作者:IvanCodes
日期:2025年5月16日
专栏:Hive教程
在数据分析的江湖中,数据往往分散在不同的“门派”(表)之中。要洞察数据间的深层联系,就需要JOIN这把利器,将相关联的数据串联起来。Hive SQL 提供了多种 JOIN语法,如同六脉神剑,各有精妙之处。掌握它们,能让你在数据整合时游刃有余。
思维导图
准备工作:创建示例表
为了演示各种 JOIN,我们先创建两张简单的表:employees (员工表) 和 departments (部门表)。
-- 员工表
CREATE TABLE employees (
emp_id INT,
emp_name STRING,
dept_id INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;-- 部门表
CREATE TABLE departments (
dept_id INT,
dept_name STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;-- 插入数据
INSERT INTO employees VALUES
(1, '张三', 101),
(2, '李四', 102),
(3, '王五', 101),
(4, '赵六', 103),
(5, '孙七', NULL);INSERT INTO departments VALUES
(101, '技术部'),
(102, '市场部'),
(104, '行政部');
Hive JOIN 六大语法详解
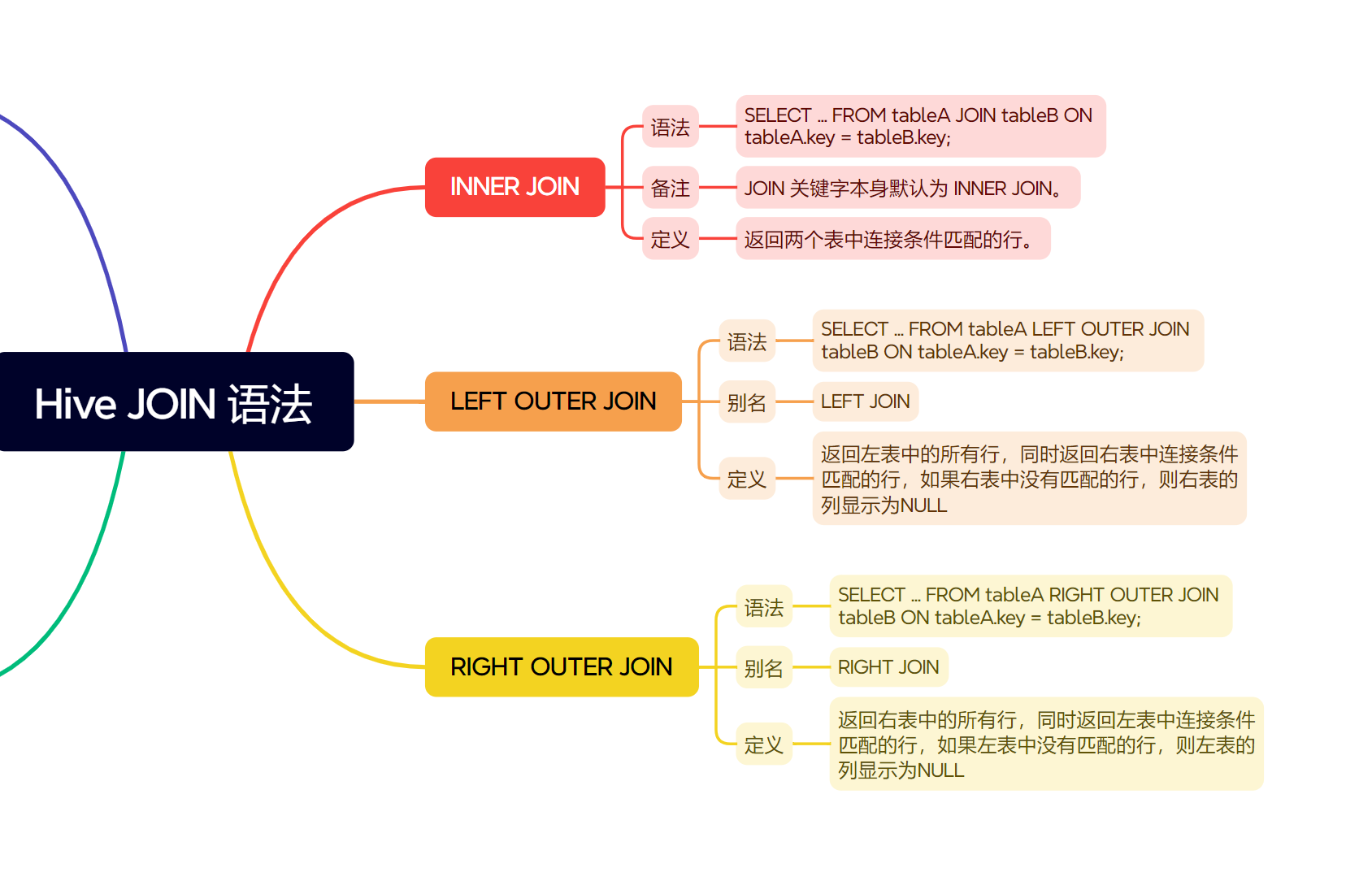
1. INNER JOIN (内连接,或简写为 JOIN)
- 核心思想:只返回两张表中连接条件匹配的行。如果某行在一张表中找不到在另一张表中与之匹配的行,则该行不会出现在结果中。
- 通用语法:
SELECT table1.col1, table1.col2, table2.col_other
FROM table1
INNER JOIN table2
ON table1.join_column = table2.join_column;
- 代码示例:查询所有有明确部门归属的员工及其部门名称。
SELECT e.emp_name, d.dept_name
FROM employees e
INNER JOIN departments d
ON e.dept_id = d.dept_id;
- 预期输出:
张三 技术部
李四 市场部
王五 技术部
2. LEFT OUTER JOIN (左外连接,或简写为 LEFT JOIN)
