前面python的学习中我们已经学习了python的函数和列表元组相关的内容,接下来我们来学习剩下的python语法:字典和文件
相关代码已经上传到作者的个人gitee:楼田莉子/Python 学习喜欢请点个赞谢谢
目录
字典
创建字典
查找key
新增/修改元素
删除元素
遍历字典
取出所有的key和value
合法的key类型
文件
什么是文件?
文件路径
绝对路径和相对路径
1. 绝对路径 (Absolute Path)
2. 相对路径 (Relative Path)
如何表示:语法总结
命令行应用
如何选择?
文件操作
打开文件
关闭文件
写文件
读文件
关于中文的处理
上下文管理器
字典
字典是一种存储 键值对 的结构.
啥是键值对? 这是计算机/生活中一个非常广泛使用的概念.
把 键(key) 和 值(value) 进行一个一对一的映射, 然后就可以根据键, 快速找到值.
python中字典的关系类似于C++中的键值对,类似于map、unordered_map
python中字典有很多键值对,且键不能重复
创建字典
创建一个空的字典. 使用 { } 表示字典
a = { }
b = dict()
print(type(a))
print(type(b))结果为:

也可以在创建的同时指定初始值
键值对之间使用 , 分割, 键和值之间使用 : 分割. (冒号后面推荐加一个空格).
使用 print 来打印字典内容
student={1:"张三",2:"李四",3:"王五"}
print(student)结果为:

最后一个键值对, 后面可以写 , 也可以不写.
查找key
使用 in 可以判定 key 是否在 字典 中存在. 返回布尔值
#用in判定是否存在
#这里的“\”表示换行,删掉就会报错
student = \{'id': 1,'name': 'zhangsan',}
print('id' in student)
print('score' in student)结果为:

使用 [ ] 通过类似于取下标的方式, 获取到元素的值. 只不过此处的 "下标" 是 key. (可能是整数, 也可能是字符串等其他类型).
#这里的“\”表示换行,删掉就会报错
student = \{'id': 1,'name': 'zhangsan',}
#用[]获取键值
print(student['id'])
print(student['name'])结果为:

如果 key 在字典中不存在, 则会抛出异常.
#这里的“\”表示换行,删掉就会报错
student = \{'id': 1,'name': 'zhangsan',}
#如果不存在则抛异常
print(student['score'])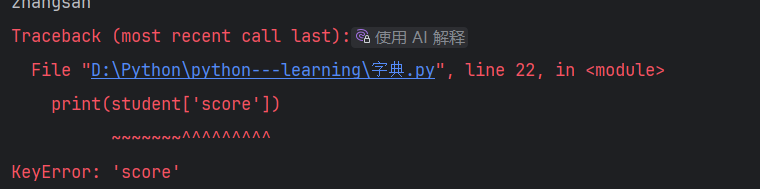
新增/修改元素
使用 [ ] 可以根据 key 来新增/修改 value.
如果 key 不存在, 对取下标操作赋值, 即为新增键值对
student = \{'id': 1,'name': 'zhangsan',}
student['score'] = 90
print(student)结果为:

如果 key 已经存在, 对取下标操作赋值, 即为修改键值对的值
student = {'id': 1,'name': 'zhangsan','score': 80
}
student['score'] = 90
print(student)

删除元素
使用 pop 方法根据 key 删除对应的键值对
#删除元素
#使用 pop 方法根据 key 删除对应的键值对
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
student.pop('score')
print(student)遍历字典
直接使用 for 循环能够获取到字典中的所有的 key, 进一步的就可以取出每个值了
#遍历字典元素
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
for key in student:print(key, student[key])结果为:

取出所有的key和value
使用 keys 方法可以获取到字典中的所有的 key
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
#取出所有key和value
print(student.keys()) 结果为: 
此处 dict_keys 是一个特殊的类型, 专门用来表示字典的所有 key. 大部分元组支持的操作对于
dict_keys 同样适用.
使用 values 方法可以获取到字典中的所有 value
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
#取出所有key和value
print(student.values())
此处 dict_values 也是一个特殊的类型, 和 dict_keys 类似.
使用 items 方法可以获取到字典中所有的键值对.
student = {
'id': 1,
'name': 'zhangsan',
'score': 80
}
print(student.items())

