论文阅读笔记:Dataset Condensation with Gradient Matching
- 1. 解决了什么问题?(Motivation)
- 2. 关键方法与创新点 (Key Method & Innovation)
- 2.1 核心思路的演进:从参数匹配到梯度匹配
- 2.2 算法实现细节 (Implementation Details)
- 3. 实验结果与贡献 (Experiments & Contributions)
- 4.个人思考与启发
- 主要代码
- 算法逻辑总结
ICLR2021 github
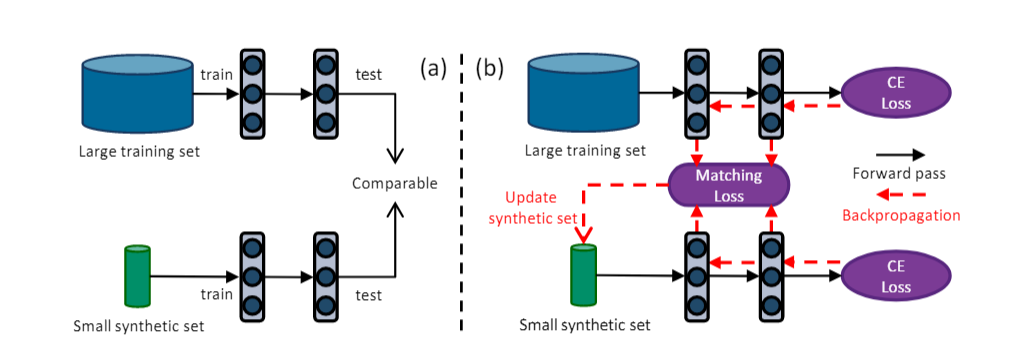
核心思想一句话总结:
本文提出了一种创新的数据集压缩方法——数据集凝缩(Dataset Condensation,DC),其核心思想是通过梯度匹配(Gradient Matching),将一个大型数据集
T浓缩成一个极小的、信息量丰富的合成数据集S。在S上从头训练的模型,其性能可以逼近在T上训练的模型,从而极大地节省了存储和训练成本。
1. 解决了什么问题?(Motivation)
- 问题:现代深度学习依赖于大规模数据集,导致存储成本、数据传输宽带和模型训练时间急剧增加。
- 目标:创建一个微型合成数据集
S,它能作为原始大型数据集T的高效替代品,用于从零开始训练神经网络
2. 关键方法与创新点 (Key Method & Innovation)
2.1 核心思路的演进:从参数匹配到梯度匹配
- 参数匹配 (Parameter Matching) - 一个被否定的思路
- 想法:直接让
S训练收敛后的模型参数θS\theta_SθS与用T训练收敛后的θT\theta_TθT尽可能接近。 - 缺陷:
- 优化路径复杂:深度网络的参数空间非凸,直接走向目标θT\theta_TθT极易陷入局部最优。
- 计算成本高:需要嵌套的双层优化,内循环必须将模型训练至收敛,计算上不可行。
- 想法:直接让
- 梯度匹配 (Gradient Matching) - 本文的核心创新
- 想法:放弃匹配静态的”终点“,转而匹配动态的”过程“。即,确保在训练每一步,模型在合成数据
S上产生的梯度∇Ls∇L_s∇Ls在真实数据T上产生的梯度∇LT∇L_T∇LT方向一致。 - 优势:
- 计算高效:通过一个巧妙的近似,极大提高了效率和可扩展性。
- 优化路径清晰:每一步都有明确的监督信号(梯度差异),引导
S的优化,避免了在复杂空间中盲目搜索。 - 对齐学习动态:保证了模型在
S上的学习方式与T上一致,结果更鲁棒。
- 想法:放弃匹配静态的”终点“,转而匹配动态的”过程“。即,确保在训练每一步,模型在合成数据
2.2 算法实现细节 (Implementation Details)
- 课程学习 (Curriculum Learning)
- 为了让合成数据
S具有泛化性,算法采用了一个”课程学习“的框架。在整个凝缩过程中,会周期性地重新随机初始化网络参数θ\thetaθ。 - 这确保了
S不会过拟合到某一个特定的网络初始化,而是对多种随机起点都有效。
- 为了让合成数据
- 梯度匹配损失函数(Gradient Matching Loss)
- 使用**余弦距离(1-Cosine Similarity)**来衡量两个梯度的差异。这更关注梯度的方向而非大小,与梯度下降的本质契合。
- 按输出节点分组计算:并非所有层的梯度粗暴地展平,而是按输出神经元分组计算余弦距离,更好地保留了网络结构信息。
- 重要的工程技巧(Practical Tricks)
- BatchNorm层预热与冻结:由于合成数据批次极小,为了避免BN层统计量不稳定,每次迭代前都先用一个较大的真实数据批次来计算并”冻结“BN层的均值和方差。
- 按类别独立匹配:在计算梯度时,按类别独立进行,即用”猫“的合成数据区匹配”猫“的真实数据梯度。这降低了学习难度和内存消耗。
3. 实验结果与贡献 (Experiments & Contributions)
- 性能优越:在CIFAR-10, CIFAR-100, SVHN等数据集上,仅用极少量合成样本(如IPC=1或10),就能训练出性能远超当时其他数据压缩方法的模型。
- 开创性贡献:
- 首次提出了梯度匹配这一高效且可扩展的数据集凝缩范式,为后续大量的研究(如DSA, MTT, FTD等)奠定了基础。
- 成功将数据集凝缩技术应用到了大型网络上,证明了其可行性。
- 展示了其在持续学习和神经架构搜索 (NAS) 等资源受限场景下的巨大潜力。
4.个人思考与启发
- ”过程“比”结果”更重要:这篇论文最精妙的哲学在于,它揭示了在复杂优化问题中,对齐“过程”(梯度)比直接追求“结果”(参数)更有效、更可行。这一思想在很多其他领域也具有启发性。
- 理论与实践的结合:论文不仅提出了一个优雅的理论框架,还通过BN层处理等工程技巧解决了实际应用中的痛点。
主要代码
