本文讨论了达梦数据实时同步软件DMHS的相关内容,包括概念总结、环境模拟及部署实现从达梦数据库到Kafka队列的同步复制。关键要点包括:
1.DMHS系统概述:
达梦公司推出的异构环境高性能数据库实时同步系统,可应用于应急、容灾等多领域,能避免传统备份问题,降低性能影响,解决主备系统局限。
2.系统组件与功能:
由源端和目标端数据库及服务组成,源端含装载、日志捕获分析等模块,目标端含执行和管理服务模块,支持秒级同步、主备同步及数据一致性。
3.环境模拟:
在[192.168.58.3](192.168.58.3)机器创建达梦数据库环境及数据,在[192.168.58.5](192.168.58.5)机器安装单机Kafka并测试。
4.部署同步:
源端检查并开启归档和逻辑日志,两端安装DMHS服务,配置dmhs.hs等文件,进行同步测试,验证数据能否从源端同步到Kafka队列。
一、概念总结
达梦数据实时同步软件 DMHS 是达梦公司推出的新一代支持异构环境的高性能、高可靠和高可扩展的数据库实时同步系统。
DMHS 的基础实现原理如下图所示:
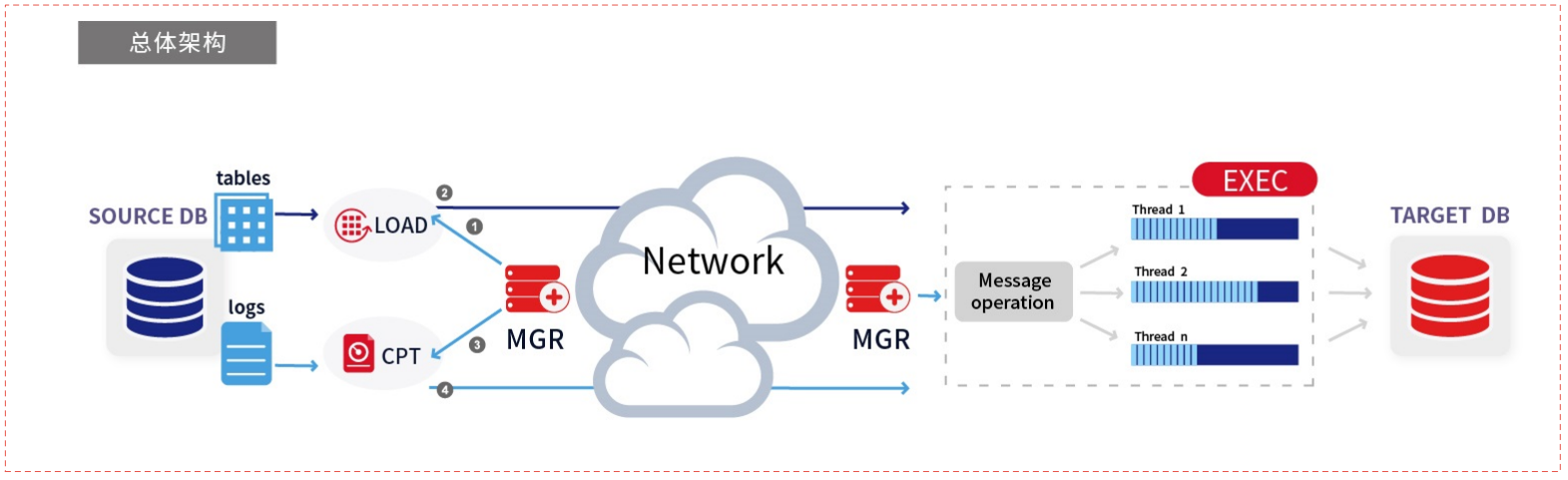
1、这是一个描述数据从源数据库(SOURCE DB)迁移到目标数据库(TARGET DB)的过程。以下是详细解析:
1.1、源端数据库(SOURCE DB):
-
- 包含两个主要部分:
tables和logs。 tables表示数据库中的表结构和数据。logs表示数据库的操作日志。
- 包含两个主要部分:
1.2、加载(LOAD):
-
- 步骤①:源数据库的表数据被加载到一个临时存储区域或缓冲区中,准备进行传输。
1.3、变更数据捕获(CPT):
-
- 步骤③:源数据库的日志信息通过变更数据捕获(CPT)处理,提取出需要同步的数据变更信息。
1.4、管理器(MGR):
-
- 步骤②和步骤④:管理和协调数据的传输过程。它接收来自LOAD和CPT的数据,并通过网络发送给目标端的管理器。
1.5、网络传输:
-
- 数据通过网络从源端的管理器传输到目标端的管理器。
1.6、消息操作(Message operation):
-
- 目标端接收到数据后,进行消息操作,将数据分配给多个线程(Thread 1, Thread 2, ..., Thread n)进行并行处理。
1.7、执行(EXEC):
-
- 各个线程处理完数据后,将结果写入目标数据库(TARGET DB)。
整个流程是一个典型的数据库迁移或同步过程,涉及数据加载、变更数据捕获、网络传输、多线程处理和最终写入目标数据库等步骤。
DMHS 的组成原理框图中包含源端数据库、目标端数据库、源端 DMHS 服务以及目标端 DMHS 服务,
源端 DMHS 服务主要由装载模块(LOAD)、日志捕获分析模块(CPT)以及管理服务模块(MGR)组成;
目标端 DMHS 服务则由执行模块(EXEC)和管理服务模块 (MGR)组成。
在源端,DMHS 的 CPT 模块采用优化的日志扫描算法实现增量日志数据的快速捕获分析,并将分析完成后的日志数据转换为内部的消息格式,然后通过网络将消息发送至目标端DMHS 服务;
在目标端, DMHS 服务接收到源端的日志消息后,对消息进行处理,通过多线程并行执行的方式将同步数据应用至目标端数据库,实现数据实时同步。
2、系统概述与组件描述
1. 系统概述与组件
- DMHS 是高性能、高可靠性的数据库实时同步系统。
- 系统组件包括:
-
- MGR(管理模块):启动框架,负责加载和启动其他模块。
- CPT(捕获模块):捕获源数据库的增量日志。
- LOAD(装载模块):负责数据的初始装载和离线字典管理。
- NET(传输模块):负责数据传输,包括发送和接收子模块。
- EXEC(执行模块):在目标端执行数据入库。
2. 关键概念
- 同步:DMHS 支持秒级实时数据同步。
- 主备同步:支持双活数据库,实现业务连续性。
- 数据一致性:确保事务级的数据完整性和一致性。
3. 配置与管理
- 配置文件使用 XML 格式,详细定义了各模块的参数。
- MGR 模块配置包括站点号、管理端口号等。
- CPT 模块配置涉及数据库连接信息、日志文件清理策略等。
4. 日志捕获与分析
