摘要
得益于Transformer模型的成功,近期研究开始探索其在3D医学分割任务中的适用性。在Transformer模型中,自注意力机制是核心构建模块之一,与基于局部卷积的设计相比,它致力于捕捉长距离依赖关系。然而,自注意力操作存在二次复杂度问题,这已成为计算瓶颈,尤其在体医学成像中——此类输入为3D形式且包含大量切片。本文提出一种3D医学图像分割方法,名为UNETR++,该方法既能生成高质量分割掩码,又在参数数量、计算成本和推理速度方面具备高效性。我们设计的核心是引入一种新型高效配对注意力(EPA)模块:该模块通过一对基于空间注意力和通道注意力的互依赖分支,高效学习空间和通道维度的判别性特征。我们提出的空间注意力公式具有高效性,其复杂度与输入呈线性关系。为实现空间聚焦分支与通道聚焦分支之间的信息交互,我们共享查询和键映射函数的权重——这不仅带来互补优势(配对注意力),还降低了整体复杂度。我们在五个基准数据集(Synapse、BTCV、ACDC、BraTS和Decathlon-Lung)上进行了大量评估,结果证实了所提方法在效率和准确性上的优势。在Synapse数据集上,UNETR++的Dice评分达到87.2%,刷新了当前最优性能;同时与文献中最佳方法相比,其参数数量和计算量(FLOPs)均减少了71%以上。我们的代码和模型可通过以下链接获取:https://tinyurl.com/2p87x5xn。
关键词——深度学习、高效注意力、混合架构、医学图像分割
INTRODUCTION
体素级(3D)分割是医学成像领域的基础性问题,具有众多应用场景,包括用于诊断目的的肿瘤识别和器官定位等[1][2]。该任务通常通过类U-Net[3]的编码器-解码器架构来解决:编码器生成3D图像的分层低维表征,解码器则将这种学习到的表征映射为体素级分割结果。早期基于CNN(卷积神经网络)的方法在编码器和解码器中分别使用卷积和反卷积操作,但难以获得精确的分割结果。近期有研究[4]尝试解决基于CNN方法的局限性——通过扩大CNN的感受野,增强其对上下文表征的建模能力。尽管在编码更优上下文表征方面取得了进展,但感受野有限、局部连接以及权重固定等问题,仍是基于CNN方法面临的挑战。这些挑战可能影响其捕捉广泛全局依赖关系的效果。此外,虽然基于3D CNN的方法通过权重共享实现了参数层面的高效性,但由于操作数量较多,其计算量(FLOPs)相应增加,推理速度也随之变慢,这是一种性能上的权衡。相比之下,基于Transformer的方法本身具有全局性,近期已展现出有竞争力的性能,但代价是模型复杂度提高。具体而言,这类方法依赖全局自注意力机制,而该机制的复杂度与输入呈二次关系。而且,在输入为3D体数据的体素级医学图像分割任务中,这种复杂度问题更为突出。
