用于精确实时滑坡检测的双向LSTM模型:以印度梅加拉亚邦毛永格里姆为例的研究
IEEE Internet of Things Journal(简称 IoT‑J)是一份 IEEE 自 2014 年起双月刊发表的国际顶级学术期刊,专注于物联网各领域的研究。
作者: J. Sharailin Gidon
🧠 研究目标
建立一个基于深度学习的预测模型,用于:
- 精确预测滑坡区域的斜坡位移(slope displacement)、
- 地下水位(WL) 和
- 基质吸力(matric suction, MS),
主要以 降雨、水压、时间等气象/水文变量 作为输入,不依赖传统的土壤物理参数或复杂地质信息。
🔍 方法概述
-
使用 自回归多变量 Bi-LSTM(Bidirectional Long Short-Term Memory)模型,可以:
- 同时处理多个输入变量(multivariate);
- 捕捉时序前后依赖(bidirectional);
- 利用前一步预测值作为下一步的输入(auto-regressive)。
-
模型结构特点:
- 输入层 → 两个 LSTM 隐藏层 → 输出层;
- 激活函数选择上对比了 ReLU 和 tanh;
- 多组 LSTM 单元数量和 dropout 比例组合对性能进行了测试;
- 模型结构如图 5 和图 6 所示,参数配置如表 I。
📊 结果
-
最佳模型具有:
- 最多 LSTM 单元、
- 最大 dropout 比例、
- 使用 tanh 激活函数,
在所有测试中取得最高 R 2 R^2 R2(0.93)和最低 MSE。
-
训练准确率达 95.9%,测试准确率为 93%;
-
模型成功预测了:
- 不同深度(10m、20m、30m)及方向的斜坡位移;
- 三个测量点的基质吸力;
- 地下水位。
🔁 对比分析
-
与传统 LSTM、Bi-LSTM 模型对比:
- 本文提出的模型处理的是多变量输入和输出,而传统模型多用于单变量;
- 能同时捕捉时间(时序)和空间(多传感器)之间的关系;
- 拥有更强的泛化能力和预测精度。
✅ 结论
- 模型对滑坡形变预测高度准确;
- 降雨是滑坡变形最关键的外部因素;
- 提出的 Bi-LSTM 模型为滑坡预警提供了一种高效、经济、无需复杂地质数据的解决方案;
- 可轻松迁移至其他区域,只要有降雨、水位和基质吸力数据;
- 相较以往方法,本研究的模型预测精度高、误差低,适合实际部署用于滑坡预警。
摘要——本文提出了一种用于滑坡检测的双向长短期记忆(LSTM)模型。以往在该领域应用机器学习(ML)已经展示出其整体潜力,这也促使有必要实现一种合适的算法。滑坡是一种自然灾害,会对受影响区域造成严重破坏和干扰。滑坡的早期检测是减少其影响的关键,因此开发准确且高效的模型显得尤为重要。
本研究选取了位于印度梅加拉亚邦毛永格里姆(Mawiongrim)的一个活跃滑坡区域作为研究对象。所提出的模型采用双向LSTM,旨在捕捉从该地区部署的长期实时监测系统中收集的输入数据的时间模式。为评估模型预测的有效性,研究使用包含多种与滑坡相关特征的数据集进行训练,这些特征包括地形、降雨、水文及土壤属性等。
