文章目录
- 一、本文知识覆盖范围
- 1、概述
- 2、知识体系概览
- 二、系统可靠性基础概念
- 1、可靠性与可用性的本质区别
- 2、软件可靠性与硬件可靠性的深度对比
- 3、核心可靠性指标的业务价值
- 三、系统架构可靠性模型
- 1、串联系统的可靠性挑战
- 2、并联系统的高可靠性设计
- 3、混合系统的复杂性管理
- 四、可靠性建模与评估方法
- 1、可靠性建模方法的分类与应用
- 2、实用建模方法的深度应用
- 五、影响软件可靠性的关键因素
- 1、开发方法与环境的深度影响
- 2、运行环境的复杂性挑战
- 3、软件规模与复杂度的管理
- 六、容错设计技术详解
- 1、N版本程序设计的工程实践
- 2、恢复块方法的动态容错
- 3、防卫式程序设计的实用策略
- 七、高可用系统架构设计
- 1、双机容错系统的工程实现
- 2、集群容错的扩展性设计
- 3、冗余设计的系统化方法
- 八、实际应用指导
- 1、可靠性设计的分阶段实施策略
- 2、可靠性技术选择指南
- 3、常见可靠性问题及解决方案
- 4、可靠性测试与验证方法
- 5、可靠性运维最佳实践
系统可靠性分析与设计是构建高质量软件系统的核心技术能力,通过系统学习和实践这些技术,我们能够构建出既稳定可靠又高效运行的现代化软件系统。
- 可靠性分析能力:掌握系统可靠性建模和量化评估方法
- 容错设计能力:熟练运用各种容错技术,设计高可靠系统架构
- 故障处理能力:具备快速故障定位、分析和恢复的实战能力
- 预防性思维:建立从设计阶段就考虑可靠性的工程思维
一、本文知识覆盖范围
1、概述
系统可靠性分析与设计能够:
- 降低业务损失:通过可靠性设计,系统故障时间从小时级降低到分钟级,避免重大业务损失
- 提升用户体验:系统可用性从99%提升到99.99%,用户满意度显著提升
- 减少运维成本:通过容错设计,人工干预次数减少80%,运维效率大幅提升
- 保障企业声誉:避免因系统故障导致的品牌形象损害和客户流失
知识应用场景:
- 金融交易系统(银行核心系统、支付平台、证券交易)
- 电商平台(双11大促、订单处理、库存管理)
- 工业控制系统(生产线控制、安全监控、设备管理)
- 通信网络系统(电信基础设施、互联网服务、云计算平台)
2、知识体系概览
本文涵盖系统可靠性分析与设计的完整技术体系:
| 知识模块 | 具体内容 | 学习重点 |
|---|---|---|
| 可靠性基础概念 | 可靠性定义、软硬件可靠性对比、关键指标 | 理解可靠性与可用性区别,掌握MTBF、MTTR等核心指标 |
| 系统架构模型 | 串联系统、并联系统、混合系统可靠性计算 | 学会不同架构的可靠性评估和设计选择 |
| 可靠性建模方法 | 数学模型、统计模型、结构分析模型 | 掌握可靠性预测和评估的量化方法 |
| 影响因素分析 | 开发方法、运行环境、软件规模等因素 | 识别和控制影响可靠性的关键因素 |
| 容错设计技术 | N版本程序、恢复块、防卫式编程 | 掌握主流容错技术的原理和应用场景 |
| 高可用架构 | 双机热备、集群容错、冗余设计 | 学会设计和实施高可用系统架构 |
二、系统可靠性基础概念
1、可靠性与可用性的本质区别
| 对比维度 | 可靠性关注点 | 可用性关注点 | 实际业务影响 |
|---|---|---|---|
| 设计目标 | 系统不出错、出错后能恢复 | 系统大部分时间可用 | 可靠性影响数据安全 可用性影响用户体验 |
| 衡量标准 | 故障处理能力、错误率 | 正常运行时间比例 | 金融系统更重视可靠性 社交媒体更重视可用性 |
| 技术手段 | 容错设计、冗余备份 | 负载均衡、快速恢复 | 容错技术成本高但安全 负载均衡成本低但复杂 |
| 故障影响 | 数据丢失、功能异常 | 服务暂时不可访问 | 可靠性故障后果严重 可用性故障影响范围大 |
2、软件可靠性与硬件可靠性的深度对比

复杂性维度的深度分析:
| 复杂性类型 | 软件系统 | 硬件系统 | 实际影响 |
|---|---|---|---|
