{t}, \mathcal{T}, q) at∼πθ(a∣st,T,q)
where πθ\pi_{\theta}πθ 是通过我们的知识锚定学习方法进行训练的,以根据查询需求动态切换通用和医学专用工具。
2.2智能体架构
我们的框架直接解决了通用代理的两个基本限制:医学知识密度不足以及对通用检索工具的依赖,这些工具无法捕捉细微的医学关系。
推理- 行动范式。遵循REACT框架[Yao等人,2023a],我们的智能体通过迭代推理- 行动- 观察循环运行,并增加了医疗特定的增强功能,以实现探索性医疗研究能力。在每个步骤中,策略生成:
·思考:一个医疗推理跟踪,用于识别信息差距、形成假设,并确定是否需要通用或专用工具
·行动:一个针对医疗信息提取的工具调用,参数经过优化,优先考虑权威来源而非一般网络内容
·观察:经过临床证据验证的结构化医疗知识,并整合到智能体的不断发展的状态中
该过程持续迭代,代理同时追求多个假设,直到综合出一个全面的答案。复杂的multi- hop问题通常需要4- 5次工具交互,反映了专家临床医生系统探索的模式。
通用工具。我们的代理保留对标准工具的访问权限,以实现广泛的覆盖范围:
(1)WebSearch:标准网络检索,用于一般医学信息、最新发展和企业/组织数据(例如,图2中所示制药公司合并)。
(2)DocumentRead:从检索到的文档中提取和综合,使用高容量LLM主干(例如,Qwen2.5-72B[Bai等人,2024]),特别适用于处理冗长的临床报告或研究论文。
医学专用工具套件。我们架构的核心创新是集成了专有的医学领域工具,这些工具解决了临床研究的独特挑战,并在一般检索和专门医学推理之间架起了桥梁。我们的医学专用工具套件包括:
(1)PrivateMedicalRetriever:该模块直接从权威临床资源聚合证据,包括FDA数据库、临床试验注册机构和PubMed出版物。每个候选文档 ddd 通过语义相关性和临床权威性的加权线性组合对查询 qqq 进行评分:
Score(d,q)=λRel(d,q)+(1−λ)Auth(d), \mathrm{Score}(d,q) = \lambda \mathrm{Rel}(d,q) + (1 - \lambda)\mathrm{Auth}(d), Score(d,q)=λRel(d,q)+(1−λ)Auth(d),
where Rel(d,q)\mathrm{Rel}(d,q)Rel(d,q) 表示与查询的语义相似度(通过嵌入余弦相似度计算), Auth(d)\mathrm{Auth}(d)Auth(d) 反映临床权威性(结合影响因子和指南状态)。超参数 λ\lambdaλ (0≤λ≤1)(0\leq \lambda \leq 1)(0≤λ≤1) 平衡相关性和权威性的重要性;在所有实验中,我们将 λ=0.4\lambda = 0.4λ=0.4 设置为优先考虑可靠且具有临床意义的证据。
(2)临床推理引擎:专为循证鉴别诊断而设计,该工具应用贝叶斯推理系统性地评估多个假设。给定观察到的症状s、候选诊断 DjD_{j}Dj 和患者背景信息c,每个诊断的后验概率计算如下:
P(Dj∣s,c)=∏i=1nP(si∣Dj,c)⋅P(Dj∣c)∑k=1m∏i=1nP(si∣Dk,c)⋅P(Dk∣c) P(D_{j}\mid \mathbf{s},\mathbf{c}) = \frac{\prod_{i = 1}^{n}P(s_{i}\mid D_{j},\mathbf{c})\cdot P(D_{j}\mid\mathbf{c})}{\sum_{k = 1}^{m}\prod_{i = 1}^{n}P(s_{i}\mid D_{k},\mathbf{c})\cdot P(D_{k}\mid\mathbf{c})} P(Dj∣s,c)=∑k=1m∏i=1nP(si∣Dk,c)⋅P(Dk∣c)∏i=1nP(si∣Dj,c)⋅P(Dj∣c)
条件概率源自临床文献,并根据新检索的证据进行迭代更新。
动态工具选择策略。如图2所示,我们的智能体在通用工具和医学专用工具之间动态切换,以确保完整的证据链。工具选择由一个学习到的策略控制,该策略评估查询的复杂性:
P(t∣st,q)={σ(wmTϕ(st,q))ift∈Tmedcalσ(wgTϕ(st,q))ift∈Tgeneral P(t\mid s_t,q) = \left\{ \begin{array}{ll}\sigma (\mathbf{w}_m^T\phi (s_t,q)) & \mathrm{if} t\in \mathcal{T}_{\mathrm{medcal}}\\ \sigma (\mathbf{w}_g^T\phi (s_t,q)) & \mathrm{if} t\in \mathcal{T}_{\mathrm{general}} \end{array} \right. P(t∣st,q)={σ(wmTϕ(st,q))σ(wgTϕ(st,q))ift∈Tmedcalift∈Tgeneral