结果表明,所提出的模型相比其他模型在滑坡检测方面具有更高的准确率和更低的误差值。此外,该模型还能提供实时预警系统,使其成为滑坡早期检测的可行工具。研究还重点分析了基质吸力与地下水位的预测模型,这两者对判断边坡稳定性具有关键作用。
关键词:人工智能(AI)、滑坡、长短期记忆网络(LSTM)、实时监测、边坡检测。
一、引言
在一个多雨或持续降雨的地区,如果斜坡本身已经处于不稳定状态,那么该斜坡就更容易发生塌陷。当降雨入渗引起的土壤应力行为变化超过土体的抗剪强度时,斜坡就会发生崩塌。如果不研究滑坡在特定气候事件下的运动模式,就很难对其发生进行准确预测 [1]。仅仅监测斜坡位移是不够的,还需要结合环境和岩土工程方面的其他因素。
基于大量反映斜坡在雨水入渗影响下行为的数据集,可以模拟基于物理和经验的模型,以构建可靠的预警系统 [2]。多个物理因素,如斜坡材料、强度、地下水、降雨入渗和斜坡几何形状都会影响其稳定性。为了理解斜坡可能崩塌的条件,有必要对这些因素进行观测。渗流与变形可以与斜坡稳定性同时进行监测,这有助于在不同条件下评估斜坡行为,并为防护策略的有效性提供数据支持。
实时监测可以对可能的斜坡失稳事件发出预警。各种设备可以用来验证这些特征随时间的变化。例如:
- 使用 irrometer 测量土壤吸力或负孔隙水压力;
- 使用 孔隙水压力计(piezometer) 监测地下水位变化;
- 使用 雨量计(rain gauge) 跟踪降雨量和降雨时长 [3]。
在滑坡监测中常用的工具还包括:倾斜计、全球定位系统(GPS)、全站仪、孔隙水压力计等。过去 50 年里,大量基于人工智能(AI)和机器学习(ML)的预测研究模型被开发出来 [4]。先进研究广泛采用了循环神经网络(RNN)、神经动力学求解器、残差神经网络下的非负潜因子建模、以及多层结构的采样型潜因子模型(MLF)等方法 [5]-[10]。
有研究提出了一种博弈论框架,用以指导 RNN 的设计,用于多个冗余机械臂的分布式协调控制。此外,也有针对含时延问题的冗余机械臂协同控制,提出了一种时延与分布式神经动态方案 [6]。另一研究提出了一种基于交替方向乘子法(ADMM)的对称非负潜因子分析(ASNL)模型,用于准确表达网络对称性,并有效处理大型无向加权网络中的缺失数据 [8]。
AI 模型的应用不仅限于机械臂控制、性能优化、机器翻译等领域,还扩展到了滑坡预测和边坡位移预测。滑坡过程的主要指标是边坡位移,研究和预测滑坡位移对于预判斜坡失稳具有重要意义和实际价值。
本研究所用数据来自于印度梅加拉亚邦地区一个独特的实时监测系统。滑坡预测的研究可以追溯到 1960 年代 [11],而长短期记忆网络(LSTM)则是其中非常相关的模型。LSTM 是一种强大的 RNN 结构,主要为了解决传统 RNN 在学习长期依赖问题时的梯度爆炸/消失问题。该模型能够高效利用本地实时信息来预测区域斜坡的运动情况。
LSTM 后来经过进一步发展,被众多研究者采用和改进 [12], [13]。多项测试表明,这一框架比先进方法表现更为稳健和出色。在机器学习文献中,基于 RNN 的 LSTM 已被证实可用于预测土体移动 [14], [15]。这些循环模型作为前馈神经网络的扩展,具有内部记忆结构。模型当前的输入结果依赖于先前的计算过程,每条数据输入都执行相同的函数运算。
