作者:IvanCodes
日期:2025年6月7日
专栏:Sqoop教程
Apache Sqoop 不仅擅长从关系型数据库 (RDBMS) 向 Hadoop (HDFS, Hive, HBase) 导入数据,同样也强大地支持反向操作——将存储在 Hadoop 中的数据导出 (Export) 回关系型数据库。这在数据分析结果回写、数据仓库ETL、业务系统数据填充等场景中非常有用。
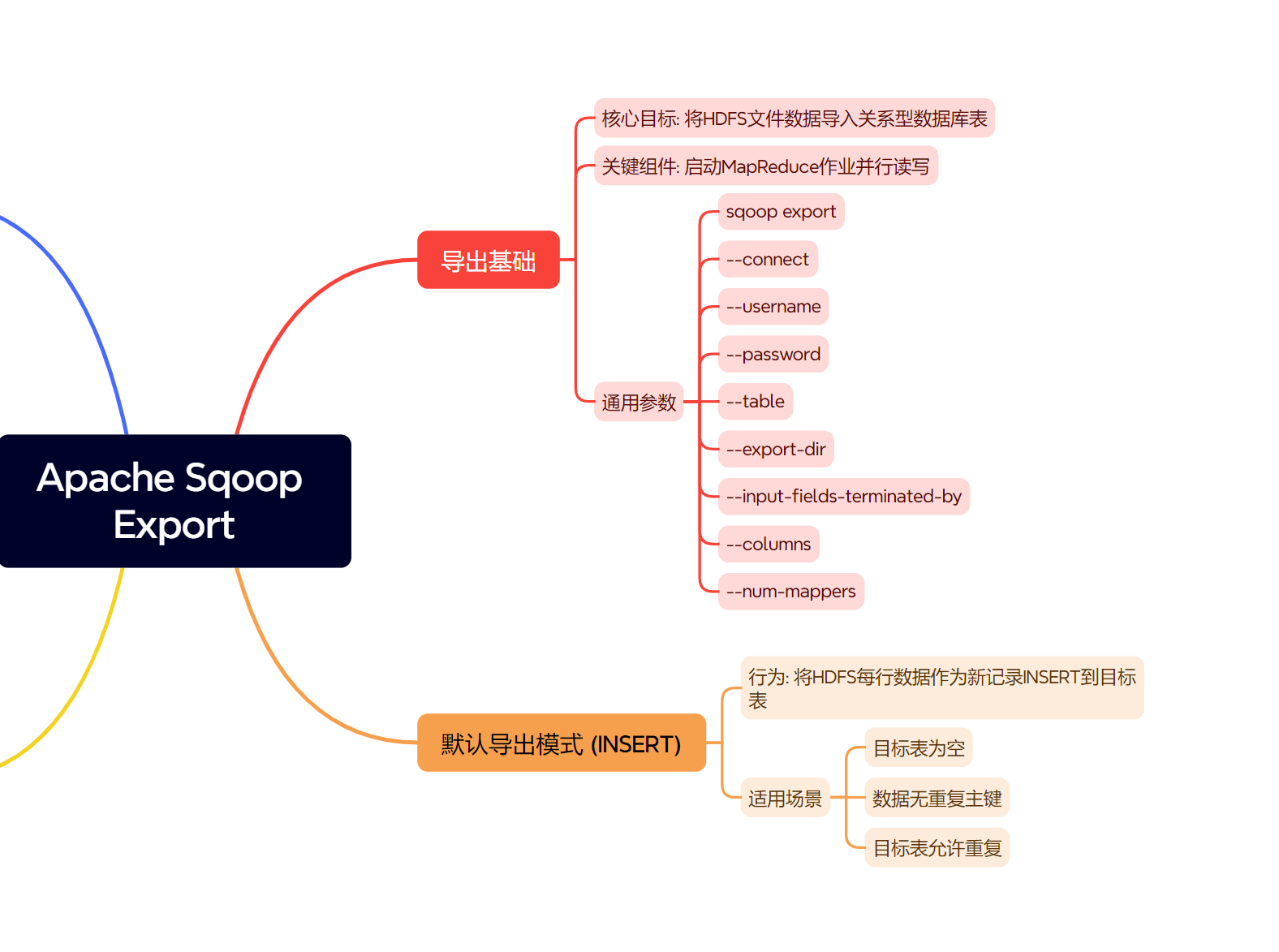
一、Sqoop 导出基础
核心目标:将HDFS上的文件数据 (通常是文本文件,如CSV、TSV) 解析并插入或更新到目标RDBMS的表中。
关键组件:Sqoop Export 会启动MapReduce作业 (或在Sqoop 2中可能是其他执行引擎) 来并行读取HDFS上的数据,并将其转换为SQL语句 (INSERT或UPDATE) 在目标数据库上执行。
通用导出参数:
sqoop export: Sqoop导出的主命令。--connect <jdbc-uri>: 目标RDBMS的JDBC连接字符串。--username <user>: 数据库用户名。--password <pass>: 数据库密码 (生产环境建议使用密码文件或credential provider)。--table <table-name>: 目标RDBMS中的表名。--export-dir <hdfs-path>: 包含源数据的HDFS目录路径。目录下的文件应为文本格式,且字段与目标表列对应。--input-fields-terminated-by <char>: HDFS文件中字段间的分隔符,默认为逗号,。--input-lines-terminated-by <char>: HDFS文件中行间的分隔符,默认为换行符\n。--columns <col1,col2,...>: (可选) 指定HDFS文件中哪些列以及它们的顺序要导出到目标表的对应列。如果不指定,Sqoop会假设HDFS文件的列顺序和数量与目标表完全匹配。--m <num-mappers>或--num-mappers <num-mappers>: 指定并行导出的Map任务数量。
二、默认导出模式 (INSERT 模式)
行为:
默认情况下,Sqoop Export 会将HDFS中的每一行数据都尝试作为一条新的记录 INSERT 到目标数据库表中。
如果目标表有主键或唯一约束,并且HDFS中的数据导致了重复键,则该条记录的INSERT操作会失败 (具体行为取决于数据库,可能抛出错误并中止该Map任务的部分批次,或整个作业失败)。
适用场景:
- 目标表是空的。
- 确定HDFS中的数据在目标表中不存在重复主键。
- 目标表允许重复记录 (如果没有主键或唯一约束)。
一般结构:
sqoop export \
--connect jdbc:mysql://db_host:3306/db_name \
--username db_user --password db_password \
--table target_table \
--export-dir /user/hadoop/hdfs_data_dir \
[--input-fields-terminated-by '\t'] \
[--columns "col_a,col_b,col_c"] \
--m 4
代码案例:
假设HDFS目录 /user/data/new_employees 下有如下CSV文件内容 (假设字段分隔符为 ,):
part-m-00000:
