关于Tensorrt的python api文档阅读翻译加总结
文档源地址
Overview
Getting started with TensorRT
Installation(安装)
安装可参考:官方地址
Samples
关于样例的内容可参考:样例地址
Operator Documentation
有关更多信息(包括示例),请参阅 TensorRT Operator’s Reference documentation
Installing cuda-python
虽然 TensorRT Python API 不需要,但 cuda-python 用于多个示例。有关安装说明,请参阅 CUDA Python 安装文档 。
Core Concepts
TensorRT Workflow工作流
Class Overview类概述
Logger(记录器)
Tensorrt提供一个tensorrt.Logger实现,基本功能都有,但是可以重写获取更高级的功能.
Parsers(解析器)
Parasers用于填充tensorrt.INetworkDefinition(来自深度学习训练的模型)
Newwork(网络)
tensorrt.INetworkDefinition表示一个计算图,为了填充网络,TensorRT提供了一套适用于各种深度学习框架的解析器,您也可以使用网络API手动填充网络
Builder(构建器)
tensorrt.Builder用于构建tensorrt.ICudaEngine
为此必须提供一个tensorrt.INetworkDefinition
Engine and Context(引擎和上下文)
tensorrt.ICudaEngine是TensorRT的输出,生成可执行推理的tensorrt.IExecutionContext.
Writing custom operators with TensorRT python plugins(使用TensorRT Python插件编写自定义运算符)
本指南展示了如何实现和包装定义插件行为的 Python 函数,以便将其作为自定义算子添加到网络中。
Composition of a plugin(plugin的组成)
需要定义两个函数,由tensorrt.plugin提供的装饰器包装
1、tensorrt.plugin.register()
tensorrt.plugin.register()返回输出张量的形状和类型特征。函数签名还定义了输入张量以及插件运行所需的任何属性。
2、tensorrt.plugin.impl()ortensorrt.plugin.aot_impl()
tensorrt.plugin.impl():JIT计算定义(A Just-in-Time compute definition)
tensorrt.plugin.aot_impl()AOT计算定义(A Ahead-of-Time compute definition)
Example: Circular padding plugin(圆形填充插件)
具体内容可见此官方链接
使用经典JIT实现(一般需要register和impl两个函数)
TensorRT 允许通过自定义插件扩展支持的算子(如这里的循环填充)。插件需要定义两部分关键信息:
形状描述:告知 TensorRT 输入输出的形状、数据类型等元信息(由 circ_pad_plugin_desc 函数实现)。
import tensorrt.plugin as trtp
import numpy.typing as npt@trtp.register("example::circ_pad_plugin")
def circ_pad_plugin_desc( # 注册插件名称()inp0: trtp.TensorDesc, # 输入张量的描述(形状、数据类型等)pads: npt.NDArray[np.int32]# 填充参数(各维度的前后填充量)
) -> trtp.TensorDesc: # 返回输出张量的描述ndim = inp0.ndimout_desc = inp0.like()for i in range(np.size(pads) // 2):out_desc.shape_expr[ndim - i - 1] += int(pads[i * 2] + pads[i * 2 + 1])return out_desc
cicular padding plugin的具体实现如下
import tensorrt.plugin as trtp@trtp.impl("example::circ_pad_plugin")# 注册插件实现(名称需与形状描述函数一致)
def circ_pad_plugin_impl(inp0: trtp.Tensor,# 输入张量(来自 TensorRT 的输入绑定)pads: npt.NDArray[np.int32],# 填充参数(各维度的前后填充量)outputs: Tuple[trtp.Tensor],# 输出张量元组(可能包含多个输出,此处仅一个)stream: int # CUDA 流句柄(用于计算同步)