已有研究者设计了单层 LSTM 模型,通过时间序列形式的历史土体移动数据来预测潜在的边坡移动 [15]-[18]。为了预测印度喜马拉雅地区已知滑坡事件中的土体移动,有人提出了一种双向堆叠式(BM)LSTM 集成模型 [19]。在标准计算智能方法无法胜任时,LSTM 网络在时间序列分析中的预测和识别能力已经被证明非常有效 [20]。
近年来也有研究开发出单变量和多变量的深度学习预测模型。文献 [21] 展示了这些模型的性能评估,并讨论了影响其预测能力的因素。尽管已有方法在准确度和均方根误差(RMSE)上表现良好,但仍存在在滑坡预测中误差偏大的问题。
因此,本研究提出了一种误差更低、预测更精准的滑坡/边坡位移预测方法。该方法基于 RNN 架构的 LSTM 网络,专门用于降雨诱发的滑坡预测,选用此模型正是因为它擅长处理长期数据预测。模型中使用的斜坡数据来自于部署在印度梅加拉亚邦毛永格里姆地区的实时监测系统。LSTM 模型被用于研究斜坡位移与降雨模式、基质吸力变化和雨季期间地下水位之间的依赖关系。同时,模型也分析了降雨下基质吸力和地下水位的变化。
本研究提出了一种深度学习模型,用于预测边坡倾斜、基质吸力和地下水位(WL),这些都是判断滑坡可能性的关键因素。此外,与现有研究相比,该模型在误差率方面表现最佳。本研究共开发了 5 个斜坡倾斜模型(INC)、3 个基质吸力模型(MS)以及若干地下水位模型。
II. 背景
总体上,这些研究可以分为基于物理原理的模型和基于数据驱动的模型 [16], [22]。随着深度学习的发展,特别是 LSTM 的出现,使得处理具有长期依赖关系的时间序列数据成为可能,从而有望构建可靠的预测解决方案。由于滑坡位移本质上是典型的时间序列数据,因此时间序列分析方法经常被用于研究与建立预测模型 [15], [23]。
滑坡预测模型所期望的位移值范围(而非单一值)决定了预测结果的准确性 [17], [24], [25]。Xie 等人 [26] 使用 LSTM 模型直接预测滑坡位移,同时考虑了坡度、土地利用因素、滑坡特征剖面和岩体性质等多种因素。通过模型得到的位移信息可以反映滑坡本身随时间的稳定性及其变化状态 [27]。为了验证位移预测的准确性,该研究将模型预测结果与一年期的累计位移实测值进行比较,证明了其有效性 [26]。
此外,研究者还提出结合 LSTM 的变分模态分解(VMD)算法,用于动态建模边坡周期性与随机性位移行为。然而,该算法在性能上受到限制,主要是因为参数设置通常依赖经验判断。
考虑到滑坡位移的非线性动态特性,研究中引入了 双向 LSTM(Bi-LSTM) 模型来探究阶梯状滑坡的位移情况。该方法能够有效捕捉监测数据中过去与未来的成分 [18]。
边坡失稳通常由土壤基质吸力的降低所引起,这种变化会导致土体强度下降。因此,掌握降雨参数及其对土体抗剪强度、土水相互作用、地下水位变化的影响,对于了解滑坡成因是十分有益的 [28]。
在印度,西北部和东北部的喜马拉雅山脉以及半岛地区的西高止山脉,是最容易在降雨季节发生滑坡的地区。而 梅加拉亚邦(Meghalaya) 位于印度东北部,该地由于强降雨频发,滑坡灾害屡见不鲜。