- CPT 模块使用优化算法快速捕获和分析增量日志。
- 支持基于触发器和数据库日志的 DDL 操作捕获。
5. 数据装载
- 初始装载确保源端和目标端数据库数据一致性。
- 支持直接数据装载和备份文件装载两种方式。
6. 数据传输
- NET 模块负责数据的传输,支持 TCP/IP 网络传输和文件传输。
- 可以配置数据过滤和映射,以适应不同的同步需求。
7. 数据执行
- EXEC 模块负责在目标端执行数据入库。
- 支持多线程并行执行,提高同步效率。
8. 高级功能
- CVT 模块:提供数据清洗和转换功能。
- 复杂同步场景:支持双向同步、级联同步、环状同步等。
- ETL 支持:与达梦 ETL 工具集成,提供数据抽取、清洗、转换和装载。
9. 二次开发
- 提供 C 语言接口和数据结构,方便第三方应用程序进行二次开发。
二、环境模拟
| 操作环境:VMware Workstation Pro 17 | ||||
| 机器ip | 主机名 | 操作系统 | 资源配置 | 实例名 |
| 192.168.52.10 | source | kylin-v10 | 4核4G,磁盘20g | SOURCE |
| 192.168.52.11 | kafka | kylin-v10 | 4核4G,磁盘20g |
|
| 机器ip | 实例名 | 达梦软件安装目录 | 数据存储目录 |
| 192.168.52.10 | SOURCE | /dm8/dminstall | /dm8/data |
| 192.168.52.11 | / | /dm8/dminstall | /dm8/data |
三、安装达梦数据库并数据准备
需求:192.168.52.10机器上有一个SOURCE的数据库,数据库里面有个APP的模式,里面存放着项目的表数据,现在需要把这些表数据实时同步到192.168.52.11机器上的kafka数据库里面的APP模式。
192.168.52.10(源数据库)的SOURCE数据库中的APP模式---->>192.168.52.11(目的数据库)的kafka数据库中的APP模式
下面的操作模拟环境:
1、模拟192.168.52.10(源环境)
1.1、创建达梦数据库对应的用户和组
groupadd dinstall
useradd -g dinstall dmdba
echo "Dameng123" |passwd --stdin dmdba1.2、创建达梦数据库安装目录
mkdir -p /dm8/{dminstall,dmdata,dmarch,dmback}
chown -R dmdba:dinstall /dm8
chmod -R 755 /dm81.3、调整系统资源限制
vim /etc/security/limits.conf
dmdba soft nofile 65536
dmdba hard nofile 65536
dmdba soft nproc 65536
dmdba hard nproc 65536###soft软连接,hard硬连接,nofile打开文件,nproc打开的进程
1.4、关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config1.5、下载镜像
达梦数据库镜像,官方下载:
产品下载 | 达梦在线服务平台
1.6、挂载镜像:
mount -o loop dm8_20230925_x86_rh6_64.iso /mnt/1.7、切换dmdba用户,安装数据库
su - dmdba
/mnt/DMInstall.bin -i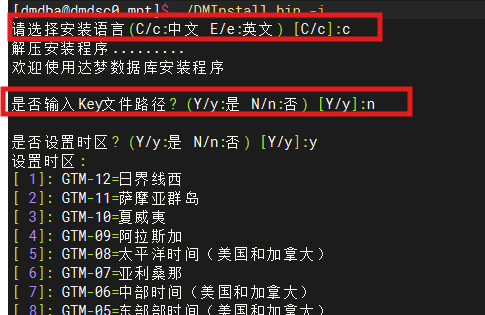
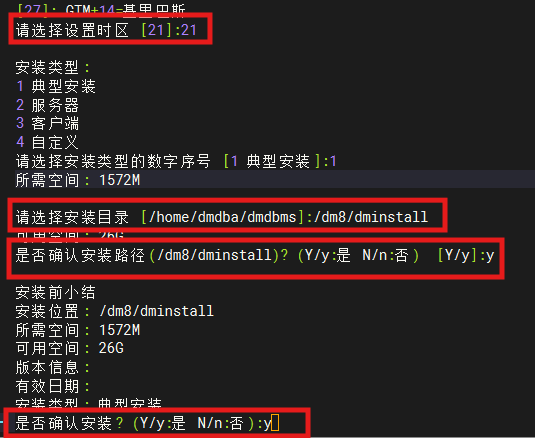
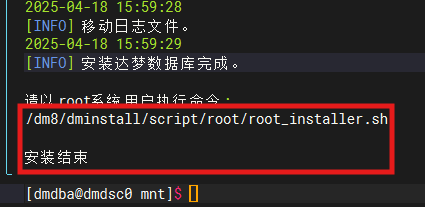
root用户下执行命令
/dm8/dminstall/script/root/root_installer.sh
root用户下执行命令 (关闭自启服务)
systemctl disable DmAPService.service --now
systemctl status DmAPService.service数据库创建完毕!!!
