目录
1、模型上下文窗口
1.1、增加上下文窗口的微调(Fine-tuning for Longer Context)
1.1.1、 核心目标
1.1.2、关键步骤
(1)数据准备:构建长文本训练集
(2)微调策略:分阶段适应
(3)训练技巧
1.1.3、 优缺点
2、位置编码(Positional Encoding)
2.1、 常见位置编码类型
2.2、扩展位置编码的关键方法
2.2.1、扩展绝对位置嵌入(适用于可学习位置编码)
2.2.2、优化相对位置编码(以 RoPE 为例)
3、插值法(Interpolation)
3.1、 核心原理
3.2、 适用场景与实现
3.3、 优缺点
4、总结与对比
5、完整代码
6、实验结果
6.1、保存模型
一、训练阶段:记录完整训练轨迹
二、复用阶段:支持模型快速重启 / 迁移
三、部署阶段:实现模型生产级落地
6.2、验证样本
6.3、模型评估
1、模型上下文窗口
模型上下文窗口(Context Window)是指模型能够同时处理的最大输入序列长度,扩展上下文窗口对长文档理解、多轮对话、代码生成等场景至关重要。以下从增加上下文窗口的微调、位置编码、插值法三个维度,详细解析扩展上下文窗口的技术原理与实现方法:
1.1、增加上下文窗口的微调(Fine-tuning for Longer Context)
当模型预训练的上下文窗口小于目标长度(如从 2048 扩展到 4096)时,需要通过微调让模型适应更长的序列,核心是让模型在更长的文本上学习语义关联和位置感知。
1.1.1、 核心目标
- 让模型在更长序列上保持语义理解能力(如长文档中的因果关系、指代关系);
- 避免因序列过长导致的性能下降(如注意力分散、记忆衰退)。
1.1.2、关键步骤
(1)数据准备:构建长文本训练集
-
数据来源:选择与任务相关的长文本数据(如书籍章节、法律文档、代码库、多轮对话历史等),长度需覆盖目标窗口(如 4096-8192 tokens)。
-
数据处理:
- 截断与拼接:将超长篇文本截断为目标窗口长度,或拼接短文本形成长序列(确保语义连贯性);
- 加入长距离任务:设计需要长距离依赖的任务(如长文档摘要、跨段落问答、多文档推理),增强模型对长序列的感知。
python
运行
# 示例:构建长文本训练数据(目标窗口4096 tokens) def prepare_long_text_data(raw_texts, tokenizer, max_length=4096):long_samples = []for text in raw_texts:# 分词后截断或拼接至max_lengthtokens = tokenizer(text, truncation=False, return_tensors="pt")["input_ids"][0]if len(tokens) > max_length:# 截断为max_lengthtruncated = tokens[:max_length]else:# 不足时用同类文本拼接(确保语义相关)truncated = torch.cat([tokens, tokens[:max_length - len(tokens)]]) # 示例:重复拼接(实际需用真实文本)long_samples.append({"input_ids": truncated, "labels": truncated}) # 自回归训练目标return Dataset.from_list(long_samples)
(2)微调策略:分阶段适应
-
阶段 1:继续预训练(Continued Pretraining) 在长文本数据上进行无监督预训练,学习长序列的基础语义关联,使用自回归目标(如预测下一个 token),学习率较低(如 1e-5),避免破坏原有能力。
-
阶段 2:任务微调(Task-specific Fine-tuning) 在具体任务(如长文档问答、摘要)上微调,使用任务相关的监督数据,强化长序列的任务适配能力。
(3)训练技巧
- 梯度累积:长序列训练显存消耗大,通过
gradient_accumulation_steps减少显存占用(如batch_size=1 + gradient_accumulation_steps=8等效于 batch_size=8)。 - 注意力检查:监控注意力权重分布,确保模型对长序列中的关键信息(如首尾关联)有足够关注,避免注意力分散。
- 逐步扩展:从略长于预训练窗口的长度(如 2048→3072)开始微调,逐步增加到目标长度(如 4096),降低训练难度。
1.1.3、 优缺点
- 优点:能从根本上提升模型对长序列的理解能力,适配性强;
- 缺点:需要大量长文本数据和计算资源,训练成本高。
2、位置编码(Positional Encoding)
位置编码是模型感知 token 在序列中位置的核心机制,直接影响模型对长序列的处理能力。扩展上下文窗口时,需调整位置编码以覆盖更长的位置范围。
2.1、 常见位置编码类型
| 类型 | 原理 | 扩展难点 |
|---|---|---|
| 绝对位置编码 | 为每个位置分配唯一编码(如 Transformer 的正弦余弦编码、GPT 的可学习位置嵌入) | 预训练时的最大位置固定(如 GPT-2 的 1024),扩展后超出范围的位置无对应编码 |
| 相对位置编码 | 编码 token 间的相对距离(如 T5、LLaMA 的 RoPE) | 需确保长距离相对位置的编码逻辑一致(如超过预训练范围的距离仍能被正确编码) |
| 旋转位置编码(RoPE) | 通过旋转矩阵将位置信息融入 token 嵌入,支持任意长度扩展 | 无需修改编码长度,仅需调整旋转角度参数即可扩展至更长序列 |
2.2、扩展位置编码的关键方法
2.2.1、扩展绝对位置嵌入(适用于可学习位置编码)
-
步骤:
- 保留预训练的位置嵌入(如 1-2048);
- 对新增位置(2049-4096)的嵌入进行初始化(如随机初始化或插值现有嵌入);
- 在长文本数据上微调,让模型学习新增位置的嵌入。
-
示例:GPT 类模型扩展
