【Linux】awk 命令详解及使用示例:结构化文本数据处理工具
引言
awk 是一种强大的文本处理工具和编程语言,专为处理结构化文本数据而设计。它的名称来源于其三位创始人的姓氏首字母:Alfred Aho、Peter Weinberger 和 Brian Kernighan。
基本功能
- 文本分析:按列/字段处理结构化文本数据
- 模式匹配:根据条件筛选文本
- 数据处理:支持算术运算和字符串操作
- 报表生成:格式化输出结果
工作原理
- awk 逐行读取输入
- 将每行按分隔符(默认是空格)分割为字段
- 对每行应用模式匹配和操作
- 输出处理结果
内置变量
$0- 当前整行内容$1,$2, … - 第1个、第2个…字段NF- 当前行的字段数$NF- 最后一个字段NR- 当前处理的行号FNR- 当前文件中的行号FS- 输入字段分隔符(默认为空白字符)OFS- 输出字段分隔符RS- 输入记录分隔符(默认为换行符)ORS- 输出记录分隔符FILENAME- 当前输入文件名
常用选项
-F 分隔符- 指定输入字段分隔符-v var=值- 设置变量-f 脚本文件- 从文件读取awk脚本
程序结构
awk程序可以包含三部分:
BEGIN { ... }- 在处理文本前执行pattern { action }- 对匹配的每一行执行END { ... }- 在处理完所有文本后执行
awk 'BEGIN {print "开始处理"} {sum += $1} END {print "总和:", sum}' data.txt
控制结构
awk支持常见的编程语言控制结构:
- 条件:
if-else - 循环:
for,while,do-while - 分支:
switch
# 使用if条件
awk '{if ($1 > 10) print "大于10:", $0; else print "小于等于10:", $0}' file.txt# 使用for循环
awk '{for(i=1; i<=3; i++) print $i}' file.txt
内置函数
awk提供了丰富的内置函数:
- 数学函数:
sqrt(),sin(),rand() - 字符串函数:
length(),substr(),index(),match() - 时间函数:
systime(),strftime() - 其他函数:
gsub(),system()
使用示例
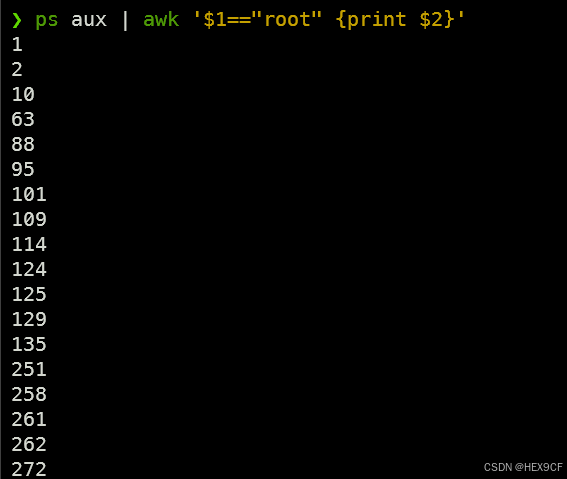
- 利用awk命令获取查看用户为root的进程PID信息
ps aux | awk '$1=="root" {print $2}'
- 利用列出/bin目录下连接文件的创建日期或者是最近的修改日期
ls -l /bin | awk '/^l/ {print $6, $7, $8}'

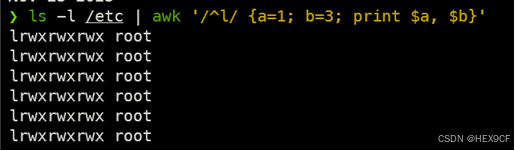
- 利用awk指令设置变量a=1,b=3并查找/etc目录下连接文件中第 a , a, a,b列的字符信息
ls -l /etc | awk '/^l/ {a=1; b=3; print $a, $b}'
- 利用awk列出/bin目录下连接文件的权限信息(使用substr内置函数)
ls -l /bin | awk '/^l/ {print substr($1, 1, 10)}'

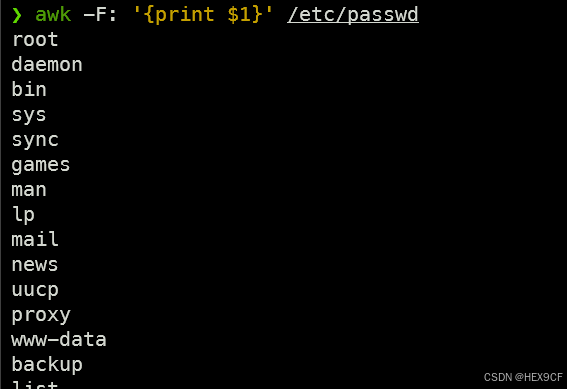
- 利用awk命令在/etc/passwd文件中显示以:作为分隔的第1列的数据
awk -F: '{print $1}' /etc/passwd
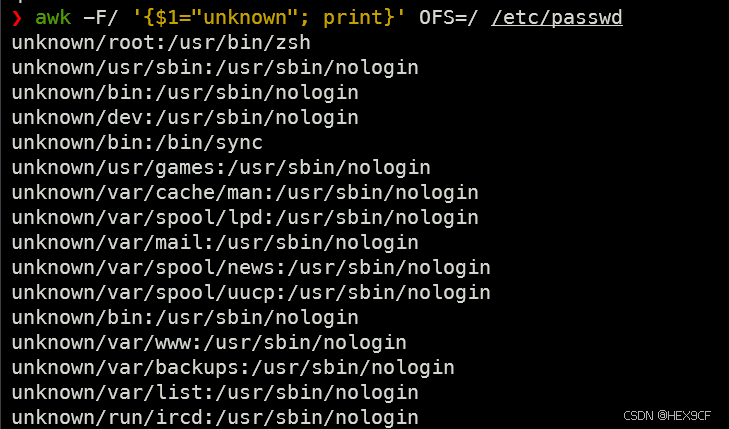
- 利用awk命令在/etc/passwd文件中第一个"/“符号前面的字段变为"unknown”
awk -F/ '{$1="unknown"; print}' OFS=/ /etc/passwd
参考资料
- https://www.runoob.com/linux/linux-comm-awk.html
/串并转换器(解串器))



)
动手学线性神经网络:从数学原理到代码实现)









(1984-2018))