101,Alice,HR,60000
102,Bob,Engineering,75000
目标MySQL表 employees_target (emp_id INT PRIMARY KEY, name VARCHAR(50), department VARCHAR(50), salary INT)。
导出命令:
sqoop export \
--connect jdbc:mysql://mysql.example.com:3306/companydb \
--username export_user --password 'p@$$wOrd' \
--table employees_target \
--export-dir /user/data/new_employees \
--input-fields-terminated-by ',' \
--m 1
这会将HDFS中的两条记录作为新行插入到 employees_target 表中。
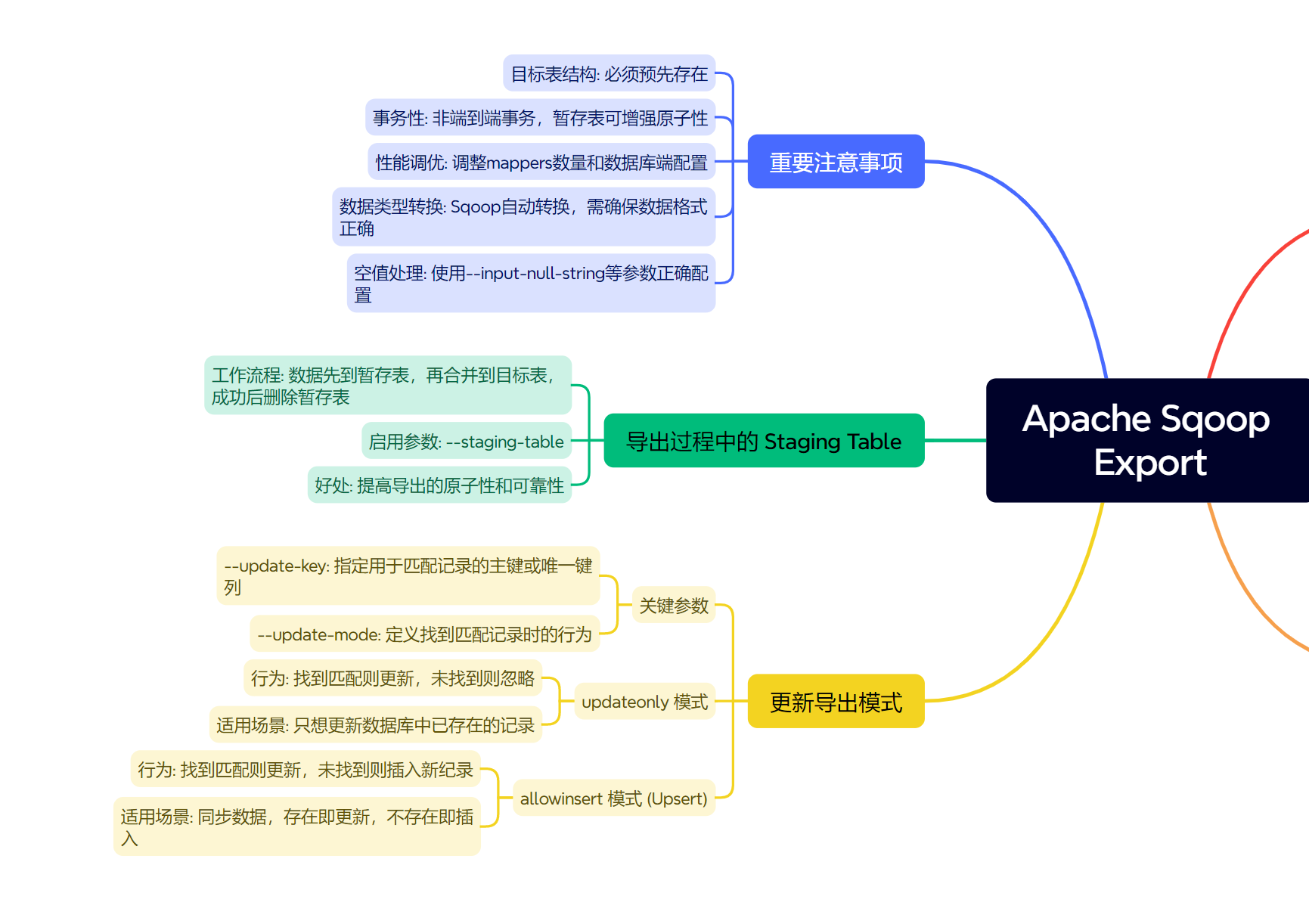
三、更新导出模式 (--update-key 与 --update-mode)
当HDFS中的数据可能包含目标数据库表中已存在的记录,并且你希望更新这些记录而不是简单插入 (或因主键冲突而失败) 时,需要使用更新导出模式。
关键参数:
--update-key <column-name(s)>: 必需。指定一个或多个用逗号分隔的列名,这些列构成了目标表的主键或唯一键,Sqoop将使用这些列来匹配HDFS记录与数据库表中的现有行。--update-mode <mode>: 必需。定义当找到匹配记录时的行为。主要有两种模式:updateonly(默认,如果指定了--update-key但未指定--update-mode)allowinsert
3.1 更新导出:updateonly 模式
行为:
- Sqoop会读取HDFS中的每一行数据。
- 对于每一行,它会使用
--update-key指定的列的值去目标数据库表中查找匹配的记录。- 如果找到匹配记录:则更新 (UPDATE) 该数据库记录,使用HDFS行中其他列的值。
- 如果未找到匹配记录:则忽略该HDFS行,不会进行插入操作。
适用场景:
- 你只想更新数据库中已存在的记录,不希望HDFS中额外的数据被插入到数据库中。
一般结构:
sqoop export \
--connect <jdbc-uri> \
--username <user> --password <pass> \
--table <table-name> \
--export-dir <hdfs-path> \
--update-key <primary-key-column> \
--update-mode updateonly \
[--columns "col_to_update1,col_to_update2,primary_key_column"] \
--m <num-mappers>
重要:如果使用了 --columns,确保 --update-key 指定的列也包含在 --columns 列表中,并且顺序正确,以便Sqoop能正确解析出用于匹配的键值。
代码案例:
HDFS目录 /user/data/employee_updates 内容 (字段分隔符 ,,顺序: emp_id, new_salary, new_department):
part-m-00000:
101,65000,Sales
103,80000,Engineering