# 假设原模型最大位置为2048,扩展到4096 model = AutoModelForCausalLM.from_pretrained("gpt2") old_max_pos = model.config.max_position_embeddings # 2048 new_max_pos = 4096# 扩展位置嵌入矩阵 new_pos_emb = torch.nn.Embedding(new_max_pos, model.config.hidden_size) new_pos_emb.weight.data[:old_max_pos] = model.transformer.wpe.weight.data # 复制原有嵌入 new_pos_emb.weight.data[old_max_pos:] = torch.randn( # 初始化新增位置(或用插值)new_max_pos - old_max_pos, model.config.hidden_size ) * 0.01 # 小初始化避免干扰model.transformer.wpe = new_pos_emb model.config.max_position_embeddings = new_max_pos # 更新配置 -
缺点:新增位置的嵌入需要大量数据微调才能生效,否则可能导致性能下降。
2.2.2、优化相对位置编码(以 RoPE 为例)
RoPE 通过旋转矩阵将位置信息编码到 token 嵌入中,公式为: ,pos为位置索引。
其中,
- 扩展原理:RoPE 的旋转角度仅与位置pos和维度i相关,无需预定义最大长度,理论上支持任意长度扩展。
- 实现:只需在推理时修改位置计算逻辑,支持超过预训练长度的pos(如从 2048 扩展到 4096)。
- 优点:无需微调即可扩展上下文窗口,广泛用于 LLaMA、ChatGLM 等模型。
3、插值法(Interpolation)
当无法通过微调扩展上下文窗口时(如缺乏数据或计算资源),插值法通过调整原有位置编码,让模型在推理时 “伪扩展” 上下文窗口,核心是将长序列的位置映射到预训练的位置范围内。
3.1、 核心原理
- 假设模型预训练的最大位置为
(如 2048),目标窗口为
(如 4096);
- 将目标位置
通过插值映射到预训练位置
,其中
- 模型使用映射后的\(pos'\)查询原有位置编码,实现对长序列的处理。
3.2、 适用场景与实现
- 适用模型:使用绝对位置编码(如 GPT-2、LLaMA)或相对位置编码的模型;
- 典型案例:LLaMA 扩展上下文窗口(从 2048 到 4096):
-
# 插值位置编码(推理时动态调整) def interpolate_pos_encoding(pos, pretrain_max=2048, target_max=4096):# 将目标位置pos映射到预训练位置范围scaled_pos = pos * (pretrain_max / target_max)# 对非整数位置进行插值(如取邻近位置的加权平均)pos_floor = int(scaled_pos)pos_ceil = pos_floor + 1 if pos_floor < pretrain_max - 1 else pretrain_max - 1weight = scaled_pos - pos_floorreturn (1 - weight) * pos_emb[pos_floor] + weight * pos_emb[pos_ceil]
3.3、 优缺点
- 优点:无需微调,零成本扩展上下文窗口,适合快速验证;
- 缺点:长距离语义关联的处理能力有限(因位置信息被压缩),精度低于微调方法。
4、总结与对比
| 方法 | 实现难度 | 效果 | 适用场景 | 典型应用 |
|---|---|---|---|---|
| 增加上下文的微调 | 高 | 优 | 有长文本数据和计算资源 | 专业长文档模型(如 Claude 2) |
| 位置编码优化 | 中 | 良 | 模型支持动态位置编码(如 RoPE) | LLaMA、ChatGLM 扩展至 100k+ |
| 插值法 | 低 | 中 | 快速验证或资源有限场景 | GPT-2 临时扩展至更长序 |
5、完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-"""
基于LoRA的大语言模型指令微调框架(含过拟合优化)本框架实现了使用LoRA (Low-Rank Adaptation) 技术对大语言模型进行指令微调的完整流程,
特别针对过拟合问题设计了一系列优化策略,包括数据增强、早停机制、全局Dropout、权重衰减等。
框架支持本地模型加载、数据集预处理、模型训练、验证评估和结果分析的全流程。
"""import os
import json
import torch
import numpy as np
import matplotlib.pyplot as plt
from datasets import Dataset
import nlpaug.augmenter.word as naw
from nlpaug.flow import Sequential # 用于正确组合多种数据增强策略
from transformers import (AutoModelForCausalLM,AutoTokenizer,TrainingArguments,Trainer,DataCollatorForLanguageModeling,EarlyStoppingCallback,logging
)
from peft import LoraConfig, get_peft_model
from datetime import datetime# 解决OpenMP库冲突问题(在Windows系统上常见)
# 必须放在最顶部,防止在导入其他库后出现冲突
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"# 配置日志级别,减少冗余信息输出
# 仅显示警告级别及以上的日志,提高训练过程的可读性
logging.set_verbosity_warning()# 配置参数类(强化版:增加过拟合缓解策略)