| 逻辑复杂度 | 百万行代码、复杂算法逻辑 | 电路逻辑相对固定 | 软件缺陷数量级更高 |
| 交互复杂度 | 模块间调用关系错综复杂 | 硬件接口相对标准化 | 软件集成测试更困难 |
| 状态复杂度 | 系统状态空间巨大 | 硬件状态相对有限 | 软件状态测试覆盖困难 |
| 环境复杂度 | 依赖操作系统、中间件等 | 物理环境相对稳定 | 软件兼容性问题更多 |
失效模式的本质差异:
| 失效特征 | 软件失效模式 | 硬件失效模式 | 应对策略差异 |
|---|---|---|---|
| 失效原因 | 逻辑错误、设计缺陷 | 物理磨损、环境影响 | 软件需要逻辑验证 硬件需要物理防护 |
| 失效规律 | 随机性强、难以预测 | 遵循物理规律、可预测 | 软件需要统计分析 硬件可用物理模型 |
| 修复方式 | 软件补丁、版本升级 | 硬件更换、维修 | 软件修复快但影响大 硬件修复慢但局部 |
| 预防措施 | 代码审查、测试验证 | 冗余设计、定期维护 | 软件重在开发阶段 硬件重在运行阶段 |
3、核心可靠性指标的业务价值
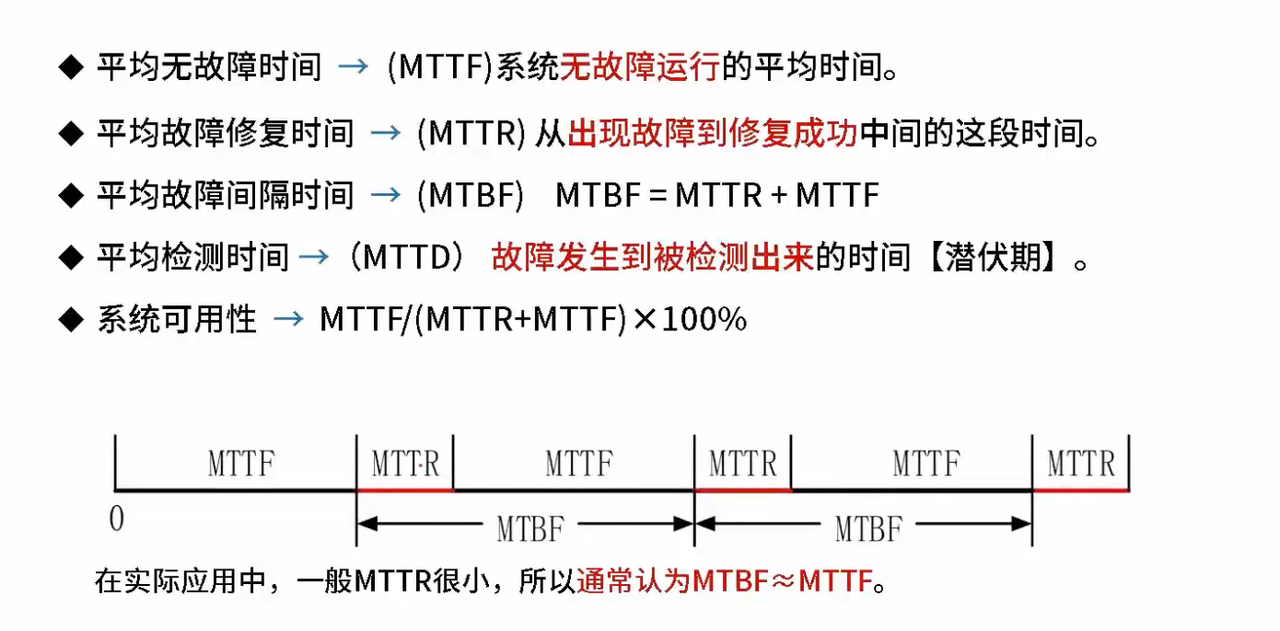
| 可靠性指标 | 计算公式 | 业务含义 | 优化策略 | 典型目标值 |
|---|---|---|---|---|
| MTTF | 总正常运行时间/故障次数 | 系统稳定性水平 | 提升代码质量 加强测试验证 | 互联网服务:720小时 金融系统:8760小时 |
| MTTR | 总修复时间/故障次数 | 故障响应效率 | 自动化监控 快速定位工具 | 互联网服务:30分钟 金融系统:15分钟 |
| MTBF | MTTF + MTTR | 整体可靠性水平 | 平衡预防和响应 | 互联网服务:750小时 金融系统:8775小时 |
| 可用性 | MTTF/(MTTF+MTTR)×100% | 用户服务体验 | 同时优化MTTF和MTTR | 99.9%(8.76小时/年) 99.99%(52.6分钟/年) |
不同行业的可靠性要求对比:
| 行业领域 | 可用性要求 | 年停机时间 | MTBF目标 | MTTR目标 | 业务影响 |
|---|---|---|---|---|---|
| 电商平台 | 99.9% | 8.76小时 | 720小时 | 30分钟 | 每分钟损失百万交易额 |
| 银行核心 | 99.99% | 52.6分钟 | 8760小时 | 15分钟 | 监管合规和客户信任 |
| 工业控制 | 99.999% | 5.26分钟 | 17520小时 | 5分钟 | 生产安全和设备损坏 |
| 航空航天 | 99.9999% | 31.5秒 | 87600小时 | 1分钟 | 人员安全和任务成功 |
三、系统架构可靠性模型
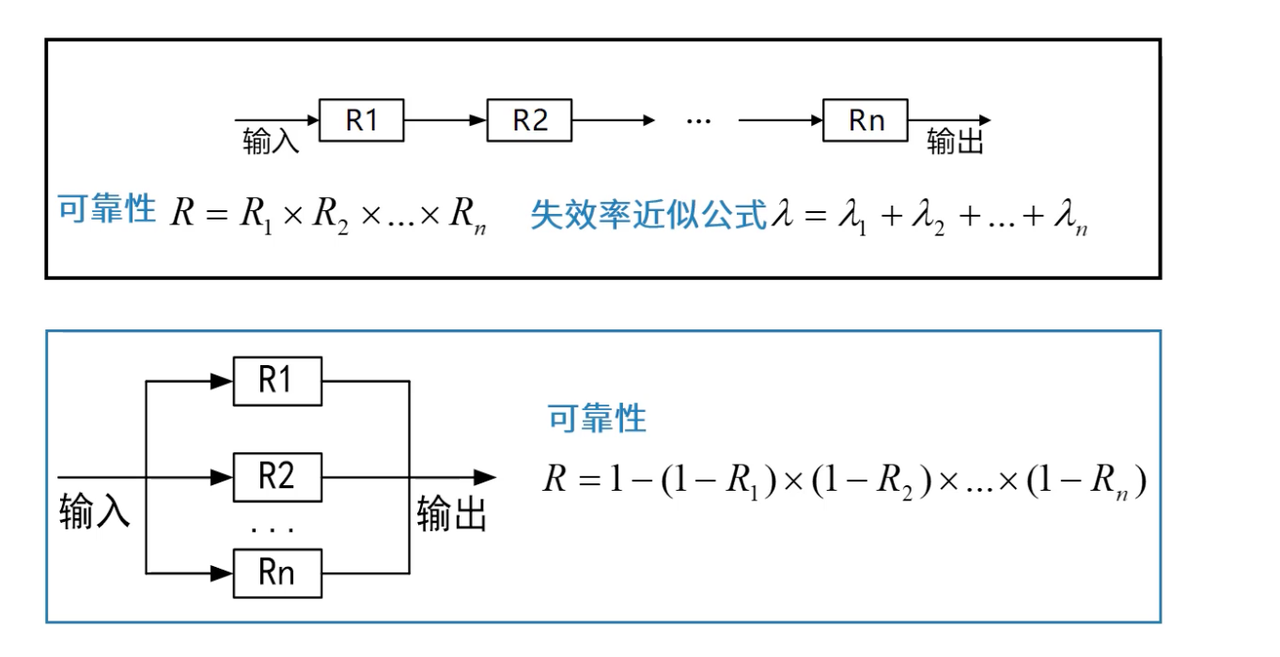
1、串联系统的可靠性挑战
串联系统的可靠性问题源于其"单点故障"特性:
- 故障传播效应:任何一个组件的故障都会导致整个系统失效
- 可靠性乘积效应:系统可靠性是各组件可靠性的乘积,必然低于最低的组件可靠性
- 复杂度累积效应:组件数量增加时,系统整体可靠性呈指数级下降
- 维护复杂性:需要确保所有组件都正常工作,维护成本高
串联系统可靠性计算的实际应用:
| 组件数量 | 单组件可靠性 | 系统可靠性 | 可用性影响 | 实际案例 |
|---|---|---|---|---|
| 3个组件 | 0.9 | 0.729 | 年停机时间增加到75小时 | 简单Web应用 (Web服务器+应用服务器+数据库) |
| 5个组件 | 0.9 | 0.590 | 年停机时间增加到120小时 | 传统企业应用 (负载均衡+Web+应用+缓存+数据库) |
| 10个组件 | 0.9 | 0.349 | 年停机时间增加到190小时 | 复杂分布式系统 (多层架构+中间件+存储) |
串联系统的优化策略:
| 优化方向 | 具体措施 | 效果预期 | 实施难度 | 成本影响 |
|---|---|---|---|---|