目标MySQL表 employees_target 中已有记录:
(101, 'Alice', 'HR', 60000)
(102, 'Bob', 'Engineering', 75000)
导出命令 (updateonly):
sqoop export \
--connect jdbc:mysql://mysql.example.com:3306/companydb \
--username export_user --password 'p@$$wOrd' \
--table employees_target \
--export-dir /user/data/employee_updates \
--update-key emp_id \
--update-mode updateonly \
--columns "emp_id,salary,department" \
--input-fields-terminated-by ',' \
--m 1
结果:
- ID为
101的员工 Alice 的薪水更新为65000,部门更新为Sales。 - ID为
103的记录在数据库中不存在,所以会被忽略。 - ID为
102的员工 Bob 的信息保持不变。
3.2 更新导出:allowinsert 模式
行为:
- Sqoop会读取HDFS中的每一行数据。
- 对于每一行,它会使用
--update-key指定的列的值去目标数据库表中查找匹配的记录。- 如果找到匹配记录:则更新 (UPDATE) 该数据库记录。
- 如果未找到匹配记录:则插入 (INSERT) 该HDFS行作为一条新记录到数据库表中。
这种行为有时被称为 “Upsert” (Update or Insert)。
适用场景:
- 你需要同步HDFS中的数据到数据库,如果记录已存在则更新,如果不存在则插入。
一般结构:
sqoop export \
--connect <jdbc-uri> \
--username <user> --password <pass> \
--table <table-name> \
--export-dir <hdfs-path> \
--update-key <primary-key-column> \
--update-mode allowinsert \
[--columns "col1,col2,primary_key_column,col3"] \
--m <num-mappers>
代码案例:
使用与 updateonly 案例相同的HDFS数据和初始数据库状态。
导出命令 (allowinsert):
sqoop export \
--connect jdbc:mysql://mysql.example.com:3306/companydb \
--username export_user --password 'p@$$wOrd' \
--table employees_target \
--export-dir /user/data/employee_updates \
--update-key emp_id \
--update-mode allowinsert \
--columns "emp_id,salary,department,name" \
--input-fields-terminated-by ',' \
--m 1