- 核心思想:返回左表中所有的行,以及右表中与左表连接条件匹配的行。如果右表中没有匹配的行,则右表的列值显示为
NULL。 - 通用语法:
SELECT table1.col1, table1.col2, table2.col_other
FROM table1
LEFT OUTER JOIN table2
ON table1.join_column = table2.join_column;
- 代码示例:查询所有员工,并显示他们的部门名称(如果存在)。
SELECT e.emp_name, e.dept_id AS emp_dept_id, d.dept_name
FROM employees e
LEFT JOIN departments d
ON e.dept_id = d.dept_id;
- 预期输出:
张三 101 技术部
李四 102 市场部
王五 101 技术部
赵六 103 NULL
孙七 NULL NULL
3. RIGHT OUTER JOIN (右外连接,或简写为 RIGHT JOIN)
- 核心思想:与 LEFT JOIN 相反。返回右表中所有的行,以及左表中与右表连接条件匹配的行。如果左表中没有匹配的行,则左表的列值显示为
NULL。 - 通用语法:
SELECT table1.col1, table2.col_other1, table2.col_other2
FROM table1
RIGHT OUTER JOIN table2
ON table1.join_column = table2.join_column;
- 代码示例:查询所有部门,并显示部门下的员工姓名(如果存在)。
SELECT e.emp_name, d.dept_name, d.dept_id AS dep_dept_id
FROM employees e
RIGHT JOIN departments d
ON e.dept_id = d.dept_id;
- 预期输出:
张三 技术部 101
李四 市场部 102
王五 技术部 101
NULL 行政部 104
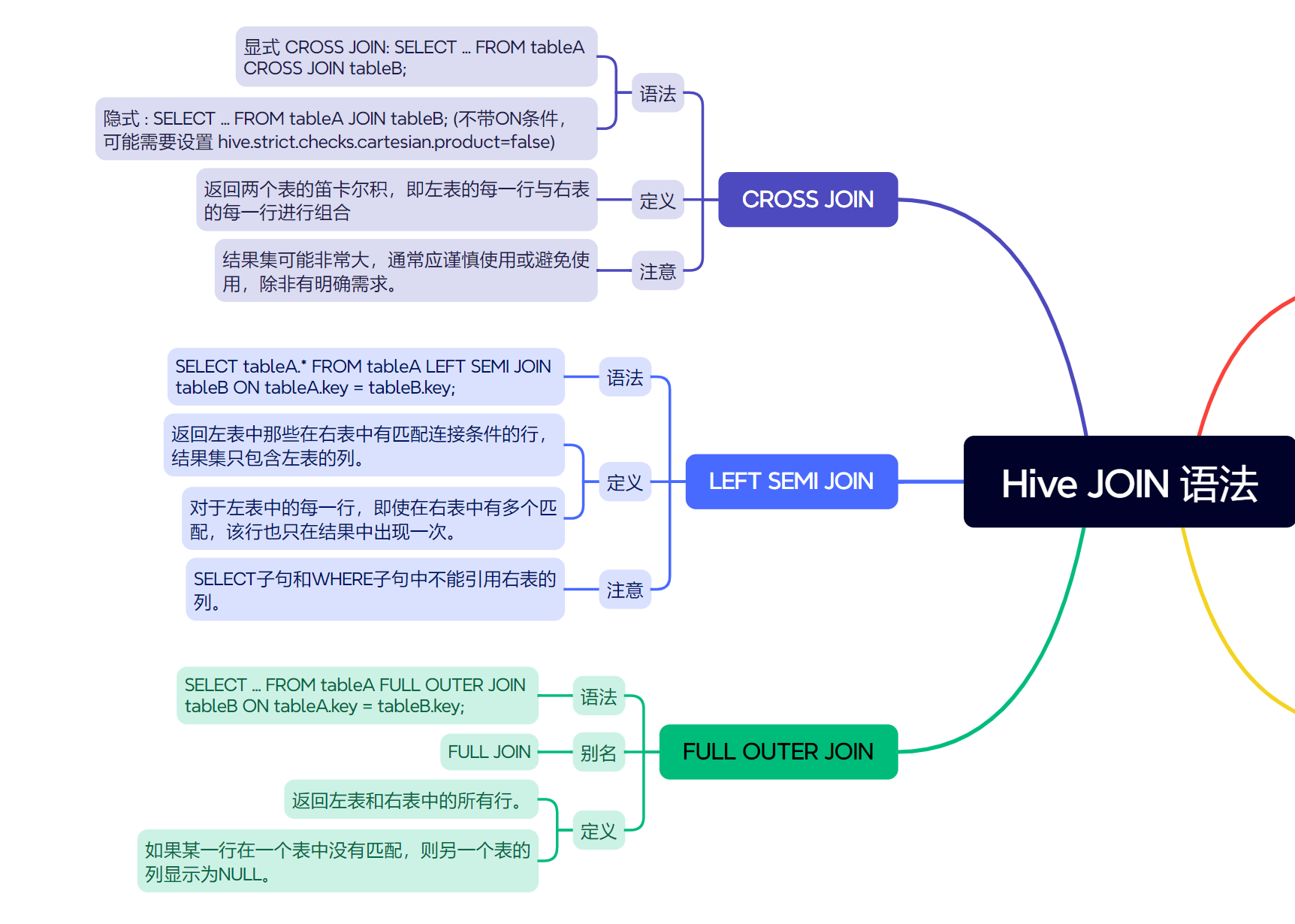
4. FULL OUTER JOIN (全外连接,或简写为 FULL JOIN)
- 核心思想:返回左表和右表中所有的行。当某行在另一张表中没有匹配时,该表对应的列值显示为
NULL。 - 通用语法:
SELECT table1.col1, table2.col_other
FROM table1
FULL OUTER JOIN table2