| 减少组件数量 | 功能合并、架构简化 | 可靠性提升50% | 中等 | 开发成本增加 |
| 提升组件质量 | 严格测试、代码审查 | 单组件可靠性提升到0.95+ | 高 | 质量保证成本增加 |
| 快速故障恢复 | 自动重启、健康检查 | MTTR从小时级降到分钟级 | 中等 | 运维工具投入 |
| 监控告警 | 实时监控、预警机制 | 故障发现时间缩短90% | 低 | 监控系统成本 |
2、并联系统的高可靠性设计
并联系统的可靠性优势
并联系统通过冗余设计实现高可靠性,是关键业务系统的首选架构:
并联系统可靠性提升的数学原理:
并联系统的可靠性计算公式:R = 1 - (1-R₁)×(1-R₂)×…×(1-Rₙ)
这个公式的核心思想是:只要有一个组件正常工作,系统就能正常运行。
并联系统可靠性提升效果分析:
| 并联组件数 | 单组件可靠性 | 系统可靠性 | 可靠性提升倍数 | 典型应用场景 |
|---|---|---|---|---|
| 2个组件 | 0.9 | 0.99 | 1.1倍 | 双机热备系统 |
| 3个组件 | 0.9 | 0.999 | 1.11倍 | 三副本存储系统 |
| 5个组件 | 0.9 | 0.99999 | 1.11倍 | 高可用集群系统 |
| 10个组件 | 0.9 | 0.9999999999 | 1.11倍 | 大规模分布式系统 |
并联系统的设计考虑因素:
| 设计因素 | 技术挑战 | 解决方案 | 业务价值 |
|---|---|---|---|
| 负载分配 | 如何均匀分配负载 | 负载均衡算法 动态权重调整 | 资源利用率提升30% |
| 故障检测 | 如何快速发现故障组件 | 健康检查机制 心跳监控 | 故障发现时间<1分钟 |
| 自动切换 | 如何实现无缝切换 | 自动故障转移 会话保持 | 用户无感知切换 |
| 数据一致性 | 如何保证数据同步 | 主从复制 分布式一致性算法 | 数据一致性>99.9% |
3、混合系统的复杂性管理
现实系统的架构复杂性
实际的企业级系统往往是串联和并联的复杂组合,需要综合考虑可靠性设计:
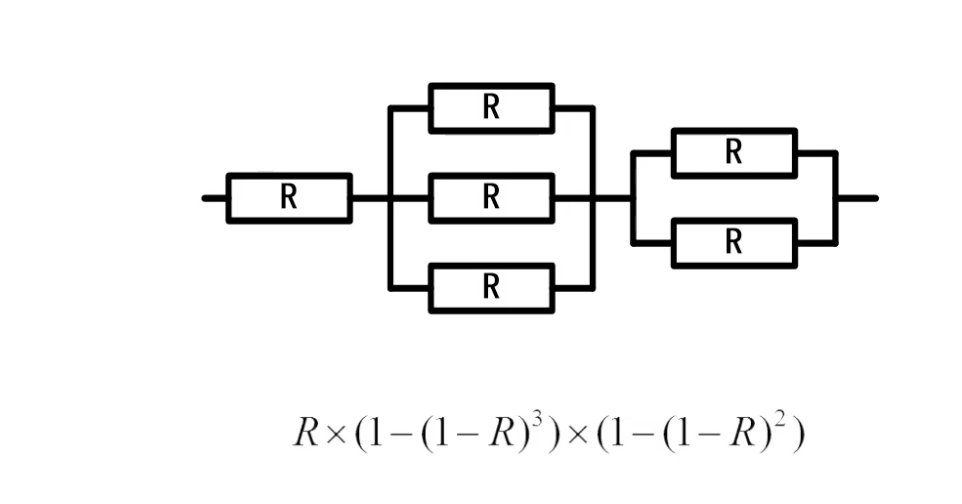
混合系统的可靠性分析方法:
- 分层分析法:将复杂系统分解为多个子系统,分别分析每个子系统的可靠性
- 关键路径分析:识别影响整体可靠性的关键路径和瓶颈组件
- 故障模式分析:分析不同故障模式对系统整体的影响程度
- 蒙特卡洛仿真:通过随机模拟评估复杂系统的可靠性表现
典型混合系统架构分析:
| 系统层次 | 架构模式 | 可靠性计算 | 关键风险点 | 优化重点 |
|---|---|---|---|---|
| 接入层 | 并联(多个负载均衡器) | R₁ = 1-(1-0.99)² = 0.9999 | 负载均衡器故障 | 增加节点数量 |
| 应用层 | 并联(多个应用服务器) | R₂ = 1-(1-0.95)³ = 0.999875 | 应用程序缺陷 | 提升代码质量 |
| 数据层 | 串联(主从数据库) | R₃ = 0.99×0.98 = 0.9702 | 数据库主节点故障 | 实现自动切换 |
| 整体系统 | 串联组合 | R = R₁×R₂×R₃ = 0.9697 | 数据层是瓶颈 | 重点优化数据层 |
四、可靠性建模与评估方法
1、可靠性建模方法的分类与应用
不同建模方法的适用场景分析:

| 建模方法 | 核心原理 | 适用场景 | 优势 | 局限性 |
|---|---|---|---|---|
| 种子法模型 | 预设已知错误评估检测能力 | 测试阶段可靠性评估 | 操作简单、成本低 | 依赖人工设置错误 |
| 失效率模型 | 数学函数描述失效率变化 | 软件生命周期管理 | 理论基础扎实 | 参数估计困难 |
| 曲线拟合模型 | 统计回归分析变量关系 | 历史数据丰富的系统 | 基于实际数据 | 需要大量历史数据 |
| 可靠性增长模型 | 增长函数描述改进过程 | 迭代开发过程 | 动态反映改进效果 | 假设条件较强 |
