SQL概述与数据库定义
SQL的基本组成
1、数据定义语言。SQL DDL提供定义关系模式和视图、删除关系和视图、修改关系模式的命令。
2、交互式数据操纵语言。SQL DML提供查询、插入、删除和修改的命令。
3、事务控制。SQL提供定义事务开始和结束的命令。
4、嵌入式SQL和动态SQL。用于嵌入到某种通用的高级语言中混合编程。其中,SQL负责操纵数据库,
高级语言负责控制程序流程。
5、完整性。SQL DDL包括定义数据库中的数据必须满足的完整性约束条件的命令,对于破坏完整性
约束条件的更新将被禁止。
6、权限管理。SQL DDL中包括说明对关系和视图的访问权限。
7、SQL语言中完成核心功能的9个动词:
(1)数据查询:Select
(2)数据定义:Create、Drop、Alter
(3)数据操纵:Insert、Update、Delete
(4)数据控制:Grant、Revoke
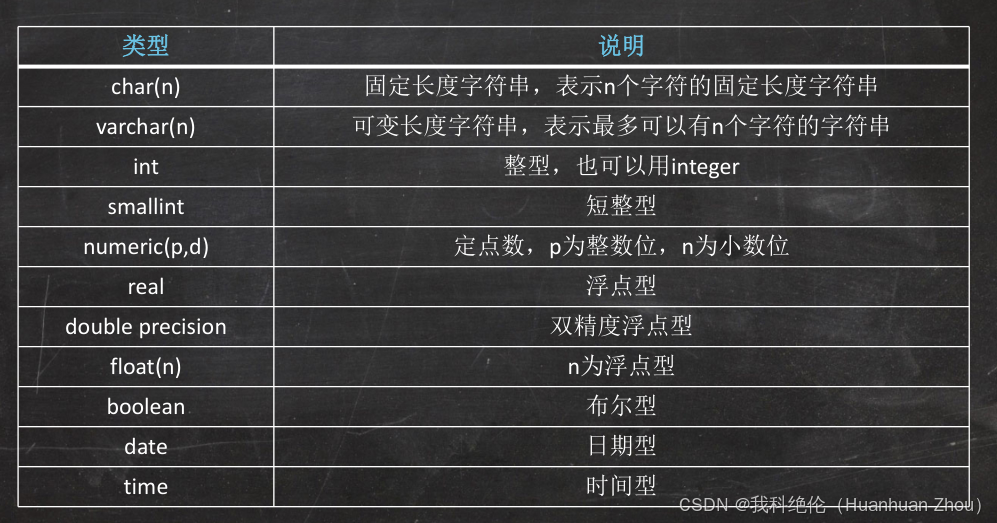
SQL的数据类型
表的创建、修改和删除
1、创建表
语句格式:CREATE TABLE <表名> (<列名><数据类型>[列级完整性约束条件]
[,<列名><数据类型>[列级完整性约束条件]]…
[,<表级完整性约束条件>]);
注:[ ]表示可选,< >表示必填。
1)、实体完整性约束:
(1)在列后面加 PRIMARY KEY
(2)在最后加PRIMARY KEY(属性名1,属性名2)
//主码为属性组(两个或以上属性的组合)只能
用这种方法
2)、参照完整性约束:
(1)在列后面加 References 表名(属性名)
(2)在最后面加,有几个外码,就写几行。
Foreign Key (属性名) References 表名(属性名)
[ON DELETE [CASCADE|SET NULL]
ON DELETE CASCADE 表示删除被参照关系的元组时,同时删除参照关系中的元组;
ON DELETE SET NULL表示删除被参照关系的元组时,将参照关系的相应属性值置为空值。
3)、属性值上的约束
(1)NOT NULL:表示不允许取空值;
(2)UNIQUE:表示取值唯一;
(3)NOT NULL UNIQUE:表示取值唯一且不为空;
(4)CHECK:限制列中值的取值范围。
如:CHECK (Sex=‘男’ OR Sex=‘女’),CHECK (余额>=0),CHECK (年龄>=18 AND 年龄<=60)
4)、全局约束
1)基于元组的检查子句:
这种约束是对单个关系的元组值加以约束。
例:入职日期小于等于离职日期,可以用 CHECK (入职日期<=离职日期)
CREATE TABLE E
(Eno CHAR(8) PRIMARY KEY,
入职日期 DATE,
离职日期 DATE,
CHECK (入职日期<=离职日期) );
2)基于断言的语法格式:
CREATE ASSERTION <断言名> CHECK (<条件>)
例:教学数据库的模式Students、SC、C中创建一个约束ASSE_SC1:不允许男同学选修“张勇”老师的课。
CREATE ASSERTION ASSE_SC1 CHECK
(NOT EXISTS
(SELECT * FROM SC WHERE Cno IN
(SELECT Cno FROM C WHERE TEACHER=‘张勇’)
AND Sno IN
