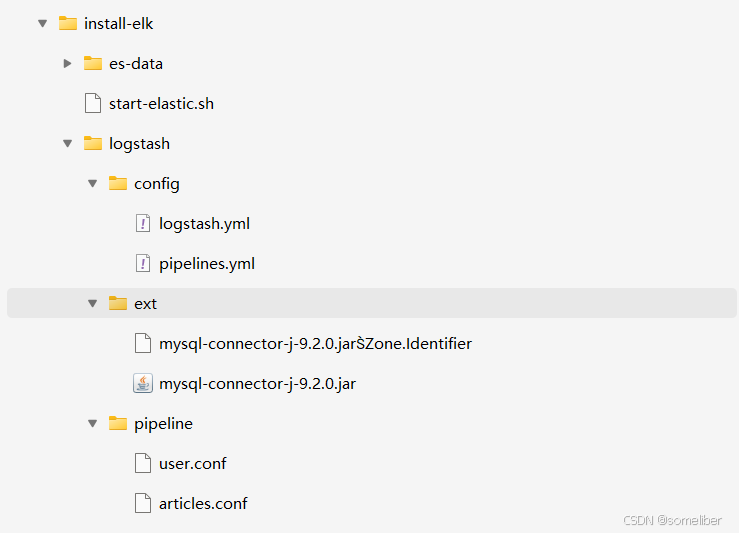
1. 项目结构
install-elk/
├── start-elastic.sh
├── es-data/ # Elasticsearch 持久化目录(自动创建)
├── logstash/├── logstash.yml├── pipeline/│ ├── user.conf│ ├── articles.conf│ └── ... #可以有更多的表├── config/│ └── pipelines.yml├── ext/│ └── mysql-connector-j-9.2.0.jar # 通过 https://downloads.mysql.com/archives/c-j/ 获取对应的版本。
1.1 本案例项目结构
1.2 start-elastic.sh
#!/bin/bash# ================== 🎨 Logo 开场 ==================
RED='\033[1;31m'
CYAN='\033[1;36m'
YELLOW='\033[1;33m'
RESET='\033[0m'echo -e "${CYAN}"
cat << "EOF"_____ _ _ _/ ____| | (_) || (___ ___ ___ _ __ _ __| |_| |_ ___ _ __\___ \ / _ \/ __| '__| '__| | | __/ _ \ '__|____) | __/ (__| | | | | | | || __/ ||_____/ \___|\___|_| |_| |_|_|\__\___|_|EOF
echo -e "${YELLOW} 🚀 Welcome to the someliber Elastic Stack 🚀${RESET}"
echo# ================== 获取版本号 ==================
read -p "请输入要使用的版本号(默认: 8.17.3): " VERSION_INPUT
VERSION=${VERSION_INPUT:-8.17.3}ES_IMAGE="elasticsearch:$VERSION"
KIBANA_IMAGE="kibana:$VERSION"
LOGSTASH_IMAGE="logstash:$VERSION"# ================== 获取密码 ==================
read -s -p "请输入 Elasticsearch 登录密码(默认: 123456): " PASSWORD_INPUT
echo
ES_PASSWORD=${PASSWORD_INPUT:-123456}
KIBANA_USER=kibana_user
KIBANA_PASS=someliber# ================== 是否挂载 ES 数据目录 ==================
read -p "是否挂载 Elasticsearch 数据目录?(y/n 默认 y): " USE_VOLUME
USE_VOLUME=${USE_VOLUME:-y}# ================== 基本变量 ==================
ES_CONTAINER_NAME=es11
KIBANA_CONTAINER_NAME=kibana11
LOGSTASH_CONTAINER_NAME=logstash11
NETWORK_NAME=elastic11
LOGSTASH_DIR="$PWD/logstash"
# ================== 创建网络 ==================
docker network create $NETWORK_NAME >/dev/null 2>&1 || echo "🔗 网络已存在:$NETWORK_NAME"# ================== 启动 Elasticsearch ==================
echo " 启动 Elasticsearch..."