此处 dict_items 也是一个特殊的类型, 和 dict_keys 类似.
合法的key类型
类似于C++中的字典本质上是一个 哈希表, 哈希表的 key 要求是 "可哈希的", 也就是可以计算出一个哈希值.
不是所有的类型都可以作为字典的 key.
可以使用 hash 函数计算某个对象的哈希值.
但凡能够计算出哈希值的类型, 都可以作为字典的 key.
#计算是否为合法key
print(hash(0))
print(hash(3.14))
print(hash('hello'))
print(hash(True))
print(hash(())) # ( ) 是一个空的元组 以下结果表明均为合法的key类型
列表无法计算哈希值.
print(hash([1, 2, 3]))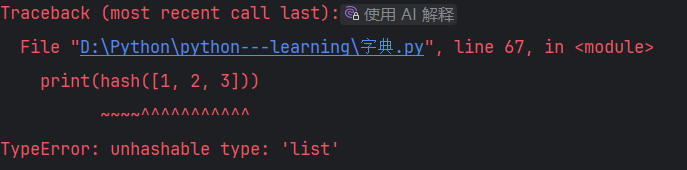
字典也无法计算哈希值
print(hash({ 'id': 1 }))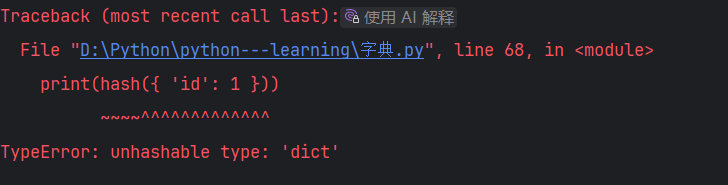
文件
什么是文件?
变量是把数据保存到内存中. 如果程序重启/主机重启, 内存中的数据就会丢失.要想能让数据被持久化存储, 就可以把数据存储到硬盘中. 也就是在 文件 中保存.
在 Windows "此电脑" 中, 看到的内容都是 文件.
通过文件的后缀名, 可以看到文件的类型. 常见的文件的类型如下:文本文件 (txt)
可执行文件 (exe, dll)图片文件 (jpg, gif)
视频文件 (mp4, mov) office 文件 (.ppt, docx)
......
而接下来我们将介绍最简单的文件格式
文件路径
一个机器上, 会存在很多文件, 为了让这些文件更方面的被组织, 往往会使用很多的 "文件夹"(也叫做目录)来整理文件.
实际一个文件往往是放在一系列的目录结构之中的.
为了方便确定一个文件所在的位置, 使用 文件路径 来进行描述.
如以下的路径
D:\program\qq\Bin\QQ.exe 来表示.D: 表示 盘符. 不区分大小写.
每一个 \ 表示一级目录. 当前 QQ.exe 就是放在 "D 盘下的 program 目录下的 qq 目录下的 Bin 目录中" .
目录之间的分隔符, 可以使用 \ 也可以使用 / . 一般在编写代码的时候使用 / 更方便.
绝对路径和相对路径
-
绝对路径:从“根目录”开始,描述文件位置的完整路径。它就像是一个文件在文件系统中的完整邮寄地址。
-
相对路径:从“当前所在目录”开始,描述文件位置的相对路径。它就像是在一个商场里,别人告诉你“我在你楼上的奶茶店”,这个指引依赖于你“当前的位置”。
1. 绝对路径 (Absolute Path)
-
是什么:从根目录(
C:\或/)开始,一层不落地写到目标文件。 -
怎么表示:
-
Windows:
C:\Users\ming\Desktop\my_essay.docx -
Mac/Linux:
/Users/ming/Desktop/my_essay.docx
-
-
特点:
-
唯一性:这个文件的绝对路径在全宇宙只有这一个。
-
绝对性:无论你当前在哪个目录,只要你使用这个绝对路径,系统就一定能精准定位到它。
-
开头:Windows通常以盘符(如
C:\)开头;Mac/Linux以正斜杠(/)开头。
-
比喻:就像告诉别人你的完整地址:“中国北京市海淀区XX路XX号XX大厦10楼1001室”。无论这个人现在在世界的哪个角落,凭借这个地址都能找到你。
2. 相对路径 (Relative Path)
-
是什么:从你当前所在的目录出发,如何找到目标文件。
-
怎么表示(基于当前目录是
Desktop):-
目标文件就在当前目录下,直接写文件名:
my_essay.docx -
想表示“当前目录”本身,可以用一个点:
./my_essay.docx(./代表“在这里”) -
想进入当前目录的子目录(这里
Desktop没有子目录,所以用Downloads举例):如果当前在ming目录,去Downloads就是Downloads/game.zip -