ON table1.join_column = table2.join_column;
- 代码示例:查询所有员工和所有部门的完整信息。
SELECT e.emp_name, e.dept_id AS emp_dept_id, d.dept_name, d.dept_id AS dep_dept_id
FROM employees e
FULL JOIN departments d
ON e.dept_id = d.dept_id;
- 预期输出:
张三 101 技术部 101
李四 102 市场部 102
王五 101 技术部 101
赵六 103 NULL NULL
孙七 NULL NULL NULL
NULL NULL 行政部 104
5. LEFT SEMI JOIN (左半连接)
- 核心思想:这是 Hive 特有的一种 JOIN。它只返回左表中那些在右表中存在匹配记录的行。关键在于,结果集中不包含右表的任何列。它更像是一个存在性检查 (类似于 SQL 中的
EXISTS子查询)。 - 通用语法:
SELECT table1.col1, table1.col2
FROM table1
LEFT SEMI JOIN table2
ON table1.join_column = table2.join_column;
- 代码示例:查询所有在部门表中确实存在对应部门的员工信息。
SELECT e.emp_id, e.emp_name, e.dept_id
FROM employees e
LEFT SEMI JOIN departments d
ON e.dept_id = d.dept_id;
- 预期输出:
1 张三 101
2 李四 102
3 王五 101
6. CROSS JOIN (交叉连接,笛卡尔积)
- 核心思想:返回左表中的每一行与右表中的每一行的所有可能组合。结果集的行数是左表行数乘以右表行数。通常不使用 ON 子句(或者使用
ON 1=1这种恒为真的条件)。 - 通用语法:
SELECT table1.col1, table2.col_other
FROM table1
CROSS JOIN table2;
- 代码示例:显示员工和部门的所有可能组合(通常在实际业务中要谨慎使用)。
SELECT e.emp_name, d.dept_name
FROM employees e
CROSS JOIN departments d;
- 预期输出: (员工表5行 * 部门表3行 = 15行,部分示例)
张三 技术部
张三 市场部
张三 行政部
李四 技术部
李四 市场部
李四 行政部
...