if [[ "$USE_VOLUME" == "y" || "$USE_VOLUME" == "Y" ]]; thenmkdir -p ./es-datadocker run -d --name $ES_CONTAINER_NAME \--network $NETWORK_NAME \-p 9200:9200 -p 9300:9300 \-e "discovery.type=single-node" \-e "xpack.security.enabled=true" \-e "ELASTIC_PASSWORD=$ES_PASSWORD" \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-v "$PWD/es-data:/usr/share/elasticsearch/data" \$ES_IMAGE
elsedocker run -d --name $ES_CONTAINER_NAME \--network $NETWORK_NAME \-p 9200:9200 -p 9300:9300 \-e "discovery.type=single-node" \-e "xpack.security.enabled=true" \-e "ELASTIC_PASSWORD=$ES_PASSWORD" \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \$ES_IMAGE
fi# ================== 等待 ES 启动 ==================
echo " 正在等待 Elasticsearch 启动..."
for i in {1..60}; doSTATUS=$(curl -s -u elastic:$ES_PASSWORD http://localhost:9200/_cluster/health | grep -o '"status":"[^"]\+"' || true)if [[ $STATUS == *"green"* || $STATUS == *"yellow"* ]]; thenecho " Elasticsearch 启动成功:$STATUS"breakfisleep 2
done# ================== 创建 Kibana 用户 ==================
echo " 创建 Kibana 用户($KIBANA_USER)..."
docker exec $ES_CONTAINER_NAME bash -c "bin/elasticsearch-users useradd $KIBANA_USER -p $KIBANA_PASS -r kibana_system" || \echo " 用户可能已存在,忽略错误"# ================== 启动 Kibana ==================
echo " 启动 Kibana..."
docker run -d --name $KIBANA_CONTAINER_NAME \--network $NETWORK_NAME \-p 5601:5601 \-e "ELASTICSEARCH_HOSTS=http://$ES_CONTAINER_NAME:9200" \-e "ELASTICSEARCH_USERNAME=$KIBANA_USER" \-e "ELASTICSEARCH_PASSWORD=$KIBANA_PASS" \-e "XPACK_ENCRYPTEDSAVEDOBJECTS_ENCRYPTIONKEY=2kR9HmNaesytcVDwEAK3uTQ1obCrvP7B" \-e "XPACK_REPORTING_ENCRYPTIONKEY=aSTr3J7sLgt2BCKbIyw0DE6OjZGMY1kX" \-e "XPACK_SECURITY_ENCRYPTIONKEY=WO6Xetyubr45ZonlLd32DfNmRTkcAhvp" \-e "I18N_LOCALE=zh-CN" \$KIBANA_IMAGE# ================== 启动 Logstash(全目录挂载) ==================
