目录
- 项目介绍
- 🎯 功能展示
- 🌟 一、环境安装
- 🎆 环境配置说明
- 📘 安装指南说明
- 🎥 环境安装教学视频
- 🌟 二、数据集介绍
- 🌟 三、系统环境(框架/依赖库)说明
- 🧱 系统环境与依赖配置说明
- 📈 模型训练参数说明
- 🎯 基本训练参数
- 🔁 实时数据增强策略
- 🌟 四、YOLO相关介绍
- 🎀 yolov5相关介绍
- 🎑 yolov8相关介绍
- 🎐 yolo11相关介绍
- 🌟 五、模型训练步骤
- 🌟 六、模型评估步骤
- 🌟 七、训练结果
- 🌟 获取方式说明
项目介绍
本项目基于 PyQt5 构建了简洁易用的图形用户界面,支持用户选择本地图片或视频进行目标检测。系统界面美观,交互流畅,具备良好的用户体验。
项目附带完整的 Python 源码和详细的使用说明,适合学生进行学习或有一定 Python 基础的开发者,参考与二次开发。您可以在文末获取完整的代码资源文件。
✨ 项目亮点
-
🔧 完整系统级项目: 包括pyqt5界面、后台检测逻辑、模型加载等模块
-
🧠 支持深度学习模型扩展: 源代码,支持个人添加改进、模型修改等
-
🚀 可用于毕(she)/课(she)/个人项目展示: 结构清晰,逻辑完整,便于演示