) -> None:inp_t = torch.as_tensor(inp0, device="cuda")# 将输入张量转为 PyTorch CUDA 张量out_t = torch.as_tensor(outputs[0], device="cuda")# 将输出张量转为 PyTorch CUDA 张量out = torch.nn.functional.pad(inp_t, pads.tolist(), mode="circular")# 循环填充out_t.copy_(out)# 将填充结果复制到输出张量(共享内存时可省略,但显式复制更安全)
关于以上两端代码的内容,总结下来为:这两段代码分别对应 TensorRT 自定义插件开发中的两个核心部分:插件描述注册(Shape Inference)和插件计算实现(Execution),主要区别如下:
1.功能定位不同
第一段(@trtp.register装饰的函数):
负责定义插件的形状推断逻辑(Shape Inference)。
作用是在 TensorRT 构建网络(如解析模型时)时,根据输入张量的描述(TensorDesc)和插件参数(pads),计算输出张量的形状(如维度大小),确保 TensorRT 能正确分配内存、优化网络结构。
第二段(@trtp.impl装饰的函数):
负责定义插件的实际计算逻辑(Execution)。
作用是在模型推理时,根据输入张量的数据、插件参数(pads)和 CUDA 流(stream),完成具体的计算操作(如循环填充),并将结果写入输出张量。
2.执行截断不同
第一段(形状推断):
在 TensorRT 网络构建阶段(如解析 ONNX 模型、优化引擎时)执行,仅需要元信息(形状、数据类型),不需要实际数据。
第二段(计算实现):
在模型推理阶段(引擎运行时)执行,需要操作真实的输入 / 输出数据,并通过 CUDA 流管理计算同步。
Providing an Ahead-of-time(AOT)implement (提供预先AOT实现)
与tensorrt.plugin.impl()提供的JIT实现相比,AOT实现具有以下优势:
1、为插件构建具有 JIT 计算功能的 TRT 引擎需要其 tensorrt.plugin.register() 和 tensorrt.plugin.impl() Python 定义在运行时均存在。使用 AOT 实现时,插件将完全嵌入到引擎中,因此运行时无需用户提供插件定义。
2、插件层在运行时独立于 Python。这意味着,如果 TRT 引擎仅包含 AOT 插件,它可以在标准 TRT 运行时上执行,就像使用已编译的 C++ 插件的引擎一样,例如通过 trtexec 执行。
tensorrt.plugin.aot_impl()可用于插件的AOT实现。使用OpenAI Triton内核定义一个AOT实现:
import triton
import triton.language as tl@triton.jit
# Triton内核,定义循环填充的具体计算逻辑
def circ_pad_kernel(# input tensorX,#输入数据,存储在GPU内存中# extra scalar args in between input and output tensors 填充参数和维度信息(如输入/输出的各维度大小,总元素数)all_pads_0,all_pads_2,all_pads_4,all_pads_6,orig_dims_0,orig_dims_1,orig_dims_2,orig_dims_3,Y_shape_1,Y_shape_2,Y_shape_3,X_len,Y_len,# output tensorY, #填充后的结果(需写入 GPU 内存)BLOCK_SIZE: tl.constexpr,#Triton 内核的线程块大小
):pid = tl.program_id(0) #通过 tl.program_id(0) 获取当前线程块的 ID(pid)i = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE) #计算每个线程的全局索引imask_y = i < Y_len
#将全局索引 i 分解为输出张量的多维坐标 (i0, i1, i2, i3)(对应输出的各维度位置)i3 = i % Y_shape_3i2 = (i // Y_shape_3) % Y_shape_2i1 = (i // Y_shape_3 // Y_shape_2) % Y_shape_1i0 = i // Y_shape_3 // Y_shape_2 // Y_shape_1
#将输出的位置 (i0, i1, i2, i3) 映射回原始输入张量 X 的位置 (j0, j1, j2, j3)j0 = (i0 - all_pads_0 + orig_dims_0) % orig_dims_0j1 = (i1 - all_pads_2 + orig_dims_1) % orig_dims_1j2 = (i2 - all_pads_4 + orig_dims_2) % orig_dims_2j3 = (i3 - all_pads_6 + orig_dims_3) % orig_dims_3load_idx = (orig_dims_3 * orig_dims_2 * orig_dims_1 * j0+ orig_dims_3 * orig_dims_2 * j1+ orig_dims_3 * j2+ j3)#计算输入张量 X 中的线性索引 load_idx,并通过 tl.load 加载数据(带越界检查 mask_x)mask_x = load_idx < X_len
