精选专栏链接 🔗
- MySQL技术笔记专栏
- Redis技术笔记专栏
- 大模型搭建专栏
- Python学习笔记专栏
- 深度学习算法专栏
欢迎订阅,点赞+关注,每日精进1%,与百万开发者共攀技术珠峰
更多内容持续更新中!希望能给大家带来帮助~ 😀😀😀
MySQL多表查询中的笛卡尔积问题
- 1,为什么需要多表查询
- 2,什么是笛卡尔积
- 3,多表查询的笛卡尔积错误
- 3.1,笛卡尔积错误案例
- 3.2,笛卡尔积错误的分析和解决
- 3.3,公共字段的处理
- 练习
1,为什么需要多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
可进行多表查询的前提条件: 这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,比如:员工表和部门表,这两个表依靠“部门编号”进行关联。
案例说明为什么需要多表查询:
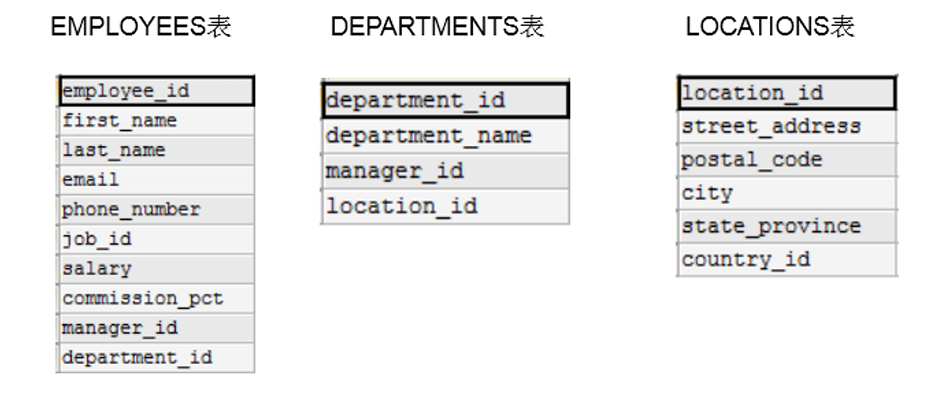
如下图所示的是一个项目的三张表:EMPLOYEES表(员工表)、DEPARTMENTS表、LOCATIONS表。
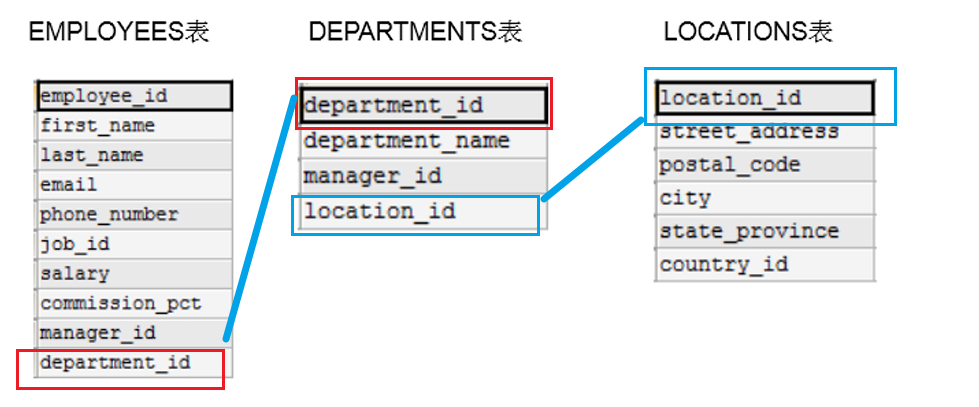
显然,我们可以得到如下信息:
- EMPLOYEES 表和DEPARTMENTS表通过 department_id 字段相关联;
- DEPARTMENT表和 LOCATIONS 表通过 location_id 字段相关联;
如果我们现在有一个新需求:要求查询员工名为 “Abel” 的人在哪个城市工作?