想返回上一级目录,用两个点:
../(../代表“上一层”)-
比如,你现在在
Desktop,想找到Downloads里的game.zip,你需要先退回上一层(ming目录),再进入Downloads。路径就是:../Downloads/game.zip
-
-
-
特点:
-
相对性:它的有效性严重依赖你当前的位置。如果你不在
Desktop目录,那么my_essay.docx这个相对路径就失效了。 -
简洁性:通常比绝对路径短得多,写起来更方便。
-
如何表示:语法总结
| 符号 | 含义 | 示例 (假设当前目录是 /Users/ming/Desktop) |
|---|---|---|
| 绝对路径 | 从根目录开始 | /Users/ming/Desktop/my_essay.docx |
[文件名] | 当前目录下的文件 | my_essay.docx |
./ | 当前目录本身(通常可省略) | ./my_essay.docx (等价于 my_essay.docx) |
../ | 上一级目录 | ../ 指向 /Users/ming/ |
../../ | 上两级目录 | ../../ 指向 /Users/ |
[文件夹名]/ | 当前目录下的某个子文件夹 | (如果存在) Projects/my_app.py |
命令行应用
# 当前在 Desktop 目录
# 用绝对路径打开文件(无论在哪都能执行)
$ open /Users/ming/Desktop/my_essay.docx # Mac
> start C:\Users\ming\Desktop\my_essay.docx # Windows# 用相对路径打开文件(必须在Desktop目录或其父目录执行才有效)
$ open ./my_essay.docx # Mac
$ open my_essay.docx # 省略 ./
> start my_essay.docx # Windowspython中应用
# 使用绝对路径(更可靠)
file = open("/Users/ming/Desktop/my_essay.docx", "r")# 使用相对路径(假设程序运行时,当前目录就是Desktop)
file = open("my_essay.docx", "r")# 使用相对路径,从上一级目录的Downloads文件夹读取
file = open("../Downloads/game.zip", "rb")如何选择?
-
用绝对路径:当你需要确保万无一失的精准定位时,比如在脚本、程序配置或日志中记录文件位置。
-
用相对路径:当你在项目内部移动或引用文件时,这样可以使整个项目更容易被移动或共享(因为路径不依赖于项目在电脑上的具体位置)。
文件操作
打开文件
使用内建函数 open 打开一个文件.
f=open('D:\Python\python---learning\hello world.txt','r')
第一个参数是一个字符串, 表示要打开的文件路径
第二个参数是一个字符串, 表示打开方式. 其中 r 表示按照读方式打开. w 表示按照写方式打开. a表示追加写方式打开.
如果打开文件成功, 返回一个文件对象. 后续的读写文件操作都是围绕这个文件对象展开.
如果打开文件失败(比如路径指定的文件不存在), 就会抛出异常
关闭文件
使用 close 方法关闭已经打开的文件
f.close()
使用完一定要关闭文件!
如果一直循环的打开文件, 而不去关闭的话, 就会出现下述报错.
![]()
当一个程序打开的文件个数超过上限, 就会抛出异常.
注意: 上述代码中, 使用一个列表来保存了所有的文件对象. 如果不进行保存, 那么 Python 内置的垃圾回收机制, 会在文件对象销毁的时候自动关闭文件.
但是由于垃圾回收操作不一定及时, 所以我们写代码仍然要考虑手动关闭, 尽量避免依赖自动关闭
写文件
文件打开之后, 就可以写文件了.
写文件, 要使用写方式打开, open 第二个参数设为 'w'
使用 write 方法写入文件.
f = open(r'D:/Python/python---learning/hello world.txt', 'w')