🎯 功能展示
本系统具备多个核心功能,支持图像、视频、摄像头等多种输入源的目标检测需求:
-
🎴功能1:支持单张图片识别
加载本地图片进行目标识别,支持多种图片格式(如.jpg、.png等)。 -
📁功能2:支持遍历文件夹识别
可批量读取指定文件夹中的所有图像,并依次完成目标检测任务。 -
🎫功能3:支持识别视频文件
支持导入本地视频文件,逐帧分析,实时显示检测效果。 -
📷功能4:支持摄像头识别
直接调用笔记本/外接USB摄像头进行实时目标检测。(此功能识别不准,仅仅是为了有这个功能。) -
📤功能5:支持结果文件导出(.xls 格式)
自动保存检测结果为表格文件,包含类别、位置、置信度等信息,方便后续统计与分析。 -
🔄功能6:支持切换检测目标进行查看
可自定义选择或切换需要检测的目标种类,仅显示感兴趣的目标。
🎥 更多功能细节、代码演示效果获取请参考下方视频演示。此视频是必看的,里面的信息比文章要丰富,很多内容无法通过博客文字表达出来。
62-基于深度学习的海洋垃圾检测识别系统-yolo11-彩色版界面
62-基于深度学习的海洋垃圾检测识别系统-yolov8/yolov5-经典版界面
🌟 一、环境安装
🎆 环境配置说明
本项目已准备好 完整的环境安装资源包,包含:
- Python、PyCharm
- CUDA、PyTorch
- 其他依赖库(版本已适配)
所有依赖版本均已过验证,确保彼此兼容,可直接参考配套文档或视频教程一步步安装,无需手动调试。
📘 安装指南说明
本项目附带的环境配置文档及配套视频,文档是我在辅导上千名同学安装环境过程中,持续整理总结而成的经验合集,内容覆盖:
- GPU 与 CPU 两种版本的详细安装流程
- 安装过程中常见问题汇总
- 每个问题对应的解决方案
- 实测可行的安装顺序建议与注意事项
🧩 无论你是新手还是有经验的开发者,相信这份文档都能为你省下大量踩坑时间!
🎥 环境安装教学视频
环境安装-03GPU版
🌟 二、数据集介绍
使用数据集一部分个人标注,一部分来源网络,已统一标注格式并完成预处理,可直接用于训练与测试。
数据集样式如下:
| 训练样例1 | 训练样例2 |
|---|---|
 |  |
数据集制作流程
标注数据: 使用标注工具(LabelImg)对图像中的目标进行标注。每个目标需要标出边界框,并且标注类别。
转换格式: 将标注的数据转换为YOLO格式。YOLO标注格式为每行: <x_center> <y_center> ,这些坐标是相对于图像尺寸的比例。
分割数据集: 将数据集分为训练集、验证集和测试集,通常的比例是80%训练集、10%验证集和10%测试集。
准备标签文件: 为每张图片生成一个对应的标签文件,确保标签文件与图片的命名一致。
调整图像尺寸: 根据YOLO网络要求,统一调整所有图像的尺寸(如416x416或608x608)。
这里只是简单大概介绍,我实际的文档里,内容更要比这里丰富很多,保姆级的教程。这里放太多链接,大家容易看不到😂😂😂。
🌟 三、系统环境(框架/依赖库)说明
以下内容是简单的介绍,方便大家写文章,可直接套用。