if [[ -d "$LOGSTASH_DIR" ]]; thenecho " 启动 Logstash(全目录挂载)..."docker run -d --name $LOGSTASH_CONTAINER_NAME \--network $NETWORK_NAME \-p 5044:5044 -p 9600:9600 -p 5000:5000 \-e "xpack.monitoring.elasticsearch.hosts=http://$ES_CONTAINER_NAME:9200" \-e "xpack.monitoring.elasticsearch.username=elastic" \-e "xpack.monitoring.elasticsearch.password=$ES_PASSWORD" \-v "$PWD/logstash/pipeline:/usr/share/logstash/pipeline" \-v "$PWD/logstash/ext:/usr/share/logstash/ext" \-v "$PWD/logstash/config:/usr/share/logstash/config" \$LOGSTASH_IMAGEecho " Logstash 启动完成(使用 logstash/ 目录)"
elseecho " 未找到 logstash/ 目录,Logstash 未启动"
fi# ================== 提示 ==================
echo
echo -e "${CYAN} 所有容器启动完成!${RESET}"
echo -e "${YELLOW} Elasticsearch: http://localhost:9200${RESET}"
echo -e "${YELLOW} Kibana: http://localhost:5601${RESET}"
1.3 logstash/pipeline/user.conf
# ====================== 输入阶段:从 MySQL 中读取数据 ======================
input {jdbc {# MySQL JDBC 连接串jdbc_connection_string => "jdbc:mysql://192.168.167.175:3306/test"# 数据库账号和密码jdbc_user => "root"jdbc_password => "123456"# MySQL JDBC 驱动的路径(需要确保已经挂载进容器)jdbc_driver_library => "/usr/share/logstash/ext/mysql-connector-j-9.2.0.jar"# JDBC 驱动类名称jdbc_driver_class => "com.mysql.cj.jdbc.Driver"jdbc_paging_enabled => truejdbc_page_size => 10000# ========== 增量同步设置 ==========# 启用基于字段的增量同步use_column_value => true# 增量字段:用来判断是否有更新tracking_column => "updated_at"tracking_column_type => "timestamp"record_last_run => true# 记录上次同步时间的文件(容器中可写路径)last_run_metadata_path => "/usr/share/logstash/last_run_metadata/users_last_run.yml"# 执行的 SQL 语句:查所有新增、修改、逻辑删除的数据statement => "SELECTid,username,gender,email,age,created_at,updated_at,is_deletedFROM usersWHERE updated_at > :sql_last_valueORDER BY updated_at ASC, id ASC"# 每分钟执行一次同步任务(Cron 格式)schedule => "* * * * *"}