1.8、初始化实例
su - dmdba
/dm8/dminstall/bin/dminit path=/dm8/dmdata db_name=SOURCE instance_name=SOURCE port_num=52361.9、编写启动脚本
cd /dm8/dminstall/bin
cp service_template/DmService DmServiceSOURCE
vim DmServiceSOURCE1.10、修改内容如下
INI_PATH=%INI_PATH% 修改为 INI_PATH=/dm8/dmdata/DEST/dm.ini
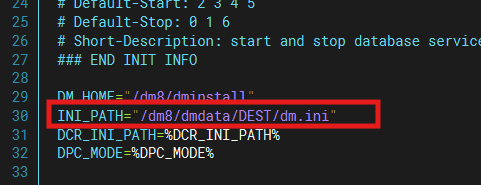
1.11、启动数据库实例
./DmServiceSOURCE start
1.12、创建数据
切换到dmdba用户执行
su - dmdba
cd /dm8/dminstall/bin
./disql SYSDBA/SYSDBA@192.168.52.10:5236执行下面的命令创建表空间、用户
CREATE TABLESPACE TEST DATAFILE 'TEST.DBF' SIZE 256;
CREATE USER APP IDENTIFIED BY "Dameng123" DEFAULT TABLESPACE TEST;
grant "DBA" to "APP";
exit1.13、使用新建的APP用户登录数据库,创建表和插入数据
./disql APP/Dameng123@192.168.52.10:5236CREATE TABLE STUDENTS(STUDENT_ID INTEGER PRIMARY KEY IDENTITY(1,1),NAME VARCHAR(50) NOT NULL,BIRTH_DATE DATE NOT NULL,GENDER CHAR(1) CHECK (GENDER IN ('M','F')) NOT NULL,EMAIL VARCHAR(100) UNIQUE NOT NULL,PHONE_NUMBER VARCHAR(15));INSERT INTO STUDENTS (NAME, BIRTH_DATE, GENDER, EMAIL, PHONE_NUMBER) VALUES ('张三', '2000-03-01', 'M', 'zhangsan@djl.com', '13243253257'),('李四', '1999-05-21', 'F', 'lisi@djl.com', '13312345678'),('王五', '2001-07-11', 'M', 'wangwu@djl.com', '13423456789'),('赵六', '1998-08-15', 'F', 'zhaoliu@djl.com', '13534567890'),('钱七', '2002-12-12', 'M', 'qianqi@djl.com', '13645678901'),('孙八', '2000-10-10', 'F', 'sunba@djl.com', '13756789012'),('周九', '1997-11-22', 'M', 'zhoujiu@djl.com', '13867890123'),('吴十', '2001-04-05', 'F', 'wushi@djl.com', '13978901234'),('郑十一', '1999-06-18', 'M', 'zhengshiyi@djl.com', '14089012345'),('王十二', '1998-09-09', 'F', 'wangshier@djl.com', '14190123456');commit;
SELECT * from STUDENTS;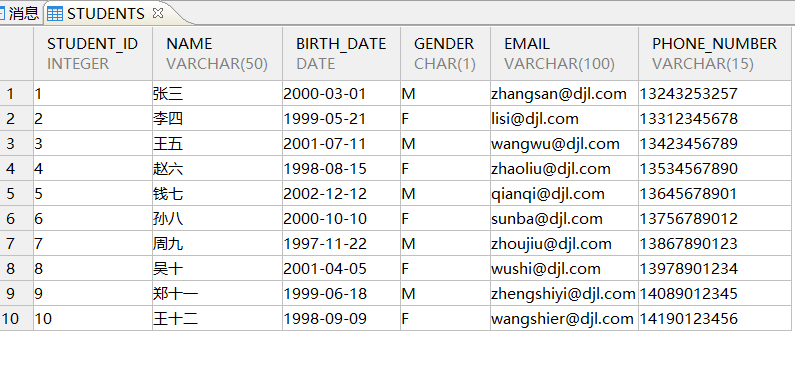
exit
2、模拟192.168.52.11(目的库)环境,安装单机kafka
1.1、安装数据库不再占用篇幅,参考上方安装数据库
1.2、安装java环境(root用户)
java -version在银河麒麟V10sp2系统中,系统中已经带有java,这里就不进行安装了

1.3、安装zookeeper(root用户)
由于kafka依赖于ZooKeeper,需要安装部署zookeeper并启动,这里使用的是3.9.3版本
可以上阿里云里下载:apache-zookeeper-zookeeper-3.9.3安装包下载_开源镜像站-阿里云
1.3.1、上传压缩包并解压
tar -zxvf apache-zookeeper-3.9.3-bin.tar.gz
mv apache-zookeeper-3.9.3-bin /usr/local/zookeeper1.3.2、复制配置文件zoo_sample.cfg 为zoo.cfg
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg1.3.3、修改 zoo.cfg 中dataDir的路径