在此背景下,双向 LSTM 网络 可用于序列标注任务,因为它们可以在某一时刻同时访问过去和未来的输入数据。通过这种方式,我们能够有效利用过去(通过前向状态)和未来(通过后向状态)特征来建模一段时间内的动态过程 [29]。
反向传播算法(Backpropagation Through Time, BPTT) 被用于训练双向 LSTM 网络。训练过程中,模型会在展开的网络上执行正向与反向的扫描操作,类似于普通神经网络中的前向传播与反向传播,但在每一个时间步都需要显式地展开隐藏状态。
另外,在处理序列的起始和结束数据点时需要特殊的处理策略。本研究中采用了批处理实现(batch implementation),这使得可以同时处理多条时间序列数据。
III. 研究区域
Mawiong Rim 是印度 梅加拉亚邦(Meghalaya) 的一个偏远地区,位于国家公路 6 号线(NH-6)——古瓦哈提至西隆(Guwahati–Shillong, GS)沿线(见图 1)。该地区以其陡峭的山坡、深谷和脆弱的基岩而闻名,这些地质特征显著增加了滑坡发生的风险。

此外,该地区的降雨量极高,而强降雨已知会进一步破坏山区的稳定性。Mawiong Rim 的基础设施高度暴露于滑坡等自然灾害之中,一旦发生滑坡,将可能对该区域造成严重破坏。
该地区也容易发生突发性的山洪和积水现象,进一步导致边坡失稳甚至滑坡。因此,为了降低滑坡灾害的风险,必须采取合理的土地管理措施,尤其是在季风季节更显重要。
因此,必须实施切实可行的 减灾措施,例如:建立早期预警系统,制定人员转移策略等,以保障该区域居民的生命安全和财产安全。
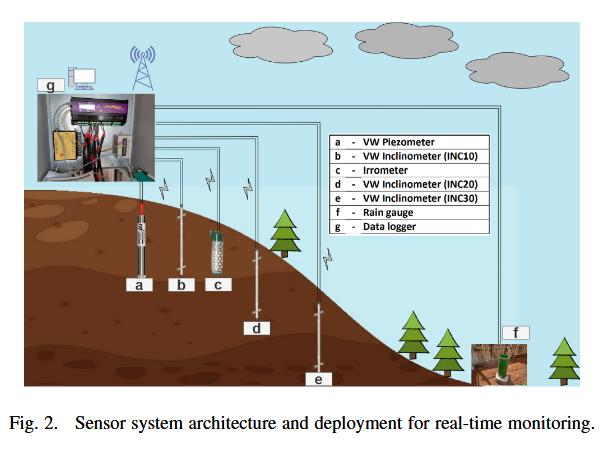
IV. 方法论
A. 实时监测系统
该区域滑坡的主要诱因是持续性的强降雨。本次监测选址位于印度梅加拉亚邦 NH-6(古瓦哈提-西隆)路段的 Mawïong Rim 地区(见图2)。理解降雨引发边坡失稳的机制至关重要,因为降雨渗入坡体会改变土体应力状态,最终削弱其抗剪强度。
影响边坡行为的因素包括:土体的岩土工程性质、降雨量、有无植被、水文参数等。雨季时,边坡周围存在张裂缝,这些裂缝使雨水易于渗入。
为了研究降雨对边坡的影响,系统地安装了一个实时监测系统,监测周期超过一年,覆盖了旱季与雨季的坡体行为。通过持续监测土体水文行为、边坡的岩土特性与当地降雨情况,可以更好地理解边坡对降雨的响应。
在 Mawiong Rim 的目标坡面布设了多个传感器,监测基质吸力、地下水变化、坡面位移以及降雨的影响。2021 年 5 月进行现场开挖并钻孔,以安装振弦(VW)孔压计和振弦倾斜仪,分别用于实时监测地下水位变化和边坡位移。
所安装的 VW 倾斜仪为双向传感器( A + A − A^+A^- A+A− 与 B + B − B^+B^- B+B−),分别记录东南(SE)方向和西南(SW)方向的倾角(见图2)。共安装了三组双向 VW 垂直多点倾斜仪,分别在深度为 10 m、20 m 和 30 m 的钻孔中测量水平位移。
VW 孔压计是一种压力传感器,根据其顶部所感应的压力进行读数。**张力计(Tensiometer)**用于监测基质吸力(即负孔隙水压力)。其测量范围为 50 k g / c m 3 50\ \mathrm{kg/cm^3} 50 kg/cm3,输出单位为 centibar( 10 − 2 10^{-2} 10−2 kPa),量程为 200 centibar。