为解决这些挑战,探索融合CNN和Transformer优势的混合架构的研究热度日益上升。近期已有多项研究[1][5][6]尝试设计混合架构,以结合局部卷积和全局注意力的优点。其中,部分方法[1]采用基于Transformer的编码器搭配卷积解码器,另一些方法[5][6]则致力于为编码器和解码器子网络设计混合模块。然而,这些研究主要聚焦于提高分割精度,这反过来导致模型在参数数量和计算量(FLOPs)上大幅增加,稳健性不尽如人意。我们认为,这种不理想的稳健性可能源于其低效的自注意力设计——这在体素级医学图像分割任务中问题更为明显。此外,现有方法未能捕捉空间特征与通道特征之间的显式依赖关系,而这种依赖关系本可以提升分割质量。在本研究中,我们旨在通过一个统一框架,同时提高分割精度和模型效率。
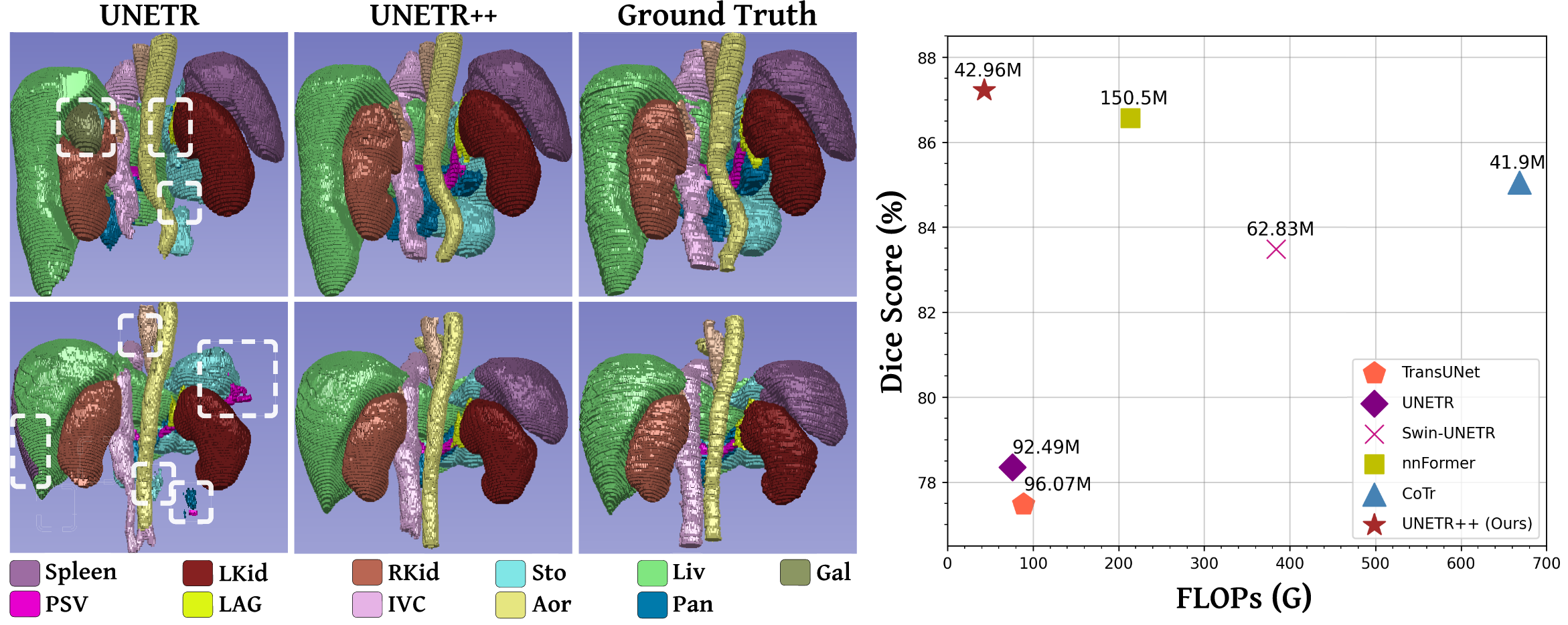
右图:Synapse数据集上准确率(Dice评分)与模型复杂度(FLOPs和参数数量)的对比。与nnFormer [5]相比,UNETR++实现了更优的分割性能,同时将模型复杂度显著降低71%以上。
A. Contributions
我们提出了一种用于3D医学图像分割的高效混合分层架构,名为UNETR++。该架构力求在分割精度以及参数数量、计算量(FLOPs)、GPU内存消耗和推理速度等效率相关方面均实现提升。我们提出的UNETR++分层方法以近期的UNETR框架[1]为基础,引入了一种新型高效配对注意力(EPA)模块。该模块通过在两个分支中分别应用空间注意力和通道注意力,高效捕捉丰富的、互相关联的空间特征与通道特征。EPA中的空间注意力将键(keys)和值(values)投影到固定的低维空间,使得自注意力计算的复杂度与输入标记(tokens)数量呈线性关系。另一方面,EPA中的通道注意力通过在通道维度上对查询(queries)和键执行点积运算,着重捕捉通道特征图之间的依赖关系。此外,为了强化空间特征与通道特征之间的关联性,两个分支共享查询和键的权重——这同时还有助于控制网络的参数数量。与之相对,值的权重保持独立,以确保两个分支能够学习到互补的特征。
UNETR++相比现有方法具有显著优势:它大幅降低了GPU内存消耗,同时提升了推理速度并减少了计算量。这一点对于3D分割任务至关重要,因为此类任务本身复杂度较高。例如,与nnFormer[5]相比,UNETR++不仅性能更优,GPU推理速度提升2.4倍,GPU内存消耗减少5倍,计算量减少6倍;与Swin-UNETR[6]相比,UNETR++的推理速度提升3.6倍,GPU内存消耗和计算量均减少8倍;此外,相较于高效的基于CNN的方法nnUNet[2],UNETR++的内存消耗降低35%,计算量减少6倍。我们优先考虑高效的资源利用,从而在CPU和GPU上均实现了更快的推理速度。而且我们认为,上述这些混合方法难以有效捕捉特征通道之间的相互依赖关系,因此无法获得同时编码空间信息和通道间特征依赖的丰富特征表征。在本研究中,我们致力于在一个统一的混合分割框架中集中解决上述问题。