#将加载的数据通过 tl.store 写入输出张量 Y 的对应位置(带越界检查 mask_y)x = tl.load(X + load_idx, mask=mask_x)tl.store(Y + i, x, mask=mask_y)@trtp.aot_impl("example::circ_pad_plugin")##@trtp.aot_impl标记,是TensorRT的预编译实现接口,负责将 Triton 内核编译为 CUDA 代码,并配置 TensorRT 运行时所需的参数。
def circ_pad_plugin_aot_impl(inp0: trtp.TensorDesc, pads: npt.NDArray[np.int32], outputs: Tuple[trtp.TensorDesc], tactic: int
) -> Tuple[Union[str, bytes], Union[str, bytes], trtp.KernelLaunchParams, trtp.SymExprs]:assert tactic == 0 #假设仅支持默认优化策略block_size = 256 #Triton内核的线程块大小type_str = "fp32" if inp0.dtype == trt.float32 else "fp16"#根据输入数据类型fp32/fp16生成类型字符串type_str用于内核签名### Triton内核编译#使用 triton.compiler.ASTSource 包装内核函数,指定其签名(输入输出类型)和编译时常量(BLOCK_SIZE)。src = triton.compiler.ASTSource(fn=circ_pad_kernel,signature=f"*{type_str},{','.join(['i32']*13)},*{type_str}",##签名格式constants={"BLOCK_SIZE": block_size,},)compiled_kernel = triton.compile(src)#调用triton.compile编译内核,生成包含PTX汇编代码和元数据的compiled_kernel.#### 内核启动该参数配置launch_params = trtp.KernelLaunchParams()N = inp0.ndimall_pads = np.zeros((N * 2,), dtype=np.int32)inp_dims = inp0.shape_exprout_dims = outputs[0].shape_exprfor i in range(np.size(pads) // 2):all_pads[N * 2 - 2 * i - 2] = pads[i * 2]all_pads[N * 2 - 2 * i - 1] = pads[i * 2 + 1]# grid dimslaunch_params.grid_x = trtp.cdiv(out_dims.numel(), block_size)##grid维度,根据输出张量的总元素数(out_dims.numel())和 BLOCK_SIZE 计算(向上取整)。# block dimslaunch_params.block_x = compiled_kernel.metadata.num_warps * 32#线程块内的线程数 warpx32# shared memorylaunch_params.shared_mem = compiled_kernel.metadata.shared#内核使用的共享内存大小all_pads = all_pads.tolist()# Representing all int32 scalar inputs as symbolic expressions.# These inputs are either constants or derivatives of input/output shapes.# The symbolic expressions are resolved after the full shape context becomes available at runtime.# For the `circ_pad_kernel`, there are 13 such scalar extra-arguments, corresponding to the 13 arguments# between the mandatory input and output tensors in the triton kernel's function signature.