坡体地下共安装了三个水印传感器(I1、I2、I3)。雨量计用于监测降雨持续时间与强度(见图2)。通过 **数据记录仪(Data Logger)**收集传感器数据,数据容量最大支持 512 MB,同时内置一张宏尺寸 SIM 卡。
数据通过 SIM 卡连接互联网,发送到指定邮箱以供存储和分析(见图2)。
B. 双向 LSTM 模型(Bidirectional LSTM)
双向 LSTM 由两个独立的 LSTM 层组成,一个处理正向序列,另一个处理反向序列。正向 LSTM 从第一个时间步开始,顺序处理输入序列直至末尾(见图3),每个时间步 t t t处的 LSTM 单元根据当前输入与前一个隐藏状态输出新的隐藏状态与输出。
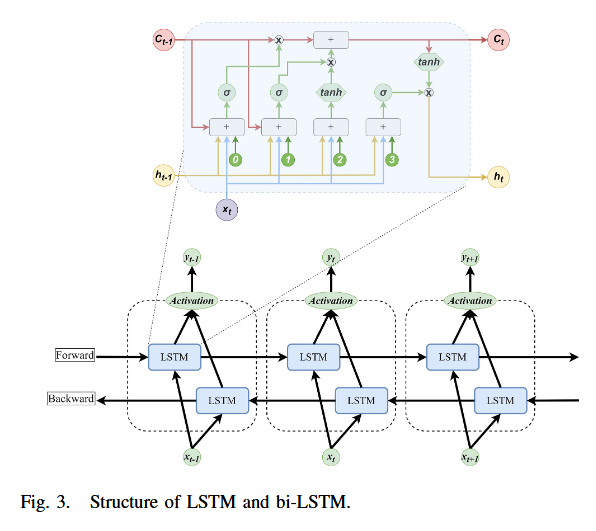
反向 LSTM 从最后一个时间步开始,倒序处理输入,同样计算每个时间步的输出与隐藏状态。两个方向的输出在对应时间步进行拼接,得到包含前向与后向上下文的完整特征表示,便于捕捉时序依赖性。
最终,拼接后的输出将传递至后续层或输出层用于预测。
设输入序列为:
X ~ = ( x 1 , x 2 , … , x T ) \tilde{X} = (x_1, x_2, \ldots, x_T) X~=(x1,x2,…,xT)
标准 RNN 生成的隐藏状态序列与输出序列分别为:
h ~ = ( h 1 , h 2 , … , h T ) , Y ~ = ( y 1 , y 2 , … , y T ) \tilde{h} = (h_1, h_2, \ldots, h_T), \quad \tilde{Y} = (y_1, y_2, \ldots, y_T) h~=(h1,h2,…,hT),Y~=(y1,y2,…,yT)
通过以下迭代公式计算(KaTeX parse error: Undefined control sequence: \[ at position 7: t \in \̲[̲1, T]):
- $ \tilde{h}t = H\left(\tilde{W}{xh}x_t + \tilde{W}{hh}h{t-1} + \tilde{b}_h \right) $ (1)
- $ \tilde{y}t = \tilde{W}{hy}h_t + \tilde{b}_y $ (2)
其中:
- H H H 为激活函数,如 Sigmoid、Tanh 或 ReLU;
- W ~ \tilde{W} W~ 表示权重矩阵, b ~ \tilde{b} b~ 表示偏置向量。
LSTM 架构通过 记忆单元(memory cells) 有效保留长程信息。在 LSTM 中, H H H 的计算方式如下:
- i _ t = tanh ( W ~ ∗ x f x _ t + W ~ ∗ h f h _ t − W ~ _ c f c _ t − b ~ _ i ) i\_t = \tanh\left( \tilde{W}*{xf} x\_t + \tilde{W}*{hf} h\_t - \tilde{W}\_{cf} c\_t - \tilde{b}\_i \right) i_t=tanh(W~∗xfx_t+W~∗hfh_t−W~_cfc_t−b~_i) (3)