- 注意:CROSS JOIN 非常容易产生巨大的结果集,消耗大量资源,务必谨慎使用。
练习题
假设我们有如上创建的 employees 和 departments 表。
- 找出所有在“技术部”工作的员工姓名。
- 列出所有部门的名称,以及该部门的员工数量(如果某部门没有员工,数量显示为0)。
- 找出所有没有分配到任何有效部门的员工姓名(即员工表中的dept_id在部门表中不存在,或者员工的dept_id为NULL)。
- 列出所有员工的姓名,以及他们所在部门的名称。对于没有部门的员工孙七,部门名称应显示为 “未分配”;对于部门ID存在但部门表中无对应名称的赵六,部门名称应显示为 “未知部门”。
- 使用 LEFT SEMI JOIN,找出所有部门ID为101的员工信息。
- 解释 INNER JOIN 和 LEFT OUTER JOIN 在处理不匹配数据时的主要区别。
- 如果
employees表有100行,departments表有5行,那么CROSS JOIN会产生多少行结果? - 找出所有既有员工,其部门也在部门表中存在的员工姓名和部门名称。(提示:思考多种JOIN方式)
- 使用 FULL OUTER JOIN,然后筛选出只存在于员工表(在部门表无匹配)或只存在于部门表(在员工表无匹配)的记录。请描述如何筛选。
- 查询所有部门ID (dept_id),以及这些部门的名称。如果一个部门ID只存在于员工表中,也需要列出这个ID,但部门名称显示为NULL。
练习题答案
- 找出所有在“技术部”工作的员工姓名。
SELECT e.emp_name
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
WHERE d.dept_name = '技术部';
- 列出所有部门的名称,以及该部门的员工数量(如果某部门没有员工,数量显示为0)。
SELECT d.dept_name, COUNT(e.emp_id) AS employee_count
FROM departments d
LEFT JOIN employees e ON d.dept_id = e.dept_id
GROUP BY d.dept_id, d.dept_name;
- 找出所有没有分配到任何有效部门的员工姓名(即员工表中的dept_id在部门表中不存在,或者员工的dept_id为NULL)。
SELECT e.emp_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id
WHERE d.dept_id IS NULL;
- 列出所有员工的姓名,以及他们所在部门的名称。对于没有部门的员工孙七,部门名称应显示为 “未分配”;对于部门ID存在但部门表中无对应名称的赵六,部门名称应显示为 “未知部门”。
SELECT
e.emp_name,
CASE
WHEN e.dept_id IS NULL THEN '未分配'
WHEN d.dept_name IS NULL THEN '未知部门'
ELSE d.dept_name
END AS department_status
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id;
- 使用 LEFT SEMI JOIN,找出所有部门ID为101的员工信息。
SELECT e.emp_id, e.emp_name, e.dept_id
FROM employees e
LEFT SEMI JOIN departments d ON e.dept_id = d.dept_id AND e.dept_id = 101;
-
解释 INNER JOIN 和 LEFT OUTER JOIN 在处理不匹配数据时的主要区别。
INNER JOIN 只保留两边表中都能通过连接条件找到匹配的行。如果左表的一行在右表中没有匹配,或者右表的一行在左表中没有匹配,这些行都会被丢弃。
LEFT OUTER JOIN 会保留左表的所有行。如果左表的某行在右表中找到了匹配,则合并两边的列;如果在右表中找不到匹配,则右表对应的列将填充为NULL,但左表的行仍然会出现在结果中。 -
如果
employees表有100行,departments表有5行,那么CROSS JOIN会产生多少行结果?
100 * 5 = 500 行。 -
找出所有既有员工,其部门也在部门表中存在的员工姓名和部门名称。(提示:思考多种JOIN方式)
SELECT e.emp_name, d.dept_name
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id;
- 使用 FULL OUTER JOIN,然后筛选出只存在于员工表(在部门表无匹配)或只存在于部门表(在员工表无匹配)的记录。请描述如何筛选。
筛选条件是:当employees.emp_id IS NULL(表示这条记录只在departments表中有) 或者departments.dept_id IS NULL(表示这条记录只在employees表中有,且连接失败)。
SELECT e.emp_name, e.dept_id AS emp_dept_id, d.dept_name, d.dept_id AS dep_dept_id
FROM employees e
FULL OUTER JOIN departments d ON e.dept_id = d.dept_id
WHERE e.emp_id IS NULL OR d.dept_id IS NULL;
- 查询所有部门ID (dept_id),以及这些部门的名称。如果一个部门ID只存在于员工表中,也需要列出这个ID,但部门名称显示为NULL。
SELECT DISTINCT e.dept_id AS emp_dept_id_distinct, d.dept_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id;




利用C11模拟伪闭包实现连接的安全回收)
:Agent系统的应用架构与落地实)




:如何使用?)