| 马尔可夫模型 | 状态转移概率描述 | 状态变化明确的系统 | 数学模型严密 | 状态空间复杂 |
2、实用建模方法的深度应用
马尔可夫过程模型的企业级应用
马尔可夫模型特别适合分析系统状态转换,在企业级系统可靠性分析中应用广泛:
系统状态定义与转移分析:
| 系统状态 | 状态描述 | 转移条件 | 业务影响 | 恢复策略 |
|---|---|---|---|---|
| 正常运行 | 所有功能正常 | λ(故障率) | 无影响 | 预防性维护 |
| 部分故障 | 部分功能异常 | μ₁(修复率) | 功能受限 | 快速修复 |
| 系统故障 | 系统完全不可用 | μ₂(恢复率) | 业务中断 | 紧急恢复 |
| 维护状态 | 计划维护中 | ν(维护完成率) | 计划停机 | 计划内恢复 |
贝叶斯分析模型的动态优化
贝叶斯方法能够结合先验知识和实时数据,动态优化可靠性评估:
贝叶斯模型的实际应用价值:
| 应用阶段 | 先验信息来源 | 观测数据类型 | 后验结果应用 | 业务价值 |
|---|---|---|---|---|
| 设计阶段 | 类似系统经验 | 设计评审结果 | 设计方案优化 | 降低设计风险 |
| 测试阶段 | 设计阶段评估 | 测试缺陷数据 | 测试策略调整 | 提升测试效率 |
| 运行阶段 | 测试阶段数据 | 运行故障数据 | 维护计划制定 | 降低运维成本 |
| 优化阶段 | 运行历史数据 | 改进效果数据 | 持续改进方向 | 持续价值提升 |
五、影响软件可靠性的关键因素
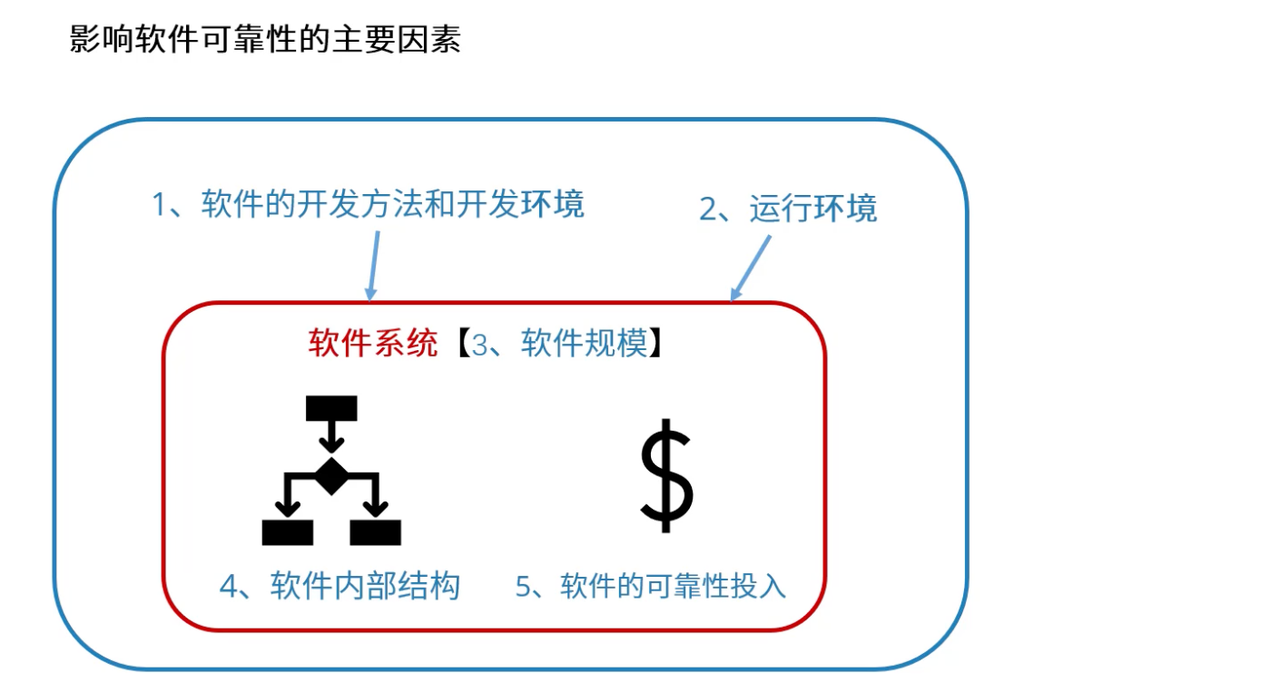
1、开发方法与环境的深度影响
开发方法论对可靠性的决定性作用
不同的开发方法论对软件可靠性有着根本性的影响,选择合适的开发方法是保障可靠性的第一步:
主流开发方法的可靠性对比分析:
| 开发方法 | 可靠性优势 | 可靠性风险 | 适用场景 | 可靠性提升效果 |
|---|---|---|---|---|
| 瀑布模型 | 需求明确、设计完整 | 后期修改成本高 | 需求稳定的关键系统 | 设计阶段可靠性提升40% |
| 敏捷开发 | 快速响应变化、持续改进 | 文档不足、架构演进风险 | 需求变化频繁的系统 | 缺陷修复速度提升300% |
| DevOps | 开发运维一体化 | 快速发布可能引入问题 | 互联网快速迭代系统 | 故障恢复时间缩短80% |
| 极限编程 | 代码质量高、测试覆盖全 | 过度工程化风险 | 高质量要求的系统 | 代码缺陷率降低60% |
开发环境对可靠性的技术支撑:
| 环境要素 | 影响机制 | 最佳实践 | 可靠性提升 |
|---|---|---|---|
| IDE工具 | 代码提示、语法检查 | 使用现代化IDE,启用所有检查 | 编译期错误减少50% |
| 版本控制 | 代码历史、分支管理 | Git工作流、代码审查 | 代码质量问题减少30% |
| 自动化测试 | 回归测试、持续验证 | 单元测试、集成测试、端到端测试 | 缺陷发现率提升70% |
| 静态分析 | 代码质量检查 | SonarQube、Checkstyle等工具 | 潜在缺陷发现率提升40% |
2、运行环境的复杂性挑战
硬件环境对可靠性的影响分析:
| 硬件因素 | 可靠性影响 | 风险表现 | 应对策略 | 效果评估 |
|---|---|---|---|---|
| CPU性能 | 计算能力不足导致超时 | 响应时间增长、请求堆积 | 性能监控、动态扩容 | 超时错误减少80% |
| 内存容量 | 内存不足导致系统崩溃 | OutOfMemory错误 | 内存优化、垃圾回收调优 | 内存相关故障减少90% |
| 存储IO | 磁盘IO瓶颈影响性能 | 数据库操作缓慢 | SSD升级、IO优化 | 数据库性能提升5倍 |
| 网络带宽 | 网络拥塞导致通信失败 | 服务调用超时 | 网络优化、限流控制 | 网络错误减少60% |