(SELECT Sno FROM Students WHERE SEX=‘M’)));
2、修改表
语句格式:ALTER TABLE <表名> [ADD <新列名><数据类型>[列级完整性约束条件]]
[DROP <完整性约束名>]
[Modify <列名><数据类型>]);
如:
ALTER TABLE S ADD Zap CHAR(6);
//在表S中新增一列ZAP,该列的数据为空
ALTER TABLE S MODIFY Status INT;
//将表S的Status属性的数据类型更改为INT
ALTER TABLE S ADD Constraint C_cno CHECK(…) //在表S中新增CHECK约束,取名为C_cno
3、删除表
语句格式:DROP TABLE <表名>
如:
DROP TABLE S;
//表删除后,不再是数据库模式的一部分
索引的创建和删除
1、索引的概念
• 数据库中的索引与书籍中的索引类似,在一本书中,利用索引可以快速查找到所需信息,无须阅
读整本书。在数据库中,索引使数据库无须对整个表进行扫描,就可以在其中找到所需数据。
• 比如在字典中,我们按字母建立索引。在数据库中,索引是某个表中的一列或者若干列的值的集
合,和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
2、索引的作用
(1)通过创建唯一索引,可以保证数据记录的唯一性。
(2)可以大大加快数据检索速度。
(3)可以加速表与表之间的连接,这一点在实现数据的参照完整性方面有特别的意义。
(4)在使用ORDER BY和GROUP BY子句中进行检索数据时,可以显著减少查询中分组和排序的时间。
(5)使用索引可以在检索数据的过程中使用优化隐藏器,提高系统性能。
索引分为聚集索引和非聚集索引。聚集索引是指索引表中索引项的顺序与表中记录的物理顺序
一致的索引。
3、建立索引:
语句格式:CREATE [UNIQUE][CLUSTER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>]]…);
• 次序:ASC(升序)或DESC(降序),默认为升序。
• UNIQUE:表明此索引的每一个索引值只对应唯一的数据记录。
• CLUSTER:表明要建立的索引是聚簇索引,意为索引项的顺序是与表中记录的物理顺序一致的索引组织
如:
CREATE UNIQUE INDEX S_Sno on S(Sno);
//在表S的Sno列上建立索引S_Sno,默认为升序
CREATE UNIQUE INDEX P_Pno on P(Pno);
//在表P的Pno列上建立索引P_Pno,默认为升序
CREATE UNIQUE INDEX J_Jno on J(Jno);
//在表J的Jno列上建立索引J_Jno,默认为升序
CREATE UNIQUE INDEX SPJ_NO on SPJ(Sno ASC,Pno DESC,Jno ASC);
//在表SPJ上建立索引SPJ_NO,属性Sno按升序,Pno按降序,Jno按升序
4、删除索引
语句格式:DROP INDEX <索引名>
例:DROP INDEX StudentIndex;
//删除索引StudentIndex
视图的创建和删除
1、视图的作用:
视图是从一个或者多个基本表或视图中导出的表,其结构和数据是建立在对表的查询基础上的。和真实的表一样,视图也包括几个被定义的数据列和多个数据行,但从本质上讲,这些数据列和数据行来源于其所引用的表。因此,视图不是真实存在的基本表,而是一个虚拟表,视图所对应的数据并不实际地以视图结构存储在数据库中,而是存储在视图所引用的表中。使用视图的优点和作用如下:
(1)可以使视图集中数据、简化和定制不同用户对数据库的不同数据要求。(2)使用视图可以屏蔽数据的复杂性,用户不必了解数据库的结构,就可以方便地使用和管理数据,简化数据权限管理和重新组织数据以便输出到其他应用程序中。
(3)视图可以使用户只关心他感兴趣的某些特定数据和所负责的特定任务,而那些不需要的或者无用的数据则不在视图中显示。
(4)视图大大地简化了用户对数据的操作。
(5)视图可以让不同的用户以不同的方式看到不同或者相同的数据集。
(6)在某些情况下,由于表中数据量太大,因此在表的设计时常将表进行水平或者垂直分割,但表的结构的变化对应用程序产生不良的影响。
(7)视图提供了一个简单而有效的安全机制。
2、创建视图
语句格式:CREATE VIEW 视图名(列表名)
AS SELECT 查询子句
[WITH CHECK OPTION];
• 视图的创建中,必须遵循如下规定:
(1)子查询可以是任意复杂的SELECT语句,但通常不允许含有ORDER BY子句和DISTINCT短语。
(2)WITH CHECK OPTION表示对UPDATE,INSERT,DELETE操作时保证更新、插入或删除的行满足视图
定义中的谓词条件(即子查询中的条件表达式)
(3)组成视图的属性列名或者全部省略或者全部指定。如果省略属性列名,则隐含该视图由SELECT
子查询目标列的主属性组成。
例:学生关系模式S(Sno,Sname,Sage,Sex,SD,Email,Tel),建立计算机系(CS表示计算机系)学生的
视图,并要求进行修改、插入操作时保证该视图只有计算机系的学生。
CREATE VIEW CS_STUDENT
//创建视图CS_STUDENT
AS SELECT Sno,Sname,Sage,Sex
//选择学号、姓名、年龄、性别列
FROM Student
//从学生表中查询
Where SD=‘CS’
//选择系名等于“CS”的行
WITH CHECK OPTION;
//以后对该视图进行修改、插入操作时DBMS
会自动加上SD='CS’的条件,
保证视图中只有计算机系的学生
3、删除视图
语句格式:DROP VIEW 视图名
如:DROP VIEW CS_STUDENT //删除视图CS_STUDENT
数据操作
SQL的数据操作功能包括SELECT(查询)、INSERT(插入)、DELETE(删除)和UPDATE(修改)4条语句。
Select 基本结构

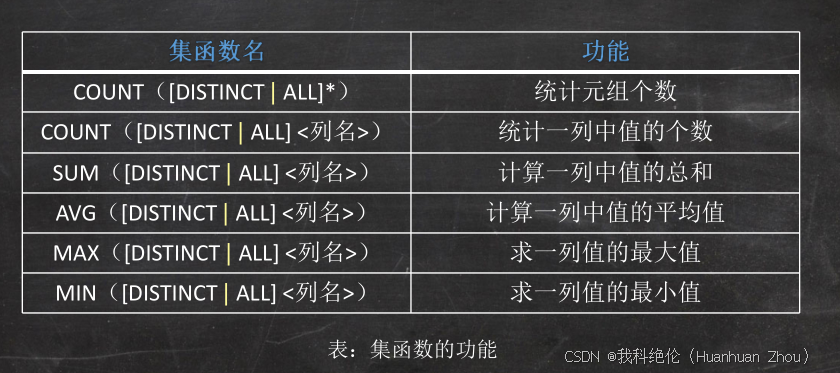
聚集函数
• 聚集函数是一个值的集合为输入,返回单个值的函数。SQL提供了5个预定义集函数:
平均值AVG()、最小值MIN()、最大值MAX()、求和SUM()、计数COUNT()
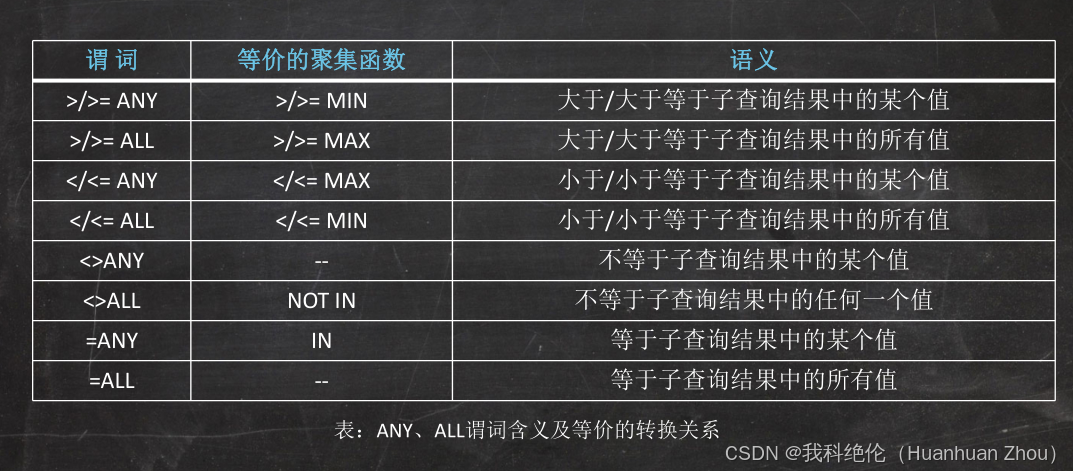
授权与触发器
授权(GRANT)
语句格式: GRANT 权限 ON TABLE/DATABASE 表名/数据库名 TO 用户1,用户2… /PUBLIC
[WITH GRANT OPTION];
PUBLIC:表示将权限授予所有人
WITH GRANT OPTION:表示获得了这个权限的用户还可以将权限赋给其他用户。
