1.客户端类型 推荐场景 版本兼容性
Elasticsearch Java API Client 新项目、ES 8.x+集群 8.x及以上
Spring Data Elasticsearch Spring生态项目、简化ORM操作 ES 7.x-8.x(需版本匹配)
Low-Level REST Client 需要底层HTTP控制、兼容多版本ES 全版本
high-level已经被弃用。
2.ik_smart 分出后不再细分。程序员
ik_max_word. 程序员 程序 员 多次递归分解。
3.ELK:
典型架构演变
基础架构:
Beats/Logstash → Elasticsearch → Kibana
适用于小型系统,资源占用低,但缺乏缓冲和复杂处理能力
。
生产级架构:
Beats → Kafka → Logstash → Elasticsearch → Kibana
引入消息队列(如Kafka)缓冲数据,支持高并发和大规模日志处理
。
混合架构:
结合Beats和Logstash优势,Beats负责轻量采集,Logstash处理复杂过滤和格式转换
。
4.原理:
构建了词到text的映射:

5.为什么使用nested object 嵌套对象
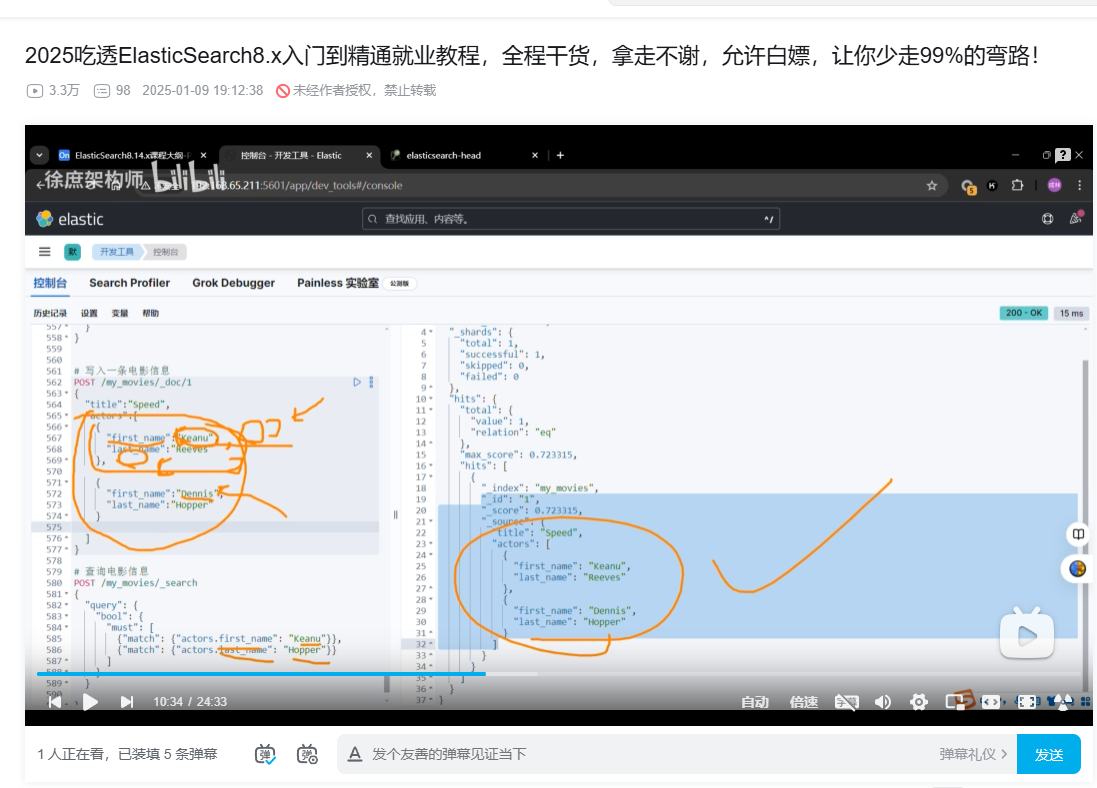
es存储时对 数组对象的属性做了扁平化处理。
比如firstName 单独生成一个数组,把其他对象的这个字段一起存起来。
这样在尝试多个属性的与查询时,会遇到非预期结果。
如图,只要一个属性匹配到就会出结果。
所以使用nested object.
“tie”表示“平局、胶着”,“break”意为“打破”。组合后指通过特定规则或操作解决势均力敌的状态,常见于以下场景:
体育比赛
如网球中“抢七”(tie-break):当双方局分6:6时,通过抢七局决胜负,避免比赛无限延长
。规则要求选手至少领先2分(如7:5或8:6)才能胜出,体现对“绝对优势”的要求。
其他应用:板球通过“超级轮”(super over)、足球通过点球大战打破平局
。
编程与算法
在哈希冲突或排序逻辑中,当两个对象的哈希值(hashCode)相同且无法直接比较时,需通过额外规则(如内存地址、插入顺序)决定优先级,称为“tie-break order”[^用户代码注释]。
无论是体育还是Elasticsearch,tie break的本质都是通过规则设计,在平衡状态中选择更合理的胜出方。
参考来源: concurrentHashMap中的比较hash大小 以及 Elasticsearch:dis_max查询与tie_breaker参数
在 Elasticsearch 的 Mapping 定义中,title 字段下定义的 sdt 是子字段(sub-field),而非子对象或子属性。这是通过 fields 参数实现的多字段(multi-field)特性,允许一个字段以不同方式被索引和分析。
一、核心概念解析
fields 的作用
fields 参数允许为同一字段定义多个子字段,每个子字段可指定不同的数据类型或分词器。例如:
jsonjson复制markdown复制"title": {
“type”: “text”,
“analyzer”: “english”, // 主字段使用英文分词器
“fields”: {
“sdt”: { // 子字段 sdt
“type”: “text”,
“analyzer”: “standard” // 使用标准分词器
}
}
}
主字段 title:默认使用 english 分词器(如词干提取、停用词过滤)。
子字段 title.sdt:使用 standard 分词器(仅按空格分割,无词干处理)。
这个是为实现multi-field 查询而增加的子字段。(即表示此字段可以以其他类型或分词方式去进行搜索。)
)









)