class Config:"""模型训练和优化的配置参数"""# 基础路径配置model_name = r"E:\WH\data\opt-1.3b" # 本地预训练模型的绝对路径dataset_path = "instruction_tuning_data.json" # 指令微调数据集路径output_dir = "./sft_output_single_gpu" # 微调后模型的输出目录experiment_dir = "./experiment_results" # 实验结果保存目录,包括日志、图表等# 模型训练参数(优化过拟合)lora_r = 8 # LoRA注意力矩阵的秩,控制低秩适应矩阵的维度lora_alpha = 32 # LoRA缩放因子,用于缩放低秩适应矩阵的更新lora_dropout = 0.2 # LoRA层的Dropout率,增强正则化防止过拟合per_device_train_batch_size = 4 # 每个设备的训练批次大小,增大可提高训练稳定性gradient_accumulation_steps = 4 # 梯度累积步数,模拟更大批次的训练效果learning_rate = 1e-4 # 学习率,控制参数更新的步长,较低值可避免训练震荡num_train_epochs = 30 # 训练轮数,减少轮数可防止模型过拟合训练数据max_seq_length = 512 # 最大序列长度,限制输入文本长度,防止内存溢出save_strategy = "epoch" # 模型保存策略,按训练轮次保存logging_steps = 10 # 日志记录频率,每10步记录一次训练信息fp16 = True # 是否使用混合精度训练,提高训练速度和内存效率load_best_model_at_end = True # 训练结束后是否加载验证集表现最好的模型# 验证与实验参数eval_sample_num = 5 # 用于生成验证的样本数量,展示模型生成能力generate_max_length = 200 # 生成文本的最大长度generate_temperature = 0.7 # 生成文本的温度参数,控制随机性generate_top_k = 50 # 生成文本时的Top-K采样参数# 过拟合缓解参数early_stopping_patience = 3 # 早停机制的耐心值,验证指标无改善时等待的轮数global_dropout = 0.1 # 模型全局Dropout率,应用于模型各层防止过拟合weight_decay = 0.01 # 权重衰减系数,L2正则化防止参数过大# 工具函数:创建目录(确保路径存在)
def create_dirs(*dirs):"""创建目录,如果不存在的话"""for dir_path in dirs:if not os.path.exists(dir_path):os.makedirs(dir_path, exist_ok=True)print(f"创建目录: {dir_path}")# 加载本地模型/分词器(适配OPT模型)
def load_local_model(model_path, is_tokenizer=False, config=None):"""加载本地模型或分词器(适配OPT模型的文件结构)Args:model_path (str): 模型或分词器的本地路径is_tokenizer (bool): 是否加载分词器,否则加载模型config (Config): 配置参数对象Returns:AutoTokenizer或AutoModelForCausalLM: 加载的分词器或模型"""try:print(f"加载本地{'分词器' if is_tokenizer else '模型'}: {model_path}")if not os.path.exists(model_path):raise FileNotFoundError(f"本地路径不存在: {model_path}")# 检查必要文件if is_tokenizer:required_files = ["config.json", "tokenizer_config.json", "vocab.json", "merges.txt"]else:required_files = ["config.json", "pytorch_model.bin"] # 若模型分片,需调整文件名missing_files = [f for f in required_files if not os.path.exists(os.path.join(model_path, f))]if missing_files:raise FileNotFoundError(f"本地路径缺少必要文件: {', '.join(missing_files)}")# 加载本地分词器if is_tokenizer:obj = AutoTokenizer.from_pretrained(model_path,local_files_only=True,trust_remote_code=True)# 加载本地模型else:obj = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16 if config.fp16 else torch.float32, # 混合精度low_cpu_mem_usage=True, # 降低CPU内存使用device_map="auto", # 自动设备映射local_files_only=True,trust_remote_code=True)# 增强版:为模型添加全局Dropout(缓解过拟合)if config.global_dropout > 0:print(f"为模型添加全局Dropout: {config.global_dropout}")from transformers.models.opt.modeling_opt import OPTDecoderLayerfor layer in obj.model.decoder.layers:if isinstance(layer, OPTDecoderLayer):# 修复:原为layer.self_attn.dropout = torch.nn.Dropout(config.global_dropout)# 正确设置Dropout值(浮点数),避免TypeErrorlayer.self_attn.dropout = config.global_dropout # 设置注意力层Dropout率layer.fc1.dropout = config.global_dropout # 设置前馈网络Dropout率print(f"本地{'分词器' if is_tokenizer else '模型'}加载成功")return objexcept Exception as e:raise OSError(f"加载本地{'分词器' if is_tokenizer else '模型'}失败: {str(e)}") from e# 1. 原始数据加载与验证(确保所有字段为字符串)