}# ====================== 过滤器阶段:处理数据逻辑 ======================
filter {# 如果 is_deleted = 1,则为“逻辑删除”,我们在元数据中标记 action 为 deleteif [is_deleted] and [is_deleted] in [1, "1", true, "true"] {mutate {add_field => { "[@metadata][action]" => "delete" }}} else {# 否则为“新增或更新”操作,标记 action 为 indexmutate {add_field => { "[@metadata][action]" => "index" }}}# 移除不希望写入 ES 的字段(如删除标记)mutate {remove_field => ["is_deleted"]}
}# ====================== 输出阶段:写入到 Elasticsearch ======================
output {elasticsearch {# Elasticsearch 地址hosts => ["http://es11:9200"]# 索引名称为 usersindex => "users"# ES 用户名和密码(需开启身份验证)user => "elastic"password => "123456"# 文档 ID 使用 MySQL 的主键 ID,避免重复写入document_id => "%{id}"# 根据前面 filter 设置的 action 决定是 index 还是 delete 操作action => "%{[@metadata][action]}"}# 控制台输出(调试用)stdout {codec => json_lines}
}
1.3 logstash/pipeline/articles.conf
# ====================== 输入阶段:从 MySQL 中读取文章数据 ======================
input {jdbc {# MySQL JDBC 连接串jdbc_connection_string => "jdbc:mysql://192.168.167.175:3306/test"# 数据库账号和密码jdbc_user => "root"jdbc_password => "123456"# MySQL JDBC 驱动的路径(需确保挂载到容器)jdbc_driver_library => "/usr/share/logstash/ext/mysql-connector-j-9.2.0.jar"# JDBC 驱动类名称jdbc_driver_class => "com.mysql.cj.jdbc.Driver"# 启用分页拉取数据,提高大数据量时性能jdbc_paging_enabled => truejdbc_page_size => 10000# ========== 增量同步设置 ==========use_column_value => true # 启用字段值来判断是否更新tracking_column => "updated_at" # 使用 updated_at 字段做增量对比tracking_column_type => "timestamp"record_last_run => truelast_run_metadata_path => "/usr/share/logstash/last_run_metadata/articles_last_run.yml"# SQL 