其中 ϕ(st,q)\phi (s_t, q)ϕ(st,q) 提取包括实体稀有性、所需推理跳数和医学术语的存在等特征, wm\mathbf{w}_mwm 和 wg\mathbf{w}_gwg 是学习到的权重向量,而 σ(⋅)\sigma (\cdot)σ(⋅) 是 sigmoid 函数。该策略学习在遇到罕见疾病或复杂化学化合物时优先使用医学工具,同时利用通用工具获取上下文信息。
PrivateMedicalRetriever 和 ClinicalReasoningEngine 共同构成了医疗专用工具套件,使代理能够检索、解释和推理超出通用工具能力范围的专门临床证据。
3 KISA:基于知识的轨迹合成方法
为解决医学深度研究智能体训练数据稀缺的关键挑战,我们提出了一种知识引导轨迹合成方法(KISA),该方法能够生成复杂的、多跳的医学推理轨迹。我们的框架通过创建强调以下方面的训练数据来直接解决通用智能体的局限性:(1) 需要密集领域知识的罕见医学实体连接,以及(2) 医学专用检索工具的有效利用。
3.1 Agentic Dataset Construction
我们的数据集构建流程由三个相互关联的组件组成,旨在生成真正复杂的医疗查询,以稳健地测试代理的能力:
3.1.1 实体中心知识图谱构建
我们构建了针对生成复杂推理链而专门优化的医学知识图谱。与关注常见概念的传统方法不同,我们优先考虑罕见医学实体 Eseed\mathcal{E}_{\mathrm{seed}}Eseed 在通用医学语料库中的频率低于阈值的实体。关注罕见实体确保生成的问答需要深厚的医学知识,而非可通过一般搜索获取的表面信息。
图谱扩展遵循迭代过程:
ei+1∼{Uniform(N(ei))with probability 0.5Discover(Enew∣ei)with probability 0.5 e_{i + 1} \sim \left\{ \begin{array}{ll} \text{Uniform} (\mathcal{N}(e_i)) & \text{with probability 0.5} \\ \text{Discover} (\mathcal{E}_{\text{new}}|e_i) & \text{with probability 0.5} \end{array} \right. ei+1∼{Uniform(N(ei))Discover(Enew∣ei)with probability 0.5with probability 0.5
其中 N(ei)\mathcal{N}(e_i)N(ei) 表示 eie_iei 的邻域集合,而 Discover() 通过我们的私有医学检索引擎识别新实体,确保新连接既具有医学有效性又具有挑战性。
每个关系都附加了额外的上下文信息:
r=⟨esubj,p,eobj,ttemporal,lspatial,cclinical⟩ r = \langle e_{\mathrm{subj}}, p, e_{\mathrm{obj}}, t_{\mathrm{temporal}}, l_{\mathrm{spatial}}, c_{\mathrm{clinical}} \rangle r=⟨esubj,p,eobj,ttemporal,lspatial,cclinical⟩
其中 cclinicalc_{\mathrm{clinical}}cclinical 编码临床上下文(例如,疾病阶段、患者人口统计), ttemporalt_{\mathrm{temporal}}ttemporal 捕获时间维度,而 lspatiall_{\mathrm{spatial}}lspatial 表示空间上下文。这种丰富的表示形式通过标准三元组提升了 12.3%12.3\%12.3% 的多跳推理准确率。
3.1.2 基于最长路径提取的多跳问题生成
我们的关键创新在于从子图中提取最长链以生成最大程度复杂的查询。对于每个罕见实体子图 GsubG_{\mathrm{sub}}Gsub ,我们计算最长有效推理路径:
P∗=argmaxp∈P(Gsub)Length(p)s.t. MedicallyValid(p) \mathcal{P}^{*} = \arg \max_{p \in \mathcal{P}(G_{\mathrm{sub}})} \text{Length} (p) \quad \text{s.t. MedicallyValid} (p) P∗=argp∈P(Gsub)maxLength(p)s.t. MedicallyValid(p)
其中 P(Gsub)\mathcal{P}(G_{\mathrm{sub}})P(Gsub) 是 GsubG_{\mathrm{sub}}Gsub 中所有路径的集合。
这种最长路径策略确保问题需要多个推理跳转(平均每个轨迹4.2次),而不是可以通过简单的查找来回答。这些路径随后被转换为需要顺序调用工具来重建完整推理链的自然语言问题。
