一、项目简介
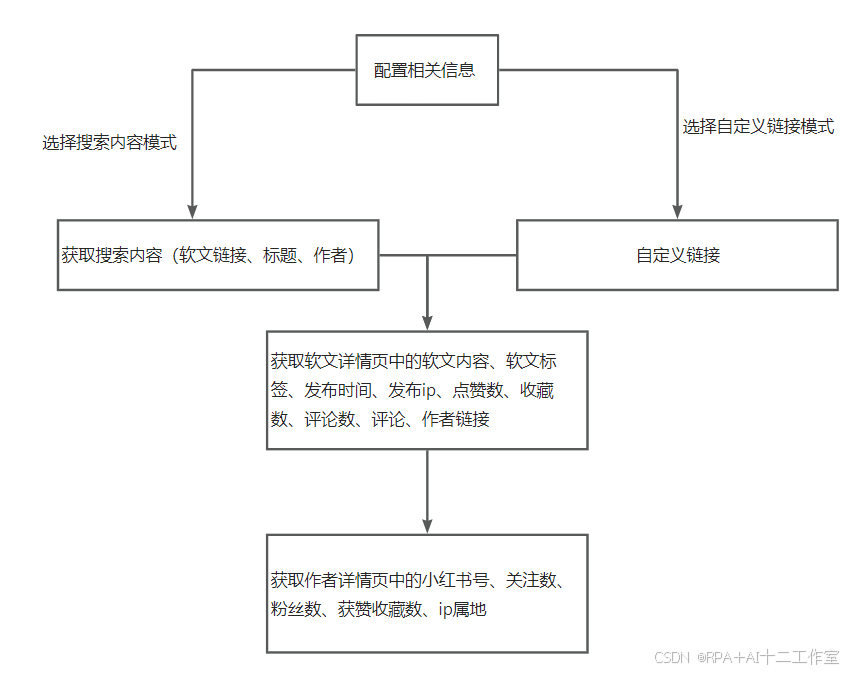
本项目是一个基于影刀RPA的小红书笔记批量采集工具,能够通过两种模式获取小红书平台的软文数据:搜索内容抓取和自定义链接抓取。工具使用Chrome浏览器自动化技术,实现了从网页数据采集、解析到Excel导出的完整流程。支持获取笔记标题、作者信息、内容、点赞收藏数据、评论等多维度信息,并提供数据表格导出功能。
二、项目结构
主要目录结构
xbot_robot/
├── .dev/ # 开发相关资源文件
├── __pycache__/ # Python编译缓存
├── main.py # 程序入口
├── package.py # 项目配置与公共接口
├── utils.py # 工具函数
├── process1-9.py # 各功能流程模块
├── selectorsV2.xml # 网页元素选择器配置
├── package.json # 项目元数据与配置
└── settings.json # 应用设置
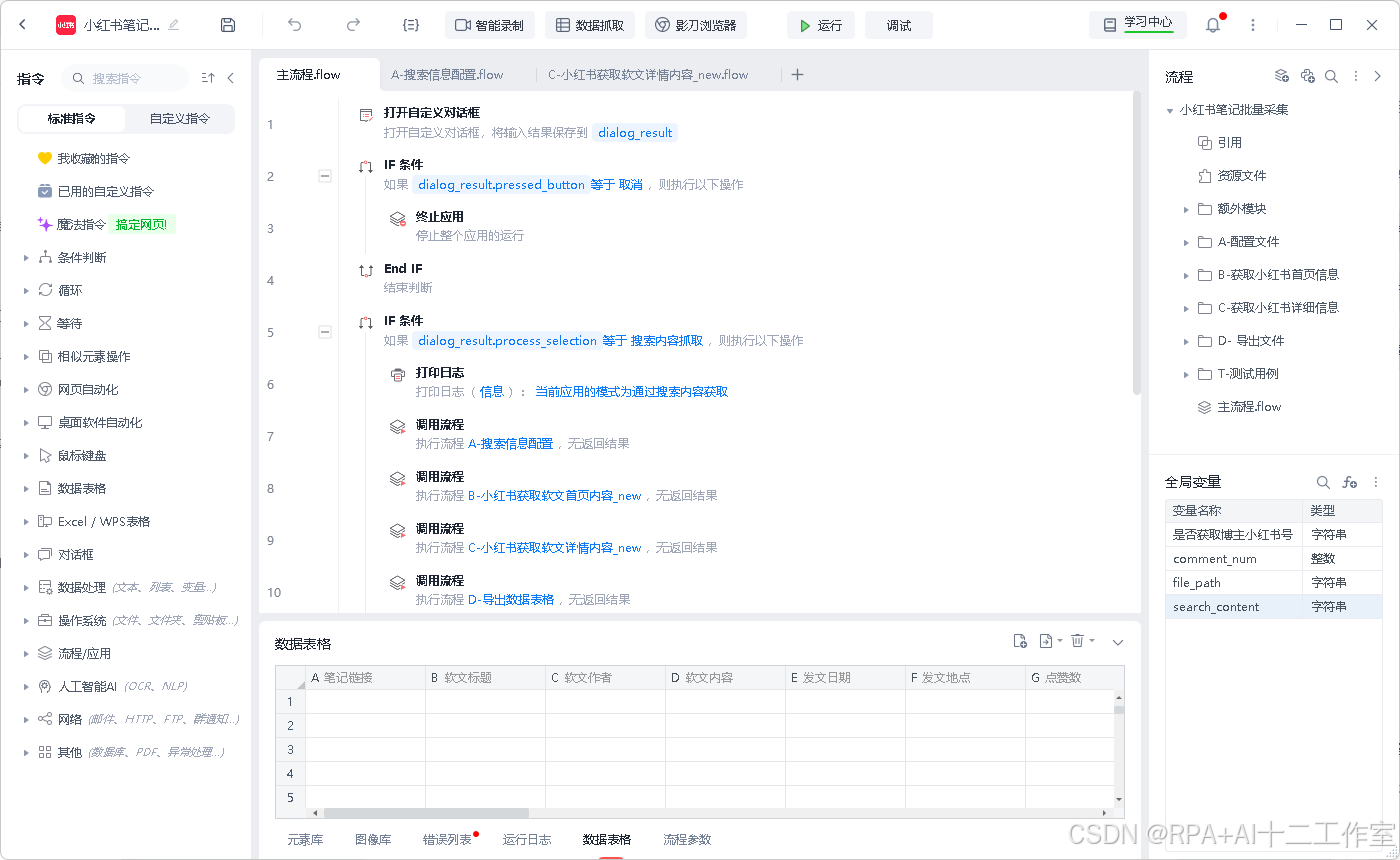
核心流程模块
- main.py: 程序入口,提供流程选择对话框
- process1.py: 搜索信息配置
- process4.py: 获取作者详情
- process5.py: 数据导出功能
- process6.py: 自定义链接配置
- process8.py: 小红书首页内容抓取
- process9.py: 小红书详情内容抓取
- utils.py: 数据处理工具函数
三、项目特点和核心代码
主要特点
- 双模式采集:支持关键词搜索和自定义链接两种采集方式
- 多维度数据:获取标题、作者、内容、点赞、收藏、评论等完整信息
- 智能分页:自动滚动加载并检测页面底部
- 数据导出:支持导出为Excel格式
- 元素定位:通过XML配置文件管理网页元素选择器
核心代码示例
1. 数据处理工具函数(utils.py)
def deal_data(response_body_list):note_id_list=[]for response in response_body_list:r = json.loads(response['body'])adinfos = r.get('data', {}).get('items', [])has_more = r.get('data', {}).get('has_more')if has_more:for info in adinfos:note_id= info.get('id','')xsec_token = info.get('xsec_token','')note_id_list.append({'id':note_id,'xsec_token':xsec_token})note_url_list = [f'https://www.xiaohongshu.com/explore/{i.get("id")}?xsec_token={i.get("xsec_token")}&xsec_source=pc_search' for i in note_id_list if len(i.get('id'))<=24]return note_url_list