🧱 系统环境与依赖配置说明
本项目采用 Python 3.8.10 作为开发语言,整个后台逻辑均由 Python 编写,主要依赖环境如下:
🎡 图形界面框架:
- PyQt5 5.15.9:用于搭建系统图形用户界面,实现窗口交互与组件布局。
🧠 深度学习框架:
- torch 1.9.0+cu111:PyTorch 深度学习框架,支持 CUDA 11.1 加速,用于模型构建与推理。
- torchvision 0.10.0+cu111:用于图像处理、数据增强及模型组件辅助。
⚡ CUDA 与 cuDNN(GPU 加速支持):
- CUDA 11.1.1(版本号:
cuda_11.1.1_456.81):用于 GPU 加速深度学习运算。 - cuDNN 8.0.5.39(适用于 CUDA 11.1):NVIDIA 深度神经网络库,用于加速模型训练与推理过程。
🧪 图像处理与科学计算:
- opencv-python 4.7.0.72:实现图像读取、显示、处理等功能。
- numpy 1.24.4:用于高效数组计算及矩阵操作。
- PIL (pillow) 9.5.0:图像文件读写与基本图像处理库。
- matplotlib 3.7.1(可选):用于结果图形化展示与可视化调试。
📈 模型训练参数说明
本项目中提供了两个训练好的模型,均基于如下参数完成训练。具体训练时的设置需根据您自己的硬件配置灵活调整:
🎯 基本训练参数
- batch size:16
- epoch:200
- imgsz(输入尺寸):640
- 优化器:SGD
- 学习率:初始学习率
0.01,最终学习率0.0001 - 学习率衰减策略:余弦退火(Cosine Annealing)
- 激活函数:SiLU
- 损失函数:CIOU(Complete IOU)
🔁 实时数据增强策略
训练过程中使用了多种 在线增强 方法,包括:
- HSV 色域变换
- 上下翻转、左右翻转
- 图像旋转
- Mosaic 图像拼接增强
⚠️ 特别说明:
以上所有增强操作均为 实时数据增强,只在训练过程中动态生成,用作模型输入,不会将增强后的图像保存到本地。
这种策略具有以下优势:
- 节省磁盘空间
- 提高训练样本的多样性
- 增强模型的泛化能力
若需要可视化增强效果,可自行编写脚本或借助工具(如 Photoshop、美图秀秀等)生成示例图像进行展示。
🌟 四、YOLO相关介绍
🎀 yolov5相关介绍
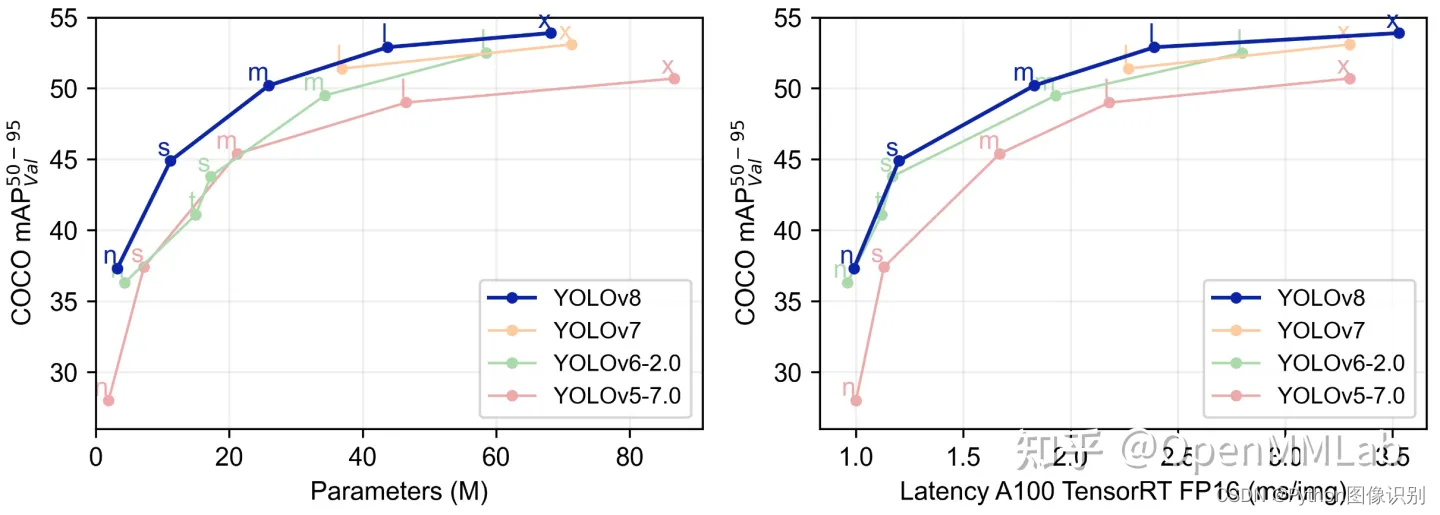
YOLOV5有YOLOv5n,YOLOv5s,YOLOv5m,YOLOV5l、YOLO5x五个版本。这个模型的结构基本一样,不同的是deth_multiole模型深度和width_multiole模型宽度这两个参数。就和我们买衣服的尺码大小排序一样,YOLOV5n网络是YOLOV5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。不过最常用的一般都是yolov5s模型。