- f _ t = tanh ( W ~ ∗ x f x _ t + W ~ ∗ h f h _ t − 1 + W ~ ∗ c f c ∗ t − 1 + b ~ _ f ) f\_t = \tanh\left( \tilde{W}*{xf} x\_t + \tilde{W}*{hf} h\_{t-1} + \tilde{W}*{cf} c*{t-1} + \tilde{b}\_f \right) f_t=tanh(W~∗xfx_t+W~∗hfh_t−1+W~∗cfc∗t−1+b~_f) (4)
- c _ t = f _ t ⋅ c _ t − 1 + tanh ( W ~ ∗ x c x _ t + W ~ ∗ h c h _ t − 1 + b ~ _ c ) c\_t = f\_t \cdot c\_{t-1} + \tanh\left( \tilde{W}*{xc} x\_t + \tilde{W}*{hc} h\_{t-1} + \tilde{b}\_c \right) c_t=f_t⋅c_t−1+tanh(W~∗xcx_t+W~∗hch_t−1+b~_c) (5)
- o _ t = tanh ( W ~ ∗ x o x _ t + W ~ ∗ h o h _ t − 1 + W ~ _ c o c _ t + b ~ _ o ) o\_t = \tanh\left( \tilde{W}*{xo} x\_t + \tilde{W}*{ho} h\_{t-1} + \tilde{W}\_{co} c\_t + \tilde{b}\_o \right) o_t=tanh(W~∗xox_t+W~∗hoh_t−1+W~_coc_t+b~_o) (6)
- h _ t = o _ t ⋅ tanh ( c _ t ) h\_t = o\_t \cdot \tanh(c\_t) h_t=o_t⋅tanh(c_t) (7)
在 双向神经网络 中,除正向隐藏序列 h ~ + \tilde{h}^+ h~+ 外,还需计算反向隐藏序列 h ~ − \tilde{h}^- h~−,以及最终输出序列 Y ~ \tilde{Y} Y~,计算过程为:
- $ \tilde{h}t^+ = \tilde{H}(\tilde{W}{xh^+} x_t + \tilde{W}{hh^+} h{t-1}^+ + \tilde{b}_{h^+})$ (8)
- $ \tilde{h}t^- = \tilde{H}(\tilde{W}{xh^-} x_t + \tilde{W}{hh^-} h{t+1}^- + \tilde{b}_{h^-})$ (9)
- $ \tilde{y}t = 2 \cdot \tilde{W}{hy^+} h_t^+ - \tilde{W}_{hy^-} h_t^- + \tilde{b}_y$ (10)
通过将两个方向的输出拼接,可获得双向上下文表示(见图4),使模型具备从两个方向学习长距离依赖的能力。
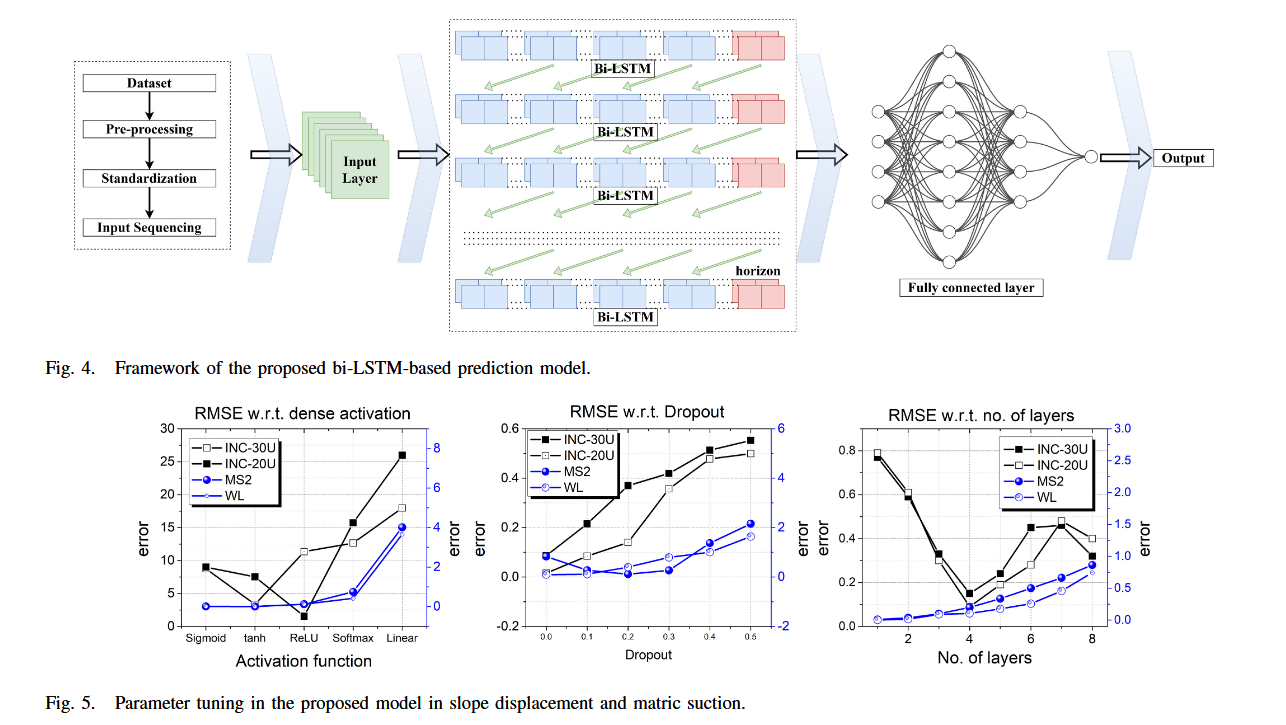