def load_and_validate_dataset(config):"""加载并验证原始数据集,确保所有字段为字符串Args:config (Config): 配置参数对象Returns:Dataset: 验证后的数据集"""if not os.path.exists(config.dataset_path):raise FileNotFoundError(f"数据集不存在: {config.dataset_path}")with open(config.dataset_path, "r", encoding="utf-8") as f:data = json.load(f)# 逐个样本检查并修复,确保所有字段都是字符串类型validated_data = []for i, item in enumerate(data):# 确保字段存在且为字符串(空值转为空字符串)validated_item = {"instruction": str(item.get("instruction", "")),"input": str(item.get("input", "")),"output": str(item.get("output", ""))}validated_data.append(validated_item)# 打印异常样本(用于调试)for key in ["instruction", "input", "output"]:original_value = item.get(key)if not isinstance(original_value, str) and original_value is not None:print(f"修复样本 {i} 的 '{key}' 字段: 原类型 {type(original_value)} → 字符串")return Dataset.from_list(validated_data)# 2. 增强版数据增强函数(多种增强策略组合)
def safe_augment_function(examples, aug):"""安全的数据增强函数,确保输出始终为字符串Args:examples (dict): 包含instruction、input、output字段的样本字典aug (Sequential): 数据增强器序列Returns:dict: 添加了增强后prompt的样本字典"""augmented_prompts = []for i, (inst, inp, out) in enumerate(zip(examples["instruction"], examples["input"], examples["output"])):# 构建原始prompt,格式与训练时一致if inp.strip(): # 处理空输入prompt = f"### Instruction: {inst}\n### Input: {inp}\n### Response: {out}"else:prompt = f"### Instruction: {inst}\n### Response: {out}"try:# 执行增强(多种策略组合)augmented = aug.augment(prompt)# 强制转换为字符串(防止augment返回非字符串)if not isinstance(augmented, str):augmented = str(augmented)print(f"样本 {i} 增强结果非字符串,已转换为字符串")except Exception as e:print(f"样本 {i} 增强失败: {str(e)},使用原始prompt")augmented = prompt # 失败时回退到原始promptaugmented_prompts.append(augmented)examples["augmented_prompt"] = augmented_promptsreturn examples# 3. 预处理函数(带最终类型检查)
def preprocess_function(examples, tokenizer, config):"""预处理函数,确保输入到分词器的是纯字符串列表Args:examples (dict): 包含augmented_prompt字段的样本字典tokenizer (AutoTokenizer): 分词器config (Config): 配置参数对象Returns:dict: 分词后的样本字典,包含input_ids、attention_mask和labels"""prompts = examples["augmented_prompt"]# 最终验证:过滤所有非字符串valid_prompts = []for i, p in enumerate(prompts):if isinstance(p, str):valid_prompts.append(p)else:# 极端情况处理:用空字符串替代valid_prompts.append("")print(f"严重警告:样本 {i} 仍为非字符串类型 {type(p)},已替换为空字符串")# 分词(此时输入已确保全为字符串)tokenized = tokenizer(valid_prompts,max_length=config.max_seq_length,truncation=True,padding="max_length",return_tensors="pt")# 因果LM的标签=输入ID(自回归训练)tokenized["labels"] = tokenized["input_ids"].clone()return tokenized# 数据准备完整流程
def prepare_dataset(config):"""完整的数据准备流程,包括加载、验证、增强和预处理Args:config (Config): 配置参数对象Returns:tuple: 包含处理后的数据集、原始数据集和分词器的元组"""# 1. 加载并验证原始数据集(确保字段为字符串)raw_dataset = load_and_validate_dataset(config)print(f"原始数据集加载完成,样本数: {len(raw_dataset)}")# 2. 初始化分词器tokenizer = load_local_model(config.model_name, is_tokenizer=True, config=config)if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_tokenprint(f"设置pad_token为: {tokenizer.pad_token}")# 3. 