#将内核需要的 13 个标量参数(如填充量、输入 / 输出维度、总元素数)转换为 trtp.SymIntExprs(符号整数表达式)。
#这些符号参数在 TensorRT 运行时会根据实际输入 / 输出的形状解析为具体数值(例如,动态形状场景下,维度可能在运行时确定)。extra_args = trtp.SymIntExprs.from_tuple([trtp.SymInt32(e)for e in [all_pads[0],all_pads[2],all_pads[4],all_pads[6],inp_dims[0],inp_dims[1],inp_dims[2],inp_dims[3],out_dims[1],out_dims[2],out_dims[3],inp_dims.numel(),out_dims.numel(),]])return compiled_kernel.metadata.name, compiled_kernel.asm["ptx"], launch_params, extra_args ## 返回编译完的内核名称compiled_kernel.metadata.name## PTX代码:compiled_kernel.asm["ptx"]## 启动参数:launch_params## 符号参数:extra_args##以上内容供TensorRT在构建引擎时使用处理动态形状时,调用 tensorrt.plugin.aot_impl() 时可能无法知道具体的 I/O 维度。因此,内核启动参数和额外的内核参数以符号形式指定。
选择性能最佳的插件配置(自动调整autotuning)
如果插件能同时支持fp32和fp16,且不确定哪个性能更好
那么可以使用tensorrt.plugin.autotune()
@trtp.autotune("example::circ_pad_plugin")
def circ_pad_plugin_autotune(inp0: trtp.TensorDesc,pads: npt.NDArray[np.int32],outputs: Tuple[trtp.TensorDesc],
) -> List[trtp.AutoTuneCombination]:return [trtp.AutoTuneCombination("FP32|FP16, FP32|FP16", "LINEAR")]
Adding the plugin to a TensorRT network(将插件添加到TensorRT网络)
通过trt的python api 添加。api为:tensorrt.INetworkDefinition
Addding the plugin using TRT Python APIs
主要使用tensorrt.INetworkDefinition.add_plugin()可用于将插件添加到网络定义实例tensorrt.INetworkDefinition
input_tensor = network.add_input(name="x", dtype=trt.DataType.FLOAT, shape=x.shape)
plugin_layer = network.add_plugin(trt.plugin.op.example.circ_pad_plugin(input_tensor, pads = pads), aot = False)
注:
1、已经注册过的plugin可以在命名空间和tensorrt.plugin.op下找到
2、tensorrt.INetworkDefinition.add_plugin()采用boolean参数,可以使用aot参数选择究竟是AOT还是JIT实现。如果只有一个,那么可以不改
当Plugin同时定义了AOT和JIT实现后,可以通过全局设置来选择哪个实现
tensorrt.NetworkDefinitionCreationFlag.PREFER_AOT_PYTHON_PLUGINS
tensorrt.NetworkDefinitionCreationFlag.PREFER_JIT_PYTHON_PLUGINS
builder = trt.Builder(trt.Logger(trt.Logger.INFO))
# Always choose AOT implementations wherever possible
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.PREFER_AOT_PYTHON_PLUGINS))
...
# Now the `aot` argument can be omitted (and TRT will choose the AOT implementation)
plugin_layer = network.add_plugin(trt.plugin.op.example.circ_pad_plugin(input_tensor, pads = pads))
Loading an ONNX model with custom operator
使用自定义运算符加载ONNX模型
如果要通过TRT插件运行该插件,得保证:
1、ONNX 节点 op 的属性与您的插件名称完全相同。
2、该节点包含一个 string 属性,该属性以插件的命名空间命名 plugin_namespace 。
