哈希表
哈希函数
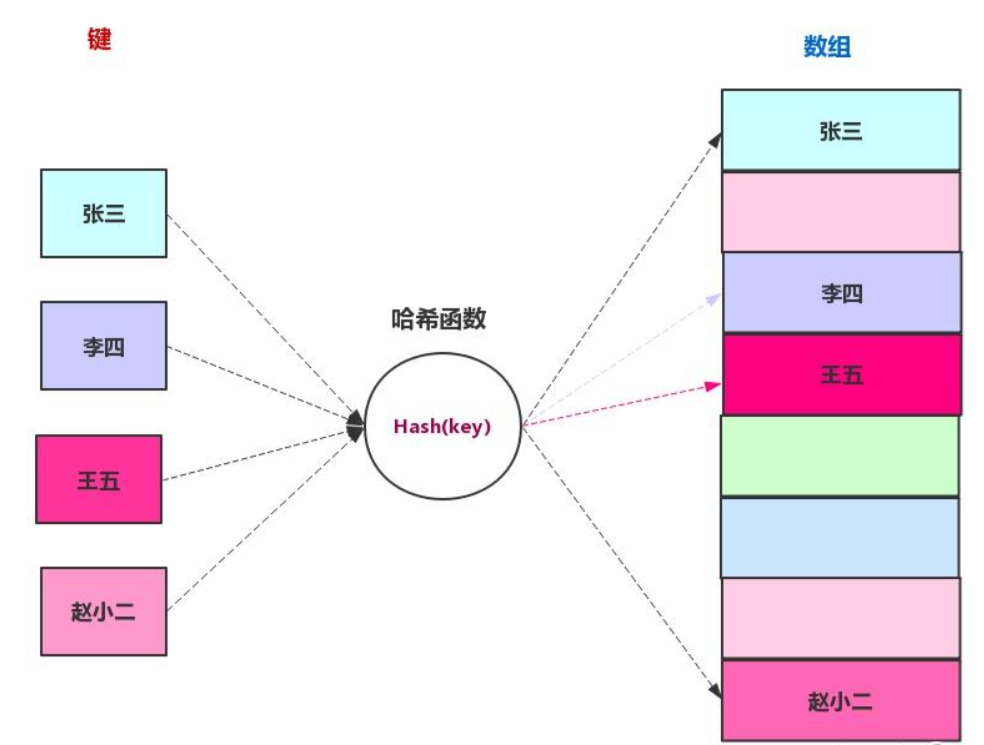
哈希表使用了哈希函数来完成key到地址的快速映射,所以在了解哈希表之前,需要先明白哈希函数的概念和特点。
哈希函数的定义
- 哈希函数
- 哈希函数是一种将任意长度输入的数据,转换成固定长度输出的算法
- 哈希函数H可以表示为
y=H(x)H指代哈希函数x是输入数据,可以是任意长度y是输出的哈希值,具有固定长度
- Hashcode
- 这部分被固定长度输出的数据被称为Hashcode哈希值或散列值
哈希函数的特点
-
确定性
- 不管执行多少次,通过某个key所得到的内存数组索引位置(即哈希值)是不变的
-
固定长度输出
- 哈希函数的核心任务是将无限映射到有限,即不管输入值数据大小是1kb还是1G,数据长度是1位还是1000位,它的通过哈希函数产生的哈希值长度都是固定的,具体输出长度由算法决定
SHA-256算法输出永远是256位(32字节)MD5算法输出永远是128位(16字节)

- 哈希函数的核心任务是将无限映射到有限,即不管输入值数据大小是1kb还是1G,数据长度是1位还是1000位,它的通过哈希函数产生的哈希值长度都是固定的,具体输出长度由算法决定
-
单向性
- 输入值可以单向通过哈希函数获得哈希值,但是通过哈希值不可以反向获取输入值原数据。哈希函数是一个“单向门”或“单向函数”。从
x计算H(x)很容易,但从H(x)反推出x极其困难。- 这一点在密码存储上至关重要,系统可以存储用户密码的哈希值,即时数据库泄漏,攻击者也无法轻易从哈希值还原出用户的原始密码
- 输入值可以单向通过哈希函数获得哈希值,但是通过哈希值不可以反向获取输入值原数据。哈希函数是一个“单向门”或“单向函数”。从
-
高效性
- 计算哈希值的过程快速且高效,即时是处理大量数据也能快速完成
- 哈希函数算法是由简单的位运算(与、或、非、异或、移位、旋转)构成,这些操作在现代计算机上执行是非常快速的
-
需要处理哈希冲突/哈希碰撞
- 哈希函数因为是无限映射到有限,输入空间是无限的,所以有可能出现两个不同的输入,对应了同一个哈希值,即出现了碰撞
- 哈希函数设计目标需要尽可能的避免出现碰撞
引申问题1:哈希函数和加密函数的区别
- 哈希函数和加密函数最大的区别是
- 哈希函数是单向的,不可逆,即通过哈希值很困难找到原始值
- 加密函数式双向的,可逆(需密钥解密),通过密文也可以找到原文
| 维度 | 哈希函数 (Hash) | 加密函数 (Encryption) |
|---|---|---|
| 可逆性 | 单向,不可逆 | 双向,可逆(需密钥解密) |
| 密钥 | 无密钥 | 有密钥(对称或公私钥) |
| 输出长度 | 固定(如 256 位) | 可变(通常 ≥ 明文长度) |
| 速度目标 | 尽量快,便于校验 | 对称快、非对称慢,但都比哈希慢 |
| 碰撞 | 必须抗碰撞(难以找到两输入同输出) | 无碰撞概念(一对一映射) |
| 典型应用 | 密码摘要、数据完整性、数字签名 | 机密传输、磁盘加密、HTTPS |
| 示例算法 | SHA-256, BLAKE3, MD5 | AES, ChaCha20(对称);RSA, ECC(非对称) |
引申问题2:MD5算法和SHA256算法是哈希函数还是加密函数
- MD5算法和SHA256算法都是哈希算法,不算加密算法
- 两者都是
任意长度的输入,压缩成固定长度摘要(SHA256为256bit,MD5为128bit) - 两者都不设秘钥,不可逆,不具备加密/界面功能