我们进行了全面评估,以检验UNETR++在五个广泛使用的基准数据集上的性能,包括Synapse[7]、BTCV[7]、ACDC[8]、BraTS[9]和Decathlon-Lung[10]。评估结果证实了我们所提方法在效率和精度上的有效性,也体现出UNETR++在不同模态(包括CT扫描和MRI)的多样化数据集上具有出色的泛化能力。在Synapse数据集上,UNETR++的Dice评分为87.2%,与现有最优方法[5]相比,参数数量和计算量均显著减少71%以上;在ACDC数据集上,UNETR++的平均Dice评分为93.83%,比近期提出的MexNeXt[4]高出1.4%;在BraTS和Decathlon-Lung分割任务中,UNETR++在三项评估指标上均优于当前最优方法,在实现更优分割性能的同时,还具备更快的推理速度,且对GPU内存的需求显著降低。
II. RELATED WORK
A. CNN-Based Segmentation Methods
自U-Net设计[3]提出以来,多种基于CNN的方法[11]、[12]、[13]、[14]对标准U-Net架构进行了扩展,以适用于各类医学图像分割任务。在3D医学图像分割领域[15]、[16]、[17]、[18]、[19],完整的体素图像通常被当作一系列2D切片来处理。已有多项研究探索了用于捕捉上下文信息的分层框架。Milletari等人[18]提出对体素图像进行下采样以降低分辨率,通过这种3D表征方式保留有益的图像特征。Çiçek等人[17]将U-Net架构扩展到体素分割任务中,用3D操作替代2D操作,并从稀疏标注的体素图像中学习特征。Isensee等人[2]提出了名为nnUNet的通用分割框架,该框架能自动配置架构,以提取多尺度特征。Roth等人[20]设计了多尺度3D全卷积网络,用于从不同分辨率的图像中学习表征,实现多器官分割。此外,文献中已有多项研究尝试在基于CNN的框架中编码整体上下文信息,例如借助图像金字塔[21]、大卷积核[22]、空洞卷积[23]和可变形卷积[24]等方式。近期,Roy等人[4]提出了名为MedNeXt的全卷积3D编解码器网络。该架构是ConNeXt框架[25]的扩展版本,融合了自适应核大小与残差连接,旨在数据有限的3D医学成像场景中提升分割精度。尽管MedNeXt-M-K3[4]展现出了良好的精度表现,但其代价是GPU内存消耗较nnUNet[2]增加了4.1倍,导致GPU和CPU的推理速度显著变慢。
B. Transformers-Based Segmentation Methods