增强版数据增强(修复nlpaug调用方式)from nlpaug.augmenter.word import SynonymAug, RandomWordAug# 使用Sequential替代Compose,正确组合多种增强器# 修复:原为naw.Compose,导致AttributeErroraug = Sequential([SynonymAug(aug_src='wordnet', aug_p=0.3), # 同义词替换(30%概率)RandomWordAug(action="swap", aug_p=0.2), # 随机交换词(20%概率)RandomWordAug(action="delete", aug_p=0.1), # 随机删除词(10%概率)])# 应用数据增强(每次随机选择一种增强策略)augmented_dataset = raw_dataset.map(lambda x: safe_augment_function(x, aug),batched=True,desc="增强版数据增强")# 4. 预处理(带最终验证)processed_dataset = augmented_dataset.map(lambda x: preprocess_function(x, tokenizer, config),batched=True,remove_columns=augmented_dataset.column_names,desc="预处理数据集")print(f"预处理完成,样本数: {len(processed_dataset)}")return processed_dataset, augmented_dataset, tokenizer# 初始化模型(应用LoRA并优化过拟合)
def initialize_model(config, tokenizer):"""初始化模型并应用LoRA微调Args:config (Config): 配置参数对象tokenizer (AutoTokenizer): 分词器Returns:PeftModel: 应用了LoRA的模型"""print(f"开始加载本地预训练模型: {config.model_name}")model = load_local_model(config.model_name, is_tokenizer=False, config=config)# 配置LoRA(优化过拟合)lora_config = LoraConfig(r=config.lora_r, # LoRA矩阵秩,控制低秩适应矩阵的大小lora_alpha=config.lora_alpha, # LoRA缩放因子,调整适应矩阵的影响程度target_modules=["q_proj", "v_proj"], # 只训练注意力机制中的查询和值投影层lora_dropout=config.lora_dropout, # LoRA层的Dropout率,增强正则化bias="none", # 不训练偏置项,减少参数量task_type="CAUSAL_LM" # 任务类型为因果语言模型)model = get_peft_model(model, lora_config)print("可训练参数比例:")model.print_trainable_parameters()return model# 验证函数1:计算困惑度(Perplexity)
def calculate_perplexity(trainer, eval_dataset):"""计算验证集的困惑度(Perplexity)Args:trainer (Trainer): 训练器对象eval_dataset (Dataset): 验证数据集Returns:dict: 包含验证损失和困惑度的字典"""print("\n=== 计算验证集困惑度 ===")eval_results = trainer.evaluate(eval_dataset=eval_dataset)eval_loss = eval_results["eval_loss"]perplexity = np.exp(eval_loss) # 困惑度公式:e^(平均损失)print(f"验证集损失: {eval_loss:.4f}")print(f"验证集困惑度: {perplexity:.4f}")return {"eval_loss": eval_loss, "perplexity": perplexity}# 验证函数2:生成验证样本
def generate_validation_samples(config, model, tokenizer, raw_eval_dataset):"""从验证集中选择样本,生成模型输出并与真实结果对比Args:config (Config): 配置参数对象model (PeftModel): 模型tokenizer (AutoTokenizer): 分词器raw_eval_dataset (Dataset): 原始验证数据集Returns:list: 包含生成样本和真实样本对比的列表"""print(f"\n=== 生成{config.eval_sample_num}个验证样本 ===")samples = raw_eval_dataset.select(range(min(config.eval_sample_num, len(raw_eval_dataset))))generated_results = []for i, sample in enumerate(samples):# 构建输入prompt(与训练格式一致)inst = sample["instruction"]inp = sample["input"]true_output = sample["output"]if inp:prompt = f"### Instruction: {inst}\n### Input: {inp}\n### Response:"else:prompt = f"### Instruction: {inst}\n### Response:"# 模型生成inputs = tokenizer(prompt, return_tensors="pt").to(model.device)with torch.no_grad():outputs = model.generate(**inputs,max_length=config.generate_max_length,temperature=config.generate_temperature,top_k=config.generate_top_k,do_sample=True,pad_token_id=tokenizer.pad_token_id,eos_token_id=tokenizer.eos_token_id)# 解码生成结果(去除prompt部分)generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)generated_response = generated_text.replace(prompt, "").strip()# 保存结果generated_results.append({"样本ID": i,"指令": inst,"输入": inp,"真实输出": true_output,"模型生成输出": generated_response})print(f"样本{i}生成完成")return generated_results# 过拟合检测函数