3、对于同时具有 AOT 和 JIT 实现的插件,必须制定实现方式
详情见此处
例如:使用ONNX Graphsurgeon,构建方式如下:
import onnx_graphsurgeon as gsvar_x = gs.Variable(name="x", shape=inp_shape, dtype=np.float32)
var_y = gs.Variable(name="y", dtype=np.float32)circ_pad_node = gs.Node(name="circ_pad_plugin",op="circ_pad_plugin",inputs=[var_x],outputs=[var_y],attrs={"pads": pads, "plugin_namespace": "example"},
)
高级用法
详情见此处
1、为具有数据相关输出形状的算子(如 non-zero)构建 shape 推导逻辑
2、TensorRT 插件中如何使用 .aliased() 方法实现就地计算操作,即让输出复用输入张量的内存,节省资源、提升性能。常用于加法、归一化等操作无需新内存开销的场景
3、如何在 TensorRT 插件中支持多个后端(backend)实现,并通过自动调优(autotune)选择性能最优的后端,即 自定义策略(tactic)机制。
TENSORRT PYTHON API REFERENCE
Foundational Types
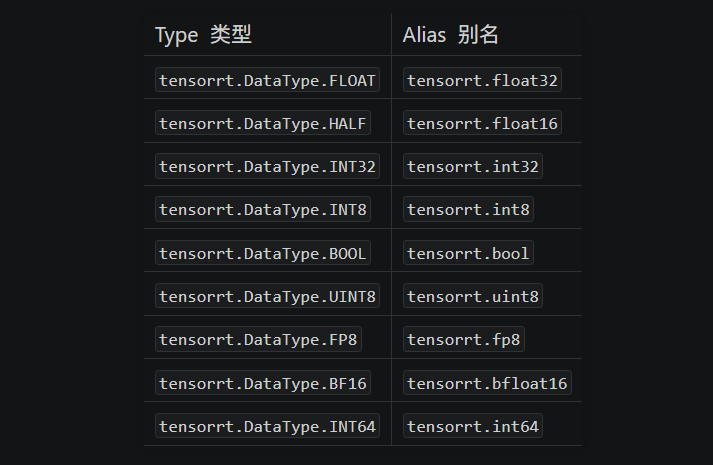
DataType
Weights
略
Dims
略
IHostMemory
tensorrt.IHostMemory 是 TensorRT 用于返回如序列化模型等缓冲数据的对象,它支持 buffer 协议、由 TensorRT 自动管理生命周期,常通过 engine.serialize() 获得,并用于保存或传输模型数据。
Core
Logger
记录器,也可以自己实现,详情见官网
ILogger接口
ILogger 是 TensorRT 日志系统的抽象基类,用于 Builder、ICudaEngine 和 Runtime 的日志记录。
主要特性:
必须显式地在子类的 init 中实例化基类
需要实现 log 方法
有 min_severity 属性控制日志级别
class MyLogger(trt.ILogger):def __init__(self):trt.ILogger.__init__(self)def log(self, severity, msg):... # Your implementation here
日志严重级别:
1、INTERNAL_ERROR:内部错误,不可恢复
2、ERROR - 应用程序错误
3、WARNING - 应用程序错误但已恢复或回退到默认值
4、INFO - 信息性消息
5、VERBOSE- 调试信息
Logger类
Logger 是 ILogger 的具体实现,默认将日志输出到 stdout。
Logger(min_severity=Severity.WARNING)
使用场景
自定义日志:继承 ILogger 实现自己的日志系统
默认日志:直接使用 Logger 类
控制日志级别:通过 min_severity 过滤不重要消息
Profiler
TensorRT 提供了性能分析接口 IProfiler 和默认实现 Profiler,用于测量神经网络各层的执行时间。
IProfiler
IProfiler 是 TensorRT 性能分析的抽象基类,用于自定义性能分析器。
主要特性:
必须显式地在子类的 init 中实例化基类
需要实现 report_layer_time 方法
绑定到 IExecutionContext 后,每次执行 execute_v2() 都会调用
class MyProfiler(trt.IProfiler):def __init__(self):trt.IProfiler.__init__(self)self.layer_times = {}def report_layer_time(self, layer_name, ms):# 自定义性能数据收集self.layer_times[layer_name] = msprint(f"Layer {layer_name} took {ms:.2f} ms")
Profiler
Profiler 是 IProfiler 的具体实现,默认将各层执行时间输出到 stdout。
主要方法:
report_layer_time(layer_name, ms) - 报告单层执行时间
使用场景:
性能分析:测量网络中各层的执行时间
瓶颈识别:找出执行时间最长的层进行优化
性能调优:比较不同优化策略的效果
工作原理
将 profiler 实例绑定到 IExecutionContext
每次调用 execute_v2() 执行推理时:
对每个层调用一次 report_layer_time
传入层名称和执行时间 (毫秒)
重要注意事项
性能影响:启用 profiler 会增加执行时间,不适用于生产环境
层名称:如果构建引擎时设置 profiling_verbosity=NONE,层名会显示为十进制索引
多次执行:多次调用 execute_v2() 会多次触发 profiler 回调
#创建自定义 profiler
profiler = MyProfiler()
#绑定到执行上下文