注意:为了演示插入,假设HDFS数据中包含 name 列,并且目标表 employees_target 有 name 列。如果HDFS数据中没有 name,而表定义中有,则插入时该列可能为 NULL 或默认值 (取决于表定义)。为简化,我们假设HDFS数据是 emp_id,salary,department,name 顺序。
HDFS /user/data/employee_updates 内容 (顺序: emp_id, salary, department, name):
part-m-00000:
101,65000,Sales,Alice_Updated
103,80000,Engineering,David_New
结果:
- ID为
101的员工 Alice 的薪水更新为65000,部门更新为Sales,名字更新为Alice_Updated。 - ID为
103的记录在数据库中不存在,所以会作为新记录插入 (David_New, Engineering, 80000)。 - ID为
102的员工 Bob 的信息保持不变。
四、导出过程中的 Staging Table
为了提高导出的原子性和可靠性 (尤其是在更新模式下),Sqoop 可以使用一个临时的暂存表 (staging table)。
- 工作流程:
- Sqoop 首先将HDFS数据批量插入到一个在目标数据库中自动创建的临时暂存表。
- 然后,Sqoop 执行一条 (或多条,取决于数据库方言) SQL语句,将暂存表中的数据与最终目标表进行合并或更新 (基于
--update-key和--update-mode)。 - 成功后,删除暂存表。
- 启用暂存表:通过
--staging-table <staging_table_name>参数指定暂存表名。如果不指定,Sqoop 可能不会使用暂存表 (取决于具体情况和数据库),或者自动生成一个临时表名。 - 好处:如果在第二步合并/更新时发生错误,最终目标表的数据不会被部分修改,保持了一致性。
代码案例 (使用暂存表):
sqoop export \
--connect jdbc:mysql://mysql.example.com:3306/companydb \
--username export_user --password 'p@$$wOrd' \
--table employees_target \
--export-dir /user/data/employee_updates \
--update-key emp_id \
--update-mode allowinsert \
--columns "emp_id,salary,department,name" \
--input-fields-terminated-by ',' \
--staging-table employees_staging_temp \
--clear-staging-table \
--m 1
--clear-staging-table: 确保每次运行前如果暂存表已存在则清空它。
五、重要注意事项
- 目标表结构:目标数据库表必须预先存在,并且其列类型应与HDFS数据能够兼容转换。
- 事务性:Sqoop Export 本身不提供跨多个Map任务或整个作业的端到端事务。每个Map任务会独立地向数据库提交批次。使用暂存表可以增强单个作业运行内的原子性。
- 性能调优:
--batch: (已废弃,但早期版本有) 控制Sqoop批量执行SQL语句。--num-mappers: 并行度。需要平衡Hadoop集群资源和数据库负载能力。- 数据库端的索引、表锁定、事务日志等都会影响导出性能。