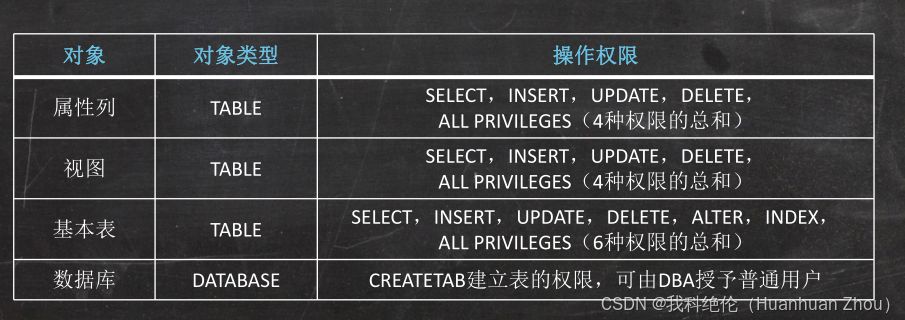
授权(GRANT)
例:用户要求把数据库SPJ中供应商S、零件P、项目J表赋予各种权限。各种授权要求如下:
(1)将对供应商S、零件P、项目J的所有操作权限赋给用户User1及User2。
GRANT ALL PRIVILEGES
ON TABLE S,P,J
TO USER1,USER2;
(2)将对供应商S的插入权限赋给用户User1,并允许将此权限赋给其他用户。
GRANT INSERT
ON TABLE S
TO USER1 WITH GRANT OPTION;
(3)DBA把数据库SPJ中建立表的权限赋给用户User1。
GRANT CREATETAB
ON DATABASE SPJ
TO User1;
收回权限(REVOKE)
语句格式: REVOKE 权限 ON TABLE/DATABASE 表名/数据库名
FROM 用户1,用户2… /PUBLIC
[RESTRICT | CASCADE];
RESTRICT:表示只收回语句中指定的用户的权限
CASCADE:表示除了收回指定用户的权限外,还收回该用户赋予的其他用户的权限。
例:将用户User1及User2对供应商S、零件P、项目J的所有操作权限收回:
REVOKE ALL PRIVILEGES ON TABLE S,P,J FROM User1,User2;
将所有用户对供应商S的所有查询权限收回:
REVOKE SELECT ON TABLE S FROM PUBLIC;
将User1用户对供应商S的供应商编号Sno的修改权限收回。
REVOKE UPDATE(Sno) ON TABLE S FROM User1;
触发器概述
• 触发器主要有以下三方面的特点:
(1)当数据库程序员声明的事件发生时,触发器被激活。声明的事件可以是对某个特定关系的插入、删除或更
新。
(2)当触发器被事件激活时,不是立即执行,而是首先由触发器测试触发条件,如果事件不成立,响应该事件
的触发器什么都不做。
(3)如果触发器声明的条件满足,则与该触发器相连的动作由DBMS执行。动作可以阻止事件发生,可以撤销事
件。
• 创建触发器时需指定:
(1)触发器名称
(2)在其上定义触发器的表
(3)触发事件:触发器将何时激发
(3)触发条件:满足什么条件时执行触发动作
(4)触发动作:指明触发器执行时应做的动作
• 触发器可以引用当前数据库以外的对象,但只能在当前数据库中创建触发器。
• 不能在临时表或系统表上创建触发器,但触发器可以引用临时表。
创建触发器
CREATE TRIGGER 触发器名称 [BEFORE | AFTER]
[DELETE | INSERT | UPDATE OF 列名]
//触发事件
ON 表名
[REFERENCING <临时视图名>]
[FOR EACH ROW | FOR EACH STATEMENT]
[WHEN <触发条件>]
//WHEN后面跟触发条件,指明当什么条件满足时,执行下面的触发动作
BEGIN
<触发动作>
//BEGIN…END 中定义触发动作,即当触发条件满足时,需要数据库做什么
END [触发器名称]
BEFORE/AFTER:指明是在执行触发语句之前激发触发器还是执行触发语句之后激发触发器。
DELETE:当一个DELETE语句从表中删除行时激发触发器。
INSERT:当一个INSERT语句向表中插入行时激发触发器。