视觉Transformer(ViT)近年来备受关注,这得益于其编码长距离依赖关系的能力——该能力使其在包括分类[26]和检测[27]在内的各类视觉任务中均取得了良好效果。Transformer架构的核心构建模块之一是自注意力操作,它能对图像块序列间的交互进行建模,进而学习全局关联。近期已有少量研究[28]、[29]、[30]、[31]尝试在Transformer框架中缓解标准自注意力操作的复杂度问题。然而,这些研究大多聚焦于分类任务,尚未在密集预测任务中展开探索。
在医学图像分割领域,近期仅有少数研究[32]、[33]对纯Transformer设计进行了探索。Karimi等人[32]提出将体素图像划分为3D块,随后将这些块展平以构建1D嵌入,并将其输入主干网络以获取全局表征。Cao等人[33]则针对2D医学图像分割提出了一种含移位窗口的架构:先将图像划分为块,再将其输入U形编码器-解码器以进行局部-全局表征学习。
C. Hybrid Segmentation Methods
除了纯CNN或基于Transformer的设计之外,近期多项研究[1]、[5]、[19]、[34]、[35]、[36]探索了混合架构,通过结合卷积与自注意力操作来实现更优的分割效果。TransFuse[34]提出了一种并行的CNN-Transformer架构,该架构配备BiFusion模块,用于在编码器中融合多尺度特征。MedT[19]在自注意力中引入门控位置敏感轴向注意力机制,以控制编码器中的位置嵌入信息,同时解码器中的ConvNet模块生成分割模型。TransUNet[35]将Transformer与U-Net架构相结合——Transformer对来自卷积特征的嵌入图像块进行编码,解码器则将上采样后的编码特征与高分辨率CNN特征融合以实现定位。Ds-transunet[36]采用基于Swin Transformer[37]的双尺度编码器,用于处理多尺度输入,并通过自注意力从不同语义尺度编码局部和全局特征表征。Hatamizadeh等人[1]提出了3D混合模型UNETR,该模型将Transformer的长距离空间依赖能力与CNN的归纳偏置融入“U形”编码器-解码器架构。UNETR中的Transformer块主要用于编码器,以提取固定的全局表征,随后在多个分辨率下与基于CNN的解码器融合。Zhou等人[5]提出了名为nnFormer的方法,该方法对SwinUNet[33]架构进行了适配:卷积层将输入扫描图像转换为3D块,并引入基于体数据的自注意力模块来构建分层特征金字塔。尽管nnFormer取得了良好的性能,但与UNETR及其他混合方法相比,其计算复杂度显著更高。CoTr[38]是一种混合架构,由CNN编码器和高效可变形Transformer组成——卷积编码器提取局部特征图,可变形Transformer仅关注少数关键位置,并对提取到的特征表征中的部分依赖关系进行编码。