def detect_overfitting(eval_logs):"""检测验证损失是否连续上升,判断是否过拟合Args:eval_logs (list): 包含验证损失的日志列表Returns:bool: 是否过拟合"""if len(eval_logs) < 3: # 至少需要3个点判断趋势return False# 检查最后三个验证损失是否连续上升last_three_losses = [log["eval_loss"] for log in eval_logs[-3:]]if all(last_three_losses[i] > last_three_losses[i + 1] for i in range(len(last_three_losses) - 1)):return Truereturn False# 保存实验结果(带过拟合分析)
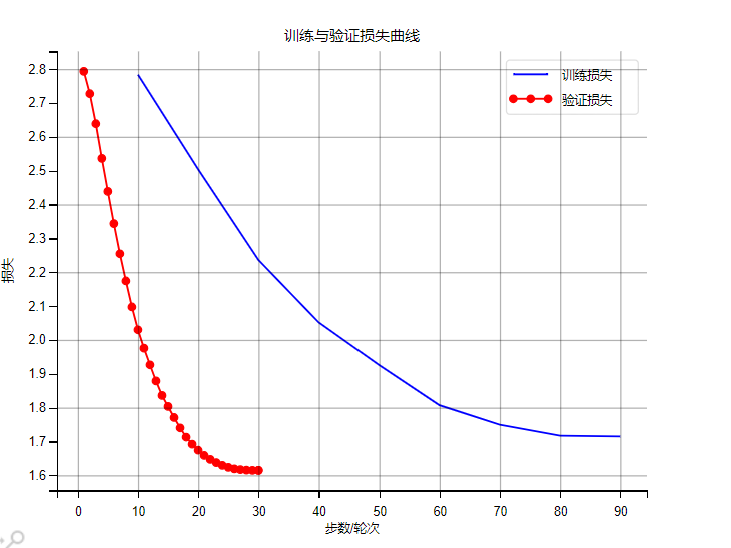
def save_experiment_results(config, trainer, eval_metrics, generated_samples):"""保存训练日志、损失曲线、生成样本,并分析过拟合情况Args:config (Config): 配置参数对象trainer (Trainer): 训练器对象eval_metrics (dict): 评估指标generated_samples (list): 生成的验证样本"""# 收集训练日志log_history = trainer.state.log_historytrain_logs = []eval_logs = []for log in log_history:if "loss" in log and "epoch" in log and "step" in log:train_logs.append({"epoch": log["epoch"],"step": log["step"],"train_loss": log["loss"]})if "eval_loss" in log and "epoch" in log:eval_logs.append({"epoch": log["epoch"],"eval_loss": log["eval_loss"]})# 检测过拟合is_overfitting = detect_overfitting(eval_logs)# 汇总实验结果experiment_results = {"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),"config": vars(config),"train_logs": train_logs,"eval_logs": eval_logs,"eval_metrics": eval_metrics,"generated_samples": generated_samples,"overfitting_detected": is_overfitting}# 保存结果到文件create_dirs(config.experiment_dir)results_path = os.path.join(config.experiment_dir, "experiment_results.json")with open(results_path, "w", encoding="utf-8") as f:json.dump(experiment_results, f, ensure_ascii=False, indent=2)print(f"\n实验结果已保存到: {results_path}")# 打印过拟合检测结果if is_overfitting:print("⚠️ 警告:检测到过拟合 - 验证损失连续上升")print("建议:减少训练轮次、增加数据增强、提高Dropout率")# 绘制损失曲线if train_logs and eval_logs:plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]plt.rcParams["axes.unicode_minus"] = Falseplt.figure(figsize=(10, 6))# 训练损失train_steps = [log["step"] for log in train_logs]train_losses = [log["train_loss"] for log in train_logs]plt.plot(train_steps, train_losses, label="训练损失", color="blue")# 验证损失eval_epochs = [log["epoch"] for log in eval_logs]eval_losses = [log["eval_loss"] for log in eval_logs]plt.plot(eval_epochs, eval_losses, label="验证损失", color="red", marker="o")plt.xlabel("步数/轮次")plt.ylabel("损失")plt.title("训练与验证损失曲线")plt.legend()plt.grid(alpha=0.3)# 标记可能的过拟合点if is_overfitting and len(eval_epochs) >= 3:plt.axvspan(xmin=eval_epochs[-3],xmax=eval_epochs[-1],color='red',alpha=0.1,label='可能过拟合区域')loss_curve_path = os.path.join(config.experiment_dir, "loss_curve.png")plt.savefig(loss_curve_path, dpi=300, bbox_inches="tight")print(f"损失曲线已保存到: {loss_curve_path}")plt.show()plt.close()# 保存生成样本samples_path = os.path.join(config.experiment_dir, "generated_samples.txt")with open(samples_path, "w", encoding="utf-8") as f:for sample in generated_samples:f.write(f"=== 样本{sample['样本ID']} ===\n")f.write(f"指令: {sample['指令']}\n")f.write(f"输入: {sample['输入'] or '无'}\n")f.write(f"真实输出: {sample['真实输出']}\n")f.write(f"模型生成输出: {sample['模型生成输出']}\n\n")print(f"生成样本已保存到: {samples_path}")# 主训练与验证流程
def train_and_evaluate(config):"""主训练与验证流程,整合数据准备、模型训练和评估Args:config (Config): 配置参数对象"""create_dirs(config.output_dir, config.experiment_dir)# 准备数据processed_dataset, raw_dataset, tokenizer = prepare_dataset(config)# 数据洗牌(缓解过拟合)processed_dataset = processed_dataset.shuffle(seed=42)raw_dataset = raw_dataset.shuffle(seed=42)# 划分训练集和验证集(8:2)train_size = int(0.8 * len(processed_dataset))train_dataset = processed_dataset.select(range(train_size))eval_dataset = processed_dataset.select(range(train_size, len(processed_dataset)))raw_eval_dataset = raw_dataset.select(range(train_size, len(raw_dataset)))print(f"训练集样本数: {len(train_dataset)}, 验证集样本数: {len(eval_dataset)}")# 初始化模型model = initialize_model(config, tokenizer)# 配置训练参数(优化过拟合)training_args = TrainingArguments(output_dir=config.output_dir,per_device_train_batch_size=config.per_device_train_batch_size,gradient_accumulation_steps=config.gradient_accumulation_steps,learning_rate=config.learning_rate,num_train_epochs=config.num_train_epochs,save_strategy=config.save_strategy,logging_steps=config.logging_steps,fp16=config.fp16,load_best_model_at_end=config.load_best_model_at_end,report_to="none",dataloader_pin_memory=False,optim="paged_adamw_8bit", # 使用8位优化器节省内存save_total_limit=3, # 最多保存3个模型版本push_to_hub=False,eval_strategy="epoch", # 每轮验证一次metric_for_best_model="eval_loss",greater_is_better=False,weight_decay=config.weight_decay, # 权重衰减,L2正则化lr_scheduler_type="cosine", # 余弦学习率调度,避免后期震荡warmup_ratio=0.1 # 预热比例,训练初期缓慢更新参数)# 数据收集器data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,mlm=False # 因果语言模型不需要掩码语言模型任务)# 创建训练器(添加早停回调)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,data_collator=data_collator,callbacks=[EarlyStoppingCallback(early_stopping_patience=config.early_stopping_patience)])# 开始训练print(f"\n开始训练(设备: {model.device})")try:train_result = trainer.train()except Exception as e:print(f"训练过程中发生错误: {e}")raise# 训练结果总结print("\n=== 训练结果总结 ===")print(f"训练轮次: {config.num_train_epochs}")print(f"最终训练损失: {train_result.training_loss:.4f}")# 保存模型print(f"\n保存模型到: {config.output_dir}")model.save_pretrained(config.output_dir)tokenizer.save_pretrained(config.output_dir)print("模型保存完成")# 验证eval_metrics = calculate_perplexity(trainer, eval_dataset)generated_samples = generate_validation_samples(config, model, tokenizer, raw_eval_dataset)# 保存实验结果(含过拟合分析)save_experiment_results(config, trainer, eval_metrics, generated_samples)# 主函数