UPDATE/UPDATE OF(列名):当UPDATE修改表中的值时,激发触发器,也可加(OF 列名)指定是某一列的值被修改时激发触发器。
REFERENCING:触发器运行过程中,系统会生成两个临时视图,分别存放更新前和更新后的值,对于行级触发器,为OLD ROW
和NEW ROW,对于语句级触发器,为OLD TABLE和NEW TABLE。
REFERENCING new row AS nrow / REFERENCING old row AS orow 。
FOR EACH ROW:表示为行级触发器,对每一个被影响的元组(即每一行)执行一次触发过程。
FOR EACH STATEMENT:表示为语句级触发器,对整个事件只执行一次触发过程,为默认方式。
更改和删除触发器
1、更改触发器
语句格式:
ALTER TRIGGER <触发器名> [BEFORE|AFTER]
DELETE|INSERT|UPDATE OF [列名]
ON 表名|视图名
AS
BEGIN
要执行的SQL语句
END
2、删除触发器
语句格式:
DROP TRIGGER <触发器名>
嵌入式SQL与存储过程
嵌入式SQL
• SQL提供了将SQL语句嵌入到某种高级语言中的方式,通常采用预编译的方法。
1、区分主语言与SQL语句的方式:
EXEC SQL <SQL语句>
2、向主语言传递SQL语句执行的状态信息的方式:
SQLCA,即SQL通信区,是系统默认定义的全局变量。
3、主变量(共享变量):
• 主语言通过主变量向SQL语句提供参数,主变量是由主语言的程序定义的,并用SQL的DECLARE语句
说明。
• 在SQL语句中,为了与SQL中的属性名区分,在引用共享变量时,前面需要加“:”
游标
• SQL语言是面向集合的,一条SQL语句可以产生或处理多条记录。而主语言是面向记录的,一组主变量一次只能放一条记录,所以,引入游标,通过移动游标指针来决定获取哪一条记录。

存储过程
• 存储过程(Procedure):是一组为了完成特定功能的SQL语句集合,经编译后存储在数据
库中,用户通过指定存储过程的名称并给出参数来执行。
• 存储过程中可以包含逻辑控制语句和数据操纵语句,它可以接受参数、输出参数、返回
单个或多个结果集以及返回值。
• 由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过
程运行要比单个的SQL语句块要快。
• 语句格式:
CREATE PROCEDURE 存储过程名(IN|OUT|IN OUT 参数1 数据类型,IN|OUT|IN OUT 参数2 数据类型…)
[AS]
//参数的数据类型只需要指明类型名即可,不需要指定宽度。具体宽度由外部调用者决定
BEGIN
<SQL语句>
END
IN:为默认值,表示该参数为输入型参数,在过程体中值一般不变。
OUT:表示该参数为输出参数,可以作为存储过程的输出结果,供外部调用者使用。
IN OUT: 既可作为输入参数,也可作为输出参数。


)


)


:)
基础自定义分区器)






![[250521] DBeaver 25.0.5 发布:SQL 编辑器、导航器全面升级,新增 Kingbase 支持!](http://pic.xiahunao.cn/[250521] DBeaver 25.0.5 发布:SQL 编辑器、导航器全面升级,新增 Kingbase 支持!)