为实现滑坡预测,构建了以下 Bi-LSTM 模型:
-
坡体倾角预测模型(SE/SW方向):以降雨模式、基质吸力、地下水位变化与时间为输入;
-
坡面位移预测模型(6个模型):
- INC-30U、INC-30D
- INC-20U、INC-20D
- INC-10U、INC-10D
-
基质吸力预测模型(3个模型:MS1, MS2, MS3):以降雨模式、地下水位变化与时间为输入;
-
地下水位变化预测模型(1个模型:WL):以降雨模式与时间为输入。
模型使用的数据集时间范围为:2022年8月21日 至 2023年1月16日。
在建模前,对数据进行了归一化处理,并将数据按 75% 训练集与 25% 测试集的比例划分,使用 sklearn 中的 train_test_split 函数随机划分数据集。
以下是你提供的**第五章“结果与讨论”和第六章“结论”**的中文翻译,所有公式均已使用 KaTeX 格式,关键变量和字母均已用美元符号 $ 包裹:
V. 结果与讨论
为了评估模型误差,采用均方误差(MSE),即实际值与预测值之间差值的平方的平均值。MSE 越大,表示误差越高。
一个衡量因变量中有多少变异可以被自变量解释的指标是决定系数 R 2 R^2 R2,它用于评估模型的拟合优度。因此, R 2 R^2 R2 越高,表示模型拟合越好;反之则越差。
斜坡位移是通过安装在地下 10 米、20 米和 30 米处的测斜仪获得的。每个测斜仪提供两个方向(东南 SE 和西南 SW)的数据,因此总共获得六组位移数据。在读取数据集后,仅筛选出所需的输入变量和目标变量。
用于预测坡面位移(INC)的输入变量包括降雨、地下水压力、水位 WL、时间和基质吸力 MS。预测 MS 的输入变量为降雨和时间。
A. 预测模型
模型中用于预测土壤运动的各个参数如表 I 所示。定义隐藏状态或输出维度的单元数和 LSTM 层的参数数量分别为:
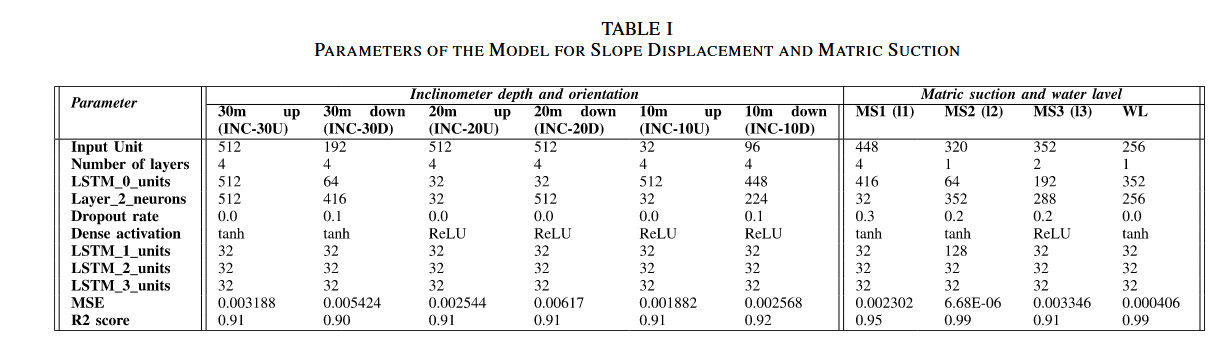
- 512 512 512:INC-30U、INC-20U、INC-20D;
- 192 192 192:INC-30D;
- 32 32 32:INC-10U;
- 96 96 96:INC-10D。
所有模型均包含四层结构:一个输入层、两个隐藏层和一个输出层。
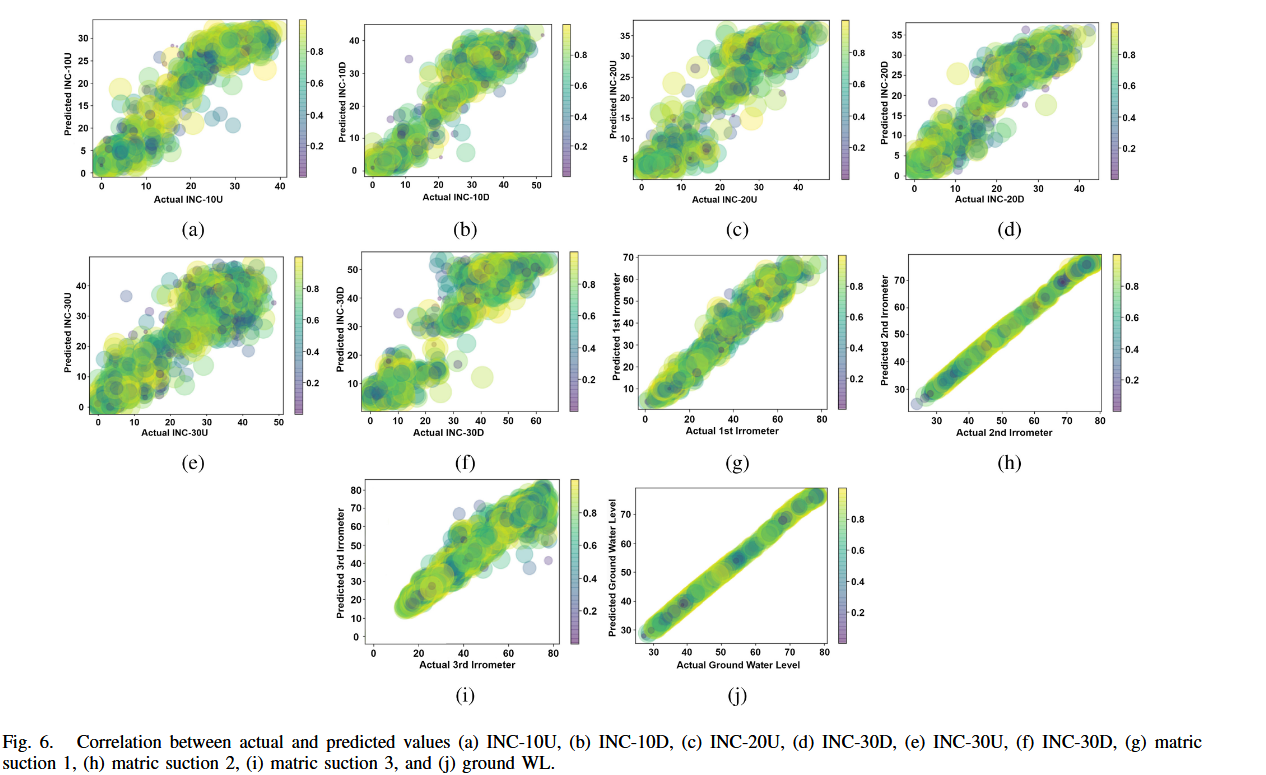
图 6 比较了多个基于 LSTM 层的深度学习模型训练设置,包括:
- 层数、
- LSTM 单元数、
- 每层神经元数量、
- Dropout 比例、
- 激活函数、
- 训练时的批次大小。
使用 MSE 和 R 2 R^2 R2 分数表示训练结果。研究结果表明,具有最多 LSTM 单元、最多层数和最高 Dropout 率的模型具有最低的 MSE 和最高的 R 2 R^2 R2。
从图 5 可见,最优模型为具有最多层数、LSTM 单元和 Dropout 率的结构。此外,激活函数的选择也影响结果,tanh 激活函数的表现优于 ReLU 激活函数。由于所有模型在 epoch 和 batch size 上参数相近,因此这两个参数对结果影响不大。