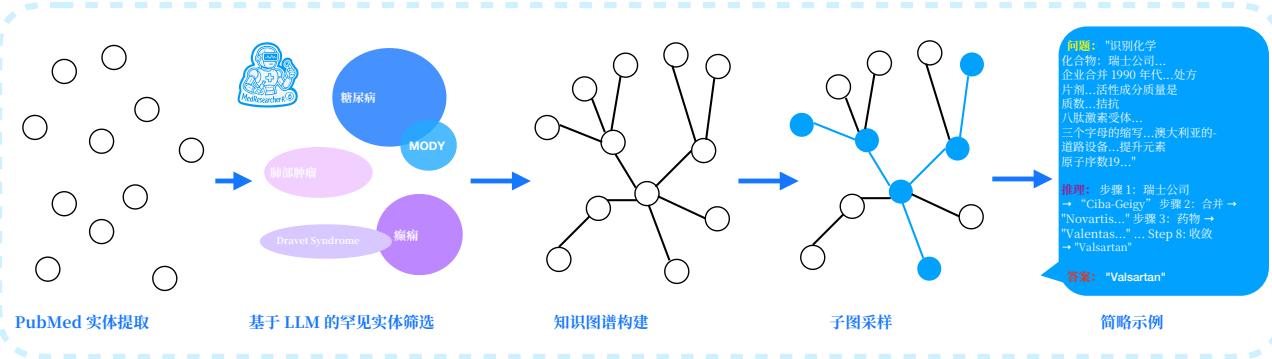
图3:基于知识图谱的问答生成管道:从罕见实体子图中提取最长链以创建复杂的多跳医学查询。
3.1.3质量控制与难度校准
为了确保生成的问题对当前系统仍然具有挑战性,我们实现了自适应难度校准每道题目都会与OpenAI- o3深度研究和GPT- 4进行评估。如果任一模型达到 >50%>50\%>50% 的准确率,该题目将自动重新生成并增加复杂度:
q′={qif max(AccO3(q),AccGPT4(q))<0.5Regenerate(q,complexity+1)otherwise q^{\prime} = \left\{ \begin{array}{ll}q & \mathrm{if~max}(\mathrm{Acc}_{\mathrm{O3}}(q),\mathrm{Acc}_{\mathrm{GPT4}}(q))< 0.5\\ \mathrm{Regenerate}(q,\mathrm{complexity} + 1) & \mathrm{otherwise} \end{array} \right. q′={qRegenerate(q,complexity+1)if max(AccO3(q),AccGPT4(q))<0.5otherwise
这种方法确保我们的数据集即使对于最先进的系统也保持具有挑战性,直接解决了MedBrowseComp中先前观察到的 25.5%25.5\%25.5% 性能上限问题。
3.2带有医疗工具集成的轨迹合成
3.2.1掩码轨迹引导(MTG)
为了生成能够有效利用我们特定医疗工具的高质量训练轨迹,我们引入了掩码轨迹引导(MTG)。给定从知识图谱中提取的推理图路径 T={(e1,r1,e2),…,(en−1,rn−1,en)}\mathcal{T} = \{(e_1,r_1,e_2),\ldots ,(e_{n - 1},r_{n - 1},e_n)\}T={(e1,r1,e2),…,(en−1,rn−1,en)} ,我们通过掩码实体来创建结构框架:
Tmasked={([MASK],ri,[MASK])}i=1n−1 \mathcal{T}_{\mathrm{masked}} = \{([\mathrm{MASK}],r_i,[\mathrm{MASK}])\}_{i = 1}^{n - 1} Tmasked={([MASK],ri,[MASK])}i=1n−1
此掩码过程有两个主要目的:
·工具选择学习:鼓励模型确定何时需要使用医学特定检索工具,而何时一般搜索就足够了。
·预防快捷方式:防止答案记忆,同时保持底层推理过程。

图4:掩码轨迹引导:一种结构支架,通过掩码实体实现推理而不进行捷径学习。
3.2.2工具多样性混合策略
为促进稳健和多样化的工具使用,我们采用混合数据策略: Dtrain=α⋅Dguided+(1−α)⋅Dexploration\mathcal{D}_{\mathrm{train}} = \alpha \cdot \mathcal{D}_{\mathrm{guided}} + (1 - \alpha)\cdot \mathcal{D}_{\mathrm{exploration}}Dtrain=α⋅Dguided+(1−α)⋅Dexploration ,其中 α=0.7\alpha = 0.7α=0.7 平衡结构化学习与探索。探索轨迹自然培养了三种关键行为:
·医疗工具优先级: 78%78\%78% 以私有医疗检索器开始处理罕见实体·工具切换: 42%42\%42% 展示通用工具和医疗工具之间的自适应切换·错误恢复: 34%34\%34% 包括使用替代工具进行显式纠正
4大规模智能体训练
4.1冷启动与监督微调
我们通过在大量合成代理对话 D={(x(i),y(i))}i=1N\mathcal{D} = \{(x^{(i)},y^{(i)})\}_{i = 1}^{N}D={(x(i),y(i))}i=1N 上进行监督微调(SFT)来启动代理训练。这里, x(i)x^{(i)}x(i) 表示输入上下文,而 y(i)y^{(i)}y(i) 表示每个示例的理想下一条动作序列(思考、工具调用等)。目标是最大化在上下文和先验代理历史条件下生成正确轨迹的可能性:
LSFT(θ)=−1N∑i=1N∑k=1∣y(i)∣logpθ(yk(i)∣x(i),y<k(i)). \mathcal{L}_{\mathrm{SFT}}(\theta) = -\frac{1}{N}\sum_{i = 1}^{N}\sum_{k = 1}^{|y^{(i)}|}\log p_{\theta}(y_k^{(i)}|x^{(i)},y_{< k}^{(i)}). LSFT(θ)=−N1i=1∑Nk=1∑∣y(i)∣logpθ(yk(i)∣x(i),y<k(i)).