查询语句,排除敏感字段,按更新时间 & ID 顺序拉取statement => "SELECTid,title,content,author_id,category,created_at,updated_at,is_deletedFROM articlesWHERE updated_at > :sql_last_valueORDER BY updated_at ASC, id ASC"# 同步频率:每分钟执行一次schedule => "* * * * *"}
}# ====================== 过滤器阶段:逻辑删除与字段处理 ======================
filter {# 如果 is_deleted = 1/true,标记 action 为 delete(逻辑删除)if [is_deleted] and [is_deleted] in [1, "1", true, "true"] {mutate {add_field => { "[@metadata][action]" => "delete" }}} else {# 否则表示新增或更新mutate {add_field => { "[@metadata][action]" => "index" }}}# 移除不希望写入 ES 的字段(如删除标记)mutate {remove_field => ["is_deleted"]}
}# ====================== 输出阶段:写入 Elasticsearch ======================
output {elasticsearch {hosts => ["http://es11:9200"]index => "articles"user => "elastic"password => "123456"document_id => "%{id}" # 使用文章主键作为文档 IDaction => "%{[@metadata][action]}" # 动态执行 index 或 delete}# 控制台调试输出(开发期使用)stdout {codec => json_lines}
}
1.4 logstash/config/pipelines.yml
# 定义第一个 pipeline(数据同步管道)
- pipeline.id: users # 唯一标识这个 pipeline 的 ID,日志中会看到 users 相关的信息path.config: "/usr/share/logstash/pipeline/user.conf"# 指定该 pipeline 使用的配置文件路径,里面写的是 input/filter/output# 定义第二个 pipeline
- pipeline.id: articles # 另一个独立的 pipeline ID,处理 articles 表的同步path.config: "/usr/share/logstash/pipeline/articles.conf"# 指定第二个 pipeline 的配置文件路径
1.5 logstash/config/logstash.yml
# ================================
# Logstash HTTP API 接口配置
# ================================api.http.host: 0.0.0.0 # Logstash API 绑定的主机地址,0.0.0.0 表示所有网卡
api.http.port: 9600 # Logstash HTTP API 的端口号,默认是 9600# ================================
# 配置自动加载(热加载)
# ================================config.reload.automatic: true # 开启配置文件自动热加载,无需重启即可更新 pipeline
config.reload.interval: 5s # 配置检查的时间间隔(单位:秒)# ================================