如上所述,UNETR[1]、nnFormer[5]等多数近期混合方法相较于纯CNN和纯Transformer方法,分割性能有所提升。然而我们注意到,这些混合方法为提高分割精度,付出了模型规模(从参数数量和计算量(FLOPs)来看)大幅增加的代价,这可能进一步导致稳健性不佳。例如,UNETR虽取得了理想的精度,但与现有最优的基于CNN的nnUNet[2]相比,其参数数量多出2.5倍;而nnFormer虽性能优于UNETR,但参数数量进一步增加1.6倍,计算量(FLOPs)增加2.8倍。
D. Efficient Attention Methods
近年来,为2D视觉应用设计高效注意力模块受到了广泛关注。CBAM[39]是一种基于卷积神经网络的高效注意力模块,该模块对特征图沿空间和通道维度进行高效处理,随后将生成的注意力图与输入特征图相乘,从而实现自适应特征优化。尽管我们提出的EPA模块也对通道和空间信息进行编码,但EPA模块与CBAM存在重大差异:(1)CBAM通过两个串行子模块对空间表征和通道表征进行编码,而EPA模块则采用并行方式对二者进行编码;(2)EPA模块中的通道注意力和空间注意力基于注意力机制构建,而CBAM的注意力则基于池化和卷积操作;(3)CBAM中的通道注意力和空间注意力拥有独立的权重矩阵,而在EPA中,我们共享查询(Q)和键(K)矩阵的权重——这种共享机制通过仅学习互补特征,将参数数量减少了25%,同时将性能提升了0.23%。
Transformer-CBAM[40]是对CBAM[39]的增强版本,它通过集成多尺度Transformer模块,实现了对不同尺度上下文信息的建模,因此在遥感图像变化检测任务中尤为有效。Squeeze-and-Excitation(SE)[41]则聚焦于通道特征图之间的关系,其提出的“挤压-激励”(SE)模块通过显式捕捉通道间的相互依赖关系,对特定通道的特征图进行重新调整。Attention Gated U-Net[42]对U-Net[3]架构进行了扩展,为医学成像场景引入了注意力门控(AG)模块——该AG模块通过不同的门控机制学习对不同形状和大小的目标结构进行优先级排序,且计算开销极小。
尽管上述多数方法在效率和准确性之间取得了良好的平衡,但它们主要是为2D视觉任务设计的。为验证所提EPA模块在3D医学分割场景中的有效性,我们通过将EPA模块替换为这些高效方法的3D对应版本进行了实验,相关细节详见表IX。
III. METHOD
A. Overall Architecture
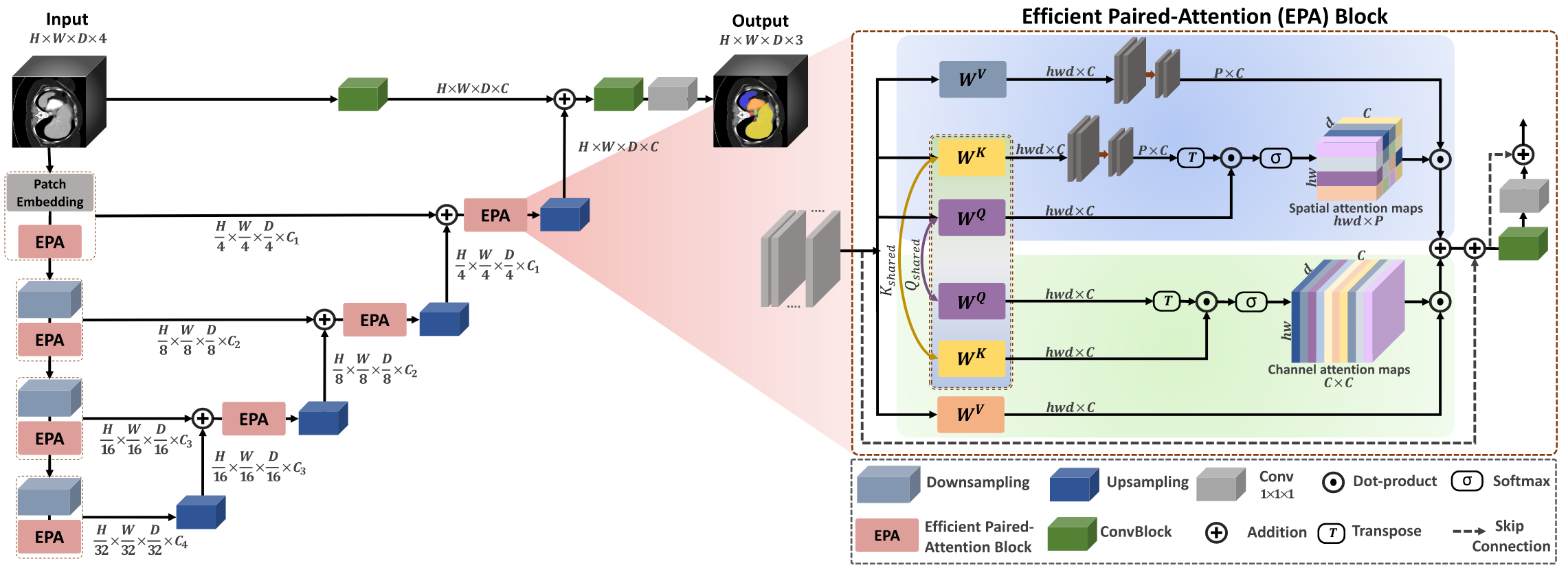
图2展示了我们的UNETR++架构,该架构包含分层的编码器-解码器结构。我们的UNETR++框架以近期提出的UNETR[1]为基础,在编码器和解码器之间设有跳跃连接,后续通过卷积模块(ConvBlocks)生成预测掩码。与在整个编码器中使用固定特征分辨率的设计不同,UNETR++采用分层设计——在每个阶段,特征分辨率会以2倍的比例逐步降低。