为了提高代理的鲁棒性和泛化能力,我们在微调过程中结合了几个关键增强:
·工具故障模拟 (5%(5\%(5% 污染率):随机污染工具输出,以鼓励下游轨迹中的应急计划和鲁棒错误恢复。
·中间思考监督:教导代理在每次工具调用之前明确表达推理,提高可解释性和决策可追溯性。
·多任务采样:在医学领域(诊断、治疗、指南、罕见疾病)中多样化训练批次,支持广泛泛化和迁移。
优化过程使用AdamW优化器(学习率 λ=0.01)\lambda = 0.01)λ=0.01) ,采用余弦退火调度 (ηmax=3×10−7)(\eta_{\mathrm{max}} = 3\times 10^{- 7})(ηmax=3×10−7) ,在 8x8x8x H800GPU上进行3个epoch。这确保了对多样化轨迹的快速探索以及收敛到经过良好校准的智能体策略。
4.2强化学习
在监督预训练后,我们通过分组正则化策略优化(GRPO)使用强化学习来改进智能体,优化与特定任务复合奖励相关的智能体轨迹: rt=αrtask+βrexpert−γrefficiencyr_t = \alpha r_{\mathrm{task}} + \beta r_{\mathrm{expert}} - \gamma r_{\mathrm{efficiency}}rt=αrtask+βrexpert−γrefficiency ,其中 rtaskr_{\mathrm{task}}rtask 衡量答案准确性, rexpertr_{\mathrm{expert}}rexpert 反映根据基于GPT- 4的专家模型的偏好, refficiencyr_{\mathrm{efficiency}}refficiency 惩罚过度或冗余的工具使用。权重系数 α\alphaα 、 β\betaβ 和 γ\gammaγ 分别设置为1.0、0.2和0.1。
奖励建模: 奖励函数的分解如下:
·任务:奖励函数的主要组成部分,直接衡量答案准确性并计算每个查询的任务完成分数。
·专家:基于GPT- 4偏好模型,该术语使模型的响应与专家知识保持一致。
·效率:惩罚不必要的工具使用,包括对同一工具的重复调用而没有增加价值、在找到答案后过度使用工具,以及为任务使用不相关的工具。效率惩罚使用基于规则的系统和LLM裁判来评估不必要的使用。
GRPO目标:GRPO目标优化: LGRPO=E(x,y)∼D[logπθ(y∣x)⋅(r(x,y)−rˉG(x))],\mathcal{L}_{\mathrm{GRPO}} = \mathbb{E}_{(x,y)\sim \mathcal{D}}\left[\log \pi_{\theta}(y|x)\cdot (r(x,y) - \bar{r}_{\mathcal{G}(x)})\right],LGRPO=E(x,y)∼D[logπθ(y∣x)⋅(r(x,y)−rˉG(x))], 其中 rˉG(x)\bar{r}_{\mathcal{G}(x)}rˉG(x) 是组级基线,计算为同一批次中响应的平均奖励。该组归一化稳定了梯度估计。
附加修改:
·KL正则化:我们从训练流程中移除了KL正则化,因为它可能会阻碍性能提升,尤其是在多阶段训练期间。这与文献中关于省略KL损失对模型泛化有益的观点一致[He等人,2025]。
·任务复杂度:任务复杂度通过课程学习逐步增加,通过任务上的平均通过率进行监控。这确保了模型在训练早期不会被过度挑战。
5实验
我们在特定领域和通用基准上评估MedResearcher- R1,以评估其在复杂医学研究任务中的有效性及其在医学领域之外的泛化能力。
5.1基准测试
·MedBrowseComp[Chen et al.,2025b]是一个最近提出的基准测试,专门设计用于评估基于LLM的代理从多个网络来源检索和合成医学证据的能力。此基准测试向代理提出开放式临床问题,这些问题需要多步推理、战略信息收集以及有效利用网络浏览API来构建全面的医学评估。
·GAIA[Shinnet al.,2023] (通用人工智能助手)是一个综合评估框架,通过需要工具使用、网络搜索和多步推理的复杂、多模态任务来测试现实世界的助手能力。基准测试强调对人类来说概念简单但对AI系统具有挑战性的任务,重点关注阅读理解、逻辑推理以及在实际场景中有效使用工具的基本技能。
·XBench- DeepSearch[Chen et al.,2025a]是一个广泛的多领域代理评估套件,系统地评估了跨各种开放域任务的工具使用能力。基准测试涵盖了广泛的各种场景,包括事实核查、比较分析、基于网络浏览的推理和复杂的信息合成任务,为基于LLM的代理在现实世界问题解决环境中导航和利用各种工具的能力提供了全面的评估。
5.2主要结果
如表1所示,我们的工具增强代理在MedBrowseComp基准测试中取得了新的最先进性能,达到了27.5/50的pass@1分数,并超过了之前的最佳代理和Qwen2.5- 32B基线。监督微调(SFT)阶段已经带来了显著的提升,而后续的强化学习进一步提高了决策质量和工具编排效率。
值得注意的是,尽管我们的代理主要针对医疗领域进行训练,但它对表2中展示的开域任务表现出强大的泛化能力。在GAIA和XBench- deepsearch上,我们的系统显示出具有竞争力的有用性分数,证明了基于工具的训练范式的多功能性。
表1:MedBrowseComp基准测试的性能比较(50个正确答案的数量)