显然 EMPLOYEES 表中没有城市这个字段,城市字段位于 LOCATIONS 表内。
我们可以通过如下步骤完成此需求。
第一步:在EMPLOYEES表内查询Abel的员工信息
SQL语句如下:
SELECT *
FROM employees
WHERE last_name = 'Abel';
运行结果如下:

可以看到Abel 所在的 department_id 为80。
第二步:在DEPARTMENT表内查询department_id 为80的部门信息
SQL语句如下:
SELECT *
FROM departments
WHERE department_id = 80;
运行结果如下:

可以看到department_id 为80的部门对应的location_id是2500。
第二步:在LOCATIONS表内查询location_id是2500的地址信息
SQL语句如下:
SELECT *
FROM locations
WHERE location_id = 2500;
运行结果如下:

由此可见,员工Abel的工作城市是Oxford。
写了三条SQL语句才实现此需求,找到了Abel的工作城市,这样是很不方便的,而且在高并发的系统中,执行多个SQL语句对效率和性能的影响是比较大的(相当于多次交互)。因此要引入多表查询,通过多表查询可以实现 一条SQL语句完成此需求。
2,什么是笛卡尔积
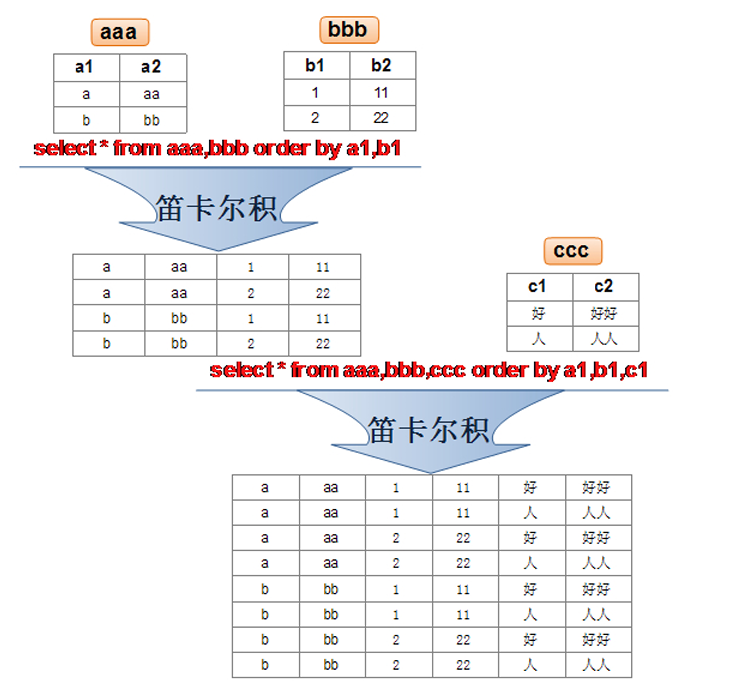