context.profiler = profiler
#执行推理(会触发 profiler 回调)
context.execute_v2(buffers)分析结果
slowest_layer = max(profiler.layer_times.items(), key=lambda x: x[1])
print(f"Slowest layer: {slowest_layer[0]} took {slowest_layer[1]:.2f} ms")
IOptimizationProfile
IOptimizationProfile 是 TensorRT 中用于处理动态输入维度和形状张量的优化配置文件类,主要用于构建具有动态输入尺寸的网络。
核心概念
动态输入:当网络输入的一个或多个维度被指定为 - 1 时,需要定义优化配置文件
多配置文件:可以定义多个优化配置文件(索引从 0 开始),索引 0 的配置文件是默认使用的
三组尺寸:必须为每个动态输入指定最小 (min)、最优 (opt) 和最大 (max) 三种尺寸
主要功能
- 形状管理
set_shape(input, min, opt, max):设置动态输入张量的三种尺寸
get_shape(input):获取动态输入张量的三种尺寸 - 形状输入管理(针对形状张量)
set_shape_input(input, min, opt, max):设置形状输入张量的值范围
get_shape_input(input):获取形状输入张量的值范围 - 内存控制
extra_memory_target:控制为额外优化配置文件分配的内存比例(0.0-1.0)
使用场景
动态批处理:处理可变批量大小的输入
可变分辨率:处理不同尺寸的输入图像
可变序列长度:处理不同长度的序列输入
重要约束条件
1、对于动态输入张量:
三种尺寸的维度数量必须相同
必须满足 min [i] ≤ opt [i] ≤ max [i]
如果原始网络定义中维度不是 - 1,则三种尺寸必须等于原始尺寸
2、对于形状张量:
必须满足 min [i] ≤ opt [i] ≤ max [i]
只能用于标记为形状张量的输入
使用示例
# 创建优化配置文件
profile = builder.create_optimization_profile()# 设置动态输入尺寸
input_name = network.get_input(0).name
profile.set_shape(input_name, min=(1, 3, 224, 224), # 最小尺寸opt=(8, 3, 224, 224), # 最优尺寸max=(32, 3, 224, 224)) # 最大尺寸# 设置形状输入张量的值范围
shape_input_name = network.get_input(1).name
profile.set_shape_input(shape_input_name,min=[1], opt=[4], max=[8])# 添加到构建配置
config.add_optimization_profile(profile)
注意事项
第一个优化配置文件 (索引 0) 是默认使用的
启用多个优化配置文件会增加内存使用
完整的验证在引擎构建时进行
可以通过 bool 检查验证配置文件的可用性:if profile: …
IBuilderConfig
IBuilderConfig 是 TensorRT 中用于配置引擎构建过程的核心类,它控制着如何优化和构建神经网络引擎。
核心功能概览
- 构建模式控制
支持多种精度模式:FP32、FP16、BF16、INT8、FP8、INT4 等
控制优化级别(0-5 级)
设置硬件兼容性级别 - 设备配置
指定默认设备类型(GPU/DLA)
为特定层设置执行设备
配置 DLA 核心 - 内存管理
控制不同类型内存池的大小限制
包括工作空间、DLA 内存、共享内存等 - 性能优化
设置优化配置文件(用于动态形状)
控制策略源(tactic sources)
配置时间缓存(timing cache)
关键配置项详解
BuilderFlag精度控制标志
config.set_flag(trt.BuilderFlag.FP16) # 启用FP16
config.set_flag(trt.BuilderFlag.INT8) # 启用INT8
builder_optimization_level优化级别
0 级:最快编译,禁用动态内核生成
3 级(默认):平衡编译时间和性能
5 级:最全面的优化,但编译时间最长
HardwareCompatibilityLevel硬件兼容性
config.hardware_compatibility_level = trt.HardwareCompatibilityLevel.AMPERE_PLUS
内存池配置
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30) # 1GB工作空间
高级功能
动态形状支持
profile = builder.create_optimization_profile()
profile.set_shape("input", (1,3,224,224), (8,3,224,224), (32,3,224,224))
config.add_optimization_profile(profile)
时间缓存