vim /usr/local/zookeeper/conf/zoo.cfg:/dataDir 或者 :12dataDir=/usr/local/zookeeper/data1.3.4、创建数据库存放目录
mkdir -p /usr/local/zookeeper/data1.3.5、配置环境变量(文件最小面追加)
vim /etc/profile #zookeeper
export ZK_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZK_HOME/bin#kafka
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin1.3.6、加载环境变量
source /etc/profile1.3.7、启动zookeeper
zkServer.sh start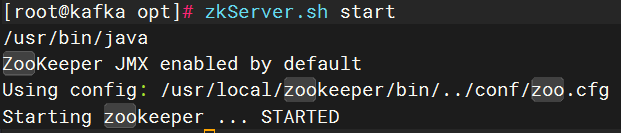
1.3.8、查看状态和端口
zkServer.sh status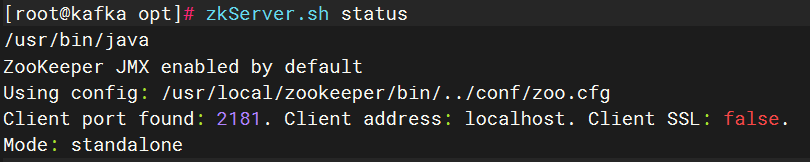
1.3.9、查看zkServer.sh 状态内容解析:
输出解析:
/usr/bin/java
-
- 这表示脚本使用了系统的
java命令来启动 ZooKeeper。 - 确保系统中安装的 Java 版本是兼容的(ZooKeeper 通常需要 Java 8 或更高版本)。
- 这表示脚本使用了系统的
ZooKeeper JMX enabled by default
-
- 表示 ZooKeeper 默认启用了 JMX(Java Management Extensions),这是一个用于监控和管理 Java 应用程序的功能。
- 如果不需要 JMX,可以通过配置禁用它,但这不是错误。
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
-
- 这表明脚本正在使用
/usr/local/zookeeper/conf/zoo.cfg配置文件。 - 确保
zoo.cfg文件存在并且配置正确(例如dataDir和clientPort是否设置正确)。
- 这表明脚本正在使用
Client port found: 2181. Client address: localhost. Client SSL: false.
-
- 客户端连接端口为
2181,这是 ZooKeeper 的默认端口。 - 客户端地址为
localhost,表示 ZooKeeper 只监听本地连接。 - SSL 被禁用,这通常是正常的,除非你需要启用 SSL 加密。
- 客户端连接端口为
Mode: standalone
-
- 表示 ZooKeeper 当前运行在 单机模式(standalone mode)。
- 单机模式适用于开发和测试环境。如果你需要高可用性或分布式部署,则需要配置 ZooKeeper 集群(即多节点模式)。
总结内容:
- ZooKeeper 成功加载了配置文件。
- 它正在监听默认的客户端端口
2181。 - 它以单机模式运行,状态正常。
1.3.10、查看与端口号 2181 相关的所有网络连接信息
ss -auntpl |grep 2181
结果解析:
- tcp:表示这是 TCP 协议的连接。
- LISTEN:表示该套接字处于监听状态,等待客户端连接。
- 0 和 50:分别表示接收队列和发送队列的大小。当前接收队列为空(0),最大允许的未完成连接数为 50。
- *:2181:表示服务器在所有可用网络接口上监听 2181 端口。
*:* 表示任何远程地址和端口都可以连接到这个监听端口。
- users:(("java",pid=3436,fd=73)):表示使用该套接字的进程是 Java 进程,其进程 ID (PID) 为 3436,文件描述符 (FD) 为 73。
总结
执行 ss -auntpl | grep 2181 可帮助检查端口 2181 上的网络活动,尤其是当 ZooKeeper 正在运行并监听此端口时。
1.4、安装kafka(root用户)
使用的版本是3.90
https://dlcdn.apache.org/kafka/3.9.0/kafka_2.12-3.9.0.tgz
1.4.1、将下载的文件上传到服务器解压
tar -zxvf kafka_2.13-3.9.0.tgz
mv kafka_2.13-3.9.0 /usr/local/kafka1.4.2、修改 /usr/local/kafka/config/server.properties 文件三个地方
vim /usr/local/kafka/config/server.properties# ip写自己机器的ip ##34行
listeners=PLAINTEXT://192.168.52.11:9092
##62行