软件环境的兼容性管理:
| 环境层次 | 兼容性挑战 | 测试策略 | 风险控制 |
|---|---|---|---|
| 操作系统 | 不同OS版本的API差异 | 多OS环境测试 | 容器化部署统一环境 |
| 运行时环境 | JVM、.NET版本差异 | 多版本兼容性测试 | 明确运行时版本要求 |
| 第三方依赖 | 依赖库版本冲突 | 依赖版本锁定测试 | 依赖管理工具使用 |
| 配置管理 | 配置参数错误 | 配置验证测试 | 配置模板化管理 |
3、软件规模与复杂度的管理
规模增长带来的可靠性挑战
软件规模的增长不是线性的可靠性问题,而是指数级的复杂度增长:
软件规模与缺陷密度关系分析:
| 代码规模 | 典型缺陷密度 | 主要风险点 | 管理策略 | 质量目标 |
|---|---|---|---|---|
| <1万行 | 1-3个/千行 | 逻辑错误、边界条件 | 代码审查、单元测试 | 缺陷密度<1个/千行 |
| 1-10万行 | 3-8个/千行 | 模块集成、接口错误 | 架构设计、集成测试 | 缺陷密度<3个/千行 |
| 10-100万行 | 8-15个/千行 | 系统集成、性能问题 | 分层架构、系统测试 | 缺陷密度<8个/千行 |
| >100万行 | 15-30个/千行 | 架构腐化、维护困难 | 微服务拆分、持续重构 | 缺陷密度<15个/千行 |
复杂度控制的技术手段:
| 复杂度类型 | 控制方法 | 技术实现 | 效果评估 |
|---|---|---|---|
| 圈复杂度 | 方法拆分、逻辑简化 | 代码重构、设计模式 | 圈复杂度<10 |
| 耦合复杂度 | 接口设计、依赖注入 | 分层架构、IoC容器 | 模块耦合度<0.3 |
| 继承复杂度 | 组合优于继承 | 设计原则、重构技术 | 继承深度<5层 |
| 数据复杂度 | 数据建模、规范化 | 数据库设计、ORM | 数据一致性>99% |
六、容错设计技术详解
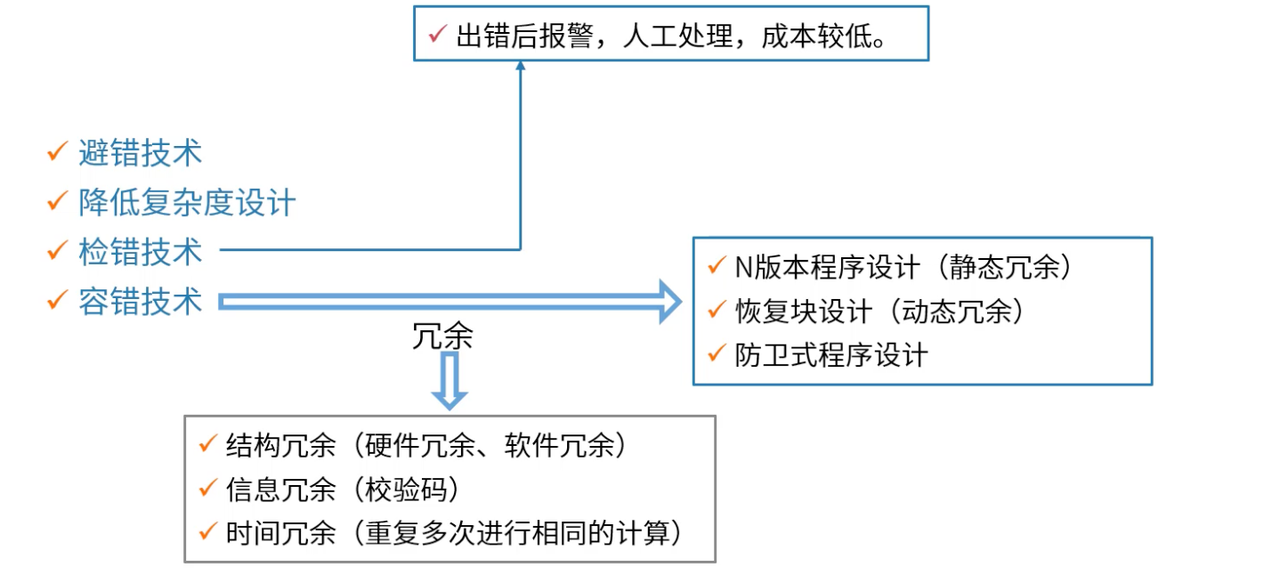
1、N版本程序设计的工程实践
N版本程序设计的核心价值与挑战
N版本程序设计通过多样性实现容错,是航空航天、核电等关键系统的标准做法:
为什么需要N版本程序设计?
传统的测试和调试方法无法完全消除软件缺陷,特别是在安全关键系统中,单一版本的软件存在系统性风险。N版本程序设计通过以下机制提升可靠性:
- 缺陷独立性假设:不同团队开发的版本,缺陷出现的位置和类型相对独立
- 多数表决机制:通过多个版本的输出比较,识别和屏蔽错误结果
- 故障掩盖能力:即使部分版本出现错误,系统仍能输出正确结果
- 持续改进机制:通过版本间的差异分析,持续改进软件质量
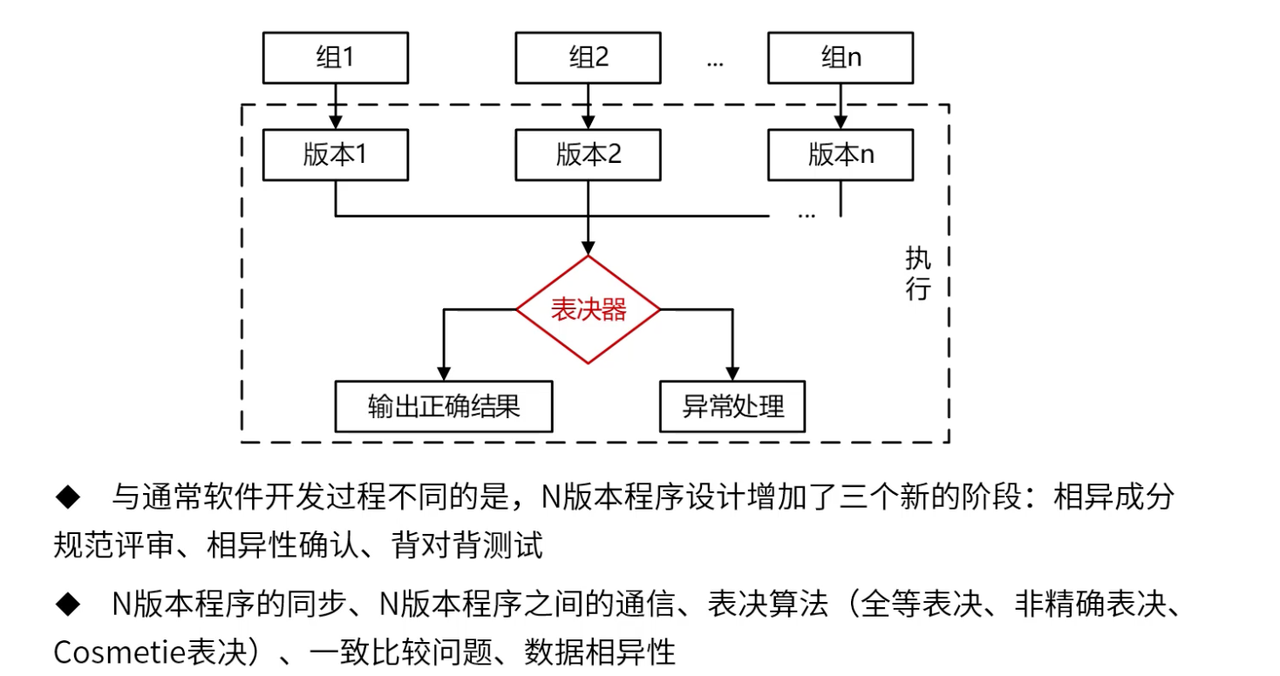
N版本程序设计的实施复杂度分析:
| 实施阶段 | 技术挑战 | 解决方案 | 成本影响 | 效果评估 |
|---|---|---|---|---|
| 需求规范 | 规范理解的一致性 | 形式化规范、需求评审 | 需求分析成本增加2倍 | 需求缺陷减少80% |
| 独立开发 | 确保开发团队的独立性 | 物理隔离、不同工具链 | 开发成本增加N倍 | 共性缺陷减少60% |
| 同步执行 | 版本间的时序同步 | 统一调度、时钟同步 | 系统复杂度增加50% | 时序错误减少90% |
| 结果表决 | 表决算法的设计 | 多种表决策略、阈值设定 | 表决开销增加10% | 错误检出率提升70% |
表决算法的选择策略:
| 表决算法 | 适用场景 | 优势 | 局限性 | 典型应用 |
|---|---|---|---|---|
| 全等表决 | 精确计算场景 | 严格一致性保证 | 对精度要求极高 | 数值计算系统 |
| 多数表决 | 一般业务场景 | 容忍度高、实用性强 | 需要奇数个版本 | 控制系统决策 |
| 加权表决 | 版本可靠性已知 | 充分利用版本差异 | 权重设定困难 | 专家系统 |