# Pipeline 性能调优参数
# ================================pipeline.batch.delay: 50 # 每个批次处理之间的最大等待时间(毫秒),默认 50ms
pipeline.batch.size: 125 # 每个批次处理的最大事件数量
pipeline.workers: 2 # 每个 pipeline 使用的 worker 线程数,建议和 CPU 核心数保持一致# ================================
# X-Pack 监控配置
# ================================xpack.monitoring.elasticsearch.hosts: ${xpack.monitoring.elasticsearch.hosts} # Elasticsearch 监控地址,从环境变量读取
xpack.monitoring.elasticsearch.username: ${xpack.monitoring.elasticsearch.username} # ES 认证用户名,从环境变量读取
xpack.monitoring.elasticsearch.password: ${xpack.monitoring.elasticsearch.password} # ES 认证密码,从环境变量读取
1.6 启动 start-elastic.sh
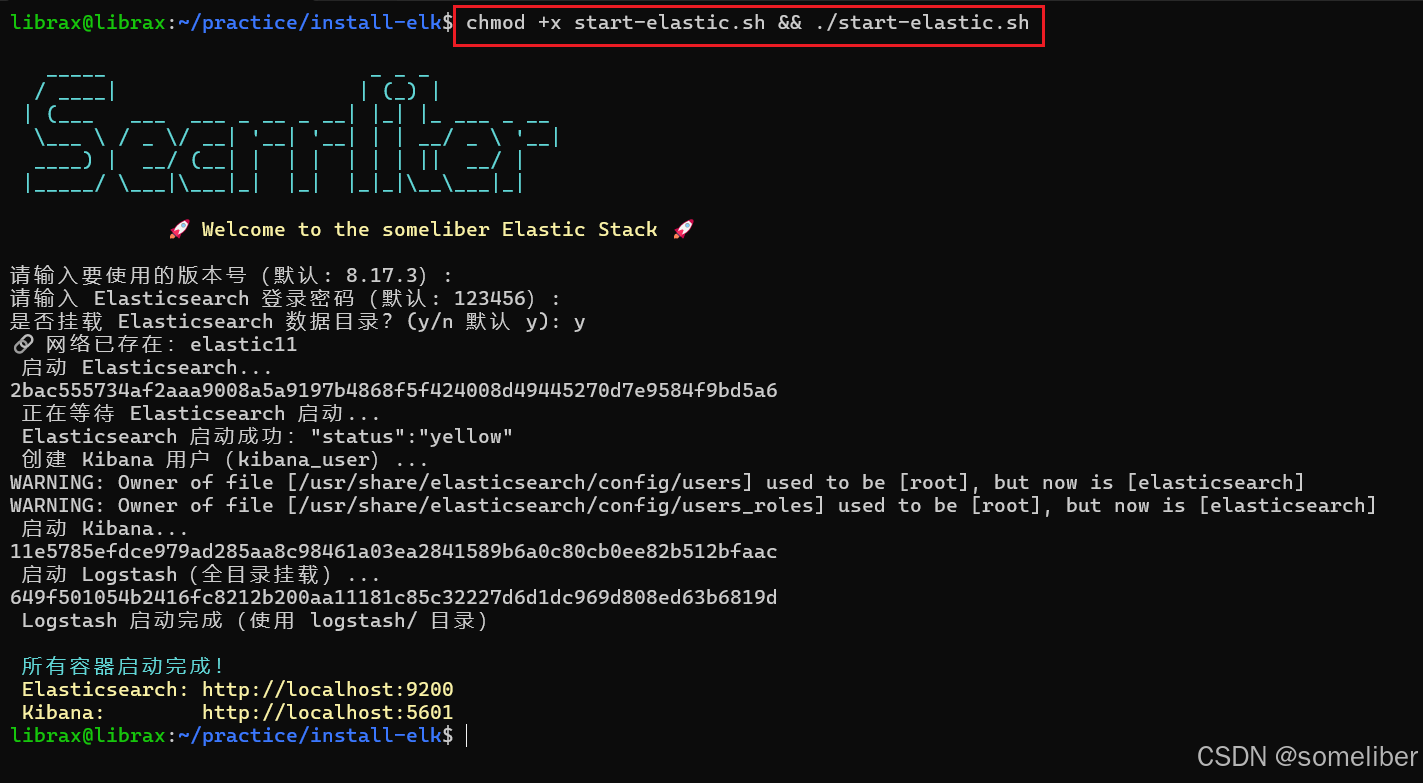
chmod +x start-elastic.sh && ./start-elastic.sh
1.7 数据库相关
1.7.1 用户信息表
CREATE TABLE users (id INT PRIMARY KEY AUTO_INCREMENT COMMENT '用户唯一标识',username VARCHAR(100) NOT NULL COMMENT '用户名',password VARCHAR(255) NOT NULL COMMENT '加密后的用户密码',gender ENUM('male', 'female', 'other') DEFAULT 'other' COMMENT '性别',email VARCHAR(255) COMMENT '用户邮箱',age INT COMMENT '年龄',created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '用户创建时间',updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',is_deleted BOOLEAN DEFAULT FALSE COMMENT '逻辑删除标记,TRUE 表示已删除'
) COMMENT='用户信息表';
1.7.2 文章信息表
CREATE TABLE articles (id INT PRIMARY KEY AUTO_INCREMENT COMMENT '文章唯一标识',title VARCHAR(255) NOT NULL COMMENT '文章标题',content TEXT COMMENT '文章内容正文',author_id INT NOT NULL COMMENT '作者ID,对应 users 表 id',category VARCHAR(100) COMMENT '文章分类',published_at DATETIME COMMENT '发布时间',created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '文章创建时间',updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',is_deleted BOOLEAN DEFAULT FALSE COMMENT '逻辑删除标记,TRUE 表示已删除'
