锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

unstack() 是 pandas 中用于数据重塑的重要方法,它与 stack() 互为逆操作。unstack() 的主要功能是将行索引的某一层级转换为列索引,从而将数据从长格式转换为宽格式。
基本语法
DataFrame.unstack(level=-1, fill_value=None)参数说明
-
level (默认为
-1):-
指定要移动到列索引的行索引层级
-
可以是整数(层级位置)、字符串(层级名称)或列表(多个层级)
-
-1表示最内层(默认值)
-
-
fill_value (默认为
None):-
用于替换缺失值的填充值
-
如果不指定,缺失值将显示为 NaN
-
1,基本操作:将行索引转换为列索引
import pandas as pd
# 创建多级索引的 Series
index = pd.MultiIndex.from_tuples([('A', 'X'), ('A', 'Y'),('B', 'X'), ('B', 'Y')
])
s = pd.Series([1, 2, 3, 4], index=index)
print("原始Series:")
print(s)
执行 unstack():result = s.unstack()
print("\nunstack() 结果:")
print(result)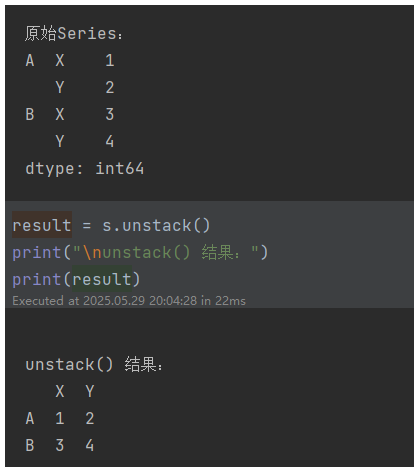
2,指定要转换的层级
import pandas as pd
# 创建三级索引的 Series
index = pd.MultiIndex.from_tuples([('I', 'A', 'X'), ('I', 'A', 'Y'),('II', 'B', 'X'), ('II', 'B', 'Y')
])
s = pd.Series([10, 20, 30, 40], index=index)
print("初始数据:")
print(s)
# 转换不同层级
print("转换最内层 (level=-1):")
print(s.unstack()) # 默认转换最内层
print("\n转换第一层 (level=0):")
print(s.unstack(level=0))
print("\n转换第二层 (level=1):")
print(s.unstack(level=1))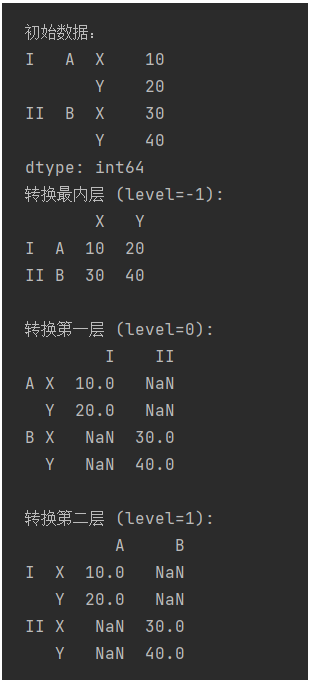















)