在UNETR++框架中,编码器包含4个阶段,这4个阶段的通道数分别为[C1, C2, C3, C4]。第一阶段由补丁嵌入(patch embedding)和我们提出的新型高效配对注意力(EPA)模块组成:补丁嵌入会将体素输入分割为3D补丁,具体而言,将3D输入(体数据)x ∈ R^H×W×D分割为非重叠的补丁xu ∈ R^N×(P1,P2,P3),其中(P1, P2, P3)为每个补丁的分辨率,N = (H/P1 × W/P2 × D/P3)表示序列长度;随后,这些补丁被投影到C个通道维度,生成尺寸为H/P1 × W/P2 × D/P3 × C的特征图。我们采用与文献[5]相同的补丁分辨率(4, 4, 2)。对于编码器的其余每个阶段,我们先通过非重叠卷积下采样层将分辨率降低2倍,再接入EPA模块。
在我们提出的UNETR++中,每个EPA模块包含两个注意力子模块。它们通过共享键-查询(keys-queries)机制对空间和通道维度的信息进行编码,从而高效学习丰富的空间-通道特征表征。编码器各阶段通过跳跃连接与解码器各阶段相连,以融合不同分辨率下的输出——这能够恢复下采样操作中丢失的空间信息,进而得到更精确的预测结果。
与编码器类似,解码器也包含4个阶段。每个解码器阶段先通过反卷积上采样层将特征图分辨率提高2倍,再接入EPA模块(最后一个解码器阶段除外)。相邻两个解码器阶段之间的通道数以2倍的比例减少。因此,最后一个解码器的输出会与卷积特征图融合,以恢复空间信息并增强特征表征能力。融合后的输出随后被输入至3×3×3和1×1×1卷积模块,生成体素级的最终掩码预测。接下来,我们将详细介绍EPA模块。
B. Efficient Paired-Attention Block
如前所述,大多数现有混合方法所采用的自注意力操作,其复杂度与标记(tokens)数量呈二次关系。这在体素分割任务中计算成本极高,而当在混合设计中交错使用窗口注意力和卷积组件时,问题会更为突出。此外,通过将键(keys)和值(values)的空间矩阵投影到低维空间,可高效学习空间注意力信息。有效结合空间维度的交互关系与通道特征间的依赖关系,能够得到丰富的上下文空间-通道特征表征,进而提升掩码预测效果。
所提出的EPA模块可执行高效全局注意力计算,并有效捕捉丰富的空间-通道特征表征。该模块包含空间注意力子模块和通道注意力子模块:空间注意力子模块将自注意力的复杂度从二次降至线性;通道注意力子模块则高效学习通道特征图之间的依赖关系。EPA模块通过在两个注意力子模块之间共享键-查询(keys-queries)实现信息互通,从而生成更优且高效的特征表征。这可能得益于通过共享键和查询、同时使用不同值(value)层来学习互补特征。为增强训练稳定性,每个EPA模块的起始处均采用了层归一化(LayerNorm)操作。