| 阈值表决 | 模糊判断场景 | 适应性强 | 阈值设定需要经验 | 模式识别系统 |
2、恢复块方法的动态容错
恢复块设计的时间效率优势
恢复块方法相比N版本程序设计,在资源利用和执行效率方面有显著优势:
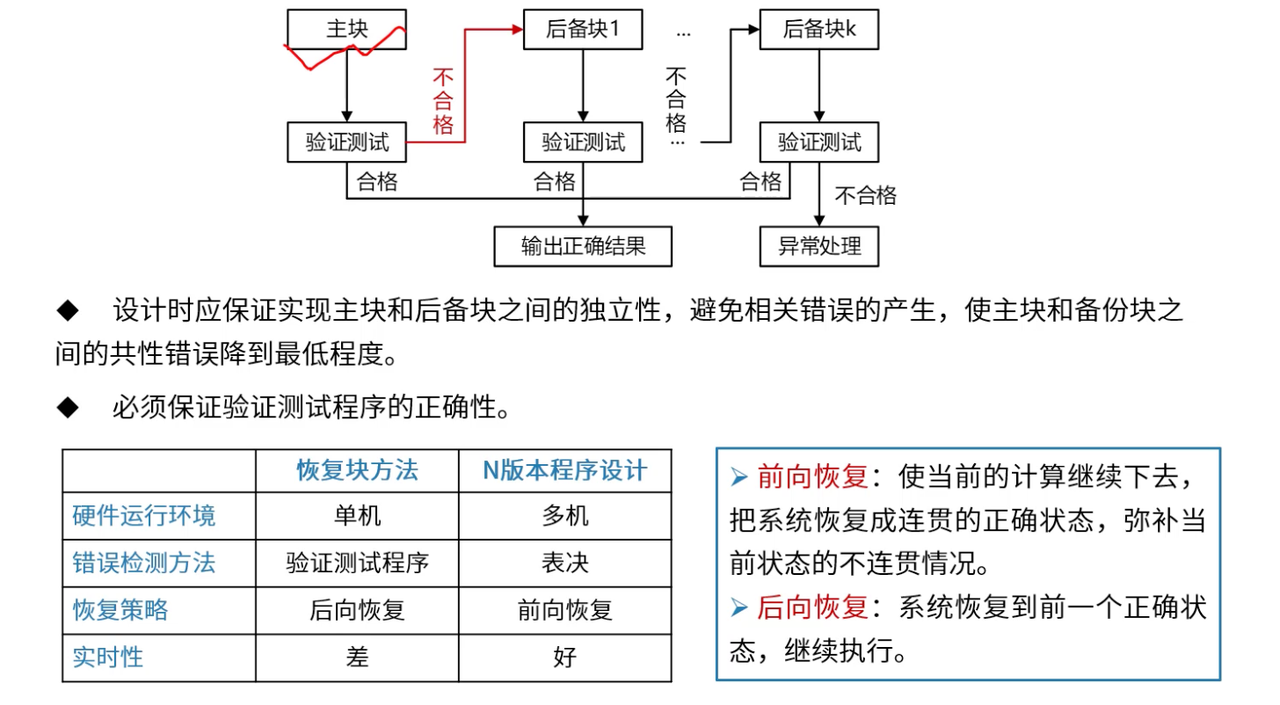
恢复块方法的执行机制:
恢复块方法采用"主备切换"的思想,正常情况下只运行主块,出现问题时才启用备份块:
| 执行阶段 | 主要活动 | 资源消耗 | 时间开销 | 可靠性贡献 |
|---|---|---|---|---|
| 主块执行 | 运行主要算法逻辑 | 1倍资源 | 正常执行时间 | 基础可靠性 |
| 验证测试 | 检查执行结果正确性 | 0.1倍资源 | 10%额外时间 | 错误检测能力 |
| 备块切换 | 启动备份块执行 | 1倍资源 | 重新执行时间 | 故障恢复能力 |
| 状态恢复 | 恢复到检查点状态 | 0.2倍资源 | 5%恢复时间 | 状态一致性 |
验证测试程序的设计要点:
验证测试程序是恢复块方法的关键组件,其质量直接影响整个方法的有效性:
| 验证维度 | 检查内容 | 实现方法 | 检查开销 | 漏检风险 |
|---|---|---|---|---|
| 输出合理性 | 结果是否在合理范围内 | 边界检查、范围验证 | 低 | 中等 |
| 不变式检查 | 程序不变式是否满足 | 断言检查、状态验证 | 中等 | 低 |
| 一致性检查 | 数据结构内部一致性 | 完整性约束检查 | 高 | 很低 |
| 性能检查 | 执行时间是否异常 | 超时检测、性能监控 | 低 | 高 |
3、防卫式程序设计的实用策略
防卫式编程的多层防护思想
防卫式程序设计通过在代码中加入大量的防护检查,实现"预防胜于治疗"的可靠性策略:
防卫式编程的实施层次:

| 防护层次 | 防护目标 | 实现技术 | 性能影响 | 可靠性提升 |
|---|---|---|---|---|
| 输入验证 | 防止无效输入 | 参数检查、格式验证 | 5-10% | 输入错误减少95% |
| 状态检查 | 确保对象状态有效 | 前置条件、后置条件 | 10-15% | 状态错误减少80% |
| 资源保护 | 防止资源泄露 | 异常处理、资源管理 | 3-5% | 资源错误减少90% |
| 边界保护 | 防止越界访问 | 数组边界检查 | 5-8% | 越界错误减少99% |
异常处理的最佳实践模式:
| 异常类型 | 处理策略 | 实现方式 | 业务影响 | 用户体验 |
|---|---|---|---|---|
| 业务异常 | 优雅降级 | 默认值、备选方案 | 功能受限但可用 | 用户可感知但可接受 |
| 系统异常 | 快速失败 | 异常抛出、错误日志 | 功能不可用 | 用户感知明显 |
| 资源异常 | 重试机制 | 指数退避、熔断器 | 临时性影响 | 用户可能无感知 |
| 网络异常 | 超时处理 | 超时设置、连接池 | 响应延迟 | 用户体验下降 |
七、高可用系统架构设计
1、双机容错系统的工程实现
双机系统的架构演进与选择
双机容错是高可用系统设计的基础,不同的双机模式适用于不同的业务场景:
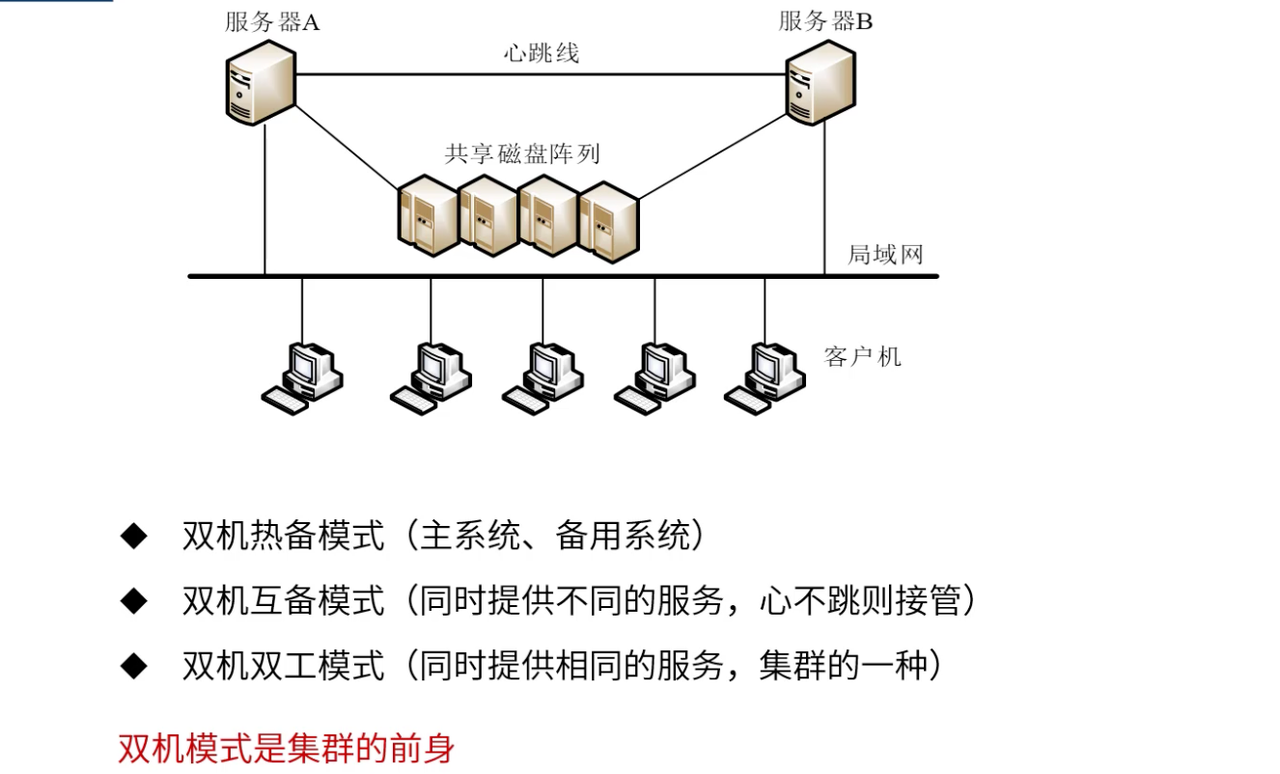
双机热备模式的深度分析:
双机热备是最常见的高可用架构,通过主备切换实现业务连续性:
| 组件类型 | 主机角色 | 备机角色 | 切换触发条件 | 切换时间 | 业务影响 |
|---|---|---|---|---|---|
| 应用服务 | 处理所有业务请求 | 实时同步状态,待命 | 主机心跳中断 | 30-60秒 | 短暂服务中断 |
| 数据库 | 处理读写操作 | 实时复制数据 | 主库故障检测 | 60-120秒 | 数据可能短暂不一致 |
| 存储系统 | 提供存储服务 | 镜像同步数据 | 存储设备故障 | 10-30秒 | 文件访问暂时中断 |
| 网络设备 | 承载网络流量 | 配置同步 | 网络中断检测 | 5-15秒 | 网络连接短暂中断 |