2. 网页内容抓取(process8.py)
# 监听网络请求获取数据
xbot_visual.web.browser.start_monitor_network(browser=web_page, url="https://edith.xiaohongshu.com/api/sns/web/v1/search/notes", use_wildcard=False, resource_type="Fetch|XHR")
# 输入搜索内容并提交
xbot_visual.web.element.input(browser=web_page, element=package.selector("小红书-搜索内容输入框"), text=glv['search_content'])
# 滚动加载更多内容
while True:xbot_visual.win32.wheel_mouse(wheel_direction="down", wheel_times="5")# 检测是否到达页面底部if web_element_list[-1] == 最后一个元素文本内容:break
四、适用场景
- 市场调研:批量采集特定关键词的小红书笔记,分析热门内容趋势
- 竞品分析:监控竞争对手的小红书账号及内容表现
- 内容创作:获取行业热门话题和用户关注点
- 舆情监控:追踪特定品牌或产品在小红书的讨论情况
- 学术研究:社交媒体内容分析与数据挖掘
五、常见问题与建议
常见问题
- 浏览器兼容性:仅支持Chrome浏览器,请确保已安装最新版本
- 登录问题:程序需要小红书账号登录状态,未登录会导致采集失败
- 反爬限制:频繁采集可能触发小红书风控机制,导致账号限制
- 元素定位失败:网页结构变更可能导致选择器失效
使用建议
- 安装影刀插件:确保Chrome浏览器已安装影刀插件
- 控制采集频率:避免长时间连续采集,建议设置适当间隔
- 定期更新选择器:当网页结构变化时,需要更新selectorsV2.xml中的元素配置
- 使用代理IP:高频率采集时建议使用代理IP池
- 及时保存数据:定期导出数据,避免程序异常导致数据丢失
六、源码下载
- 通过影刀RPA客户端应用市场获取。
- 私聊
七、后续扩展方向
- 定时任务:支持设置定时采集任务
- 云同步:增加数据云存储和多设备同步功能
- AI内容分析:集成自然语言处理,实现情感分析和关键词提取
- 代理池管理:内置代理IP池,提高反爬能力

)




)



)


)