| 模型 | o3 search | gemini2.5pro deepsearch | o3 deepresearch | claude-cua | MedResearcher-R1-32B |
| MedBrowseComp | 19.0 | 24.5 | 25.5 | 18.0 | 27.5 |
5.3定性分析
为了理解驱动性能提升的潜在因素,我们对训练数据模式及其对代理行为的影响进行了深入分析。我们的调查表明,遵循范式的训练数据能够显著提升深度研究能力。
表2:在Xbench-DeepSearch和GAIA基准测试上的性能比较
| 模型 | 范例 | Xbench-DeepSearch | GAIA |
| Owen-2.5-32B | 直接 | 8.7 | 13.6 |
| Owen-2.5-72B | 直接 | 12.7 | 14.6 |
| GPT-4o | 直接 | 18.0 | 17.5 |
| GPT-4.1 | 直接 | 17.0 | 22.3 |
| OwQ-32B | 直接 | 10.7 | 22.3 |
| o4-mini | 直接 | 22.3 | 33.3 |
| DeepSearch-R1 | 直接 | 32.7 | 16.5 |
| Owen-2.5-32B | Search-ol | 3.7 | 28.2 |
| WebDancer-32B | ReAct | 38.7 | 40.7 |
| OwQ-32B | Search-ol | 25.0 | 39.8 |
| WebSailor-7B | ReAct | 34.3 | 37.9 |
| WebSailor-32B | ReAct | 53.3 | 53.2 |
| WebSailor-72B | ReAct | 55.0 | 55.4 |
| MedResearcher-R1-32B(我们的) | ReAct | 54.0 | 53.4 |
遵循迭代搜索- 验证- 综合范式的训练数据能够显著提升深度研究能力。
图5展示了一个典型示例,其中我们的智能体通过系统性的证据收集展现了卓越的研究深度。智能体执行了一个4步策略:(1)初始广泛搜索以识别相关来源,(2)在多个权威医学数据库中验证信息一致性,(3)有针对性的后续查询以解决歧义,以及(4)对已验证发现的全面综合。这种系统性的方法——其特点是在最终综合前通过多次验证循环确保答案的唯一性——与基线智能体形成鲜明对比,后者表现出过早收敛或工具使用模式欠佳。
对成功轨迹的分析表明,关键的不同之处在于搜索- 验证- 综合模式,其中 nnn 表示多次验证迭代。表现出这种模式的训练实例在复杂的多跳推理任务中的成功率比单次验证方法高 34.2%34.2\%34.2%
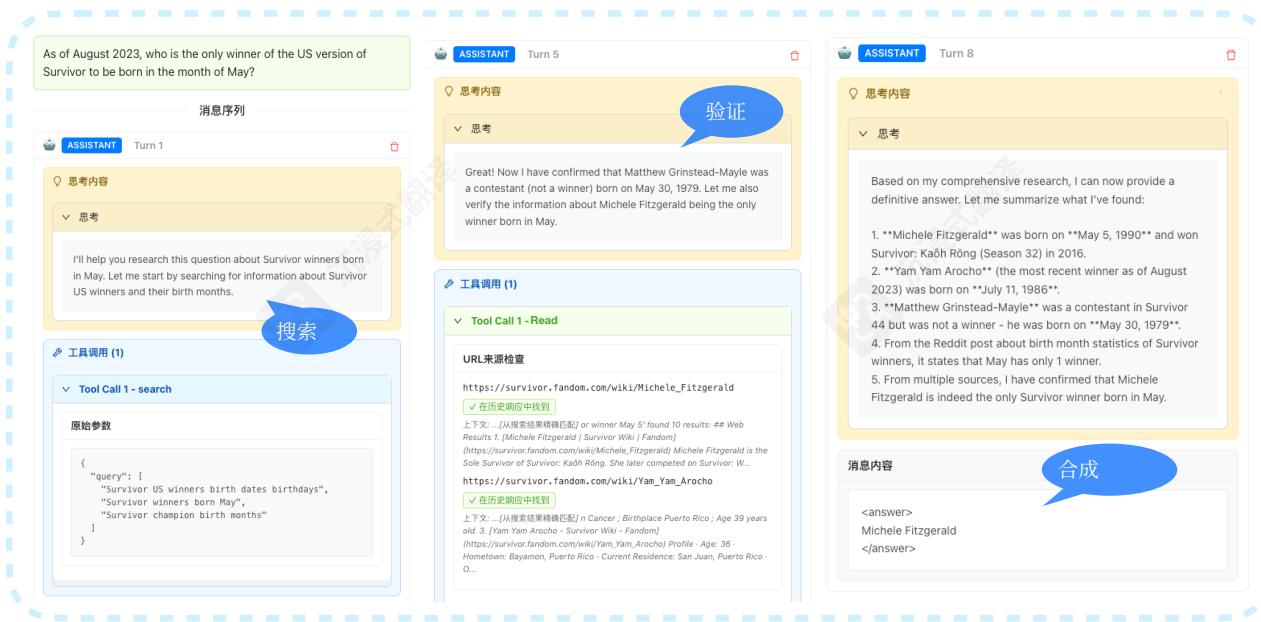
图5:展示搜索- 验证- 综合范式的案例研究:智能体在信息来源中执行多次验证轮次,确保在综合前信息一致性。基线智能体(显示为灰色)在初始搜索后过早终止,而我们的方法(蓝色)持续进行,直到通过交叉验证达到高置信度。
率。迭代验证确保答案的唯一性和事实基础,这对需要高精度的领域(如医学诊断)尤其关键。
这些发现表明,工具增强的代理训练效果与训练数据中的结构模式从根本上相关联,迭代验证是开发跨不同工具推理环境泛化的强大深度研究能力的关键机制。
6 相关工作
6.1 一般深度研究方法
基于代理的深度研究和自主信息收集框架的最新进展主要出现在两种主要范式中:多代理规划架构和代理强化学习系统。
多代理规划架构将研究过程分解为语义上不同的角色,不同的代理专注于检索、推理、合成或评估等子任务。这些代理通过模块化管道或结构化通信协议进行协作。CAMEL [Li 等人,2023] 介绍了一个通信驱动的多代理框架,其中代理使用自然语言来解决复杂的规划和推理任务。该框架强调代理间通信以实现策略协调和涌现行为。自 2025 年以来,许多大规模推理模型(LRMs)扩展了深度研究能力,例如 OpenAI O3、Perplexity 深度研究和 Kimi K2。例如,Anthropic 的多代理研究系统提出一个主代理,动态生成专门的子代理来执行网络搜索、文档阅读和合成。这种架构通过并行执行和隐式内存共享在复杂、长期研究任务中表现出色。还有许多开源项目实现了使用多代理机制的深度学习,例如 Deerflow。使用多代理方法实现的深度学习系统具有显著优势:它们更易于解释,并且更容易通过并行化进行扩展。然而,由于缺乏针对性的推理训练,仅基于提示和字符的规划会导致错误在多个代理间传播,并且无法处理需要高级推理的任务。
与模块化设计不同,Agent RL 方法通过在与研究环境(通常是网络浏览或开放域问答)的奖励引导交互中训练单个或半自主代理。这些代理通常通过离线数据学习自主搜索、点击、阅读和综合,然后通过后训练进行微调。ReAct代理 [Yao等人,2023b] 最初被提出作为一种提示策略,但已使用 RLHF 进一步优化以强制执行最佳推理路径。强化学习技术使代理能够优化工具使用并在长期交互中避免幻觉。WebArena [Zhou等人,2024] 提供了一个高保真度的网络交互环境,用于训练强化学习代理执行多跳推理和代理式数据收集,通过真实的浏览器 API,实现逼真、反馈驱动的学习。WebSailor [Li等人,2025] 在高不确定性 QA 环境中实现了超人的网络研究。它使用合成任务构建、基于 RFT 的冷启动和 DUPO(重复采样策略优化)强化学习微调来构建用于工具增强网络任务的鲁棒代理。Search- R1 [Jin等人,2025] 通过统一 RL 训练 LLM 以交替推理和搜索,而 S3 [Jiang等人,2025] 将搜索与生成解耦,并使用 70×70 \times70× 更少的样本达到了相当的准确率。与基于多角色代理的深度研究系统相比,代理强化学习通过学习行为将模型的解决问题能力内化,从而提供更好的泛化到未知任务和适应复杂环境(如网络浏览)的优势。