''' training '''# 为合成图像image_syn创建一个优化器# 我们只优化image_syn这个张量,所有优化器只传入它。# 这里的优化器是SGD,意味着我们会用梯度下降法来更新图像的像素值。optimizer_img = torch.optim.SGD([image_syn, ], lr=args.lr_img, momentum=0.5) # optimizer_img for synthetic data# 清空优化器的梯度缓存optimizer_img.zero_grad()# 定义用于计算分类损失的损失函数,这里是标准的交叉熵损失。criterion = nn.CrossEntropyLoss().to(args.device)print('%s training begins'%get_time())# 主迭代循环开始# 这个循环是整个数据集凝缩过程的核心,总共进行Iteration+1次。for it in range(args.Iteration+1):# 评估合成数据(在特定迭代点触发)''' Evaluate synthetic data '''if it in eval_it_pool:for model_eval in model_eval_pool:# 遍历model_eval_pool中的每一个模型架构,用于评估。# 这运行我们测试合成数据集在不同模型上的泛化能力。print('-------------------------\nEvaluation\nmodel_train = %s, model_eval = %s, iteration = %d'%(args.model, model_eval, it))# 设置评估时的数据增强策略if args.dsa:# 如果是DSA方法,使用其特定的增强策略。args.epoch_eval_train = 1000args.dc_aug_param = Noneprint('DSA augmentation strategy: \n', args.dsa_strategy)print('DSA augmentation parameters: \n', args.dsa_param.__dict__)else:# 如果是DC方法,调用 get_daparam 获取专为DC设计的增强参数。# 注意:这些增强只在评估时使用,在生成合成数据时不用。args.dc_aug_param = get_daparam(args.dataset, args.model, model_eval, args.ipc) # This augmentation parameter set is only for DC method. It will be muted when args.dsa is True.print('DC augmentation parameters: \n', args.dc_aug_param)# 如果在评估时使用了任何数据增强,就需要更多的训练轮数来让模型充分学习。if args.dsa or args.dc_aug_param['strategy'] != 'none':args.epoch_eval_train = 1000 # Training with data augmentation needs more epochs.else:args.epoch_eval_train = 300# --- 3.2 执行评估 ---# 创建一个空列表,用于存储多次评估的准确率accs = []# 为了结果的稳定性,我们会用当前的合成数据训练num_eval个独立,随机初始化的模型。for it_eval in range(args.num_eval):# 每一次都创建一个全新的、随机初始化的评估网络。net_eval = get_network(model_eval, channel, num_classes, im_size).to(args.device) # get a random model# 深拷贝当前的合成数据和标签,以防止在评估函数中被意外修改。# detach()是为了确保我们只复制数据,不带计算图。image_syn_eval, label_syn_eval = copy.deepcopy(image_syn.detach()), copy.deepcopy(label_syn.detach()) # avoid any unaware modification# 调用核心评估函数 evaluate_synset。# 这个函数会:# 1. 拿 image_syn_eval 从头开始训练 net_eval。# 2. 在训练结束后,用训练好的 net_eval 在真实的测试集 testloader 上进行测试。# 3. 返回在测试集上的准确率 acc_test。