本系统采用了基于深度学习的目标检测算法YOLOv5,该算法是YOLO系列算法的较新版本,相比于YOLOv3和YOLOv4,YOLOv5在检测精度和速度上都有很大的提升。YOLOv5算法的核心思想是将目标检测问题转化为一个回归问题。此外,YOLOv5还引入了一种称为SPP(Spatial Pyramid Pooling)的特征提取方法,这种方法可以在不增加计算量的情况下,有效地提取多尺度特征,提高检测性能。
在YOLOv5中,首先将输入图像通过骨干网络进行特征提取,得到一系列特征图。然后,通过对这些特征图进行处理,将其转化为一组检测框和相应的类别概率分数,即每个检测框所属的物体类别以及该物体的置信度。YOLOv5中的特征提取网络使用CSPNet(Cross Stage Partial Network)结构,它将输入特征图分为两部分,一部分通过一系列卷积层进行处理,另一部分直接进行下采样,最后将这两部分特征图进行融合。这种设计使得网络具有更强的非线性表达能力,可以更好地处理目标检测任务中的复杂背景和多样化物体。

在YOLOv5中,每个检测框由其左上角坐标(x,y)、宽度(w)、高度(h)和置信度(confidence)组成。同时,每个检测框还会预测C个类别的概率得分,即分类得分(ci),每个类别的得分之和等于1。因此,每个检测框最终被表示为一个(C+5)维的向量。在训练阶段,YOLOv5使用交叉熵损失函数来优化模型。损失函数由定位损失、置信度损失和分类损失三部分组成,其中定位损失和置信度损失采用了Focal Loss和IoU Loss等优化方法,能够有效地缓解正负样本不平衡和目标尺寸变化等问题。
YOLOv5网络结构是由Input、Backbone、Neck、Prediction组成。Yolov5的Input部分是网络的输入端,采用Mosaic数据增强方式,对输入数据随机裁剪,然后进行拼接。Backbone是Yolov5提取特征的网络部分,特征提取能力直接影响整个网络性能。YOLOv5的Backbone相比于之前Yolov4提出了新的Focus结构。Focus结构是将图片进行切片操作,将W(宽)、H(高)信息转移到了通道空间中,使得在没有丢失任何信息的情况下,进行了2倍下采样操作。
🎑 yolov8相关介绍
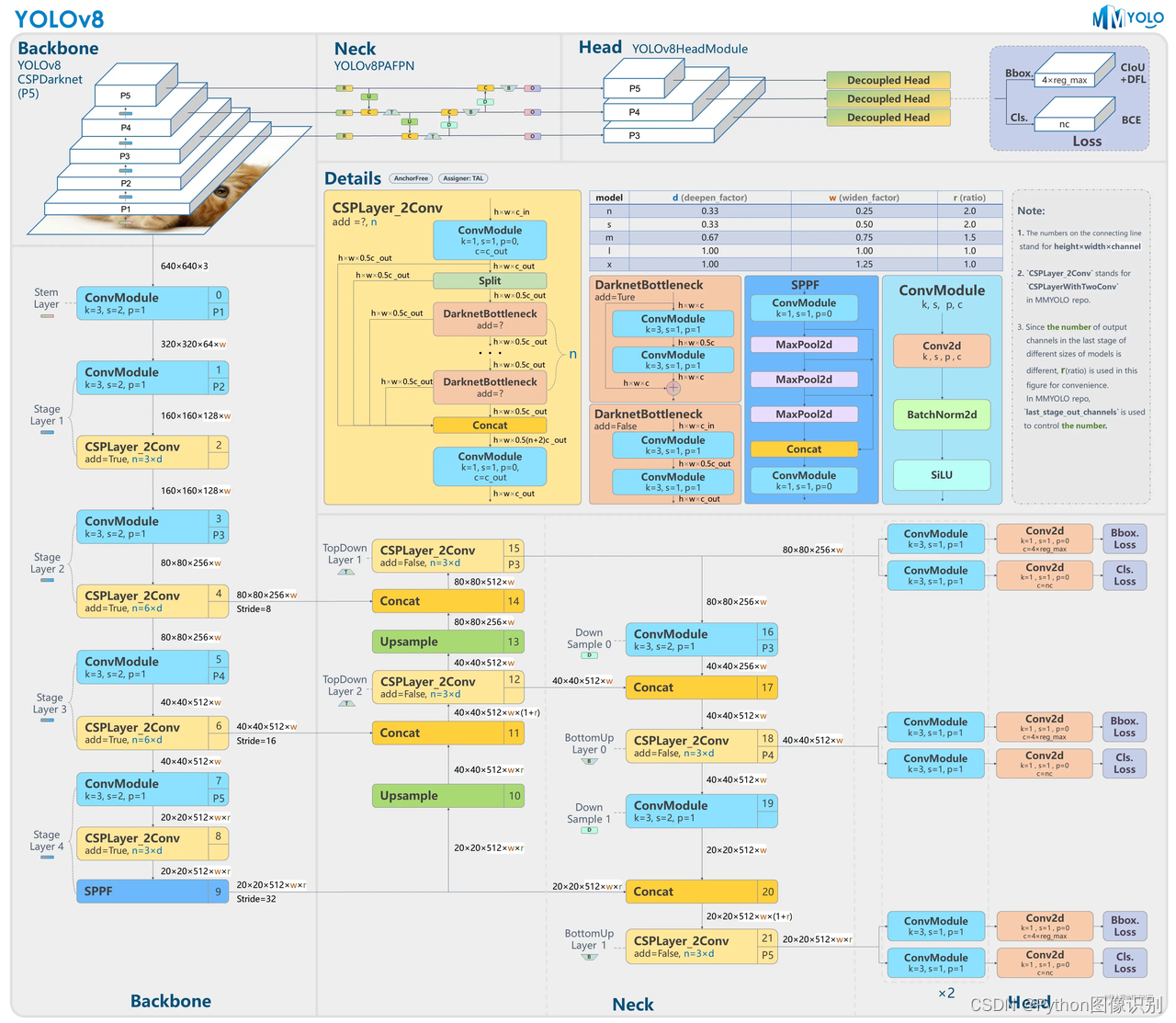
YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
不过 ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
总而言之,ultralytics 开源库的两个主要优点是:
-
融合众多当前 SOTA 技术于一体
-
未来将支持其他 YOLO 系列以及 YOLO 之外的更多算法
网络结构如下:
🎐 yolo11相关介绍
YOLO11 是Ultralytics YOLO 系列实时物体检测器的最新版本,以尖端的精度、速度和效率重新定义了可能性。基于先前 YOLO 版本的令人印象深刻的进步,YOLO11 在架构和训练方法方面引入了重大改进,使其成为各种计算机视觉任务的多功能选择。
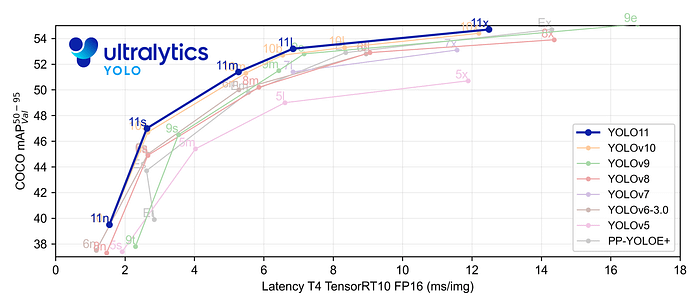
Key Features 主要特点:
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测和复杂任务性能。
- 针对效率和速度进行优化:YOLO11 引入了精致的架构设计和优化的训练管道,提供更快的处理速度并保持准确性和性能之间的最佳平衡。
- 使用更少的参数获得更高的精度:随着模型设计的进步,YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),同时使用的参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以无缝部署在各种环境中,包括边缘设备、云平台以及支持NVIDIA GPU的系统,确保最大的灵活性。
- 支持的任务范围广泛:无论是对象检测、实例分割、图像分类、姿态估计还是定向对象检测 (OBB),YOLO11 旨在应对各种计算机视觉挑战。