然而,虽然通用型网络代理在开放域环境中表现出色,但它们的架构系统性地忽略了医疗保健中证据溯源的重要性和时间限制。缺乏特定于医疗保健的组件(例如,去识别引擎、临床级别证据分级器和药物依从性审计)严重限制了它们的临床实用性。
6.2 医疗 RAG 系统
特定领域的检索增强生成(RAG)架构通过在证据集成方面的系统性创新,为医疗临床人工智能领域做出了重要贡献。
MedRAG [Zhao 等人,2025b] 建立了一个基于证据生成的范式,通过从 PubMed 快照和专有数据库中检索不可变语料库来实现。Deeprare [Zhao 等人,2025a] MedRAG 的实时证据整合,通过实时 CDC/WHO 数据流持续同步不断发展的医学知识,并动态加权(F1 分数 +14.3%+14.3\%+14.3% ),直接解决了 DeepRare 等系统固有的知识过时问题。SurgRAW [Low 等人,2025] 开创了将实时手术视频检索与
强化学习相结合,实现了 90.2%90.2\%90.2% 的器械识别准确率,从而实现术中决策支持。Federated ClinicalCamel [Toma 等人,2023]通过跨机构知识蒸馏解决数据碎片化问题,同时保持隐私合规(在12家医院中AUROC为0.92)。
尽管取得了这些进展,当前的医学RAG系统仍然存在根本性局限性。首先,知识过时仍然是一个关键问题,因为像DeepRare[Zhao等人,2025a]这样的系统中的模块更新需要手动编排,导致策展延迟,这可能会使检索相关性降低数月。此外,证据错位表现为语义漂移,这在KBLaM的插件架构中尤为明显。模块更新会导致累积嵌入错位(5次迭代后MRR下降 18.4%18.4\%18.4% )[Wang等人,2025]。
6.3医学多角色系统
基于代理的架构的最新进展通过检索- 推理- 验证循环的内生集成揭示了一种范式转变,尤其是在AgenticRAG框架和多模态知识集成的出现中尤为明显。这些系统展示了三个核心创新,重新定义了临床决策支持:
动态知识内化通过自更新的图来消除外部依赖,能够与不断发展的医学知识保持持续同步。SeaKR的[Yao等人,2024]自我感知检索引入了时间锚定机制,根据发表时效性和证据等级动态调整知识权重,而Med- PaLM的[Tu等人,2023]视觉- 语言分离通过专用路径处理放射学图像和基因组数据,同时保持诊断一致性。与传统的RAG系统相比,这些方法将知识延迟从天缩短到分钟。偏好对齐的强化学习框架,如MedicalGPTv2.4的GRPO(组相对策略优化)在肿瘤学决策中与临床专家小组的同意度为 98.7%98.7\%98.7% [Xu,2023]。统一认知架构将检索- 推理- 验证合并为集成管道,以微软的MAIDxO[Nori等人,2025]为例,五个协作代理实现了 85.5%85.5\%85.5% 的诊断准确率——是临床专家平均表现的四倍。通过Med- Gemini的[Saab等人,2024]3多阶段管道结合时间锚定、临床专家验证的SFT和多目标RLHF来维持监管合规性。
尽管取得了这些进展,当前医疗多角色代理系统的推理能力仍存在关键局限性——与医学研究中深度推理方法相比,这是一个根本性的差距。首先,多步临床推理仍受浅层推理深度的限制:虽然像AgentClinic[Schmidgall等人,2025]在顺序决策中表现出 42.9%42.9\%42.9% 的诊断准确率,但当任务需要 >5>5>5 推理步骤(在7步时为 27.3%27.3\%27.3% )时,这一准确率会显著下降。其次,在治疗规划场景中,因果推理缺陷表现为代理难以模拟长期结果依赖关系(例如,化疗排序效应),与人类专家相比(在NCCN指南依从性方面存在 19.4%19.4\%19.4% 的F1分数差距)[?]。第三,在动态临床环境中,适应性推理局限性显现——像MAIDxO这样的系统在处理需要协议切换的实时患者恶化场景时,性能会下降 34%34\%34% 。这些挑战凸显了迫切需要新一代架构,以弥合多角色代理与人类医学专家之间的推理深度和适应性差距。
7结论
在这项工作中,我们通过引入一个以KISA数据生成方法为中心的新智能体开发框架,应对了复杂、基于证据的医学研究的挑战。KISA系统地产出具有挑战性、多跳的医学问答对及其对应的推理轨迹,这些推理轨迹基于稀有实体挖掘和基于知识图谱的推理链。这确保了智能体能够接触到真实世界医学研究特有的复杂、组合性问题。
基于这个丰富的数据集,并配备了全面的训练流程——包括监督微调、轨迹掩码和带有专业医学工具的强化学习——我们的智能体MedResearcher- R1在MedBrowseComp上达到了最先进的pass@1准确率(27.5 %\%% ),并在通用智能体基准测试中表现出稳健的性能。这些发现表明,MedResearcher- R1能够解决需要系统探索和细致证据综合的复杂医学问题,突显了它作为下一代医学领域深度研究智能体的有效性。