log.dirs=/usr/local/kafka/data/kafka-logs
# 连接zookeeper ##125行
zookeeper.connect=192.168.58.5:21811.4.3、启动kafka
cd /usr/local/kafka/bin
kafka-server-start.sh ../config/server.properties &查看kafka版本
kafka-server-start.sh --version
1.4.4、测试kafka(root用户)
1、创建 topic
cd /usr/local/kafka/bin
kafka-topics.sh --create --bootstrap-server 192.168.52.11:9092 --replication-factor 1 --partitions 1 --topic test
1.kafka-topics.sh
- 这是一个 Kafka 提供的脚本,用于管理 Kafka 主题(Topic),包括创建、删除、查看和修改主题。
- 它通常位于 Kafka 安装目录的
bin文件夹中。
2. --create
- 表示要创建一个新的主题。
3. --bootstrap-server 192.168.52.11:9092
- 指定 Kafka 集群的地址和端口。
192.168.52.11是 Kafka Broker 的 IP 地址。9092是 Kafka 默认的监听端口。- 如果有多个 Broker,可以指定多个地址,用逗号分隔。例如:
4. --replication-factor 1
- 指定主题的副本因子(Replication Factor)。
- 副本因子决定了每个分区(Partition)的副本数量。
- 在这个例子中,副本因子为
1,表示每个分区只有一个副本(即没有额外的备份)。 - 注意:副本因子不能超过 Kafka 集群中可用 Broker 的数量。
5. --partitions 1
- 指定主题的分区数量。
- 分区(Partition)是 Kafka 中并行处理的基本单位。
- 在这个例子中,分区数量为
1,表示该主题只有一个分区。
6. --topic test
- 指定要创建的主题名称。
- 在这个例子中,主题名称为
test。
2、查看topic
kafka-topics.sh --list --bootstrap-server 192.168.52.11:9092 1. kafka-topics.sh
- 这是一个 Kafka 提供的脚本,用于管理 Kafka 主题(Topic),包括创建、删除、查看和修改主题。
- 它通常位于 Kafka 安装目录的
bin文件夹中。
2. --list
- 表示要列出 Kafka 集群中的所有主题。
3. --bootstrap-server 192.168.52.11:9092
- 指定 Kafka 集群的地址和端口。
192.168.52.11是 Kafka Broker 的 IP 地址。9092是 Kafka 默认的监听端口。- 如果有多个 Broker,可以指定多个地址,用逗号分隔。例如:
- --bootstrap-server 192.168.52.11:9092,192.168.52.12:9092
这条命令的作用是:
- 连接到
192.168.52.11:9092上的 Kafka Broker。 - 列出 Kafka 集群中所有的主题名称。
3、返回上面创建的 test # 查看topic描述
kafka-topics.sh --describe --bootstrap-server 192.168.52.11:9092 --topic test
1. kafka-topics.sh
- 这是一个 Kafka 提供的脚本,用于管理 Kafka 主题(Topic),包括创建、删除、查看和修改主题。
- 它通常位于 Kafka 安装目录的
bin文件夹中。
2. --describe
- 表示要查看指定主题的详细信息。
3. --bootstrap-server 192.168.52.11:9092
- 指定 Kafka 集群的地址和端口。
192.168.52.11是 Kafka Broker 的 IP 地址。9092是 Kafka 默认的监听端口。
4.--topic test
- 指定要查看的主题名称。
- 在这个例子中,主题名称为
test。
这条命令的作用是:
- 连接到
192.168.52.11:9092上的 Kafka Broker。 - 查看主题
test的详细信息,包括分区、副本、领导者(Leader)、同步副本集(ISR)等。
4、启动生产者(保留该窗口,别关闭)
cd /usr/local/kafka/binkafka-console-producer.sh --broker-list 192.168.52.11:9092 --topic test- kafka-console-producer.sh
这是一个 Kafka 提供的脚本,用于启动控制台生产者。