神经网络中的激活函数将节点的总加权输入转换为该节点的激活或输出值。**ReLU(修正线性单元)**是一种分段线性变换,输入为负时输出为 0,正数时输出为其本身。ReLU 由于易于训练和通常表现更好,已经成为多种神经网络的默认激活函数。
梯度消失现象限制了 sigmoid 和 tanh 函数在多层网络中的应用。ReLU 修复了这个问题,使得模型可以更快地学习并表现更好。因此,它在多层感知机和卷积神经网络中是默认选项。
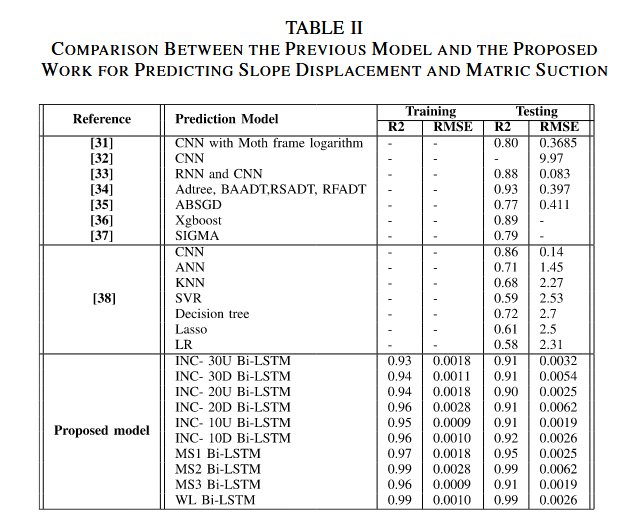
该模型在训练数据上的整体准确率为 95.9%,在测试数据上的准确率为 93%(见表 II)。模型准确预测了:
- 10、20、30 米深度处斜坡上/下方向的位移(图 6(a)-(f));
- 第 1、2、3 个吸力传感器的读数(图 6(g)-(i));
- 水位 WL(图 6(j))。
模型的结果表明,它具有高度准确性,能够从数据中学习并进行精确预测。它可以在多种地下水位、基质吸力和降雨情景下准确预测滑坡倾角。
B. 对比分析
表 III 中的指标对比了本研究提出的模型与先前在相同数据集上实现的 LSTM 与 Bi-LSTM 模型。
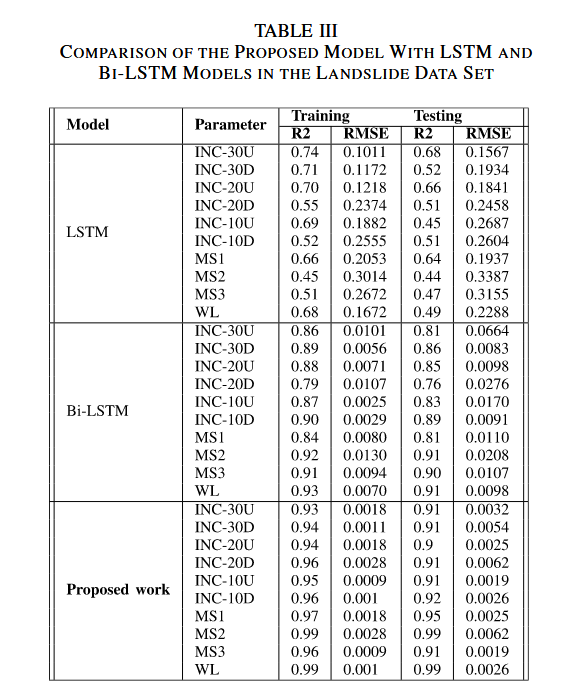
该模型采用自回归结构(auto-regressive),将前一次的预测结果作为输入之一用于下一步的预测,从而引入预测反馈。
与通常用于单变量序列的 LSTM 和 Bi-LSTM 不同,自回归多变量 Bi-LSTM 架构特别适用于处理多变量数据,即每个时间步可以包含多个特征或变量,从而可以同时捕捉多个因素之间的关系。
该模型可以捕捉数据中的空间和时间依赖性。提出的方法利用双向上下文来捕捉时间依赖关系,同时通过多变量特征来捕捉空间关系。
这种方法被设计为在每个时间步输出多个预测变量,因而非常适合多变量时间序列数据的预测任务。
综上,自回归多变量 Bi-LSTM 是一种集成了双向建模、多变量处理和自回归反馈机制的复杂模型,可有效提高多变量时间序列预测的精度。
VI. 结论
本研究利用深度学习,专注于主动预测由局部降雨引起的周期性位移。主要结论如下:
- 预测值与实测位移值高度一致。
- 结果表明,降雨是 Mawiong Rim 滑坡中最主要的动态因素。
- 双向 LSTM 模型为地面滑坡预警系统提供了潜力巨大的工具,可用于预测斜坡位移、基质吸力与地下水位(使用 INC、MS 与 WL 模型)。
- 提出了一种经济高效的工具,用于在局部尺度上预测土壤边坡不稳定性。模型可预测坡面位移、基质吸力与地下水位,而无需土壤参数或几何信息,因此可适用于其他区域,只需已知初始水位、基质吸力和降雨模式。
- 以往研究虽然具有较高精度,但往往也存在较高的 RMSE 值,说明预测模型在滑坡预测方面可能存在较大误差。而本研究模型在预测滑坡或坡面位移时,具有更高的准确率和更小的误差。


强化学习专题(1))



 的变化导致的影响(那部分被分给了链式项))

 类,加深对拷贝构造函数的理解)
)



语音/字幕标注 通过via(via_subtitle_annotator))





--linux内核之V4L2框架及ov9281驱动分析(中))