cache = config.create_timing_cache(serialized_cache)
config.set_timing_cache(cache, ignore_mismatch=False)
策略源控制
sources = 1 << int(trt.TacticSource.CUBLAS_LT) | 1 << int(trt.TacticSource.CUDNN)
config.set_tactic_sources(sources)
使用示例
# 创建构建配置
config = builder.create_builder_config()# 设置基本构建选项
config.set_flag(trt.BuilderFlag.FP16)
config.max_workspace_size = 1 << 30 # 1GB# 设置优化级别
config.builder_optimization_level = 3# 添加优化配置文件
profile = builder.create_optimization_profile()
profile.set_shape("input", (1,3,224,224), (8,3,224,224), (32,3,224,224))
config.add_optimization_profile(profile)# 构建引擎
engine = builder.build_engine(network, config)
重要注意事项
INT8 校准:在 TensorRT 10.1+ 中已被显式量化取代
DLA 限制:某些层可能无法在 DLA 上运行
内存限制:设置过小的内存池可能导致构建失败
时间缓存:可以显著减少重复构建时间
硬件兼容性:高级别兼容性可能牺牲性能
Builder 类
Builder 类用于从 INetworkDefinition 构建 ICudaEngine。
NetworkDefinitionCreationFlag
NetworkDefinitionCreationFlag 定义了在创建网络时可以设置的不可变网络属性:
EXPLICIT_BATCH (已弃用)
在 TensorRT 10.0 中,网络总是 “显式批处理”,所以此标志被忽略
STRONGLY_TYPED (强类型模式)
指定网络中每个张量都有明确定义的数据类型
只遵循类型推断规则和输入 / 操作符注释
不允许设置层精度和层输出类型
网络输出类型将根据输入类型和类型推断规则自动推断
PREFER_AOT_PYTHON_PLUGINS
如果设置,对于同时有 AOT 和 JIT 实现的 Python 插件,优先使用 AOT 实现
PREFER_JIT_PYTHON_PLUGINS
如果设置,对于同时有 AOT 和 JIT 实现的 Python 插件,优先使用 JIT 实现
主要属性
平台能力检测:
platform_has_tf32: 平台是否支持 tf32
platform_has_fast_fp16: 平台是否有快速原生 fp16 支持
platform_has_fast_int8: 平台是否有快速原生 int8 支持
DLA 相关:
max_DLA_batch_size: DLA 支持的最大批处理大小
num_DLA_cores: 可用的 DLA 引擎数量
其他:
error_recorder: 错误报告接口
gpu_allocator: GPU 内存分配器
logger: 日志记录器
max_threads: Builder 可使用的最大线程数
主要方法
create_network(flags=0)
创建一个空的 INetworkDefinition
参数 flags 是 NetworkDefinitionCreationFlag 的位组合
create_builder_config()
创建构建器配置对象 IBuilderConfig
build_engine_with_config(network, config)
根据网络定义和配置构建并返回引擎 ICudaEngine
build_serialized_network(network, config)
构建并序列化网络,返回 IHostMemory 对象
create_optimization_profile()
创建新的优化配置文件 IOptimizationProfile
对于动态输入张量,需要调用 set_shape() 或 set_shape_input()
is_network_supported(network, config)
检查网络是否符合构建器配置的限制条件
返回布尔值表示是否支持
get_plugin_registry()
获取构建器可以使用的本地插件注册表
reset()
将构建器状态重置为默认值
示例:
这个 Builder 类是 TensorRT 的核心组件,用于将网络定义转换为优化的推理引擎。
import tensorrt as trt# 创建日志记录器和构建器
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)# 创建网络定义(启用强类型模式)
network_flags = 1 << int(trt.NetworkDefinitionCreationFlag.STRONGLY_TYPED)
network = builder.create_network(network_flags)# 创建构建器配置