_, acc_train, acc_test = evaluate_synset(it_eval, net_eval, image_syn_eval, label_syn_eval, testloader, args)accs.append(acc_test)# 打印这次评估的平均准确率和标准差。print('Evaluate %d random %s, mean = %.4f std = %.4f\n-------------------------'%(len(accs), model_eval, np.mean(accs), np.std(accs)))# 如果这是最后一次迭代,将这次评估的所有准确率结果记录到总的实验结果字典中。if it == args.Iteration: # record the final resultsaccs_all_exps[model_eval] += accs# 可视化并保存合成图像''' visualize and save '''save_name = os.path.join(args.save_path, 'vis_%s_%s_%s_%dipc_exp%d_iter%d.png'%(args.method, args.dataset, args.model, args.ipc, exp, it))# 深拷贝合成图像,并移到CPU上进行处理。image_syn_vis = copy.deepcopy(image_syn.detach().cpu())# 对图像进行反归一化,以便人眼观察# 训练时图像通常是归一化的。# 反归一化公式:pixel = pixel * std + meanfor ch in range(channel):image_syn_vis[:, ch] = image_syn_vis[:, ch] * std[ch] + mean[ch]# 将像素值裁剪到[0,1]范围内,防止因浮点数误差导致显示异常。image_syn_vis[image_syn_vis<0] = 0.0image_syn_vis[image_syn_vis>1] = 1.0# 使用torchvision.utils.save_image将合成图像保存为一张网格图。# nrow=args.ipc表示每行显示ipc张图像。save_image(image_syn_vis, save_name, nrow=args.ipc) # Trying normalize = True/False may get better visual effects.# --- 初始化课程学习环境 ---''' Train synthetic data '''# 每次主迭代(it)开始,都创建一个全新的、随机初始的网络。# 这是”课程学习“的关键:确保合成数据对不同的网络初始化方法都有效,而不是过拟合到某一个。net = get_network(args.model, channel, num_classes, im_size).to(args.device) # get a random modelnet.train() # 将网络设置为训练模式# 获取网络的所有可学习参数net_parameters = list(net.parameters())# 为这个新网络创建一个优化器,用于在内循环中更新网络参数optimizer_net = torch.optim.SGD(net.parameters(), lr=args.lr_net) # optimizer_img for synthetic dataoptimizer_net.zero_grad()# 初始化平均损失,用于记录和打印loss_avg = 0# 在生成合成数据时,不使用任何数据增强,以与DC论文的设置保持一致args.dc_aug_param = None # Mute the DC augmentation when learning synthetic data (in inner-loop epoch function) in oder to be consistent with DC paper.# --- 课程学习外循环(Outer Loop) ---# 这个循环对应论文算法中的外循环,用于实现课程学习。for ol in range(args.outer_loop):# -- BatchNorm层预热与冻结(一个非常重要的工程技巧) --''' freeze the running mu and sigma for BatchNorm layers '''# Synthetic data batch, e.g. only 1 image/batch, is too small to obtain stable mu and sigma.# So, we calculate and freeze mu and sigma for BatchNorm layer with real data batch ahead.# This would make the training with BatchNorm layers easier.