双机互备模式的负载优化:
双机互备模式通过相互备份,提高了资源利用率:
| 业务配置 | 正常状态 | 故障状态 | 资源利用率 | 性能影响 | 适用场景 |
|---|---|---|---|---|---|
| 业务A+业务B | 各自运行在专用机器 | 单机承担双业务 | 100% | 性能下降50% | 业务独立性强 |
| 相同业务 | 负载均衡分担 | 单机承担全部负载 | 100% | 性能下降50% | 业务负载可预测 |
| 主次业务 | 主业务+次业务分离 | 主业务优先保障 | 90% | 次业务可能停止 | 业务优先级明确 |
2、集群容错的扩展性设计
从双机到集群的架构演进
集群架构是双机模式的自然演进,通过多节点协作实现更高的可用性和性能:
集群架构的核心技术组件:
| 技术组件 | 功能作用 | 实现方案 | 技术难点 | 业务价值 |
|---|---|---|---|---|
| 负载均衡 | 流量分发、故障隔离 | 硬件LB、软件LB、DNS轮询 | 会话保持、健康检查 | 性能线性扩展 |
| 服务发现 | 节点注册、状态管理 | Consul、Eureka、Zookeeper | 网络分区、脑裂问题 | 自动化运维 |
| 配置管理 | 统一配置、动态更新 | Apollo、Nacos、Consul | 配置一致性、版本管理 | 运维效率提升 |
| 监控告警 | 状态监控、异常告警 | Prometheus、Grafana | 指标采集、告警策略 | 故障快速响应 |
集群容错的可靠性计算:
集群系统的可靠性计算比双机系统更复杂,需要考虑多种故障模式:
| 集群规模 | 单节点可靠性 | 最少存活节点 | 系统可靠性 | 可用性等级 | 典型应用 |
|---|---|---|---|---|---|
| 3节点 | 0.99 | 2个节点 | 0.999702 | 99.97% | 小型关键系统 |
| 5节点 | 0.99 | 3个节点 | 0.9999999 | 99.99999% | 中型企业系统 |
| 7节点 | 0.99 | 4个节点 | 0.999999999 | 99.9999999% | 大型互联网系统 |
3、冗余设计的系统化方法
多维度冗余的协同设计
高可用系统需要在多个维度实现冗余,形成完整的容错体系:
结构冗余的设计策略:
| 冗余类型 | 冗余方式 | 实现成本 | 可靠性提升 | 维护复杂度 | 适用场景 |
|---|---|---|---|---|---|
| 硬件冗余 | 多台服务器、存储设备 | 高(2-5倍成本) | 显著 | 中等 | 关键业务系统 |
| 软件冗余 | 多版本程序、多个实例 | 中等(开发成本增加) | 显著 | 高 | 安全关键系统 |
| 网络冗余 | 多条网络链路、多个ISP | 中等(带宽成本增加) | 中等 | 中等 | 网络依赖系统 |
| 数据冗余 | 多副本存储、异地备份 | 中等(存储成本增加) | 高 | 高 | 数据密集型系统 |
信息冗余的错误检测与纠正:
| 冗余技术 | 检测能力 | 纠正能力 | 冗余开销 | 应用场景 |
|---|---|---|---|---|
| 奇偶校验 | 单bit错误 | 无 | 12.5% | 内存保护 |
| 海明码 | 双bit错误 | 单bit错误 | 25-50% | 存储系统 |
| CRC校验 | 突发错误 | 无(检测后重传) | 1-8% | 网络通信 |
| Reed-Solomon | 多bit错误 | 多bit错误 | 50-100% | 光盘存储 |
时间冗余的实现策略:
| 时间冗余方式 | 实现原理 | 检错能力 | 性能影响 | 适用场景 |
|---|---|---|---|---|
| 重复执行 | 同一操作执行多次 | 瞬时错误 | 性能降低2-3倍 | 关键计算任务 |
| 交替执行 | 不同时间片执行 | 持续性错误 | 性能降低50% | 实时控制系统 |
| 滚动备份 | 定期保存系统状态 | 状态错误 | 存储开销增加 | 事务处理系统 |