如图2(右侧)所示,输入特征图x被送入EPA模块的通道注意力子模块和空间注意力子模块。查询(Q)和键(K)线性层的权重在两个注意力子模块之间共享,且每个注意力子模块使用不同的值(V)层。两个注意力子模块的计算方式如下:
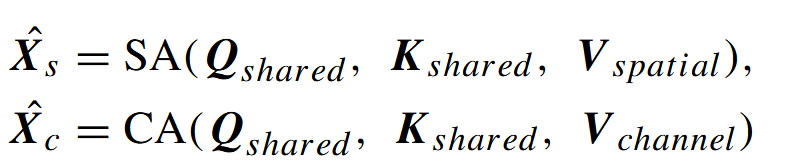
其中,X̂ₛ、X̂c、SAₛ和SAc分别表示空间注意力图、通道注意力图、空间注意力子模块和通道注意力子模块。Qₛₕₐᵣₑd、Kₛₕₐᵣₑd、Vₛₚₐₜᵢₐₗ和Vcₕₐₙₙₑₗ分别为共享查询矩阵、共享键矩阵、空间值层矩阵和通道值层矩阵。
1) 空间注意力:在该子模块中,我们致力于通过将复杂度从O(n²)降至O(np)来高效学习空间信息(其中n为标记数量,p为投影向量的维度,且p远小于n)。给定形状为hwd×C的归一化张量X,我们通过三个线性层计算Qₛₕₐᵣₑd(共享查询)、Kₛₕₐᵣₑd(共享键)和Vₛₚₐₜᵢₐₗ(空间值)的投影,得到Qₛₕₐᵣₑd=WᵅX、Kₛₕₐᵣₑd=WᵏX和Vₛₚₐₜᵢₐₗ=WᵛX(维度均为hwd×C)——其中Wᵅ、Wᵏ和Wᵛ分别为Qₛₕₐᵣₑd、Kₛₕₐᵣₑd和Vₛₚₐₜᵢₐₗ的投影权重。
之后,我们执行三个步骤:第一步,将Kₛₕₐᵣₑd和Vₛₚₐₜᵢₐₗ层从hwd×C投影到形状为p×C的低维矩阵;第二步,通过将Qₛₕₐᵣₑd层与投影后的Kₛₕₐᵣₑd的转置相乘,再经过softmax运算计算空间注意力图,以此衡量每个特征与其他空间特征之间的相似度;第三步,将这些相似度与投影后的Vₛₚₐₜᵢₐₗ层相乘,生成形状为hwd×C的最终空间注意力图。空间注意力的定义如下:
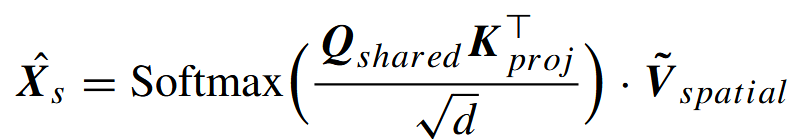
其中,Qₛₕₐᵣₑd(共享查询)、Kₚᵣₒⱼ(投影后的共享键)和Ṽₛₚₐₜᵢₐₗ(投影后的空间值层)分别表示共享查询矩阵、投影后的共享键矩阵和投影后的空间值层矩阵,d为每个向量的维度。
2) 通道注意力:该子模块通过在通道维度上对通道值层与通道注意力图执行点积运算,捕捉特征通道之间的依赖关系。我们使用与空间注意力子模块相同的Qₛₕₐᵣₑd(共享查询)和Kₛₕₐᵣₑd(共享键),并通过线性层计算通道的 值层以学习互补特征,得到Vₒₕₐₙₙₑₗ=WᵥX(维度为hwd×C)——其中Wᵥ为Vₒₕₐₙₙₑₗ(通道值层)的投影权重。通道注意力的定义如下:
![]()
其中,Vₒₕₐₙₙₑₗ(通道值层)、Qₛₕₐᵣₑd(共享查询)和Kₛₕₐᵣₑd(共享键)分别表示通道值层、共享查询矩阵和共享键矩阵。最后,我们对两个注意力子模块的输出进行求和融合,并通过卷积模块对融合结果进行转换,以获得丰富的特征表征。EPA模块的最终输出X̂计算如下:
![]()
其中,X̂ₛ和X̂c分别表示空间注意力图和通道注意力图,Conv1和Conv3分别为1×1×1和3×3×3卷积模块。
C. Loss Function