# 动机:合成数据的批次非常小(例如ipc=1),如果让BN层在这么小的批次上计算均值和方差,结果会极其不稳定,导致训练困难。# 解决方案:先用一个包含多个真实样本的”大“批次来预热BN层,计算出稳定的统计量,然后将其冻结。BN_flag = FalseBNSizePC = 16 # for batch normalization 每个类别用于BN预热的样本数# 检查网络中是否存在BN层for module in net.modules():if 'BatchNorm' in module._get_name(): #BatchNormBN_flag = Trueif BN_flag:# 从每个类别中抽取BNSizePC个真实图像,拼接成一个大批次。img_real = torch.cat([get_images(c, BNSizePC) for c in range(num_classes)], dim=0)# 确保网络在训练模式,以便BN层可以更新其 running_mean 和 running_var。net.train() # for updating the mu, sigma of BatchNorm# 进行一次前向传播,这个操作会自动更新BN层的统计量。output_real = net(img_real) # get running mu, sigma# 将所有BN层切换到评估模式。# 在评估模式下,BN层会使用已经计算好的 running_mean 和 running_var,而不会再根据新的输入来更新它们。# 这就实现了“冻结”的效果。for module in net.modules():if 'BatchNorm' in module._get_name(): #BatchNormmodule.eval() # fix mu and sigma of every BatchNorm layer# --- 核心:通过梯度匹配更新合成数据 ---''' update synthetic data '''# 初始化当前外循环的总损失loss = torch.tensor(0.0).to(args.device)# 按照类别独立进行梯度匹配,这个是论文提出的另外一个技巧。for c in range(num_classes):# 准备真实数据和合成数据img_real = get_images(c, args.batch_real)lab_real = torch.ones((img_real.shape[0],), device=args.device, dtype=torch.long) * cimg_syn = image_syn[c*args.ipc:(c+1)*args.ipc].reshape((args.ipc, channel, im_size[0], im_size[1]))lab_syn = torch.ones((args.ipc,), device=args.device, dtype=torch.long) * c# 如果使用DSA方法,对真实和合成图像应用相同的可微数据增强if args.dsa:seed = int(time.time() * 1000) % 100000img_real = DiffAugment(img_real, args.dsa_strategy, seed=seed, param=args.dsa_param)img_syn = DiffAugment(img_syn, args.dsa_strategy, seed=seed, param=args.dsa_param)# --- 计算真实梯度 gw_real ---output_real = net(img_real)loss_real = criterion(output_real, lab_real)# 计算损失对网络参数的梯度gw_real = torch.autograd.grad(loss_real, net_parameters)# clone()和detach()是为了将梯度值复制下来,并切断其与计算图的联系,# 因为我们只需要它的数值作为匹配目标,不希望梯度回流真实数据。gw_real = list((_.detach().clone() for _ in gw_real))# -- 计算合成梯度gw_syn --output_syn = net(img_syn)loss_syn = criterion(output_syn, lab_syn)# 关键所在:create_graph=True# 这个参数告诉pytorch,在计算gw_syn时,要保留其计算图。# 这意味着gw_syn本身也成为了一个计算图中的节点,它依赖于iamge_syn.# 因此,后续对gw_syn的损失进行反向传播时,梯度可以一直流回image_syn。