笛卡尔乘积是一个数学运算。假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能组合,也就是第一个对象来自于 X,第二个对象来自于 Y 的所有可能。组合的个数即为两个集合中元素个数的乘积数。如下图所示:
3,多表查询的笛卡尔积错误
多表查询的一个常见错误就是笛卡尔积错误。
3.1,笛卡尔积错误案例
当我们有如下需求时:
需求:查询每一位员工的employee_id和department_name。
注意: 如下图所示,员工的employee_id位于EMPLOYEES表,而department_name字段位于DEPARTMENTS表。

如果执行如下SQL语句,得到的是错误结果:
SELECT employee_id,department_name
FROM employees,departments;
运行结果如下:
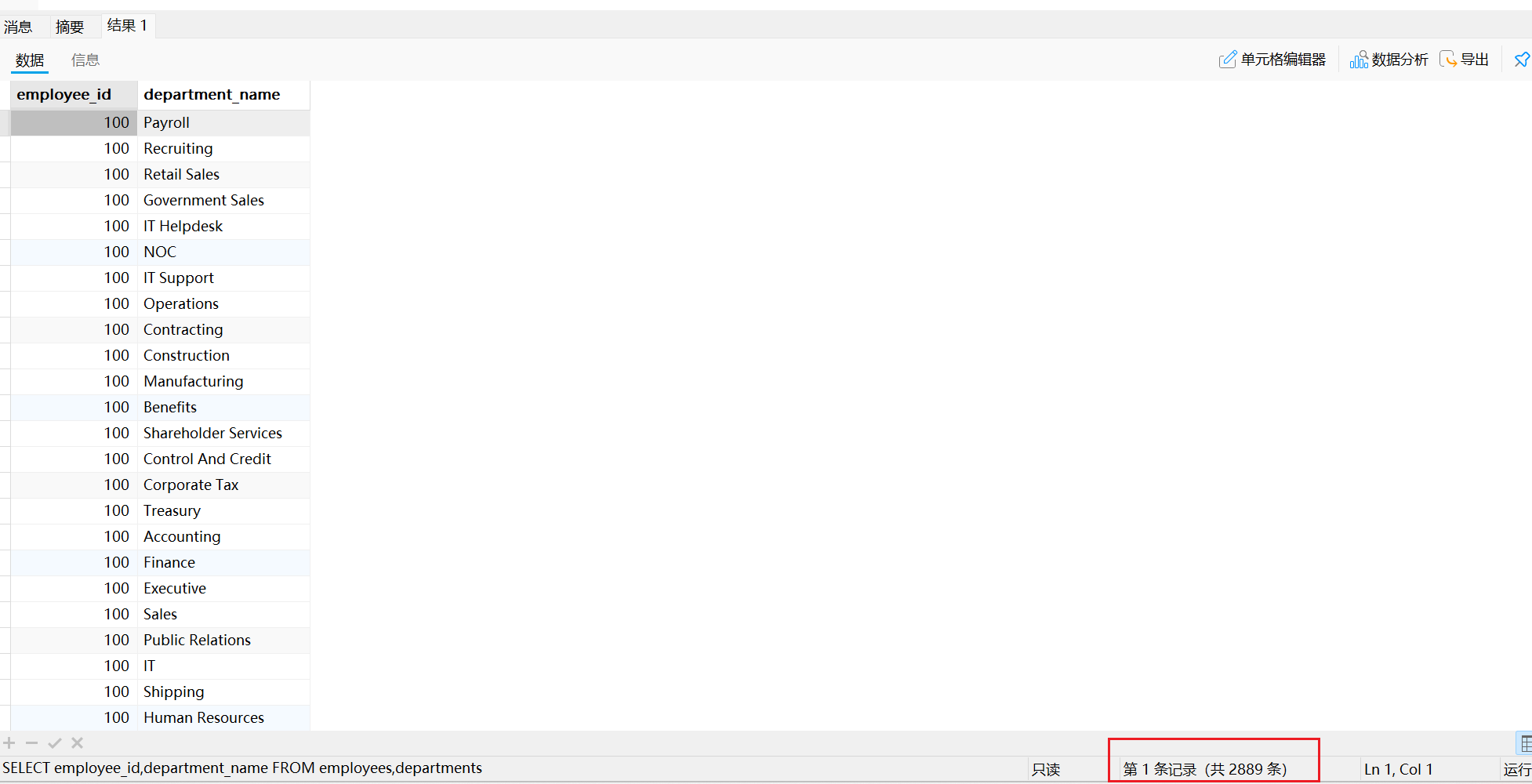
一共查询出2889条记录,而EMPLOYEES表有107条记录;DEPARTMENTS表有27条记录。27✖107=2889,它把每个员工都与每个部门匹配了一遍,显然这是一种错误的实现方式,具体来说是出现了笛卡尔积的错误。
错误的原因是:缺少了多表的连接条件。
3.2,笛卡尔积错误的分析和解决
笛卡尔积错误会在下面条件下产生:
- 省略多个表的连接条件(或关联条件);
- 连接条件(或关联条件)失效;
- 所有表中的所有行互相连接;