🌟 五、模型训练步骤
以下操作步骤,每年我都会更新,所以下方操作步骤可跳过,可以去我文档里查看最新的操作步骤。
-
使用pycharm打开代码,找到
train.py打开,示例截图如下:

-
修改
model_yaml的值,根据自己的实际情况修改,想要训练yolov5s模型 就 修改为model_yaml = yaml_yolov5s, 训练 添加SE注意力机制的模型就修改为model_yaml = yaml_yolov5_SE -
修改
data_path数据集路径,我这里默认指定的是traindata.yaml文件,如果训练我提供的数据,可以不用改 -
修改
model.train()中的参数,按照自己的需求和电脑硬件的情况更改# 文档中对参数有详细的说明 model.train(data=data_path, # 数据集imgsz=640, # 训练图片大小epochs=200, # 训练的轮次batch=2, # 训练batchworkers=0, # 加载数据线程数device='0', # 使用显卡optimizer='SGD', # 优化器project='runs/train', # 模型保存路径name=name, # 模型保存命名) -
修改
traindata.yaml文件, 打开traindata.yaml文件,如下所示:

在这里,只需修改 path 的值,其他的都不用改动(仔细看上面的黄色字体),我提供的数据集默认都是到yolo文件夹,设置到 yolo 这一级即可,修改完后,返回train.py中,执行train.py。 -
打开
train.py,右键执行。

-
出现如下类似的界面代表开始训练了

-
训练完后的模型保存在runs/train文件夹下

🌟 六、模型评估步骤
以下操作步骤,每年我都会更新,,所以下方操作步骤可跳过,可以去我文档里查看最新的操作步骤。
-
打开
val.py文件,如下图所示:

-
修改
model_pt的值,是自己想要评估的模型路径 -
修改
data_path,根据自己的实际情况修改,具体如何修改,查看上方模型训练中的修改步骤 -
修改
model.val()中的参数,按照自己的需求和电脑硬件的情况更改model.val(data=data_path, # 数据集路径imgsz=300, # 图片大小,要和训练时一样batch=4, # batchworkers=0, # 加载数据线程数conf=0.001, # 设置检测的最小置信度阈值。置信度低于此阈值的检测将被丢弃。iou=0.6, # 设置非最大抑制 (NMS) 的交叉重叠 (IoU) 阈值。有助于减少重复检测。device='0', # 使用显卡project='runs/val', # 保存路径name='exp', # 保存命名) -
修改完后,即可执行程序,出现如下截图,代表成功(下图是示例,具体输出结果以自己的实际项目为准。)