| 检查点机制 | 关键点状态保存 | 逻辑错误 | 轻微性能影响 | 长时间运行任务 |
八、实际应用指导
1、可靠性设计的分阶段实施策略
可靠性建设的渐进式路径
可靠性建设是一个系统工程,需要根据业务发展阶段和技术能力,制定分阶段的实施计划:
不同发展阶段的可靠性重点:
| 发展阶段 | 业务特点 | 可靠性重点 | 技术投入 | 预期效果 | 实施周期 |
|---|---|---|---|---|---|
| 初创期 | 快速验证、资源有限 | 基础监控、异常处理 | 开发时间10% | 可用性达到99% | 2-4周 |
| 成长期 | 用户增长、稳定性要求提升 | 负载均衡、数据备份 | 开发时间20% | 可用性达到99.9% | 1-2个月 |
| 扩张期 | 大规模用户、业务关键 | 集群部署、容错设计 | 开发时间30% | 可用性达到99.99% | 3-6个月 |
| 成熟期 | 业务稳定、精细化运营 | 智能运维、预测性维护 | 开发时间40% | 可用性达到99.999% | 6-12个月 |
2、可靠性技术选择指南
基于业务场景的技术选择矩阵:
| 业务场景 | 可靠性要求 | 推荐技术方案 | 实施重点 | 成本预算 |
|---|---|---|---|---|
| 电商平台 | 高可用、数据一致性 | 微服务+数据库集群+缓存 | 交易链路保护、库存一致性 | 中高 |
| 金融系统 | 极高可靠性、监管合规 | N版本程序+双机热备 | 容错设计、审计追踪 | 高 |
| 内容平台 | 高并发、用户体验 | CDN+负载均衡+缓存 | 内容分发、访问加速 | 中等 |
| 企业应用 | 业务连续性、数据安全 | 集群部署+数据备份 | 业务流程保护、数据恢复 | 中等 |
3、常见可靠性问题及解决方案
典型可靠性故障的预防与处理:
| 故障类型 | 故障表现 | 根本原因 | 预防措施 | 应急处理 |
|---|---|---|---|---|
| 内存泄漏 | 系统越来越慢,最终崩溃 | 对象未正确释放 | 代码审查、内存监控 | 重启服务、内存分析 |
| 数据库死锁 | 事务处理超时 | 锁资源竞争 | 锁顺序规范、超时设置 | 事务回滚、锁检测 |
| 网络分区 | 部分节点无法通信 | 网络故障、配置错误 | 网络冗余、心跳检测 | 服务降级、手动切换 |
| 缓存雪崩 | 大量请求直接打到数据库 | 缓存同时失效 | 缓存预热、过期时间随机化 | 限流降级、缓存重建 |
4、可靠性测试与验证方法
可靠性验证的系统化方法:
| 测试类型 | 测试目标 | 测试方法 | 验收标准 | 工具推荐 |
|---|---|---|---|---|
| 故障注入测试 | 验证容错能力 | 模拟各种故障场景 | 故障恢复时间<目标值 | Chaos Monkey |
| 压力测试 | 验证系统极限 | 逐步增加负载 | 性能指标不降级 | JMeter、LoadRunner |
| 可用性测试 | 验证服务连续性 | 长期运行监控 | 可用性达到目标值 | Pingdom、监控系统 |
| 恢复测试 | 验证恢复能力 | 模拟灾难场景 | 恢复时间<RTO目标 | 灾备演练工具 |
5、可靠性运维最佳实践
可靠性运维的关键活动:
| 运维活动 | 执行频率 | 关键指标 | 自动化程度 | 业务价值 |
|---|---|---|---|---|
| 健康检查 | 实时 | 响应时间、错误率 | 完全自动化 | 故障早期发现 |
| 性能监控 | 实时 | CPU、内存、IO使用率 | 完全自动化 | 性能问题预警 |
| 日志分析 | 每日 | 错误日志数量、异常模式 | 半自动化 | 问题根因分析 |
| 容量规划 | 每月 | 资源使用趋势、增长预测 | 半自动化 | 资源优化配置 |
| 灾备演练 | 每季度 | 恢复时间、数据完整性 | 部分自动化 | 灾备能力验证 |
+ 最小栈解决方案)





)






》)




)