正确的多表查询需要有连接条件。为了避免笛卡尔积错误,可以通过WHERE子句加入有效的连接条件。
加入连接条件后的查询语法如下:
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2; #连接条件
因此,正确的SQL语句应该是:
SELECT employee_id,department_name
FROM employees,departments
# 两个表的连接条件
WHERE employees.department_id = departments.department_id;
运行结果如下:
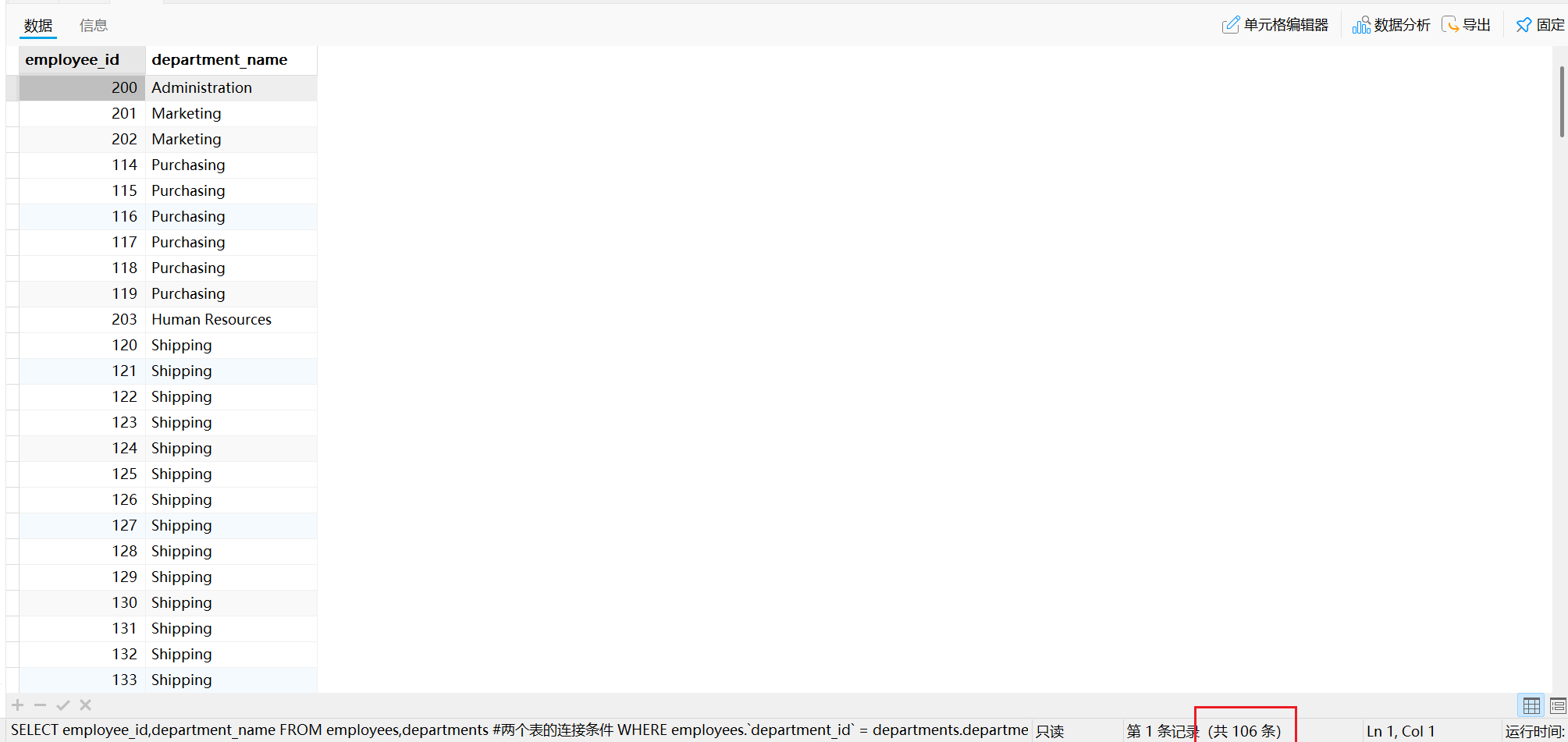
此时查询得到的结果才是正常的。
注意:如上SQL查询得到106条记录,而EMPLOYEES表内有107条记录,原因是EMPLOYEES表中存在一条记录的 department_id 字段为Null。
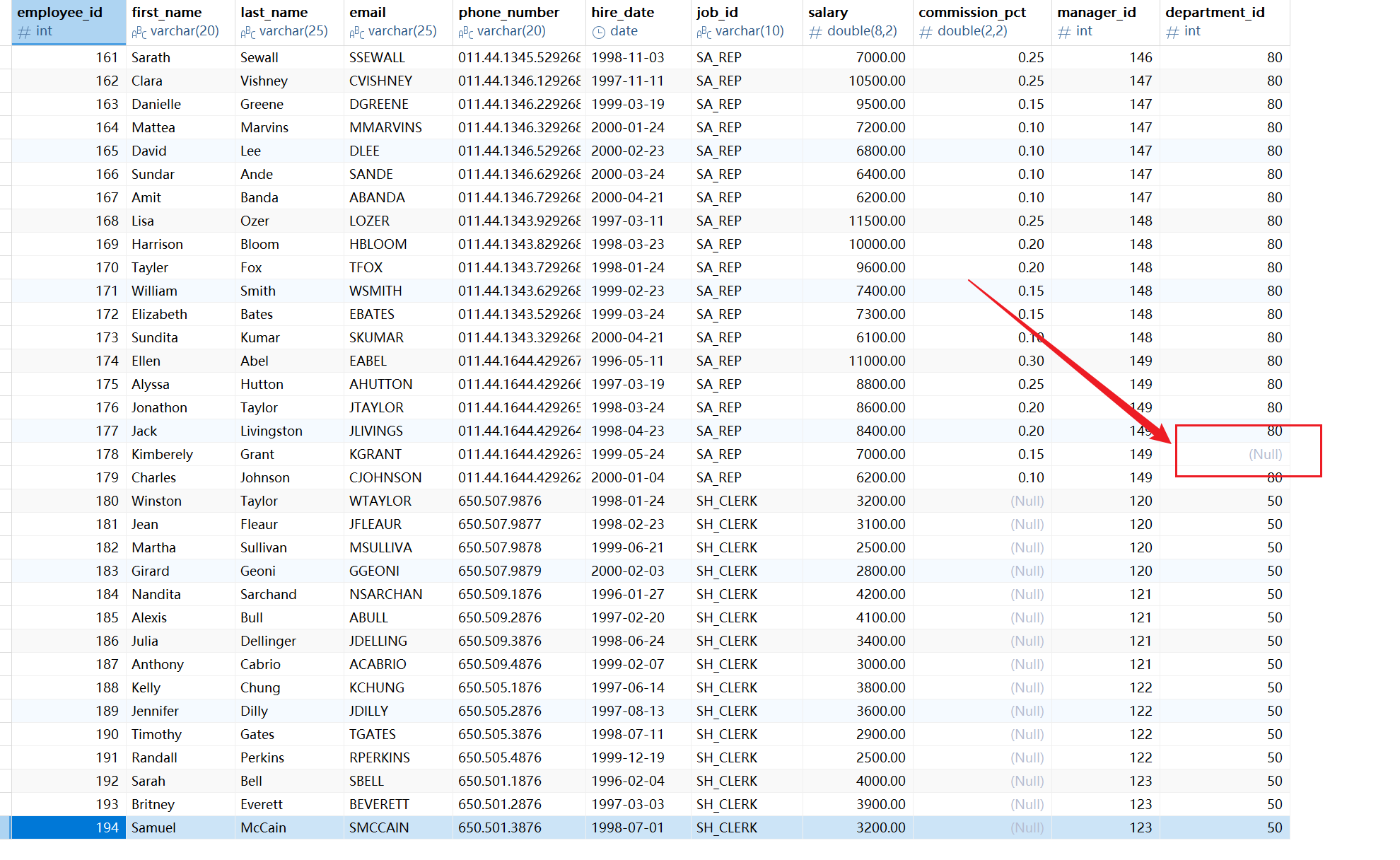
3.3,公共字段的处理
一个细节问题是:如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表。接下来结合案例解释:
需求:查询每一位员工的employee_id、department_name、department_id。
如果执行如下SQL:
SELECT employee_id,department_name,department_id