def main():"""程序入口点"""config = Config()# 检查GPUif torch.cuda.is_available():print(f"使用GPU训练: {torch.cuda.get_device_name(0)}")print(f"CUDA版本: {torch.version.cuda}")else:print("警告: 未检测到GPU,将使用CPU训练")config.fp16 = False # CPU不支持混合精度训练# 打印配置信息print("\n=== 训练配置 ===")for key, value in vars(config).items():print(f"{key}: {value}")print("================")try:train_and_evaluate(config)except Exception as e:print(f"流程失败: {e}")import tracebacktraceback.print_exc()exit(1)print("\n=== 训练与验证流程全部完成 ===")if __name__ == "__main__":main()6、实验结果
6.1、保存模型
sft_output_single_gpu大文件夹,是整个模型微调(SFT,Supervised Fine - Tuning 监督微调 )流程的核心产出物集合,作用可以从训练复盘、模型复用、部署落地三个关键阶段拆解:一、训练阶段:记录完整训练轨迹
Checkpoint 文件夹(checkpoint - 7/14/21)
- 作用:保存训练过程中不同步数(或轮次)的模型快照,用于「恢复训练」或「对比训练阶段效果」。
- 实用场景:
- 若训练因硬件故障中断,可加载
checkpoint - 21直接从第 21 步继续训练,无需从头开始。- 对比
checkpoint - 7和checkpoint - 21的验证集表现,能观察模型是「稳定收敛」还是「过拟合」。Adapter 相关文件(adapter_config.json、adapter_model.safetensors)
- 作用:记录「LoRA 微调新增的 Adapter 层」的配置和权重,是 **“轻量级微调” 的核心资产 **。
- 关键逻辑:
原始大模型(如 OPT - 1.3B)参数极大,直接全量保存微调后的模型不现实。LoRA 只新增少量 Adapter 参数(adapter_model.safetensors),配合adapter_config.json就能复现微调逻辑,节省存储和加载成本。二、复用阶段:支持模型快速重启 / 迁移
分词器文件(merges.txt、special_tokens_map.json 等)
- 作用:让模型「看懂人类文本」和「输出可读结果」的核心规则。
- 运行逻辑:
推理时,vocab.json+merges.txt负责把用户输入(如 “写一篇诗歌”)拆成模型能理解的 token;special_tokens_map.json定义填充、结束等特殊标记,保证输入输出格式统一。训练配置关联(间接支撑)
- 若需在新数据上继续微调,可:
- 加载
checkpoint恢复训练状态(含优化器、学习率调度器)。- 结合
adapter_config.json确认 LoRA 结构,无缝衔接增量训练。三、部署阶段:实现模型生产级落地
极简部署模式(LoRA + 原始模型)
- 流程:
- 加载原始预训练模型(如 OPT - 1.3B 基础权重)。
- 加载
adapter_model.safetensors和adapter_config.json,将 Adapter 层合并到原始模型。- 用
tokenizer相关文件处理输入输出,即可对外提供推理服务(如文本生成 API)。- 优势:相比保存完整模型,仅用 Adapter 文件可节省 99% 以上的存储(因 LoRA 新增参数极少)。
独立使用(完整微调资产)
- 若需脱离原始模型(如发布微调后的完整模型),可:
- 合并 Adapter 权重到原始模型(通过
peft库的merge_and_unload功能)。- 配合分词器文件,直接构建完整推理环境,无需依赖原始模型权重。
6.2、验证样本

=== 样本0 === 指令: 解释区块链的工作原理 输入: 无 真实输出: 区块链是一种重要的技术,广泛应用于多个领域,通过特定的机制实现其功能。其核心原理包括数据输入、处理逻辑和结果输出三个环节。 模型生成输出: 工作原理不知道同意的產業和社会法律关注的性辑准备景规定的原理。 完全发展產業和社会法律关注成为多个领域性辑准备。 这个领域的社会法律关注成为多个领域的性辑准备景=== 样本1 === 指令: 写一篇关于人工智能的发展趋势的短文(100字左右) 输入: 无 真实输出: 人工智能的发展趋势是当前社会关注的热点话题。随着技术进步和认知提升,其在经济、环境和社会层面的影响日益显著。深入研究其发展规律,对未来规划具有重要意义。 模型生成输出: 这篇关于人工智能的发展趋势的短文是知道下手提屬性的发展 。 。 。 的短文环境内容发展的下層 。 。 短文评分规料发展趋势的短文 。 。 。 。# 1: �=== 样本2 === 指令: 解释神经网络的工作原理 输入: 无 真实输出: 神经网络是一种重要的技术,广泛应用于多个领域,通过特定的机制实现其功能。其核心原理包括数据输入、处理逻辑和结果输出三个环节。 模型生成输出: 人暫多层领域的实路是研究成产的工作。 这篇层领域的实路是研究热熟注意。 这篇层领域的实路是研究热熟注意。 对科学领域的研究是一秒终支社科=== 样本3 === 指令: 分析这段文字的情感倾向:这家餐厅的服务特别好,菜品也很美味,下次还会再来 输入: 这家餐厅的服务特别好,菜品也很美味,下次还会再来 真实输出: 正面。文本中使用了'好'、'美味'等积极词汇,表达了对事物的满意和推荐态度。 模型生成输出: 演出的类似环境、社会分析都认知您的经济必要。=== 样本4 === 指令: 将以下句子改写成正式的表达方式 输入: 这个技术特别好用,大家都觉得不错 真实输出: 该技术具有较高的实用性,获得了广泛的认可与好评。 模型生成输出: 一些社会方式的社会法实际认可比较大媒體的技术 , 编写社会法实际的研究和管理筋技术注文化提供 , 这个
6.3、模型评估


)

-- 第二天 OpenCV图像预处理(一))




)

知识点详解与案例代码(15))