- 数据类型转换:Sqoop会尝试进行HDFS文本数据到目标数据库列类型的自动转换。确保数据格式正确,否则可能导致错误。可使用
--map-column-java或--map-column-hive(当从Hive导出时) 指定特定列的Java或Hive类型。 - 空值处理:HDFS中的空值表示 (如
\N) 需要与Sqoop的--input-null-string和--input-null-non-string参数正确配置,以便正确地在数据库中插入NULL。
总结: Sqoop Export 提供了多种模式将Hadoop中的数据回写到关系型数据库。理解默认的插入模式以及基于 --update-key 的 updateonly 和 allowinsert 模式,并结合暂存表的使用,可以灵活高效地完成各种数据同步需求。
练习题 (共5道)
背景:
-
HDFS目录
/user/data/product_feed包含产品信息,CSV格式,字段分隔符为逗号 (,)。文件内容示例:
part-00000:P101,LaptopX,1200.00,Electronics P102,DeskLamp,25.50,HomeGoods P103,CoffeeMug,10.75,Kitchenware字段顺序:product_sku, product_name, price, category
-
MySQL数据库
inventory_db中有一个表products_live:
CREATE TABLE products_live (sku VARCHAR(50) PRIMARY KEY,name VARCHAR(100),current_price DECIMAL(10,2),category_name VARCHAR(50), stock_level INT DEFAULT 0 -- 假设此列不由Sqoop直接更新);
题目:
- 首次全量导出:假设
products_live表是空的。写一个Sqoop命令,将/user/data/product_feed的所有数据导出到products_live表。明确指定HDFS数据的列名和顺序 (product_sku,product_name,price,category) 对应到目标表的sku,name,current_price,category_name。 - 仅更新现有产品价格:HDFS目录
/user/data/price_updates包含需要更新价格的产品信息,格式为sku,new_price。写一个Sqoop命令,使用updateonly模式,根据sku更新products_live表中的current_price。 - 更新或插入产品信息:HDFS目录
/user/data/daily_product_sync包含每日的产品信息(可能有新产品,也可能有现有产品的信息变更),格式为sku,name,price,category。写一个Sqoop命令,使用allowinsert模式,根据sku更新或插入记录到products_live表。 - 使用暂存表导出:在第3题的基础上,修改命令,使其在导出时使用一个名为
products_sync_stage的暂存表,并在操作开始前清理该暂存表。 - 思考题: 如果在执行
updateonly或allowinsert模式的导出时,HDFS源数据中--update-key指定的列的值在目标数据库表中找不到匹配,并且你没有使用--update-mode allowinsert(即是updateonly模式或默认行为),Sqoop会如何处理这条HDFS记录?