FROM employees,departments
WHERE employees.`department_id` = departments.department_id;
执行报错:

原因是:EMPLOYEES表和DEPARTMENTS表都存在字段 departmen_id,SQL语句中没有明确指出查询哪个表中的 departmen_id 字段。
因此正确的SQL语句是:
# 如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表。
SELECT employee_id,department_name,employees.department_id
FROM employees,departments
WHERE employees.`department_id` = departments.department_id;
运行结果如下:
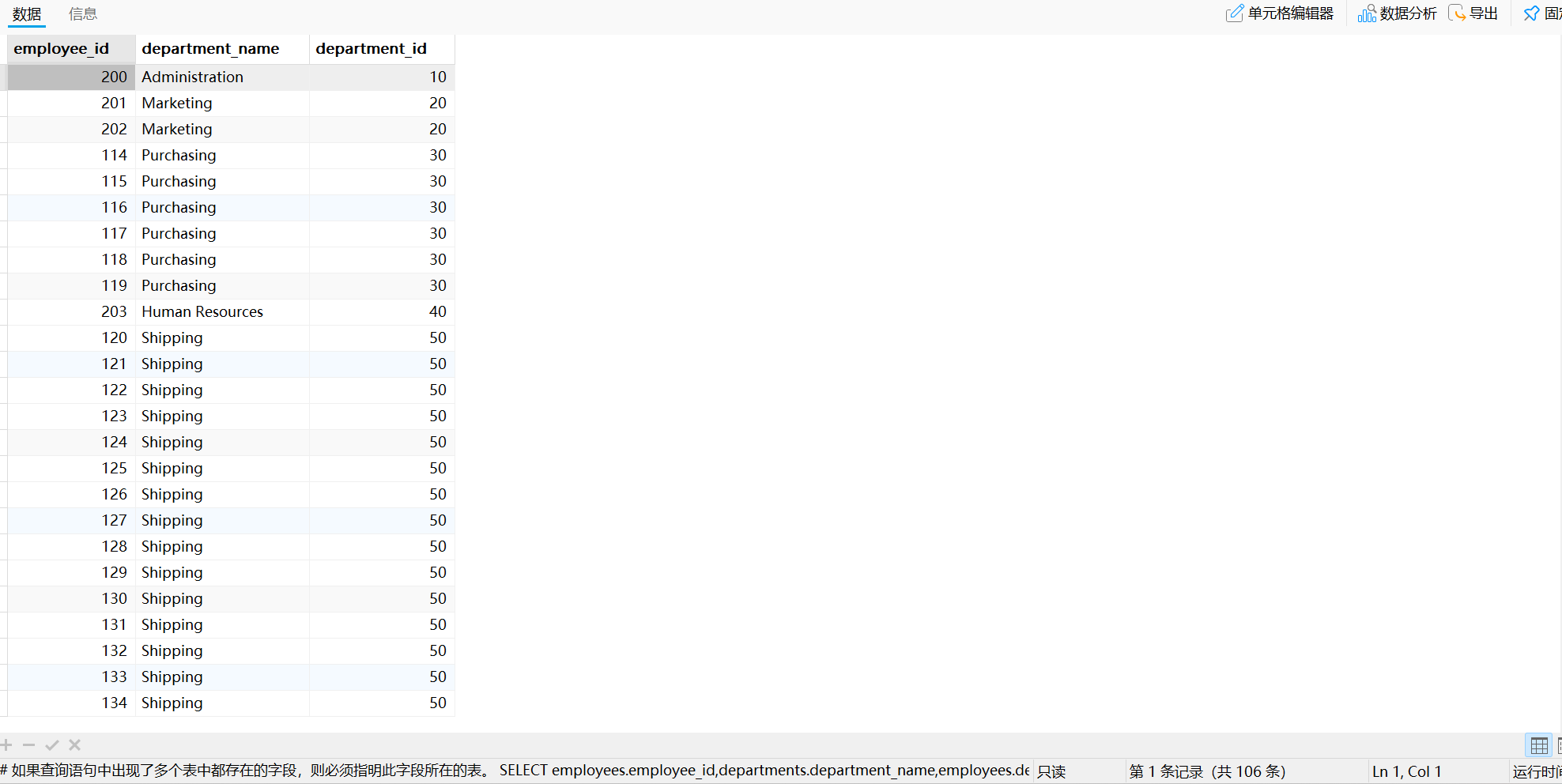
我们了解到,如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表。对此规则进行拓展:从sql优化的角度,建议多表查询时,每个字段前都指明其所在的表。
因为如果不指明字段所在的表,MySQL会自己去两张表中找此字段,找到后还需要检查另外一张表中是否存在此字段。这会在一定程度上影响查询的性能。因此建议多表查询时,每个字段前都指明其所在的表。
即,更好的SQL语句如下:
SELECT employees.employee_id,departments.department_name,employees.department_id
FROM employees,departments
WHERE employees.`department_id` = departments.department_id;
练习
我们再提出一个新的需求用做练习。
需求:查询每一位员工的employee_id、last_name、department_name、city。
SQL语句如下:
SELECT e.employee_id,e.last_name,d.department_name,l.city,e.department_id,l.location_id
FROM employees e,departments d,locations l
WHERE e.`department_id` = d.`department_id`
AND d.`location_id` = l.`location_id`;
因此可以总结出规律:如果有n个表实现多表的查询,则需要至少n-1个连接条件。

欢迎订阅,点赞+关注,每日精进1%,与百万开发者共攀技术珠峰
更多内容持续更新中!希望能给大家带来帮助~ 😀😀😀

![[C/C++内存安全]_[中级]_[安全处理字符串]](http://pic.xiahunao.cn/[C/C++内存安全]_[中级]_[安全处理字符串])








)








积分推导)