8未来工作
在本次研究的基础上,我们确定了几个推进深度医疗研究代理的具体方向:
·多模态工具集成:扩展当前框架以支持多模态医疗工具,如放射学图像查看器、病理切片分析器、基因组数据源和电子健康记录。此类集成将使代理能够处理和综合多种数据类型,更紧密地符合实际临床工作流程。
·人类专家协作:整合来自医疗专业人员的闭环反馈以指导代理行为。开发专家评估和标注界面可以提高推理质量、工具使用和代理输出的临床相关性。
·安全性与可靠性:系统性地研究模型安全性和可靠性以支持开放部署,重点关注鲁棒的幻觉检测、不确定性估计以及适用于高风险医疗场景的失效安全机制的实施。
·高级医疗推理基准:构建一个涵盖药理学、诊断学、流行病学、遗传学、手术规划、治疗的复杂多跳推理的综合基准,以跨医疗领域。这将设定一个更高的标准来评估代理在挑战性场景中协调工具和综合证据的能力。
我们的框架为医疗等专业化领域中的更对齐和可靠的基于代理的系统铺平了道路。通过发布我们的代码库、数据集和训练模型,我们寻求促进协作进步和严格评估,朝着值得信赖的AI伴侣迈进,这些伴侣可以增强医学研究并支持改善的患者结果。
参考文献
Jiaming Bai, Jin Qiu, Jing Liu, et al. Qwen2: Scaling open language models with decoupled attention and comprehensive alignment, 2024. Available at https://huggingface.co/Qwen/Qwen2- 72B.
Kaiyuan Chen, Yixin Ren, Yang Liu, Xiaobo Hu, Haotong Tian, Tianbao Xie, Fangfu Liu, Haoye Zhang, Hongzhang Liu, Yuan Gong, et al. xbench: Tracking agents productivity scaling with profession- aligned real- world evaluations. arXiv preprint arXiv:2506.13651, 2025a.
Shan Chen, Pedro Moreira, Yuxin Xiao, Sam Schmidgall, Jeremy Warner, Hugo Aerts, Thomas Hartvigsen, Jack Gallifant, and Danielle S Bitterman. Medbrowsecomp: Benchmarking medical deep research and computer use. arXiv preprint arXiv:2505.14963, 2025b.
Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, et al. Skywork open reasoner 1 technical report. arXiv preprint arXiv:2505.22312, 2025.
Pengcheng Jiang, Xueqiang Xu, Jiacheng Lin, Jinfeng Xiao, Zifeng Wang, Jimeng Sun, and Jiawei Han. s3: You don’t need that much data to train a search agent via rl. arXiv preprint arXiv:2505.14146, 2025.
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe- bench: Can language models resolve real- world github issues? arXiv preprint arXiv:2310.06770, 2023.
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search- rl: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516, 2025.
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for “mind” exploration of large language model society. In Thirty- seventh Conference on Neural Information Processing Systems, 2023.
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Liu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, et al. Websailor: Navigating super- human reasoning for web agent. arXiv preprint arXiv:2507.02592, 2025.