f.write('诗华')
f.close() 如果是使用 'r' 方式打开文件, 则写入时会抛出异常.
使用’w‘方式打开文件成功会清除原有数据
使用’a‘实现“追加写”,原有内容不变,直接在后面家内容
f = open(r'D:/Python/python---learning/hello world.txt', 'a')
f.write('诗华')
f.close()
f = open(r'D:/Python/python---learning/hello world.txt', 'w')
f.write('诗华')
f.close() 针对已经关闭的文件对象进行写操作, 也会抛出异常.
读文件
读文件需要使用’r‘的方式打开文件
使用read方法完成“读”操作,参数为几个字符
f = open('d:/test.txt', 'r')
result = f.read(2)
print(result)
f.close() 如果文件是多行文本, 可以使用 for 循环一次读取一行.
f = open('d:/test.txt', 'r')
for line in f:print(f'line = {line}')
f.close()注意:print()函数默认带换行符
使用 print(f'line = {line}', end='') 手动把 print 自带的换行符去掉.
使用 readlines 直接把文件整个内容读取出来, 返回一个列表. 每个元素即为一行.
f = open('d:/test.txt', 'r')
lines = f.readlines()
print(lines)
f.close()此处的 \n 即为换行符.
关于中文的处理
当文件内容存在中文的时候, 读取文件内容不一定就顺利.同样上述代码, 有的同学执行时可能会出现异常,有的则会出现乱码、
计算机表示中文的时候, 会采取一定的编码方式, 我们称为 "字符集"
所谓 "编码方式" , 本质上就是使用数字表示汉字.
我们知道, 计算机只能表示二进制数据. 要想表示英文字母, 或者汉字, 或者其他文字符号, 就都要通过编码.
最简单的字符编码就是 ascii. 使用一个简单的整数就可以表示英文字母和阿拉伯数字.
但是要想表示汉字, 就需要一个更大的码表.
一般常用的汉字编码方式, 主要是 GBK 和 UTF-8
必须要保证文件本身的编码方式, 和 Python 代码中读取文件使用的编码方式匹配, 才能避免出现上述问题.
Python3 中默认打开文件的字符集跟随系统, 而 Windows 简体中文版的字符集采用了 GBK, 所以如果文件本身是 GBK 的编码, 直接就能正确处理.
如果文件本身是其他编码(比如 UTF-8), 那么直接打开就可能出现上述问题
用记事本打开文本文件, 在 "菜单栏" -> "文件" -> "另存为" 窗口中, 可以看到当前文件的编码方式

如果此时为ASNI,表示GBK编码
如果此时为UTF-8,表示UTF-8编码
此时可以给open方法加上encoding,显示指定与文本相同的字符集,即可解决
更具体的可以参考这个文档:(47 封私信 / 58 条消息) 程序员必备:彻底弄懂常见的7种中文字符编码 - 知乎![]() https://zhuanlan.zhihu.com/p/46216008
https://zhuanlan.zhihu.com/p/46216008
上下文管理器
打开文件之后, 是容易忘记关闭的. Python 提供了 上下文管理器 , 来帮助程序猿自动关闭文件.使用 with 语句打开文件.
当 with 内部的代码块执行完毕后, 就会自动调用关闭方法.
with open('d:/test.txt', 'r', encoding='utf8') as f:lines = f.readlines()print(lines)
本期内容到这里就结束了,到此python的基础语法就结束了。
喜欢请点个赞,谢谢
封面图自取:











:代价函数的意义)






变换记录)
三极管)