gw_syn = torch.autograd.grad(loss_syn, net_parameters, create_graph=True)# 计算真实梯度和合成梯度之间的匹配损失,余弦相似度loss += match_loss(gw_syn, gw_real, args)# 更新合成图像optimizer_img.zero_grad() # 清空image_syn的梯度缓存loss.backward() # 反向传播,计算匹配损失对image_syn对image_syn的梯度optimizer_img.step() # 根据梯度更新image_syn的像素值loss_avg += loss.item() # 累加损失用于打印# 如果是最后一个外循环,就不需要再更新网络了,直接跳出。if ol == args.outer_loop - 1:break# --- 2.3 内循环:用更新后的合成数据训练网络 ---''' update network '''# 第二步:现在轮到网络来适应更新后的合成数据了。image_syn_train, label_syn_train = copy.deepcopy(image_syn.detach()), copy.deepcopy(label_syn.detach()) # avoid any unaware modificationdst_syn_train = TensorDataset(image_syn_train, label_syn_train)trainloader = torch.utils.data.DataLoader(dst_syn_train, batch_size=args.batch_train, shuffle=True, num_workers=0)# 对网络进行inner_loop次的训练更新。for il in range(args.inner_loop):epoch('train', trainloader, net, optimizer_net, criterion, args, aug = True if args.dsa else False)# 记录和保存# 计算并打印平均损失loss_avg /= (num_classes*args.outer_loop)if it%10 == 0:print('%s iter = %04d, loss = %.4f' % (get_time(), it, loss_avg))# 如果是最后一次主迭代,保存所有结果if it == args.Iteration: # only record the final resultsdata_save.append([copy.deepcopy(image_syn.detach().cpu()), copy.deepcopy(label_syn.detach().cpu())])torch.save({'data': data_save, 'accs_all_exps': accs_all_exps, }, os.path.join(args.save_path, 'res_%s_%s_%s_%dipc.pt'%(args.method, args.dataset, args.model, args.ipc)))算法逻辑总结
“你追我赶”的双重优化过程:
- 课程学习 (Outer Loop):
- 每一次外循环,都像是新学期开学,我们找来一个“新生”(一个随机初始化的
net)。 - 这个“新生”的存在,是为了确保我们的“教材”(合成数据
image_syn)是普适的,对任何基础的学生都有效。
- 每一次外循环,都像是新学期开学,我们找来一个“新生”(一个随机初始化的
- 教材编写 (Update Synthetic Data):
- 这是核心步骤。我们让“新生”
net分别看“官方教材”(真实数据img_real)和我们正在编写的“浓缩笔记”(合成数据img_syn)。 - 我们记录下“新生”看完两种材料后的“学习心得”(梯度
gw_real和gw_syn)。 - 我们的目标是修改“浓缩笔记”
img_syn,使得“新生”看完它之后产生的“学习心得”gw_syn和看完“官方教材”产生的gw_real一模一样。 create_graph=True是实现这一点的技术关键,它允许我们对“学习心得”本身求导,从而知道该如何修改“浓y缩笔记”的每一个字(像素)。
- 这是核心步骤。我们让“新生”
- 学生自习 (Update Network):
- “浓缩笔记”
image_syn更新完毕后,我们让“新生”net对着这本新版的笔记自习几遍(inner_loop次)。 - 这会让“新生”对当前的“浓缩笔记”有更深的理解,为下一轮的“教材编写”做好准备。
- “浓缩笔记”
这个“编写教材 -> 学生自习 -> 换个新生再来一遍”的过程不断重复,最终使得“浓缩笔记” image_syn 变得越来越精华,能够高效地替代“官方教材” T。





数据链路层)





系统:构建认知推理的骨架结构)




创建新的slave从机)