它允许用户通过命令行向 Kafka 主题发送消息。
脚本通常位于 Kafka 安装目录的 bin 文件夹中。 - --broker-list 192.168.52.11:9092
指定 Kafka 集群的地址和端口。
192.168.52.11 是 Kafka Broker 的 IP 地址。
9092 是 Kafka 默认的监听端口。
如果有多个 Broker,可以指定多个地址,用逗号分隔。例如:
Bash
深色版本
--broker-list 192.168.52.11:9092,192.168.52.12:9092 - --topic test
指定要发送消息的目标主题名称。
在这个例子中,目标主题为 test。
这条命令的作用是:
启动一个 Kafka 控制台生产者。
连接到 192.168.52.11:9092 上的 Kafka Broker。
将用户从终端输入的消息发送到主题 test。
运行过程:
执行命令后,终端会进入交互模式。
用户可以直接在终端中输入消息并按回车键发送。
每次按下回车键,输入的内容会被当作一条消息发送到 Kafka 主题 test。
生产者会持续运行,直到手动终止(通常是通过按下 Ctrl+C)。
5、启动消费者
cd /usr/local/kafka/binkafka-console-consumer.sh --bootstrap-server 192.168.52.11:9092 --topic test --from-beginning1.--topic test
指定要消费的目标主题名称。
在这个例子中,目标主题为 test。
2. --from-beginning
表示从主题的最早消息开始消费。
如果没有这个选项,消费者会从当前最新的偏移量(Offset)开始消费,只会接收新发送的消息。
使用 --from-beginning 后,消费者会读取该主题中存储的所有历史消息。
这条命令的作用是:
启动一个 Kafka 控制台消费者。
连接到 192.168.52.11:9092 上的 Kafka Broker。
从主题 test 中读取消息,并从最早的消息开始显示。
6、生产和消费的模拟
生产者生产消息:
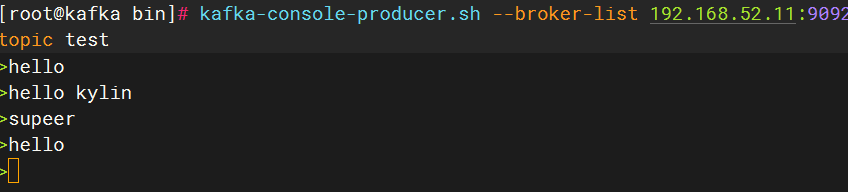
消费者查看消息:

四、开启归档和日志
1、环境检查(源端)
需要检查源端的数据库是否开启了归档日志和逻辑日志,如果有开启,忽略下面的操作
1.1、检查归档日志和逻辑日志是否开启
su - dmdba
cd /dm8/dminstall/bin
./disql APP/Dameng123@192.168.52.10:52361.2、检查归档配置的正确性,如果能查询到结果就是开启了
SELECT ARCH_DEST, ARCH_FILE_SIZE FROM SYS.V$DM_ARCH_INI WHERE ARCH_TYPE='LOCAL' AND ARCH_IS_VALID='Y'; 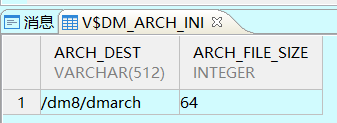
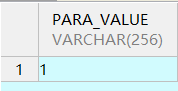
1.3、检查逻辑日志配置的正确性,查询出来的结果是1或者2是开启了
SELECT PARA_VALUE FROM SYS.V$DM_INI WHERE PARA_NAME = 'RLOG_APPEND_LOGIC'; exit
已经开启的示例:
2、如果上面的查询结果显示没有开启,执行下面的操作开启
2.1、编辑文件dm.ini
vim /dm8/dmdata/SOURCE/dm.ini##ARCH_INI和RLOG_APPEND_LOGIC设置成1,表示开启
ARCH_INI = 1
RLOG_APPEND_LOGIC = 1 2.2、添加归档配置文件
vim /dm8/dmdata/SOURCE/dmarch.ini# 内容如下:
[ARCHIVE_LOCAL1]
ARCH_TYPE = LOCAL
ARCH_DEST = /dm8/dmarch #归档目录
ARCH_FILE_SIZE = 128 #归档文件大小,单位 MB
ARCH_SPACE_LIMIT = 0 #空间大小限制,0 表示不限制2.3、重启数据库
cd /dm8/dminstall/bin
./DmServiceSOURCE restart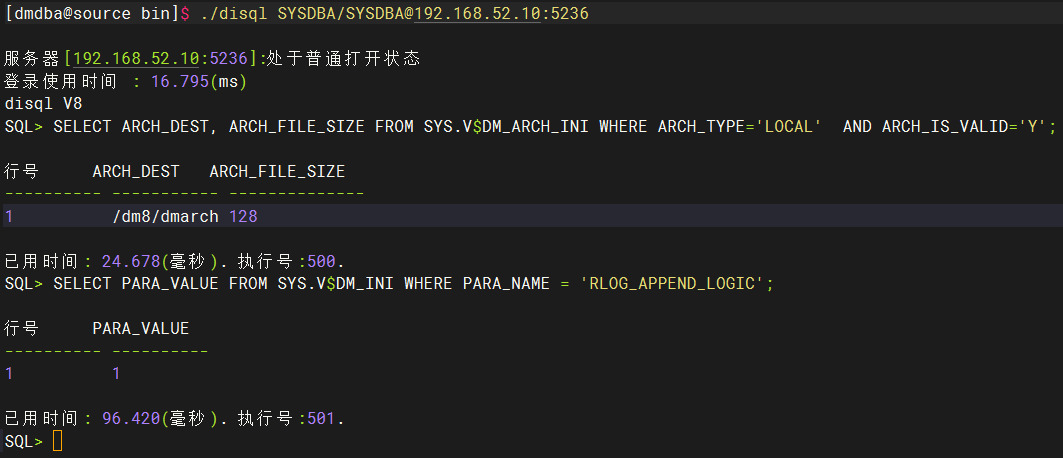
五、安装dmhs服务(源端和目的端都操作)(dmdba用户)
1、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
2、上传dmhs的bin、key文件
把下载好的bin、key文件上传到服务器的/opt目录下,并给bin文件授予执行权限。
chmod +x /opt/dmhs_V4.3.20_dm8_rev140201_rh6_64_20230916.bin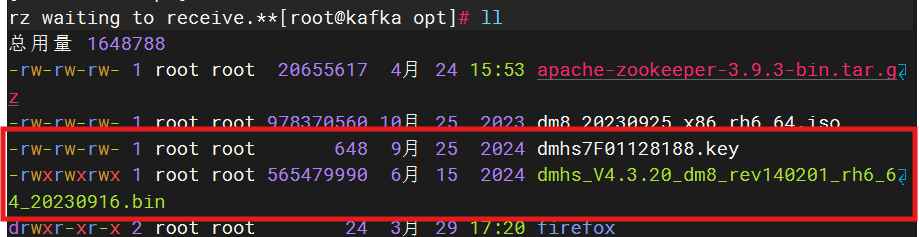