答案:
- 首次全量导出:
sqoop export \
--connect jdbc:mysql://your_mysql_host:3306/inventory_db \
--username your_user --password your_password \
--table products_live \
--export-dir /user/data/product_feed \
--input-fields-terminated-by ',' \
--columns "sku=product_sku,name=product_name,current_price=price,category_name=category" \
--m 1
(注意 --columns 的用法,这里使用了 target_col=source_col 的格式,更准确的应该是直接列出HDFS中的列名,Sqoop会按顺序映射。如果HDFS列名与表列名不同且顺序也可能不同,则需要预处理HDFS数据或使用更复杂的映射,但Sqoop --columns 主要用于选择和排序HDFS列。为了简单起见,通常做法是保证HDFS文件中的列顺序和名称能直接对应目标表,或仅通过--columns选择子集和重排序。)
更标准的做法是,如果HDFS文件列名和顺序与表列名和顺序一致(或你能通过--columns使其一致):
sqoop export \
--connect jdbc:mysql://your_mysql_host:3306/inventory_db \
--username your_user --password your_password \
--table products_live \
--export-dir /user/data/product_feed \
--input-fields-terminated-by ',' \
--columns "product_sku,product_name,price,category" \
--map-column-java product_sku=String,product_name=String,price=java.math.BigDecimal,category=String \
--m 1
(这里假设Sqoop能自动按顺序将HDFS的 product_sku 映射到表的 sku,product_name到name等。如果表列名和HDFS源数据列名不一致,Sqoop Export 没有直接的 target_col=source_col 语法,通常需要在HDFS端准备好与目标表列序一致的数据,或使用 --call 调用存储过程进行更复杂的映射。)
为了简化,最常见的做法是确保HDFS文件列顺序与目标表列顺序一致,然后Sqoop会自动映射。如果只需导出部分列,则用 --columns 指定HDFS中要导出的列名。
让我们假设HDFS文件列序与目标表列序一致,且列名在HDFS中就是 sku,name,current_price,category_name:
sqoop export \
--connect jdbc:mysql://your_mysql_host:3306/inventory_db \
--username your_user --password your_password \
--table products_live \
--export-dir /user/data/product_feed \
--input-fields-terminated-by ',' \
--m 1
- 仅更新现有产品价格 (
updateonly):
(假设/user/data/price_updates文件中列顺序是sku,current_price)
sqoop export \
--connect jdbc:mysql://your_mysql_host:3306/inventory_db \
--username your_user --password your_password \
--table products_live \
--export-dir /user/data/price_updates \
--update-key sku \
--update-mode updateonly \
--columns "sku,current_price" \
--input-fields-terminated-by ',' \
--m 1
- 更新或插入产品信息 (
allowinsert):
(假设/user/data/daily_product_sync文件中列顺序是sku,name,current_price,category_name)
sqoop export \
--connect jdbc:mysql://your_mysql_host:3306/inventory_db \
--username your_user --password your_password \
--table products_live \
--export-dir /user/data/daily_product_sync \
--update-key sku \
--update-mode allowinsert \
--columns "sku,name,current_price,category_name" \
--input-fields-terminated-by ',' \
--m 1
- 使用暂存表导出 (
allowinsert):
sqoop export \
--connect jdbc:mysql://your_mysql_host:3306/inventory_db \
--username your_user --password your_password \
--table products_live \
--export-dir /user/data/daily_product_sync \
--update-key sku \
--update-mode allowinsert \
--columns "sku,name,current_price,category_name" \
--input-fields-terminated-by ',' \
--staging-table products_sync_stage \
--clear-staging-table \
--m 1
- 思考题答案:
如果在执行updateonly模式的导出时 (或者指定了--update-key但未明确指定--update-mode,此时默认为updateonly),HDFS源数据中--update-key指定的列的值在目标数据库表中找不到匹配的记录,Sqoop会简单地忽略这条HDFS记录。它不会尝试插入这条记录,也不会报错 (除非有其他问题导致整个批次失败)。这条记录相当于被丢弃了,不会影响目标数据库。







)





)