- 常见用途
- 校验文件完整性
- 数字签名前置压缩
- 密码存储(配合盐值和KDF)
- 两者都是
引申问题3:位运算为什么快
- 位运算是直接在CPU寄存器上用最简硬件逻辑完成的
- AND/OR/XOR/NOT/SHIFT 都只需少量晶体管组成的组合逻辑门(与门、或门、异或门、移位器)
- 零内存访问、零复杂算法、单周期延迟,是所有运算中成本最低的
哈希表的定义
定义
- 哈希表是一种动态数据结构,以key-value键值对存储数据
- 核心思想是使用
哈希函数将key转换为数组下标索引保存后,下次再次查询时,使用仍然通过哈希函数将key转化为数组下标,快速定位到数据的位置
目的
- 实现快速的数据存储和检索
- 注意,此处的快速检索指的是通过key来查询value是快速的;如果仅仅只是查找某个value,数据检索效率并不高
核心公式
index = hash(key) mod capacity
组成部分
-
哈希函数
- 将key转换为数组索引的算法
-
数组
- 用于存储键值对数据的数组
-
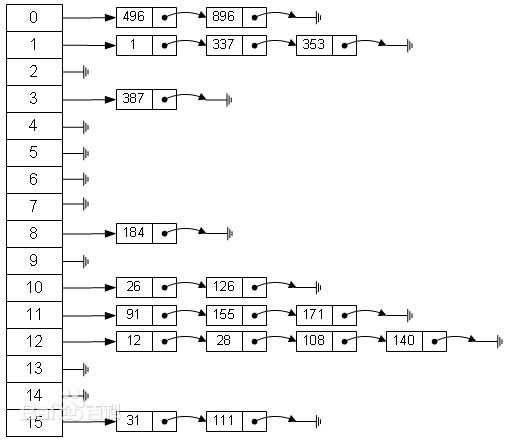
哈希冲突/碰撞解决方法
- 因为哈希函数式无限(输入)转化为有限(输出),一定存在不同的输入产生相同的输出,即碰撞(或称为冲突)
- 冲突/碰撞解决方法,指的是当碰撞发生时,不同的key被映射到同一个数组下标索引时,如何处理,一般使用以下方法
链表法开放寻址法
哈希表的优点
-
操作高效
- 增、删、查操作的时间复杂度为O(1),非常高效
-
实现简单
- 大多数编程语言中都有内置支持(Java的Hashmap;Python的dict)
-
灵活性强
- 可以存储各种类型的键值对
哈希表的缺点
-
哈希冲突处理
- 哈希冲突处理不当,会影响性能
-
空间浪费
- 为了避免哈希冲突,一般都会预留较大的内存空间
-
不支持有序遍历
- 哈希表中的元素是无序的(因为保存时是通过hash函数计算出应该放在哪个数组下标,导致整体是随机的)
-
设计复杂
- 需精心设计哈希与冲突策略、负载因子、并发、缩容等工程细节,难度较高
引申问题4:哈希表为什么操作这么高效
-
哈希表操作时可以直接定位数据存储位置(前提通过key来操作)
- 哈希表的核心是哈希函数,哈希函数可以将key直接转换为数据在数组中的下标,比如get(key)等同于直接查array[5],时间复杂度是
常数时间 O(1)
- 哈希表的核心是哈希函数,哈希函数可以将key直接转换为数据在数组中的下标,比如get(key)等同于直接查array[5],时间复杂度是
-
数据结构支持随机访问
- 因为是直接查下标,不需要遍历数据
-
哈希冲突处理优化
- 对于可能存在的哈希冲突,哈希表会通过
链表法、开放寻址法来优化防止出现哈希冲突,从而减少哈希冲突对性能的影响
- 对于可能存在的哈希冲突,哈希表会通过
哈希表的应用场景
-
快速查找
- 通过索引key快速定位内容
- 统计字符或单次出现的频率
- 计算方式:对于每个字符,如果它已经在哈希表(这一步可以使用哈希函数通过key快速索引)中,将对应的值加 1。
- 如果它不在哈希表中,将其加入哈希表,值设为 1。
- 快速判断一个元素是否在数组中
-
数据库索引
- 数据库中的哈希索引(比如MySQL的Memory引擎)
-
缓存系统
- LRU 缓存(Least Recently Used Cache)常用哈希表 + 双向链表实现
什么是渲染)
)
 视频教程 - snowNLP库实现中文情感分析)
