3、开始安装dmhs
su - dmdba
/opt/dmhs_V4.3.20_dm8_rev140201_rh6_64_20230916.bin -i大部分配置使用默认的就行,直接回车
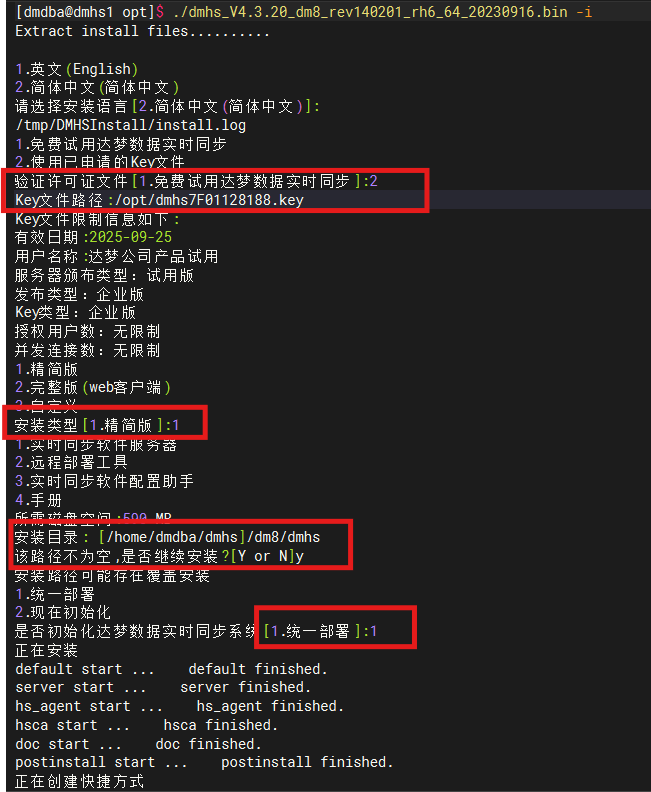
如果不用Key文件到后方会报错

这里 的ip需要照应
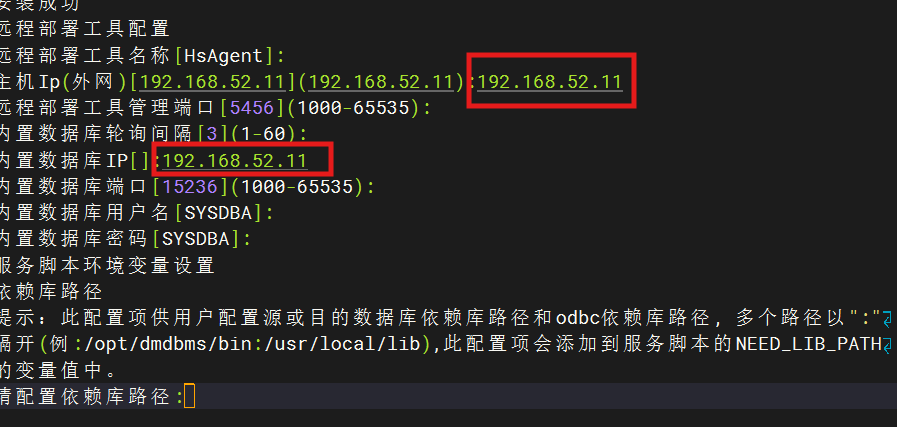
配置依赖库路径就填这个
/dm8/dminstall/bin:/dm8/dmhs/bin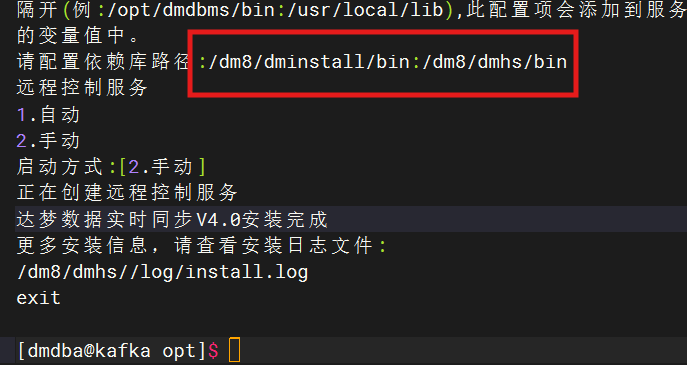
安装完成!!
六、配置dmhs.hs
1、源端配置
1.1、文件的复制
su - dmdba
cd /dm8/dmhs复制一份bin目录,单独配置,当同一个服务上需要部署多个dmhs,可以方便区分
cp -r bin cpt01
cd cpt01如果是测试dmhs,在使用的过程中可能会缺少libdmoci.so动态库文件报错,执行下面的命令复制一份到数据库的bin目录下,如果是生产中,需要去达梦官方申请
cp -r stat/libdmoci.so /dm8/dminstall/bin1.2、编辑配置文件dmhs.hs
cd /dm8/dmhs/cpt01
vim dmhs.hs# 内容如下:
<?xml version="1.0" encoding="GB2312" standalone="no"?>
<dmhs>
<base><lang>en</lang><mgr_port>5345</mgr_port><ckpt_interval>60</ckpt_interval><siteid>1</siteid><version>2.0</version>
</base>
<cpt><db_type>DM8</db_type><db_server>192.168.52.10</db_server><db_user>APP</db_user><db_pwd>Dameng123</db_pwd><db_port>5236</db_port><idle_time>10</idle_time><ddl_mask>0</ddl_mask><cpt_mask>PARSE:POST:REG_OP2</cpt_mask><n2c>0</n2c><update_fill_flag>3</update_fill_flag><set_heartbeat>1</set_heartbeat><arch><clear_interval>600</clear_interval><clear_flag>0</clear_flag></arch>
<send><ip>192.168.52.11</ip><mgr_port>5345</mgr_port><data_port>5346</data_port><net_pack_size>256</net_pack_size><net_turns>0</net_turns><crc_check>0</crc_check><trigger>0</trigger><constraint>0</constraint><identity>0</identity><filter><enable><item>APP.*</item></enable></filter><map><item>APP.* == APP.*</item></map>
</send>
</cpt>
</dmhs>2、配置目的端:
su - dmdba
cd /dm8/dmhs2.1、复制一份bin目录,单独配置,当同一个服务上需要部署多个dmhs,可以方便区分
cp -r bin exec01
cd exec012.2、目的端(52.11)配置文件dmhs.hs
vim dmhs.hs<?xml version="1.0" encoding="GB2312" standalone="no"?>
<dmhs><base><lang>en</lang><mgr_port>5345</mgr_port><ckpt_interval>60</ckpt_interval><siteid>2</siteid><version>2.0</version></base><exec><recv><data_port>5346</data_port></recv><exec_thr>1</exec_thr><exec_sql>1024</exec_sql><exec_policy>2</exec_policy><is_kafka>1</is_kafka><max_packet_size>16</max_packet_size><enable_ddl>1</enable_ddl></exec>
</dmhs>七、配置文件dmhs_kafka.properties
vim dmhs_kafka.properties# 内容如下:
# DMHS config file path
dmhs.conf.path=/dm8/dmhs/exec01/dmhs.hs
# kafka broker list,such as ip1:port1,ip2:port2,...
bootstrap.servers=192.168.52.11:9092
# kafka topic name
kafka.topic.name=test
#dmhs.sendKey.parse.format=schema:source:tableName
#dmhs.sendKey.parse.format=primary_keys_values
#dmhs.sendTopic.parse.format=schema:source:tableName
#topic.map.conf.path=/dmhs_kafka/bin_0329/tableTopicMap.properties
# whether to enable JSON format check
json.format.check=1
# How many messages print cost time
print.message.num=1000
# How many messages batch to get
dmhs.min.batch.size=100
# kafka serializer class
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
# kafka partitioner config
partitioner.class=com.dameng.dmhs.dmga.service.impl.OnePartitioner
# kafka request acks config
acks=-1
max.request.size=5024000
batch.size=1048576
linger.ms=3
buffer.memory=134217728
retries=3
#enable.idempotence=true
compression.type=none
max.in.flight.requests.per.connection=1
send.buffer.bytes=1048576
metadata.max.age.ms=300000八、配置文件start_dmhs_kafka.sh
vim start_dmhs_kafka.sh# 内容如下:
export LANG=en_US.UTF-8
java -Djava.ext.dirs="/usr/local/kafka/libs:." com.dameng.dmhs.dmga.service.impl.ExecDMHSKafkaService dmhs_kafka.properties赋可执行权限
chmod +x start_dmhs_kafka.sh九、同步测试
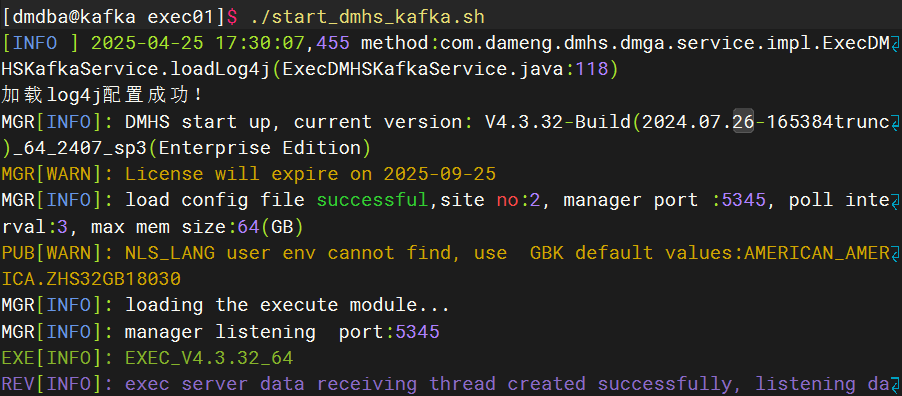
1、启动目的端
su - dmdba
cd /dm8/dmhs/exec01
./start_dmhs_kafka.sh启动后则表示目的端已经以前台方式启动增量同步。成功示例:
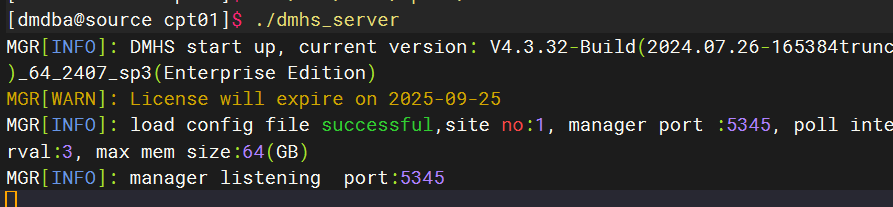
2、启动源端:
su - dmdba
cd /dm8/dmhs/cpt01
./dmhs_server成功示例:
DMHS>copy 0 "SCH.NAME='APP'" DICT
DMHS>copy 0 "SCH.NAME='APP'" INSERT
DMHS>clear exec lsn
DMHS>start cpt3、查看kafka队列(topic)test中是否有数据
kafka-console-consumer.sh --bootstrap-server 192.168.52.11:9092 --topic test --from-beginning4、配置好服务并启动后,再去源端新增一条数据,然后到目的端kafka看看是否同步成功
# 源端添加一条数据
su - dmdba
cd /dm8/dminstall/bin
./disql APP/Dameng123@192.168.52.10:5236INSERT INTO APP.STUDENTS (NAME, BIRTH_DATE, GENDER, EMAIL, PHONE_NUMBER) VALUES ('美女', '2002-4-25', 'F', 'meinv@djl.com', '13243253549');COMMIT;
达梦数据库社区地址:达梦数据库 - 新一代大型通用关系型数据库 | 达梦在线服务平台












)






能力的重要基准任务(Benchmark))