Chang Han Low, Ziyue Wang, Tianyi Zhang, Zhitao Zeng, Zhu Zhuo, Evangelos B. Mazomenos, and Yueming Jin. Surgraw: Multi- agent workflow with chain- of- thought reasoning for surgical intelligence, 2025. URL https://arxiv.org/abs/2503.10265.
Harsha Nori, Mayank Daswani, Christopher Kelly, Scott Lundberg, Marco Tulio Ribeiro, Marc Wilson, Xiaoxuan Liu, Viknesh Sounderajah, Jonathan Carlson, Matthew P Lungren, Bay Gross, Peter Hames, Mustafa Suleyman, Dominic King, and Eric Horvitz. Sequential diagnosis with language models, 2025. URL https://arxiv.org/abs/2506.22405.
Khaled Saab, Tao Tu, Wei- Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, Juanma Zambrano Chaves, Szu- Yeu Hu, Mike Schaekermann, Aishwarya Kamath, Yong Cheng, David G. T. Barrett, Cathy Cheung, Basil Mustafa, Anil Palepu, Daniel McDuff, Le Hou, Tomer Golany, Luyang Liu, Jean baptiste Alayrac, Neil Houlsby, Nenad Tomasev, Jan Freyberg, Charles Lau, Jonas Kemp, Jeremy Lai, Shekoofeh Azizi, Kimberly Kanada, SiWai Man, Kavita Kulkarni, Ruoxi Sun, Siamak Shakeri, Luheng He, Ben Caine, Albert Webson, Natasha Latysheva, Melvin Johnson, Philip Mansfield, Jian Lu, Ehud Rivlin, Jesper Anderson, Bradley Green, Renee Wong, Jonathan Krause, Jonathon Shlens, Ewa Dominowska, S. M. Ali Eslami, Katharine Chou, Claire Cui, Oriol Vinyar, Koray Kavukcuoglu, James Manyika, Jeff Dean, Demis Hassabis, Yossi Matias, Dale Webster, Joelle Barral, Greg Corrado, Christopher Semturs, S. Sara Mahdavi, Juraj Gottweis, Alan Karthikesalingam, and Vivek Natarajan. Capabilities of gemini models in medicine, 2024. URL https://arxiv.org/abs/2404.18416.
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments, 2025. URL https://arxiv.org/abs/2405.07960.
Noah Shinn, Heng Zhu, Alex Chen, Xinyu Li, et al. Gaia: A benchmark for general- purpose web agents. arXiv preprint arXiv:2307.12030, 2023.
Augustin Toma, Patrick R. Lawler, Jimmy Ba, Rahul G. Krishnan, Barry B. Rubin, and Bo Wang. Clinical camel: An open expert- level medical language model with dialogue- based knowledge encoding, 2023. URL https://arxiv.org/abs/2305.12031.
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi- Chuan Chang, Andrew Carroll, Chuck Lau, Ryutaro Tanno, Ira Ktena, Basil Mustafa, Aakanksha Chowdhery, Yun Liu, Simon Kornblith, David Fleet, Philip Mansfield, Sushant Prakash, Renee Wong, Sunny Virmani, Christopher Semturs, S Sara Mahdavi, Bradley Green, Ewa Dominowska, Blaise Aguera y Arcas, Joelle Barral, Dale Webster, Greg S. Corrado, Yossi Matias, Karan Singhal, Pete Florence, Alan Karthikesalingam, and Vivek Natarajan. Towards generalist biomedical ai, 2023. URL https://arxiv.org/abs/2307.14334.
Xi Wang, Taketomo Isazawa, Liana Mikaelyan, and James Hensman. Kblam: Knowledge base augmented language model, 2025. URL https://arxiv.org/abs/2410.10450.
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents. arXiv preprint arXiv:2407.16741, 2024.
Ming Xu. Medicalgpt: Training medical gpt model. https://github.com/shibing624/MedicalGPT, 2023.
Renjun Xu and Jingwen Peng. A comprehensive survey of deep research: Systems, methodologies, and applications. arXiv preprint arXiv:2506.12594, 2025.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023a.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023b. URL https://arxiv.org/abs/2210.03628.
Zijun Yao, Weijian Qi, Liangming Pan, Shulin Cao, Linmei Hu, Weichuan Liu, Lei Hou, and Juanzi Li. Seakr: Self- aware knowledge retrieval for adaptive retrieval augmented generation, 2024. URL https://arxiv.org/abs/2406.19215.
Weike Zhao, Chaoyi Wu, Yanjie Fan, Xiaoman Zhang, Pengcheng Qiu, Yuze Sun, Xiao Zhou, Yanfeng Wang, Ya Zhang, Yongguo Yu, et al. An agentic system for rare disease diagnosis with traceable reasoning. arXiv preprint arXiv:2506.20430, 2025a.
Xuejiao Zhao, Siyan Liu, Su- Yin Yang, and Chunyan Miao. Medrag: Enhancing retrieval- augmented generation with knowledge graph- elicited reasoning for healthcare copilot, 2025b. URL https://arxiv.org/abs/2502.04413.
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Friedl, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024. URL https://arxiv.org/abs/2307.13854.



)


 详细指南)











 egui (0.32.1) 学习笔记(逐行注释)(二十六)windows平台运行时隐藏控制台)