) COMMENT='文章信息表';
1.7.3 测试数据
INSERT INTO users (username, password, gender, email, age, is_deleted)
VALUES
('Alice', 'hashed_password_1', 'female', 'alice@example.com', 28, FALSE),
('Bob', 'hashed_password_2', 'male', 'bob@example.com', 35, FALSE),
('Charlie', 'hashed_password_3', 'male', 'charlie@example.com', 22, FALSE),
('Diana', 'hashed_password_4', 'female', 'diana@example.com', 40, TRUE),
('Eve', 'hashed_password_5', 'other', 'eve@example.com', 30, FALSE);INSERT INTO articles (title, content, author_id, category, published_at, is_deleted)
VALUES
('Elasticsearch 入门', '这是关于 Elasticsearch 的基础教程内容。', 1, '技术', NOW(), FALSE),
('MySQL 优化实践', '介绍常见的 MySQL 优化技巧。', 2, '数据库', NOW(), FALSE),
('Logstash 配置指南', '如何配置 Logstash 管道同步数据。', 1, '日志系统', NOW(), FALSE),
('前端与后端的区别', '讲解 Web 开发中的前后端职责。', 3, 'Web开发', NULL, FALSE),
('已删除的文章示例', '这篇文章已被逻辑删除。', 4, '历史', NOW(), TRUE);
1.8 测试验证过程
1.8.1 启动start-elastic.sh
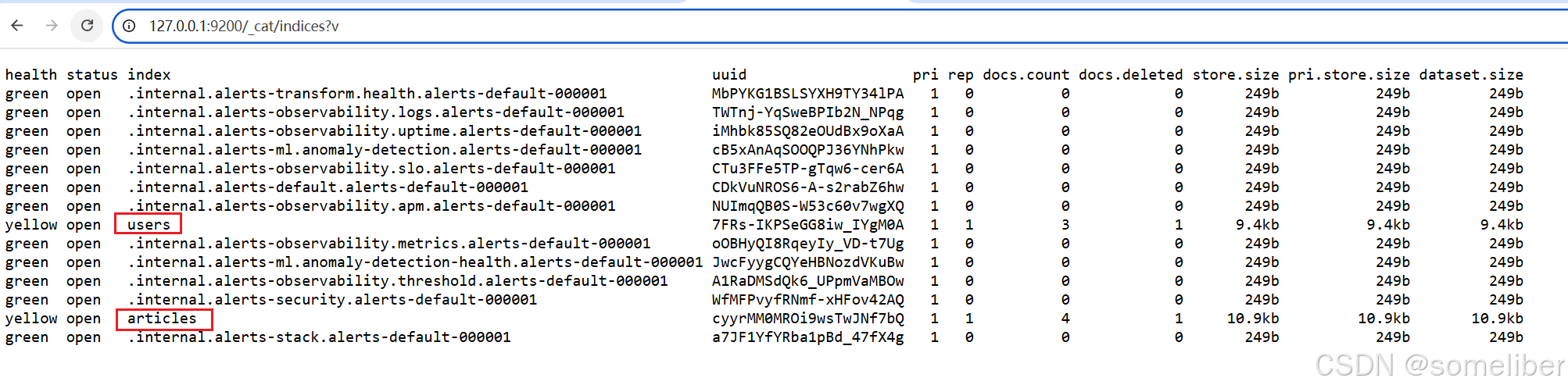
1.8.2 验证索引是否创建成功
1.8.3 进行删除测试
1.8.3.1 删除前

1.8.3.2 逻辑删除Alice用户

1.8.3.3 查看结果
说明:等待一分钟,可以看到users索引下的文档数量由4->3,即文档从ES中删除。

1.8.4 进行修改测试
1.8.4.1 修改前
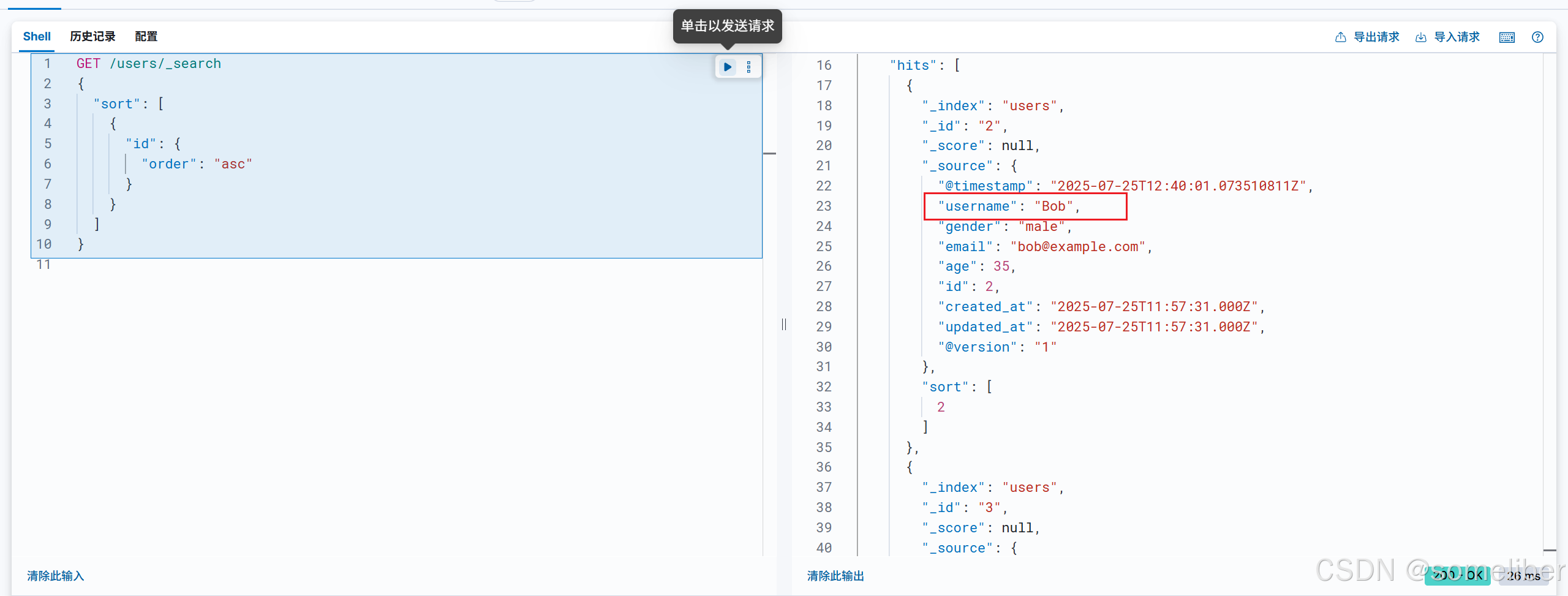
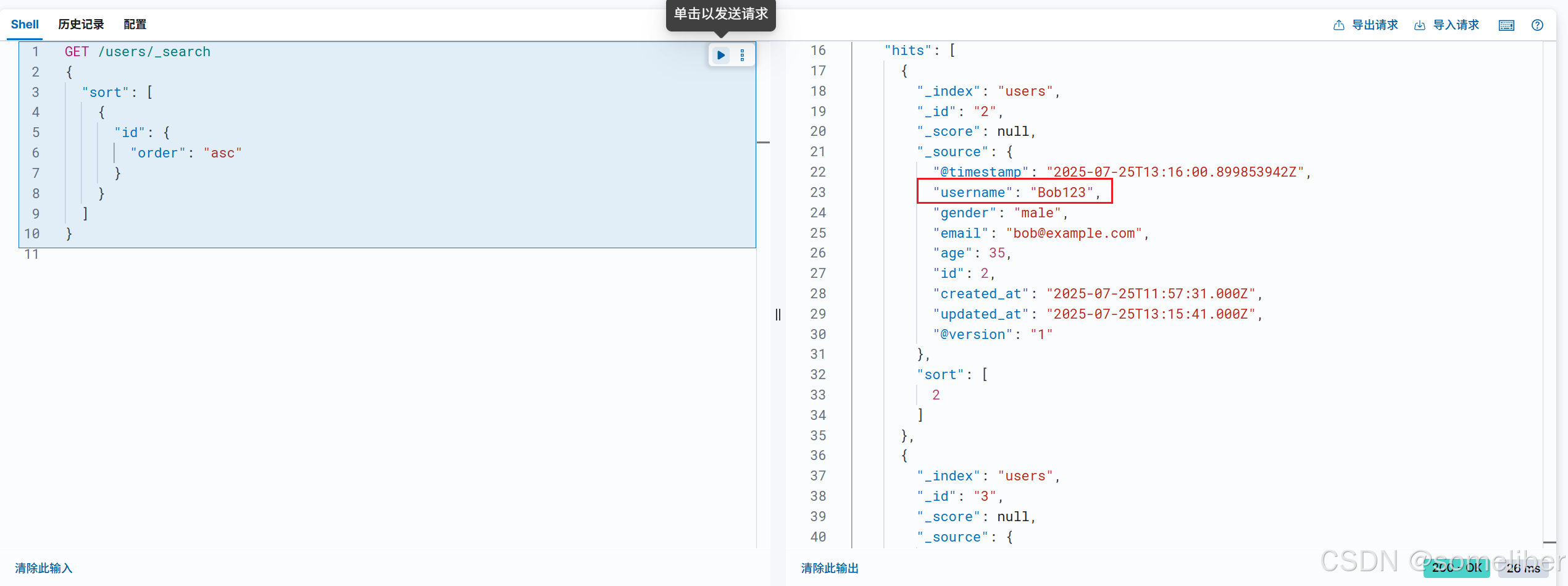
1.8.4.2 修改Bob为Bob123

1.8.4.3 查看修改结果
说明:等待一分钟,数据更新同步到ES文档。
2 总结
通过 Logstash 从 MySQL 中同步多个业务表(如 users、articles),并实现以下能力:
- 增量同步:基于
updated_at字段,避免全量拉取。 - 逻辑删除同步:使用
is_deleted字段自动触发 ES 删除操作。 - 定时同步:每分钟调度,适用于数据近实时场景。
- 多表配置隔离:每个表对应一个独立的 pipeline,实现清晰可维护结构。
- 全目录挂载:Logstash 配置、驱动、Pipeline 统一挂载,便于统一管理和部署。



)



![解决 SQL 错误 [1055]:深入理解 only_full_group_by 模式下的查询规范](http://pic.xiahunao.cn/解决 SQL 错误 [1055]:深入理解 only_full_group_by 模式下的查询规范)
)


)





:科技算力双子星)