config = builder.create_builder_config()# 构建引擎
engine = builder.build_engine_with_config(network, config)
TensorIOMode 枚举
TensorIOMode 定义了张量的输入输出模式:
NONE: 张量既不是输入也不是输出
INPUT: 张量是引擎的输入
OUTPUT: 张量是引擎的输出
ICudaEngine 类
ICudaEngine 是 TensorRT 中用于执行推理的核心类,代表一个已构建并优化的网络。
主要属性
基本信息:
num_io_tensors: 输入输出张量总数
num_layers: 网络中的层数(可能与原始网络不同,因优化会合并 / 消除层)
name: 网络名称
内存相关:
max_workspace_size: 引擎使用的最大工作空间
device_memory_size: 执行上下文所需设备内存大小
device_memory_size_v2: 考虑权重流预算的设备内存需求
功能特性:
refittable: 引擎是否可重构
engine_capability: 引擎能力级别
profiling_verbosity: 性能分析详细程度
num_optimization_profiles: 优化配置文件数量
权重流相关 (TensorRT 10.1+):
weight_streaming_budget_v2: 设置 / 获取当前权重流预算
streamable_weights_size: 可流式传输的权重大小
weight_streaming_scratch_memory_size: 执行所需的临时内存大小
主要方法
1、执行上下文创建
create_execution_context(strategy=ExecutionContextAllocationStrategy.STATIC)
创建执行上下文并指定内存分配策略
参数 strategy 可以是 STATIC (默认) 或 MANUAL
create_execution_context_without_device_memory()
创建不分配设备内存的执行上下文
需由应用程序提供内存
2、张量信息查询
get_tensor_mode(name) → TensorIOMode 获取张量是输入 / 输出 / 都不是
get_tensor_dtype(name) → DataType 获取张量数据类型
get_tensor_shape(name) → Dims获取张量形状
get_tensor_profile_shape(name, profile_index) → [min_dims, opt_dims, max_dims] 获取特定优化配置下张量的最小、最优、最大形状
3、序列化相关
serialize() → IHostMemory序列化引擎为可存储的二进制数据
serialize_with_config(config) → IHostMemory使用序列化配置序列化引擎
4、调试与检查
create_engine_inspector() → EngineInspector创建引擎检查器,用于输出层信息
创建引擎检查器,用于输出层信息 检查给定名称是否为调试张量
使用示例:
import tensorrt as trt# 加载序列化引擎
with open("model.engine", "rb") as f:runtime = trt.Runtime(trt.Logger(trt.Logger.INFO))engine = runtime.deserialize_cuda_engine(f.read())# 查询输入输出信息
for i in range(engine.num_io_tensors):name = engine.get_tensor_name(i)mode = engine.get_tensor_mode(name)dtype = engine.get_tensor_dtype(name)shape = engine.get_tensor_shape(name)print(f"{'Input' if mode==trt.TensorIOMode.INPUT else 'Output'} {i}: {name}, {dtype}, {shape}")# 创建执行上下文
context = engine.create_execution_context()# 设置权重流预算(如果适用)
if hasattr(engine, 'weight_streaming_budget_v2'):engine.weight_streaming_budget_v2 = engine.get_weight_streaming_automatic_budget()
重要注意事项
索引操作:
可通过整数索引获取绑定名称:name = engine[0]
可通过名称获取绑定索引:index = engine[“input_name”]
权重流特性:
TensorRT 10.1+ 使用 _v2 版本的相关属性和方法
权重流可减少内存占用但可能影响性能
内存管理:
使用 device_memory_size_v2 而非旧版获取内存需求
对于权重流场景,内存需求会随预算变化
性能分析:
构建时设置的 profiling_verbosity 决定可获取的信息量



:映射)



)





)

: 一刀斩断视频片头广告)