遵循基线模型UNETR [1]和nnFormer [5],我们的损失函数基于常用的软Dice损失[18]与交叉熵损失的总和,以同时利用这两种互补损失函数的优势。其定义如下:
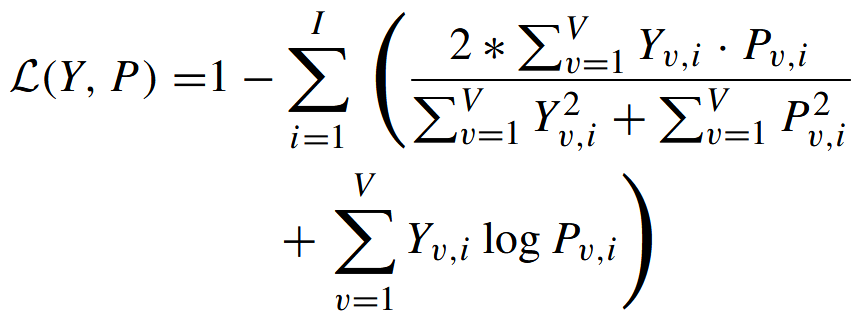
其中,I表示类别数量,V表示体素数量,Yv,i和Pv,i分别表示体素v处类别i的真实标签和输出概率。
IV. EXPERIMENTS
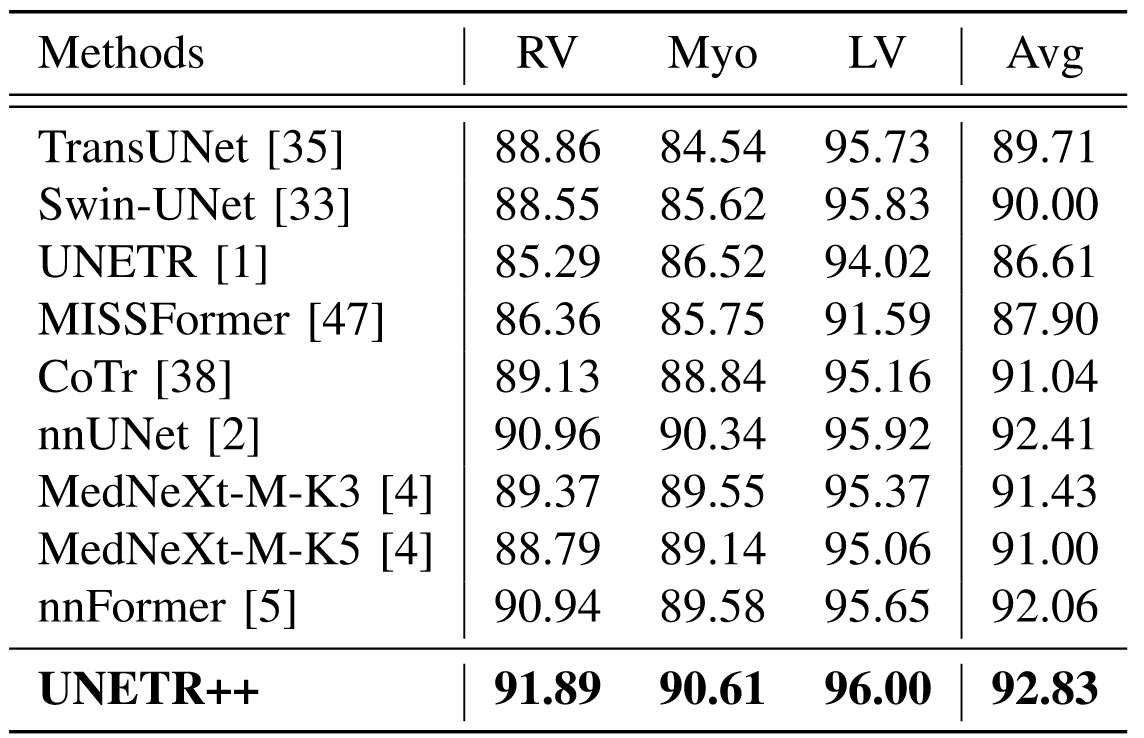
V. CONCLUSION AND DISCUSSION
我们提出了一种名为UNETR++的分层方法,用于3D医学分割。UNETR++引入了高效配对注意力(EPA)模块,通过空间注意力和通道注意力对丰富的、互依赖的空间特征与通道特征进行编码。在EPA模块中,我们共享查询和键映射函数的权重,以促进空间分支与通道分支之间的信息交互,这不仅带来了互补优势,还减少了参数数量。
我们的UNETR++在五个数据集(Synapse、ACDC、BTCV、BraTS和Decathlon-Lung)上取得了优异的分割结果,同时与现有最佳方法相比,显著降低了模型复杂度(从参数数量、计算量(FLOPs)来看)。此外,我们的研究表明,UNETR++的GPU内存消耗更低——这是3D分割任务的关键因素,且在GPU和CPU平台上均能以更快的推理速度运行。因此,UNETR++提供了一种更通用且资源效率更高的解决方案,提升了在移动平台部署医学分割模型以进行实时医学图像分析的可行性。
所提出的EPA模块具有通用性,可应用于其他研究中。为验证这一点,我们在TransBTS[43]的框架中,用所提出的EPA模块替换了其自注意力模块,并在Synapse数据集上对更新后的模型进行了评估。结果显示,Dice相似系数(DSC)提升了1.2%(从83.28%升至84.47%),归一化表面距离(NSD)提升了0.8%,95%豪斯多夫距离(HD95)从12.34显著降至7.92,平均对称表面距离(MASD)从3.65降至3.11。
为探究UNETR++可能存在的局限性,我们对不同的异常案例进行了分析。尽管我们的预测结果优于现有方法,且更接近真实标签,但我们发现,在少数案例中,我们的模型以及大多数现有方法都难以对某些器官进行分割。当少数切片中器官的几何形状异常(表现为边界纤细)时,我们的模型和大多数现有模型都难以对其进行精确分割。原因可能是,与正常形状的样本相比,这种异常形状的训练样本数量有限。在某些案例中,与最新的基于CNN的方法MedNeXt[4]相比,我们的模型在归一化表面距离(NSD)上表现较低,这一定量结果体现了上述定位误差。其原因可能在于基于CNN的方法具有归纳偏置,擅长捕捉空间层次结构和局部模式。我们计划通过在预处理阶段应用几何数据增强技术来解决这一问题。






)