-
评估后的文件全部保存在在
runs/val/exp...文件夹下

🌟 七、训练结果
模型训练完成后,所有相关文件(包括权重文件、训练日志、评估结果等)均统一保存在代码工程的weights文件夹下,便于后续模型部署与复用。文件夹内包含训练过程中生成的所有最优权重(best.pt)及最终权重(last.pt),整体结构清晰,可直接用于推理或二次训练。
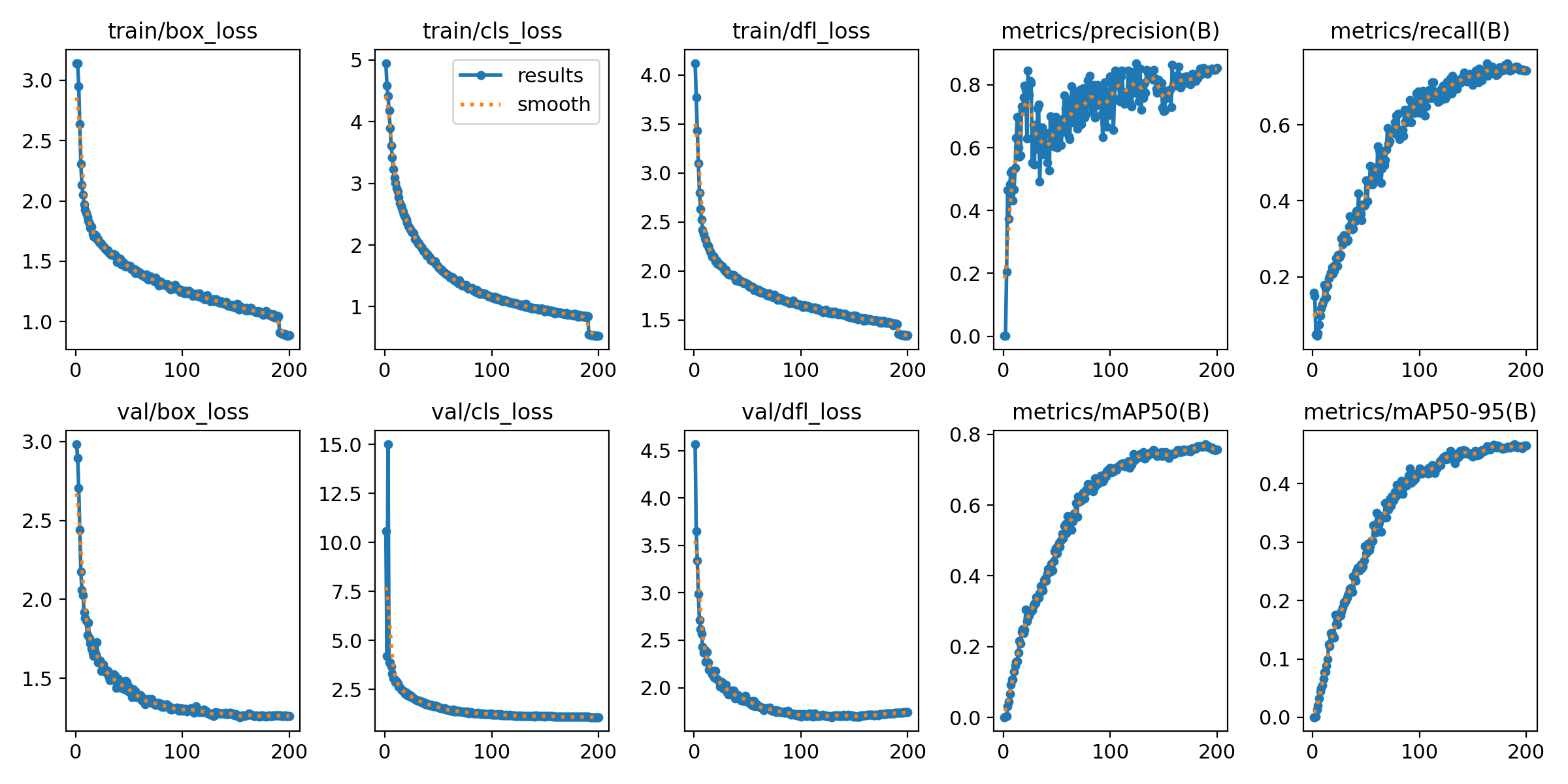
训练的曲线图:
训练过程中,模型的关键指标(如损失值、精度、召回率等)变化曲线已自动记录并可视化。从曲线中可以清晰观察到:
- 训练集与验证集的损失值(Loss)随迭代次数增加逐步下降并趋于稳定,表明模型有效学习到数据特征;
- 核心评估指标(如 mAP@0.5、准确率)在训练后期逐步收敛,验证集性能与训练集保持一致,无明显过拟合现象;
- 通过对比不同阶段的指标变化,可直观判断模型收敛速度与稳定性,为参数调优提供参考。
评估的结果示例图:
为更直观展示模型性能,选取val中具有代表性的样本进行可视化评估,涵盖不同场景、不同目标密度及复杂背景下的检测 / 分类效果:
| 评估示例图1 | 评估示例图2 |
|---|---|
 |  |
🌟 获取方式说明
这是一套完整的资源,经过往届学长学姐检验过,是OK的项目,我这里就不做过多的介绍了,说的太多了,大家容易看不到。如果想要获取源码进行学习,可观看一下前面 功能展示 章节的视频演示。如有疑问,也可通过下方的名片或者留言进行交流,一起学习、进步。
💡 温馨提示:资源仅用于学习交流,请勿用于商业用途,感谢理解与支持!
)




)
组合模式)





中,在 <script>、<template>、<style> 标签外输入内容不会导致程序报错)

)
)



